 为k近邻机器翻译领域自适应构建可解释知识库
为k近邻机器翻译领域自适应构建可解释知识库
01
摘要
通过为神经机器翻译(Neural Machine Translation,NMT)模型配备额外的符号化知识库(symbolic datastore),k近邻机器翻译(k-nearest-neighbor machine translation, kNN-MT)[1] 框架展示了一种全新的领域自适应范式。但是,在构建知识库时通常需要将平行语料中所有的目标语言词语都存储进知识库,这样不仅会导致知识库规模过于庞大,也会导致知识库中存在大量冗余条目(entry)。为了克服以上问题,本文从“NMT模型需要什么样的额外知识”这一本质问题出发,对知识库构建过程的可解释性展开了深入的研究。最终,我们提出局部准确性(local correctness)这一新概念作为解释角度,它描述了NMT模型在一个条目及其邻域空间内的翻译准确性。从局部准确性出发,我们建立了NMT模型与知识库之间的联系,确定了NMT模型容易犯错并依赖额外知识的情况。基于局部准确性,我们也提出了一种简单有效的知识库剪枝方案。在两个语言对,六个目标领域上的实验结果表明,根据局部准确性进行知识库剪枝能够为kNN-MT系统构建一个更加轻量、可解释的知识库。
该工作发表在ACL Findings,由南京大学自然语言处理组独立完成。
本文的预印本发布在arXiv:https://arxiv.org/pdf/2211.04052.pdf
相关代码发布在Github:https://github.com/NJUNLP/knn-box
02
NMT模型能力分析
鉴于NMT模型可以不依赖于知识库完成目标领域的部分翻译内容,我们推测NMT模型是掌握目标领域的部分双语知识的。但是,目前的知识库构建过程却忽略了这一点,导致知识库中存储了冗余知识。直觉上,知识库中只需要存储能够修复NMT模型缺陷的知识。
为了找到NMT模型的潜在缺陷,构建更加可解释的知识库,我们提出以局部准确性这一新概念作为分析角度。其中,局部准确性又包含两个子概念:条目准确性(entry correctness)和邻域准确性(neighborhood correctness)。基于这些分析工具,我们成功找到了NMT模型的潜在缺陷。以下是对这些概念和分析过程的具体介绍:
条目准确性:NMT模型在目标领域的翻译能力很难直接描述,但是检查NMT模型在每一个知识库条目上的翻译准确性是相对容易可行的。因此我们首先根据条目准确性,判断NMT模型的翻译能力。条目准确性的判定过程是:针对知识库中的每一个条目,我们检查NMT模型能否根据隐层表示预测出目标语言词语。若可以,则判定该条目为NMT模型掌握的知识(known entry);若不可以,则判定该条目为NMT模型没有掌握的知识(unknown entry)。
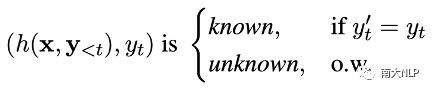
邻域准确性:但是,我们注意到仅靠条目准确性并不能完全反映NMT模型的全部缺陷。因为即使对于known条目,NMT模型仍然会在面对相似上下文时出现翻译错误。因此,为了更加全面地衡量NMT模型的能力,我们基于条目准确性提出邻域准确性的概念,它描述了NMT模型在一个邻域空间内的翻译准确性。为了量化评估邻域准确性这一概念,我们进一步提出知识边界(knowledge margin,km)指标。它的具体定义如下:给定条目(h, y),它的邻域空间由该位置的k近邻条目所描述,该位置的知识边界值km(h)的计算方式为:
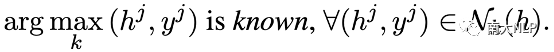
值得注意的是,知识边界的计算方式可以推广到表示空间中的任意一点,因此可以被用来考察NMT模型在表示空间中任意一点的能力。
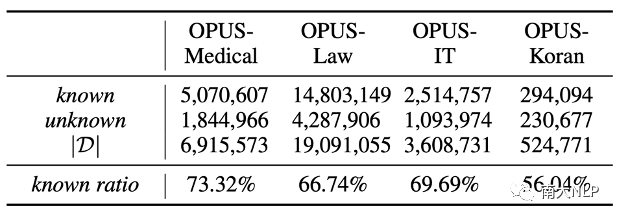
分析实验:下面我们将基于以上概念,以OPUS数据集为例,分析NMT模型与知识库之间的关系,揭露NMT模型的潜在缺陷。首先,我们统计了在不同领域知识库中,known条目和unknown条目的占比情况。统计结果显示:知识库中56%-73%的条目都是NMT模型所掌握的(表格1),这也意味着知识库确实存在极大的冗余。
表格 1 条目准确性统计结果
接着,我们衡量了NMT模型在各知识库条目上的邻域准确性,并绘制了知识边界值分布图(图1)。在四个OPUS领域上,知识边界值的分布情况相似:大多数unknown条目的知识边界值很低,而known条目的知识边界值则数值分布差异较大。这说明邻域准确性与条目准确性总体上是一致的,但是邻域准确性可以更好地展示known条目之间的差异。
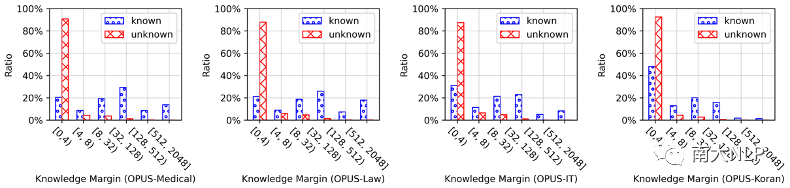
图 1 知识边界值分布情况
为了进一步展示知识边界值与NMT模型翻译能力之间的联系,我们在各个领域的验证集上进行了实验,展示NMT模型在每一个翻译步上的翻译准确率和知识边界值之间的关系。从图2中可以看出,对于知识边界值较大的翻译步,NMT模型的翻译准确率高达95%,但是对于知识边界值较小的翻译步,NMT模型的翻译准确率只有50%左右。这说明NMT模型在知识边界值小时是非常容易出现翻译错误的,这些位置也是NMT模型的缺陷所在。
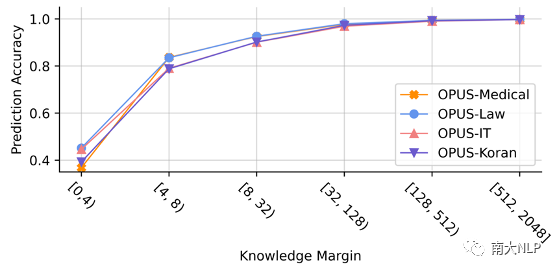
图 2 翻译准确率与知识边界值之间的关系
03
基于局部准确性构建可解释知识库
鉴于局部准确性可以准确地反映NMT模型的能力强弱,我们也使用其来衡量知识库条目对于NMT模型的价值。基于这种价值判断,我们提出了一种新颖的知识库剪枝算法PLAC(Pruning with LocAl Correctness)。该算法的核心思路是去除知识库中知识边界值大的条目,因为在这些位置NMT模型本身的能力很强,这些位置的知识库条目对于NMT模型的价值较小。PLAC方法的具体算法流程如图3。该剪枝算法实现简单,不需要训练任何额外神经网络,剪枝后的知识库也可以在不同kNN-MT系统中使用。

图 3 PLAC剪枝算法伪代码
04
实验设定
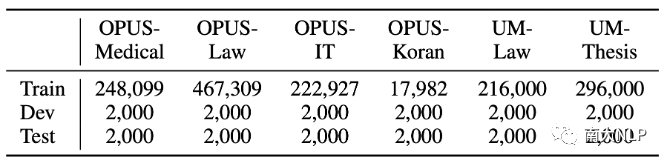
数据集:我们在众多机器翻译领域自适应数据集上进行了知识库剪枝实验,包括四个德语-英语OPUS数据集 [2] 和两个中文-英语UM数据集 [3]。各数据集的具体规模如表格2所示。
表格 2 数据集统计信息
NMT模型:在德语-英语实验中,我们使用WMT19德语-英语新闻翻译任务的冠军模型[4]作为预训练NMT模型。在中文-英语实验上,我们使用自己在CWMT17中文-英语数据上训练的NMT模型作为预训练NMT模型。
05
实验结果
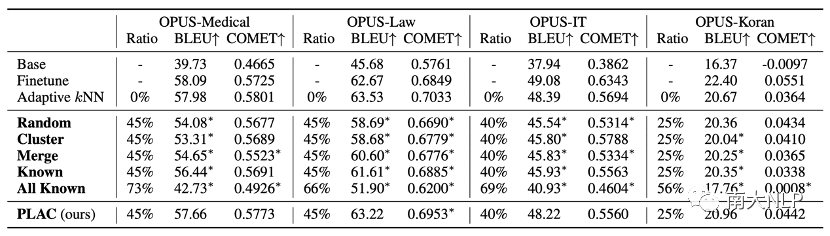
使用PLAC进行知识库剪枝是安全可靠的:从OPUS数据集上的剪枝实验结果可以看出(表格3),PLAC可以在保持翻译性能不变的情况下,去除25%-45%的知识库条目。尤其是在OPUS-Medical和OPUS-Law这两个所需知识库最庞大的领域上,我们的方法成功去除了45%的知识库条目。出色的剪枝效果说明使用局部准确性确实可以衡量NMT模型的能力以及判断知识库条目的价值。
在基线剪枝方法中,Cluster[5]和Merge[6]都造成了巨大的翻译性能损失,这说明即使一部分条目对应相同的目标语言词语,这些条目对于NMT模型的价值也是不同的。另外,从Known和All Known两种方法的结果来看,仅根据条目准确性进行剪枝也会造成性能损失。这说明在判断条目价值时,综合考虑条目准确性和邻域准确性是非常必要的。
表格 3 剪枝实验结果(OPUS数据集)
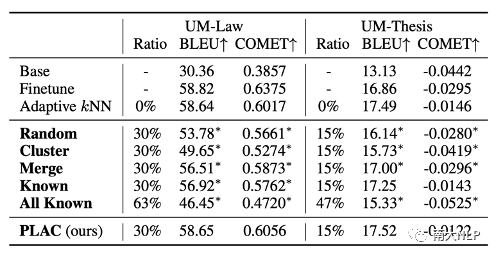
我们也在表格4中报告了UM数据集上的实验结果。在不损害翻译性能的情况下,在UM-Law数据集上知识库规模可以被减少30%,在UM-Thesis数据集上知识库规模可以被减少15%。其余的实验结论与OPUS数据集上得出的实验结论相似。
表格 4 剪枝实验结果(UM数据集)
知识边界阈值对剪枝效果的影响:在我们提出的方法中,知识边界阈值在剪枝过程中起着重要作用。在图4中,我们进一步展示了该阈值对剪枝效果的影响。我们发现在不同领域上,各剪枝方案的剪枝效果有着相同的变化趋势:PLAC方法总是比其他剪枝方法有着更好的剪枝效果,并且在高剪枝率时也可以保持更加稳定的性能。从图中还可以看出,知识边界阈值的设定对BLEU分数和最大剪枝比例有着直接影响:知识边界阈值越大,最大剪枝比例越小,翻译性能损失也越小;知识边界阈值越小,最大剪枝比例越大,但是可能造成的翻译性能损失也会增大。
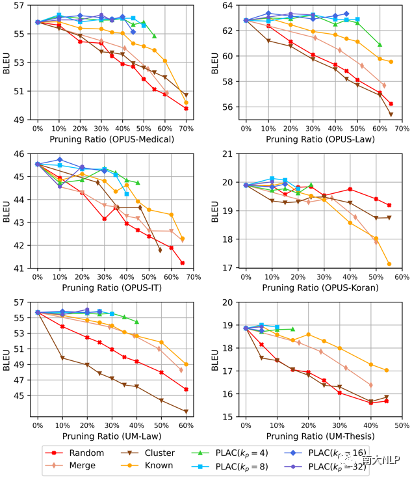
图 4 不同剪枝方案的剪枝效果对比
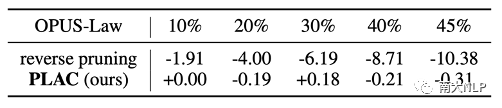
低知识边界值知识条目十分重要:为了验证低知识边界值的条目对NMT模型的价值,我们采用反向剪枝策略:对低知识边界值进行剪枝。表格5中展示了实验结果。可以看出,即使在较小的剪枝比例下,反向剪枝策略都会对翻译性能造成巨大的负面影响,这说明这部分知识库条目确实对于NMT模型成功进行领域自适应非常重要。
表格 5 正反向剪枝策略的剪枝效果对比
剪枝后的知识库占据的存储空间明显减少:在实际运行kNN-MT系统进行翻译时,知识库需要被载入到CPU和GPU上。因此,知识库的规模将直接影响翻译效率。表格6中展示了原始的完整知识库和剪枝过的轻量知识库之间的大小对比,可以看出我们提出的剪枝方法可以极大地减小知识库所占用的存储空间。
表格 6 完整知识库与轻量知识库的存储占用对比

06
总结
在本文中,我们对神经机器翻译模型和符号化知识库之间的关系展开研究,提出根据局部准确性和知识边界指标判断NMT模型的潜在缺陷,并发现NMT模型在知识边界值小的情况下常常出现翻译错误。基于以上分析,我们进一步提出了一种安全可靠的知识库剪枝算法PLAC。实验结果表明,我们的剪枝算法可以在不损害翻译性能的情况下,去除最多45%的知识库条目。出色的剪枝效果也说明局部准确性能够准确NMT模型的潜在缺陷和知识库条目的价值。
-
cpu
+关注
关注
68文章
10929浏览量
213452 -
模型
+关注
关注
1文章
3393浏览量
49367 -
机器翻译
+关注
关注
0文章
139浏览量
14971
原文标题:ACL2023 | 为k近邻机器翻译领域自适应构建可解释知识库
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
面向对象的汽车制动系专家系统及其知识库的构建
机器翻译三大核心技术原理 | AI知识科普
机器翻译三大核心技术原理 | AI知识科普 2
神经机器翻译的方法有哪些?
基于知识库的智能策略翻译技术
一种基于解释的知识库综合
本体知识库的模块与保守扩充
本体知识库的构建
阿里巴巴机器翻译在跨境电商场景下的应用和实践
从冷战到深度学习,机器翻译历史不简单!
机器翻译中细粒度领域自适应的数据集和基准实验
机器翻译研究进展
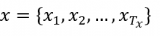





 工商网监
工商网监
评论