 基于NeRF的隐式GAN架构
基于NeRF的隐式GAN架构
3D对象的生成模型在VR和增强现实应用中越来越受欢迎。但使用标准的3D表示(如体素或点云)来训练这些模型是具有挑战性的,并且需要复杂的工具来进行适当的颜色渲染。神经辐射场(NeRF)在从一小部分2D图像合成复杂3D场景的新视图方面提供了最先进的质量。
作者提出了一个生成模型HyperNeRFGAN,它使用超网络范式来生成由NeRF表示的三维物体。超网络被定义为为解决特定任务的单独目标网络生成权值的神经模型。基于GAN的模型,利用超网络范式将高斯噪声转换为NeRF的权重。通过NeRF渲染2D新视图,并使用经典的2D判别器以隐式形式训练整个基于GAN的结构。
提出了基于NeRF的隐式GAN架构——第一个用于生成高质量3D NeRF表示的GAN模型。与基于 SIREN 的架构相比,利用NeRF的超网络范式可以获得更好的3D表示质量。该模型允许从无监督的2D图像合成3D感知图像。
笔者个人体会
这篇论文的动机是提出一种从2D图像生成高质量的3D物体的新方法,并且使用NeRF(Neural Radiance Fields)表示来重建物体的3D结构,以填补现有研究中的空白并解决传统方法的局限性。NeRF是一种基于神经网络的表示方法,可以通过从不同视角观察的2D图像重建出完整的3D物体。
传统的方法通常需要大量的3D训练数据或者深度信息,但这些数据往往难以获取或者成本较高。而作者的方法可以利用2D图像生成3D物体,无需额外的深度信息或大量的3D数据集,从而降低了数据收集的难度和成本。
此外,NeRF表示能够捕捉到物体的细节和视角变化,生成的3D物体具有高质量和准确性。
论文的核心创新是结合了HyperNetworks和NeRF的思想,提出了HyperNeRFGAN模型,将NeRF表示作为生成3D物体的基础,并利用HyperNetworks生成NeRF网络的权重,以实现从2D图像到3D物体的映射。
HyperNetworks是一种可以生成神经网络权重的神经网络,它可以用来生成NeRF网络的权重。通过HyperNeRFGAN,可以从输入的高斯噪声生成NeRF网络的权重,进而重建出相应的3D物体。
NeRF表示能够提供准确的3D物体重建,而HyperNetworks则提供了生成NeRF网络权重的有效方式。通过结合两者,作者能够将2D图像与3D物体之间的映射关系建立起来,并实现从2D图像生成高质量的3D物体。
架构设计:
使用NeRF作为3D物体的表示,它可以通过神经网络从2D图像中重建出物体的3D结构。
利用HyperNetworks生成NeRF网络的权重,以在生成过程中动态调整网络的参数。
模块设计:
生成器:使用HyperNetworks生成NeRF网络的权重,该生成器接受高斯噪声作为输入,并输出NeRF网络的权重。通过从噪声向量中生成网络的权重来实现动态调整网络参数的能力。
NeRF网络:接受空间位置作为输入,并输出物体的颜色和密度信息。通过学习从2D图像到3D物体的映射关系,可以重建物体的颜色和密度信息。
鉴别器:使用StyleGAN2架构作为鉴别器,用于区分真实图像和生成图像的差异。鉴别器使用对抗学习的思想,通过训练来学习将真实图像与生成图像区分开来的能力。
设计原理:
NeRF表示:NeRF网络通过从2D图像中学习生成物体的3D表示,能够实现高质量的物体重建。
HyperNetworks:HyperNetworks是一个生成网络权重的方法,它可以根据输入的噪声来生成网络的参数,使得网络可以根据不同的输入生成不同的结果。
实现过程:
训练阶段:使用未标记的2D图像和StyleGAN2鉴别器进行训练。生成器通过对噪声向量进行采样和变换来生成NeRF网络的权重。生成的2D图像被用作鉴别器的 "fake" 图像,生成器的目标是欺骗鉴别器。
生成阶段:在生成阶段,使用生成器生成NeRF网络的权重,然后使用NeRF网络从2D图像中重建出3D物体。
该方法的好处包括:
无需额外的深度信息或大量的3D数据集,只需要2D图像即可生成3D物体,降低了数据收集的难度和成本。
NeRF表示能够捕捉到物体的细节和视角变化,生成的3D物体具有高质量和准确性。
使用HyperNetworks生成NeRF网络的权重,可以灵活地生成不同的3D物体,具有较强的泛化能力。
模型结构简单且适用于三维物体训练,生成过程直接、高效。
摘要
最近,3D对象的生成模型在VR和增强现实应用中越来越受欢迎。
使用标准的3D表示(如体素或点云)来训练这些模型是具有挑战性的,并且需要复杂的工具来进行适当的颜色渲染。
为了克服这一限制,神经辐射场(NeRF)在从一小部分2D图像合成复杂3D场景的新视图方面提供了最先进的质量。
在本文中,作者提出了一个生成模型HyperNeRFGAN,它使用超网络范式来生成由NeRF表示的三维物体。
我们的GAN架构利用超网络范式将高斯噪声转换为NeRF模型的权重。该模型进一步用于呈现2D新视图,并使用经典的2D鉴别器来训练整个基于GAN的结构。
我们的架构产生2D图像,但我们使用3D感知的NeRF表示,这迫使模型产生正确的3D对象。
该模型相对于现有方法的优势在于,它为对象生成专用的NeRF表示,而无需共享呈现组件的某些全局参数。在来自不同领域的三个具有挑战性的数据集上,展示了与参考基线相比,作者的方法的优越性。
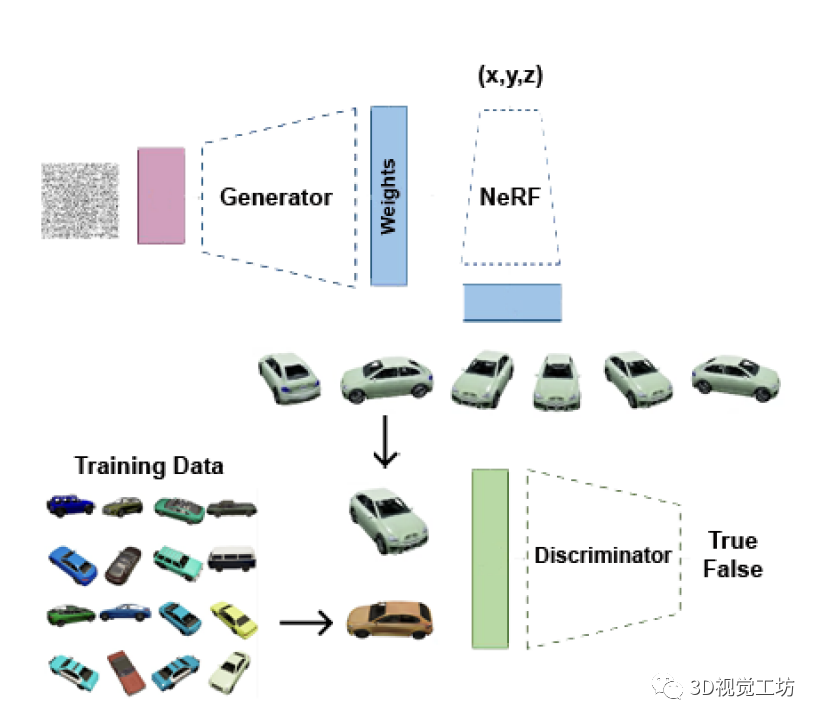
图1 HyperNeRFGAN架构利用超网络范式将高斯噪声转化为NeRF模型的权重。
在此基础上,利用NeRF渲染二维新视图,并使用经典的二维鉴别器。
架构产生2D图像,但作者使用3D感知的NeRF表示,这迫使模型产生正确的3D对象。
一、引言
生成对抗网络(Generative Adversarial Nets, GANs)使我们能够生成高质量的2D图像。另一方面,为3D对象保持类似的质量是具有挑战性的。这主要是由于使用3D表示(如体素和点云) 需要大量的深层架构,并且在真正的颜色渲染方面存在问题。
我们可以通过直接在 2D 图像空间上操作来解决这个问题。
我们希望我们的方法能够从未标记的2D视图中提取信息以获得3D形状。
为了获得这样的效果,我们可以使用神经辐射场(NeRF),它允许从一小部分2D图像合成复杂3D场景的新视图。
基于这些基础图像与计算机图形学原理(如光线追踪)之间的关系,该神经网络模型可以从以前未见过的视点渲染高质量的3D物体图像。
不幸的是,如何在 GAN 类型架构中使用NeRF表示并不是容易解决的。
最具挑战性的问题与NeRF的调节机制有关。因此,大多数模型使用SIREN而不是NeRF,我们可以自然地添加条件。但是3D物体的质量却比NeRF差。
在GRAF和π-GAN中,作者提出一个使用SIREN和调节作用机制产生隐式表征的模型。这样的解决方案给出了有希望的结果,但如何在这样的解决方案中使用NeRF而不是SIREN并不是容易解决的。
在图2中,对模型、GRAF和π-GAN进行了定性比较。正如我们所看到的,我们的模型可以模拟玻璃的透明度。
在本文中,作者提出了一种称为HyperNeRFGAN的生成模型,它结合了超网络范式和NeRF表示。
超网络被定义为为解决特定任务的单独目标网络生成权值的神经模型。基于GAN的模型,利用超网络范式将高斯噪声转换为NeRF的权重(见图1)。
之后,通过NeRF渲染2D新视图,并使用经典的2D判别器以隐式形式训练整个基于GAN的结构。
我们的架构产生2D图像,但我们使用3D感知的NeRF表示,这迫使模型产生正确的3D对象。
本文的贡献包括:
作者介绍了基于NeRF的隐式GAN架构——第一个用于生成高质量3D NeRF表示的GAN模型。
作者表明,与基于 SIREN 的架构相比,利用NeRF的超网络范式可以获得更好的3D表示质量。
作者的模型允许从无监督的2D图像合成3D感知图像。

图2 HyperNeRFGAN与HoloGAN、GRAF、π-GAN在CARLA上的比较。得到了与π-GAN相似的结果,但作者有更好的FID评分值,见表2。
二、相关背景
神经表示和渲染
3D物体可以使用许多不同的方法来表示,包括体素网格、八树网格、多视图图像、点云、几何图像、可变形网格和基于部件的结构图。上述表示是谨慎的,这在实际应用中会引起一些问题。相反,我们可以将三维物体表示为连续函数。
在实践中,隐性占用,距离场和表面参数化模型使用神经网络来参数化3D对象。
在这种情况下,我们没有固定数量的体素、点或顶点,而是将形状表示为连续函数。
这些模型受限于对 ground truth 三维几何的访问要求。隐式神经表征(NIR)被提出来解决这一问题。这种架构可以从多视图二维图像中重建三维结构。两种最重要的方法是NeRF和SIREN。
NeRF使用体渲染来重建3D场景,使用神经辐射和密度场来合成新的视图。
SIREN用调制频率的正弦函数取代了流行的ReLU激活函数。
大多数NeRF和基于SIREN的方法专注于单个3D对象或场景。
在实践中,我们过拟合单个对象或场景。在论文中,作者专注于生成以NeRF表征的3D模型。
单视图监督的 3D 感知 GAN
生成对抗网络(Generative Adversarial Nets, GANs)可以生成高质量的图像。然而,GAN在二维图像上运行,而忽略了我们物理世界的三维本质。因此,利用物体的三维结构来生成图像和三维物体是很重要的。
3D感知图像合成的第一种方法,如Visual Object Networks和 prGAN,首先使用3D- GAN生成体素化的3D形状,然后将其投影到2D中。
hooloGAN和BlockGAN在类似的融合中工作,但使用隐式3D表示来建模世界的3D表示。不幸的是,使用显式的体积表示限制了它们的分辨率。
在[36]中,作者提出使用网格来表示三维几何。另一方面,文献[15]使用基元集合进行图像合成。
在GRAF和π-GAN中,作者使用隐式神经辐射场生成3D感知图像和几何图形。
在作者的工作中,使用NeRF代替SIREN,使用超网络范式代替条件反射过程。
在ShadeGAN中,作者使用了阴影引导的pipeline;
在GOF中,他们逐渐缩小了每条相机光线的采样区域。
而在CIRAFFE种,首先生成低分辨率的特征图。
在第二步中,将表示传递给2D CNN,以生成更高分辨率的输出。
在StyleSDF中,作者将基于SDF的3D表示与用于图像生成的StyleGAN2合并。
在[1]中,作者使用StyleGAN2生成器和三维物体的三平面表示。
这些方法在生成对象的质量上优于其他方法,但极难训练。
超网络+生成建模
超网络和生成模型的结合并不新鲜。
在[29,8]中,作者构建了GAN来生成用于回归或分类任务的神经网络的参数。
HyperVAE通过生成给定分布样本的生成模型参数,对任意目标分布进行编码。
HCNAF是一个超网络,产生了条件自回归流动模型的参数。
在[34]中,作者提出INR-GAN使用超网络生成图像的连续表示。该超网络可以通过因数乘调制的低成本机制来修改共享权值。

图3 在ShapeNet的三种类型(汽车、飞机、椅子)上由模型训练生成的元素。
三、HyperNeRFGAN: 用于生成NeRF表示的超网络
在本节中,介绍了HyperNeRFGAN——一种用于3D对象的新型生成模型。该方法的主要思想是将生成器作为一个超网络,将从已知分布中采样的噪声向量转换为目标模型的权值。
与以往的作品相比,目标模型采用NeRF对对象进行三维表示。因此,可以以可控的方式从不同角度生成物体的许多图像。
此外,由于基于NeRF的图像渲染,与基于GAN的复杂3D结构模型相比,鉴别器可以在从多个角度生成的2D图像上运行。
超网络
超网络中介绍的超网络被定义为神经模型,用于预测为解决特定任务而设计的不同目标网络的权重。
与使用单个嵌入将附加信息注入目标模型的标准方法相比,这种方法减少了可训练参数的数量。可以实现目标模型大小的显著减小,因为它不共享全局权重,但它们由超网络返回。
sheikh 作者将超网络和生成模型进行了类比,使用这种机制来生成一组近似相同函数的不同目标网络。
超网络广泛应用于许多领域,包括 few-shot 问题或概率回归场景。各种方法也使用它们来生成3D对象的连续表示。
例如,HyperCloud 将3D点云表示为一个经典的MLP,作为目标模型,并将点从高斯球上的均匀分布转换为代表所需形状的点云。
在spurek 中,目标模型由连续归一化流(Continuous Normalizing Flow) 表示,这是一种生成模型,它根据假定的三维空间中的基本分布创建点云。
GAN
GAN 是一个使用极大极小博弈来训练深度生成模型的框架。目标是学习一个与实际数据分布 匹配的生成器分布 。
GAN学习一个生成器网络 ,通过将噪声变量 (通常是高斯噪声 ) 转换为样本 ,从生成器分布 中产生样本。
生成器通过对抗一个对抗鉴别器网络来学习,目的是区分真实数据分布 和生成器分布 的样本。
更正式地说,极大极小博弈由下式给出:
与其他方法相比,它的主要优点是产生与真实图像难以区分的清晰图像。
从模型中采样的图像的视觉质量方面,GAN令人印象深刻,但训练过程通常具有挑战性和不稳定性。
这种现象的产生是由于训练目标的直接优化难以实现,通常是通过交替优化鉴别器和生成器的参数来训练模型。
近年来,许多研究人员致力于改进传统的GAN过程,以提高训练过程的稳定性。
一些改进是基于将目标函数改为WGAN (WGAN) 、梯度惩罚限制、谱归一化或生成器和判别器的不平衡学习率。
通过利用自注意力机制(SAGAN)和逐步增长的ProGAN、style-GAN架构(StyleGAN ),对模型架构进行了更深入的探索。
INR-GAN
隐式神经表示GAN是基于GAN的模型的一种变体,它利用超网络为目标模型生成参数,而不是直接生成图像。
由简单MLP表示的目标模型以RGB格式返回给定像素位置的颜色。
该模型在架构上非常接近StyleGAN2,并且比直接方法具有明显的优势,主要是因为使用INR-GAN可以在不假设任意给定分辨率的情况下生成图像。
3D对象的NeRF表示
NeRF表示使用全连接架构的场景。NeRF以5D坐标(空间位置 ,观察方向 作为输入,输出发射颜色 和体积密度 。
NeRF使用一组图像进行训练。在这种情况下,我们产生许多光线通过图像和由神经网络表示的3D对象。NeRF用MLP网络近似这个3D对象:
并优化其权重,将每个输入5D坐标映射到相应的体积密度和方向发射颜色。
NeRF的丢失受到经典体渲染的启发。渲染通过场景的所有光线的颜色。体积密度 可以解释为射线的微分概率。相机射线 的期望颜色 (其中o为射线原点,d为方向)可以用积分计算。
在实际中,这个连续积分是用求积分法在数值上估计的。我们使用分层抽样方法,将射线 划分为个均匀间隔的 bins,然后从每个 bin 内均匀随机抽取一个样本:
我们使用这些样本来估计 ,使用Max在体积渲染中讨论的正交规则:
,
其中,
其中 为相邻样本间的距离。
从 值的集合计算 的函数是平凡可微的。
然后,我们使用体渲染过程来渲染来自两组样本的每条光线的颜色。与基线NeRF相反,其中两个“粗”和“细”模型同时训练,我们只使用“粗”架构。
3.1 HyperNeRFGAN
在这项工作中,作者提出了一种新的GAN架构,HyperNeRFGAN,用于生成3D表示。所提出的方法利用INR-GAN,隐式方法来生成样本。
与使用MLP模型创建输出图像的标准INR-GAN架构相比,假设使用NeRF模型作为目标网络。由于这种方法,生成器通过传递特定的NeRF参数来创建场景或对象的特定3D表示。
模型架构,如图1所示。
生成器 从假定的基本分布(高斯分布)中获取样本,并返回一组参数 。
这些参数在NeRF模型 中进一步使用,将空间位置 转换为发射颜色 和体积密度 。
没有使用标准的线性架构,而是使用因数乘调制(FMM)层。
输入尺寸为 ,输出尺寸为 的FMM层定义为:
其中 W 和 b 是在三维表示中共享参数的矩阵,A, b是由生成器创建的形状分别为 的两个调制矩阵。
参数 k 控制着 的秩。
值越高,FMM层的表达能力越强,但也会增加超网络所需的内存量。
我们设置为 。
INR模型 是基准NeRF的简化版本。为了减少训练的计算成本,我们没有像原始NeRF那样优化两个网络。
我们没有使用较大的“精细”网络,只使用较小的“粗糙”网络。
此外,我们通过将每个隐藏层中的通道数量从 256 个减少到 128 个来减小“粗”网络的大小。
在一些实验中,我们还将层数从8层减少到4层。

图4 用ShapeNet(前三行)和CARL数据集(最后两行)的汽车、飞机和椅子图像训练的模型生成的线性插值示例。

图5 在CARLA上训练的模型的例子。
我们与基线NeRF在另一个方面有所不同,因为我们不使用视图方向。
这是因为用于训练的图像没有像反射这样的依赖于视图的特征。
即使在我们的架构中没有使用视图方向,也没有理由不能将其用于将从中受益的数据集。
我们的NeRF是一个单一的MLP,它只接受空间位置作为输入:
在这项工作中,我们利用StyleGAN2架构,遵循INR-GAN的设计模式。整个模型使用StyleGANv2目标以与INR-GAN相似的方式进行训练。
在每次训练迭代中,使用生成器对噪声向量进行采样和变换,得到目标NeRF模型 的权值。进一步利用目标模型从不同角度渲染二维图像。
生成的2D图像进一步作为鉴别器的 fake 图像,生成器G的作用是创建3D表示渲染2D图像,欺骗鉴别器。
鉴别器旨在从数据分布中区分假渲染和真实的2D图像。

图6 在CARLA数据集上训练的模型和在ShapeNet的飞机和椅子上训练的模型生成的网格。
四、实验
在本节中,首先评估了HyperNeRFGAN生成3D物体的质量。使用的数据集包含从ShapeNet获得的3D物体的2D图像。
该数据集包含来自平面、椅子和汽车类的每个元素的50张图像。这是最适合我们目的的数据集,因为每个对象都有每个元素的一些图像。
然后使用包含汽车图像的CARLA。在这种情况下,每个物体只有一张图像,但仍然有物体四面八方的照片。可以制作完整的3D物体,可以用于虚拟现实或增强现实。
最后,使用了包含人脸的经典CelebA数据集。从3D生成的角度来看,这是具有挑战性的,因为我们只有脸部的正面。在实践中,基于3D的生成模型可用于3D感知图像合成。
4.1 从ShapeNet生成3D对象
在第一个实验中,使用ShapeNet基础数据集,其中包含来自平面、椅子和汽车类的每个元素的50张图像。这种表示对于训练3D模型来说是完美的,因为每个元素都可以从许多角度看到。数据取自[42],作者训练了一个基于自动编码器的生成模型。
在图3中,展示了从我们的模型生成的对象。
在图4中,也给出了对象的线性插值。可以看到,物品的质量非常好,见表1。
表1 基于FID的HyperNeRFGAN与基于自编码器的模型的比较。GAN与自编码器和GAN之间的比较是困难的。但我们可以获得更好的FID评分。

4.2 从CARLA数据集生成三维物体
在第二个实验中,我们将基于CARLA数据集的模型与其他基于GAN的模型: HoloGAN、GRAF和πGAN进行了比较。
CARLA包含汽车图像。每个物体只有一张图像,但我们仍然有物体四面八方的照片。因此,全3D对象可以用于VR或增强现实。
在图2中给出了视觉对比。如图5所示,我们可以有效地模拟汽车玻璃的透明度。
在表2中,给出了Frechet Inception Distance (FID)、Kernel Inception Distance (KID)和Inception Score (IS)的数值比较。可以看出,我们得到了比π-GAN模型更好的结果。
在NeRF表示的情况下,我们可以生成网格,见图6。
表2 CARLA 数据集上的FID, KID 和 IS。

4.3从CelebA合成3D感知图像
在作者的第三个实验中,通过将设置更改为人脸生成,进一步比较了与第二个实验相同的模型。
对于这项任务,我们使用CelebA数据集,该数据集包含10,000名不同名人的200,000张高分辨率人脸图像。
我们将图像从头发的顶部裁剪到下巴的底部,并将其大小调整为 的分辨率,就像π-GAN作者所做的那样。
在表3中给出了定量结果。可以看到,HyperNeRFGAN和π-GAN实现了相似的性能,如图7所示。
表3 CelebA数据集的FID, KID mean×100和IS。

五、总结
在这项工作中,作者提出了一种从2D图像生成NeRF表示的新方法。模型利用了超网络范式和3D场景的NeRF表示。
HyperNeRFGAN接受高斯噪声并返回NeRF网络的权重,NeRF网络可以从2D图像中重建3D物体。
在训练中,作者只使用未标记的图像和StyleGAN2鉴别器。与现有的方法相比,这种表示有几个优点。
首先,可以在GAN类型算法中使用NeRF代替SIREN表示。
其次,模型简单,可以在三维物体上进行有效的训练。
最后,模型直接生成NeRF对象,而不共享渲染组件的一些全局参数。
责任编辑:彭菁
-
3D
+关注
关注
9文章
2875浏览量
107473 -
GaN
+关注
关注
19文章
1933浏览量
73277 -
模型
+关注
关注
1文章
3226浏览量
48804
原文标题:3D 对象生成 | NeRF+GAN的超网络:HyperNeRFGAN
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
华人团队打造专为GAN量身定制架构搜索方案AutoGAN
基于NTFS的最小侵入式隐写系统
基于显式与隐式反馈信息的矩阵分解
结合显式和隐式特征交互的融合模型
Block nerf:可缩放的大型场景神经视图合成
从多视角图像做三维场景重建 (CVPR'22 Oral)
了解NeRF 神经辐射场


NeurlPS'23开源 | 大规模室外NeRF也可以实时渲染

全面总结动态NeRF





 工商网监
工商网监
评论