 2023北京智源大会亮点回顾 | 高性能计算、深度学习和大模型:打造通用人工智能AGI的金三角
2023北京智源大会亮点回顾 | 高性能计算、深度学习和大模型:打造通用人工智能AGI的金三角

AIGC| Aquila | HuggingFace
AGI | DeepMind |Stability AI
通用人工智能(AGI)是人工智能领域的最终目标,也是一项极具挑战性的任务。在诸多技术(深度学习、高性能计算、大模型训练以及ChatGPT等)的支持下,AGI的实现正在逐步向前推进。与目前的弱人工智能不同,AGI是一种能够像人类一样进行思考、学习和解决问题的智能系统。它可以理解和应对各种不同的情境,并能够自主地学习和适应新的环境。实现AGI需要克服许多技术和理论上的挑战,例如如何让计算机具有自我意识和情感,以及如何处理复杂的语言和语境。一旦实现了AGI,将会对人类社会产生深远的影响,甚至可能改变我们所理解的本质。
北京智源大会于6月10日圆满闭幕,OpenAI、DeepMind、Anthropic、HuggingFace、Midjourney、Stability AI等多位明星团队及Meta、谷歌、微软等知名大厂和斯坦福、UC伯克利、MIT等顶尖学府出席,共同探讨人工智能发展。图灵奖得主Yann LeCun、Geoffrey Hinton以及OpenAI创始人Sam Altman的演讲更是推动大会气氛到了高潮,展现专业深度与创意启发兼具的魅力。
智源研究院院长黄铁军在演讲中提到,要实现通用人工智能(AGI),有三条技术路线:第一是“大数据+自监督学习+大算力”形成的信息类模型;第二是具身智能,即基于虚拟世界或真实世界、通过强化学习训练出来的具身模型;第三是脑智能,直接“抄自然进化的作业”,复制出数字版本的智能体。
OpenAI的GPT(生成式预训练Transformer模型)就遵循第一条技术路线;以谷歌DeepMind的DQN(深度Q网络)为核心取得的一系列进展即基于第二条技术路线。黄铁军表示,智源期望从“第一性原理”出发,通过构建一个完整的智能系统AGI,从原子到有机分子、到神经系统、到身体,实现通用人工智能。这是一个大概需要20年时间才能实现的目标。
小编将总结智源大会亮点,让我们一起来看吧。
智源大会亮点总结
一、Geoffrey Hinton:超级AI风险紧迫
图灵奖得主、深度学习之父Hinton在主题演讲中提出值得深思的问题:“人工神经网络是否比真正的神经网络更聪明?”Hinton曾就职谷歌,直言对自己毕生工作感到后悔,并对人工智能危险感到担忧。
他多次公开称,人工智能对世界的危险比气候变化更加紧迫。在演讲中,再次谈及AI风险。如果一个在多台数字计算机上运行的大型神经网络,除了可以模仿人类语言获取人类知识,还能直接从世界中获取知识,会发生什么情况呢?
显然,它会变得比人类优秀得多,因为它观察到了更多的数据。这种设想并不是天方夜谭。如果这个神经网络能够通过对图像或视频进行无监督建模,并且它的副本也能操纵物理世界,那么在最极端的情况下,不法分子会利用超级智能操纵选民,赢得战争。如果允许超级智能自行制定子目标,一个子目标是获得更多权力,这个超级AI就会为了达成目标,操纵使用它的人类。

二、智源研究院理事长张宏江与Sam Altman巅峰问答:AGI或将十年内出现
Sam Altman通过视频连线现身,这是ChatGPT爆火之后首次在中国公开演讲。他强调了全球AI安全对齐与监管的必要性,特别是随着日益强大的AI系统的出现,加强国际间的通力合作,建立全球信任尤为重要。Altman还提到,对齐仍是一个未解决的问题,GPT-4在过去8个月时间完成对齐工作,主要包括扩展性和可解释性。他引用了《道德经》中的一句话:“千里之行,始于足下”,强调了推进AGI安全和加强国际间的通力合作的重要性。
Altman认为,国际科技界合作是当下迈出建设性步伐的第一步应该提高在AGI安全方面技术进展的透明度和知识共享机制。OpenAI的主要研究目标集中在AI对齐研究上,即如何让AI成为一个有用且安全的助手。一是可扩展监督,尝试用AI系统协助人类监督其他人工智能系统。二是可解释性,尝试理解大模型内部运作“黑箱”。最终,OpenAI的目标是训练AI系统来帮助进行对齐研究。
在隔空对话中,张宏江和Sam Altman一起探讨了如何让AI安全对齐的难题。当被问及OpenAI是否会开源大模型时,Altman称未来会有更多开源,但没有具体模型和时间表。他还表示不会很快有GPT-5。

三、LeCun:依然是世界模型的拥趸
图灵奖得主卷积神经网络之父LeCun继续推行自己的“世界模型”理念。对于AI毁灭人类的看法,LeCun认为这种担心实属多余,因为如今的AI还不如一条狗的智能高,还没有发展出真正的人工智能。他认为,构建人类水平AI的关键,可能就是学习“世界模型”的能力。“世界模型”由六个独立模块组成:配置器模块、感知模块、世界模型、Cost模块、Actor模块、短期记忆模块。他认为,为世界模型设计架构以及训练范式,才是未来几十年阻碍人工智能发展的真正障碍。
LeCun解释道,AI不能像人类和动物一样推理和规划,部分原因是目前的机器学习系统在输入和输出之间的计算步骤基本恒定。如何让机器理解世界如何运作,像人类一样预测行为后果,或将其分解为多步来计划复杂的任务呢?显然,自监督学习是一个路径。相比强化学习,自监督学习可以产生大量反馈,预测其输入的任何一部分。
LeCun确定未来几年人工智能的三大挑战,就是学习世界的表征、预测世界模型、利用自监督学习。被问到AI系统是否会对人类构成生存风险时,LeCun表示,我们还没有超级AI,何谈如何让超级AI系统安全呢?

四、悟道·天鹰(Aquila):全面开放商用许可
悟道·天鹰(Aquila)系列大模型首次亮相,首个具备中英双语知识,支持国内数据合规需求的开源语言大模型。该系列大模型已经全面开放商用许可,并开源了包括70亿参数和330亿参数的基础模型、AquilaChat对话模型,以及AquilaCode“文本-代码”生成模型。

1、性能更强
Aquila基础模型(7B、33B)继承了GPT-3、LLaMA等的架构设计优点,并替换了一批更高效的底层算子实现、重新设计实现了中英双语的tokenizer,升级了BMTrain并行训练方法。在训练过程中,智源实现了比Magtron+DeepSpeed ZeRO-2将近8倍的训练效率。这得益于智源去年大模型算法开源项目FlagAI,集成了BMTrain这样新的并行训练方法,优化计算和通信以及重叠的问题。此外,智源率先引入算子优化技术,将其与并行加速方法集成,进一步提升性能。
2、中英双语的大模型
悟道·天鹰(Aquila)的发布非常值得鼓舞,因为很多大模型只学习英文,但悟道·天鹰(Aquila)需要同时学习中文和英文,训练难度提升了很多倍。为了让悟道·天鹰(Aquila)针对中文任务达到优化,智源放了将近40%的中文语料在训练语料中。智源还重新设计实现了中英双语的tokenizer(分词器),以更好地识别和支持中文的分词。
在训练和设计的过程中,智源团队特意权衡质量和效率两个维度决定分词器大小。悟道·天鹰(Aquila)基础模型底座上打造AquilaChat对话模型(7B、33B)支持流畅的文本对话及多种语言类生成任务。通过定义可扩展的特殊指令规范,可以实现AquilaChat对其它模型和工具的调用,且易于扩展。AquilaCode-7B“文本-代码”生成模型基于Aquila-7B强大的基础模型能力,以小数据集、小参数量、高性能实现了中英双语的开源代码模型。AquilaCode-7B在英伟达和***上完成了代码模型的训练,并通过对多种架构的代码+模型开源,推动芯片创新和百花齐放。

3、更合规、更干净的中文语料
悟道·天鹰(Aquila)最鲜明的特点就在于支持国内数据合规需求。相比国外的开源大模型,悟道·天鹰(Aquila)使用的中文数据更加满足合规需要,更加干净。智源的目标是打造一整套大模型进化迭代流水线,让大模型在更多数据和更多能力的添加之下,源源不断地成长,并且会持续开源开放。悟道 · 天鹰(Aquila)在消费级显卡上就可用,比如7B模型就能在16G甚至更小的显存上跑起来。
AGI过去、现在及未来发展
要预知未来,先了解过去。AGI是DeepMind率先引入大众视野并通过其努力引发整个世界关注的AI终极方向。
一、什么是AI、AGI、AIGC、ChatGPT?
1、AI
人工智能(AI)是指由人制造出来的机器所表现出来的智能,通过普通计算机程序来呈现人类智能的技术。人工智能涵盖了很多不同的领域和技术,同时也指研究这样的智能系统是否能够实现,以及如何实现。
2、AGI
通用人工智能(Artificial General Intelligence, AGI)又称“强人工智能(Strong AI)”“完全人工智能(Full AI)”,是具有一般人类智慧,可以执行人类能够执行的任何智力任务的机器智能。通用人工智能是一些人工智能研究的主要目标,也是科幻小说和未来研究中的共同话题。与弱人工智能相比,通用人工智能可以尝试执行全方位的人类认知能力。
3、AIGC
人工智能生成内容(Artificial Inteligence Generated Content,缩写为AIGC),又称生成式AI,被认为是继专业生产内容(PGC)、用户生产内容(UGC)之后的新型内容创作方式。
互联网内容生产方式经历PGC——UGC——AIGC的过程。
PGC是专业生产内容,如Web1.0和广电行业中专业人员生产的文字和视频,其特点是专业,内容质量有保证;UGC是用户生产内容,伴随Web2.0概念而产生,特点是用户可以自由上传内容,内容丰富;AIFC是由AI生成的内容,其特点是自动化生产,高效。
随着自然语言生成技术NLG和AI模型的成熟,AIGC逐渐受到大家的关注,目前已经可以自动生成文字、图片、音频、视频,甚至3D模型和代码。AIGC极大的推动元宇宙的发展,元宇宙中大量的数字原生内容,需要由AI帮助完成创作。
4、ChatGPT
ChatGPT(Chat Generative Pre-trained Transformer)聊天生成预训练转换器,属于AIGC范畴。ChatGPT是OpenAI开发的人工智能聊天机器人程序,于2022年推出。ChatGPT目前仍以文字方式交互,而除了可以用人类自然对话方式来交互,还可以用于更为复杂的语言工作,包括自动生成文本,自动问答,自动摘要等多种任务。

二、2013-2022:AGI的简要发展史
2015年,Deepmind第一版的DQN,第一次将DL和RL结合,开启了AGI的实现道路。同年DeepMind的AlphaGo横空出世,实现了深度学习的全新里程碑。
2016年,OpenAI成立。
2018年,OpenAI 提出Dota Five,在Dota上战胜职业选手。
2019年,Deepmind提出AlphaStar,在星际争霸上战胜职业选手。同年,OpenAI实现了用机械手玩魔方。接下来的里程碑就转向了语言模型,图文生成及AI for Science。
2020年,OpenAI发布Image GPT,DeepMind发布AlphaFold-2。
2021年,OpenAI发布Dalle、GPT-3、Codex。
2022年,DeepMind发布AlphaCode,OpenAI发布Dalle-2、InstructGPT和ChatGPT。
上面列举的可能不全,但主要是OpenAI和DeepMind的工作。其他公司及学界也有很多不错的工作,但论影响力都达不到他们的高度。这两家公司都宣称要搞AGI,因此成为了关注的焦点。
三、AGI发展的背后缘由
看到了这么多的里程碑,他们之间有什么联系?实际上,这些发展都是在David Silver的PPT中提到的范式中进行的,只是在其中加入了IL(Imitation Learning)模仿学习,让关联更加紧密。
1、DL
DL主要指的是基于深度神经网络的一套学习训练方式,简单的说就是一个神经网络,一个损失函数,一个反向传播。
2、LeNet
深度学习的发展,网络变了,变成了以Transformer为主流的网络结构,但核心机制是完全没有变化的。
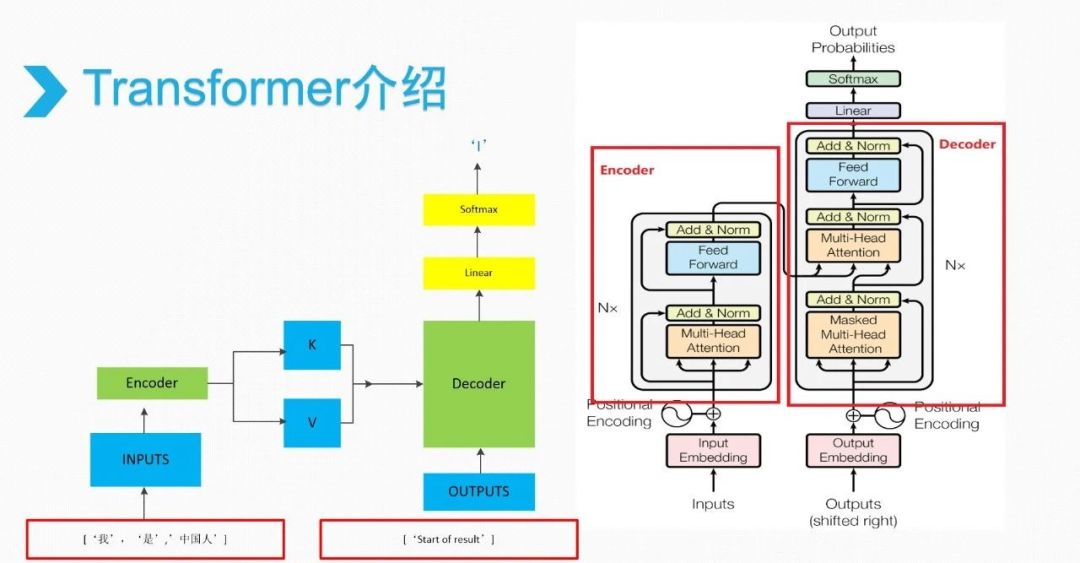
Transformer
IL和RL是构建损失函数训练神经网络的方法。IL模仿学习是指使用大量人类选手的数据来训练神经网络,以便让它们学习如何在特定领域中表现得像人类一样。例如,AlphaGo的第一代和AlphaStar都使用了大量围棋和星际争霸人类选手的数据来进行模仿学习。而GPT和ChatGPT则使用了大量的人类文本数据,通过自回归的方式来进行模仿学习。模仿学习的优点在于训练速度快,因为它提供了神经网络可以学习的大量数据。
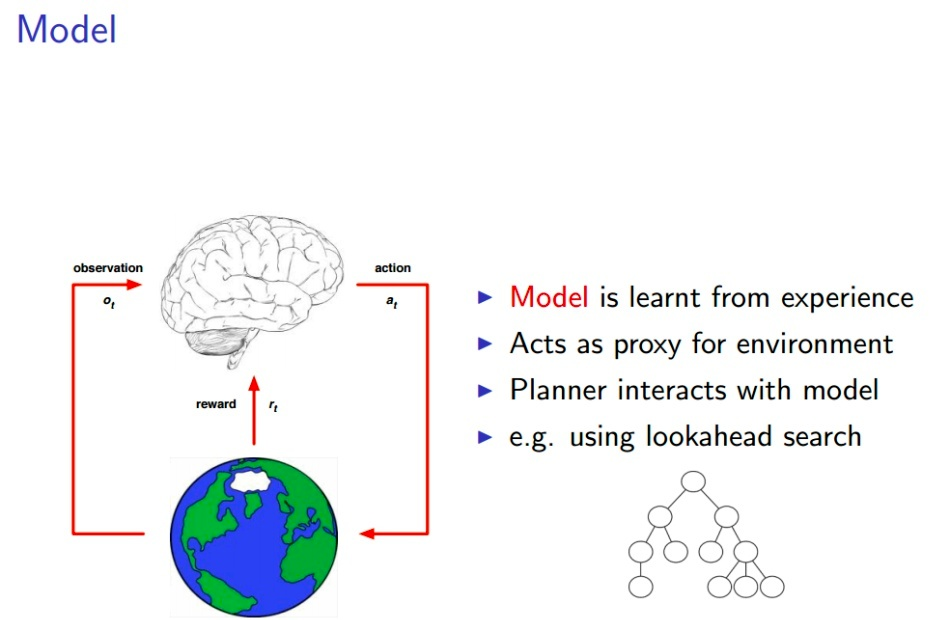
来自David Silver的ppt
实际上,人类的学习过程也是模仿学习和强化学习的结合。因此,所谓的AI就是模仿人类学习而构建的智能。AlphaGo在模仿学习后开始强化学习,水平可以吊打人类专业选手;AlphaStar在模仿学习后开始强化学习,能够战胜人类专业选手;ChatGPT在模仿学习后(GPT)使用人类反馈的信息进行强化学习,能够比较好地按照人类的指令来回答问题。这展示强化学习的威力。从某种程度上说,可以认为整个人类都是一个智能体,正在通过科学家做强化学习来拓展人类的文明边界。
为什么早期的AI里程碑都是限定场景,而之后就变成了像GPT这样的通用场景呢?
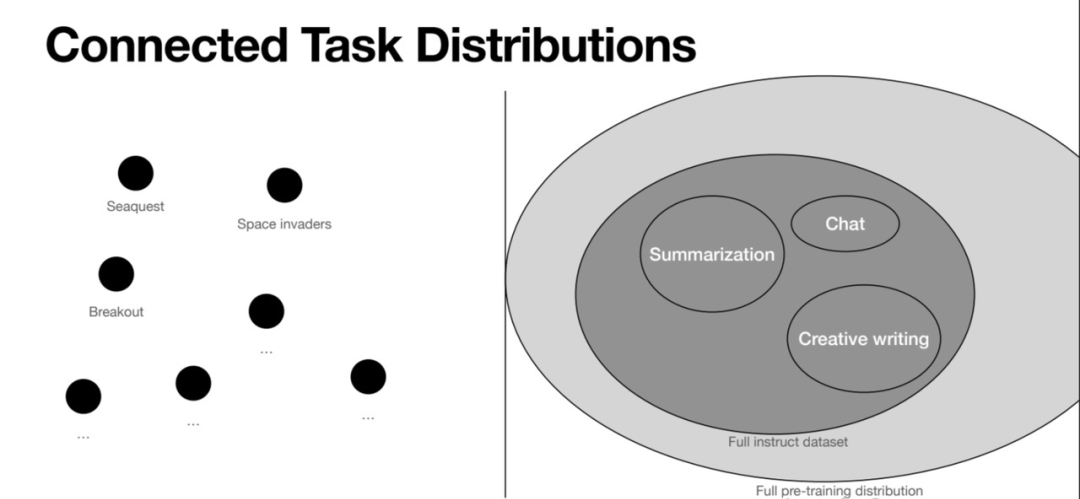
From John Schulman's PPT
早期的AI里程碑都是限定场景,因为限定场景的数据量太少,无法实现通用性。John Schulman(PPO和ChatGPT的作者)的这张图对比了之前的Atari等游戏场景和GPT场景在任务分布上的不同。游戏场景都是独立的,不同任务之间的差异也就是GAP非常大,所以AI学会一个游戏并不能让其会玩另一个游戏。而GPT的场景是文字世界,总结、写作、聊天都是联系在一起的,所以它们的任务有千千万,并且是连续的。使得GPT训练后具备很强的Few-Shot Learning/Meta Learning的能力,即能够实现非常强的泛化能力,面向全新的问题也能够回答。Meta Learning(元学习)也就是学会学习,这个概念在学术界2017、2018年后非常火,因为大家发现之前的AI都需要大量训练才能做新任务,而人类则具备快速学习的能力,因此AI也需要具备这样的能力。
GPT通过巨量的文本数据做模仿学习,InstructGPT通过巨量的任务文本数据做Instruct Finetuning,具备极强的快速学习能力。由此开创Prompt Engineering或者学术界叫In-Context Learning这个全新领域,即我们不再需要训练模型,只需要修改开头的输入Prompt,就能让AI快速学习并输出合理的结果。
OpenAI非常快地意识到文字世界这个场景拥有的数据量无与伦比,因此迅速转换赛道,关闭机器人组。这种决策令人十分钦佩。最近,DeepMind发布Ada,它仍然是游戏场景里的AI,但DeepMind也发现了原来Atari的任务空间分布差距太大的问题,因此改用自己构建的全新环境Xland进行大模型的训练。从另一个角度看,如果这个XLand未来能够变成真实世界,那么完全体的AGI也就有可能在其中诞生。因此,AGI的实现变成了一个时间问题。
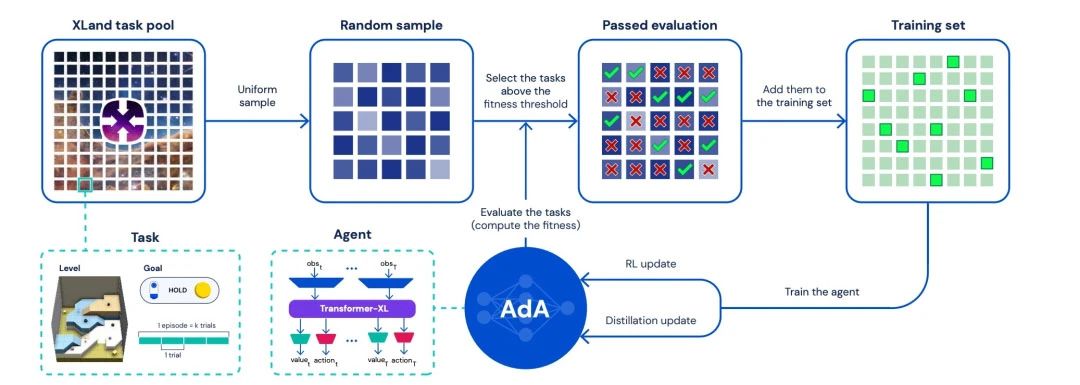
四、2023-2028: AGI会如何发展?
1、文字世界的精进,LLM从普通到专业
目前ChatGPT看起来很惊艳,似乎什么都懂,但实际上存在很多事实错误和逻辑错误,如果让它参加高考,除了英语,其他科目很难考高分。下一步的LLM需要变得更加专业,如通过高考考出985的水平,这样LLM就能成为一个真正有知识有文化的人,也意味着AI将完全通过图灵测试。GPT-4或许会给我们带来惊喜。
通过高考之后,下一步当然是专业领域的学习。LLM能否通过司法考试或公务员考试?是否能获得IMO或ACM的金牌?模仿学习之后,需要通过强化学习进行进一步的精进,这对于LLM在专业领域同样适用。例如在数学领域,现实世界中并没有那么多的数学难题可以模仿,需要通过强化学习来让LLM解决数学难题。如果可以,基于Transformer的网络架构还可以继续发展,否则就需要全新的架构来进一步突破。目前,DeepMind的AlphaCode团队正在探索这方面的问题,目前的算法仍然是模仿学习。
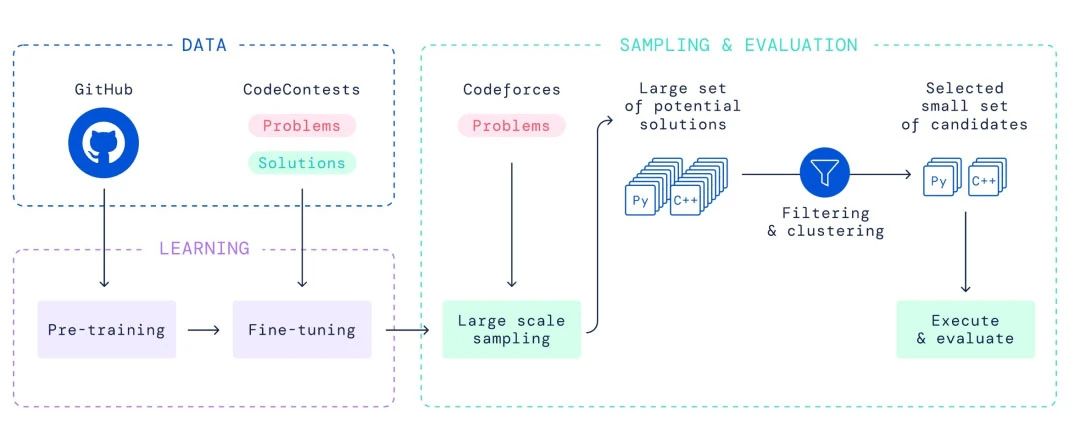
2、征服多模态的视频世界
相比文字世界,视频世界的数据量要大得多。人类从婴儿开始就是通过多模态的数据(当然还包括触觉、味觉、嗅觉等)来快速学习。如果AI能够实现很强的多模态学习能力,通过海量的视频进行学习,那么AI将会展现出令人难以置信的能力。
3、大模型连接现实世界,成为一个General Agent
Ada在一个小的虚拟世界中展现了其通用的决策能力,而ChatGPT则在文字世界中展现了强大的通用文字能力。然而,AGI不可能局限于文字或多模态,关键在于决策。这也是我们坚信RL是通往AGI的初始原因。因此,大型模型将作为一个Agent智能体出现,影响现实世界!
4、自动驾驶将全面转向大模型,并真正向L4、L5进发
自动驾驶是一个非常好的限定多模态场景,肯定会从大型模型的发展中受益。可以使用海量数据进行模仿学习,通过强化学习在仿真环境中进行优化,解决Corner Case,从而实现完全自动驾驶。甚至,可以基于一个多模态的大型模型来构建基础模型,这样不仅可以获得自动驾驶的能力,还获得一个能够与人聊天的自动驾驶司机。这正是科幻片中的自动驾驶汽车所展现的。
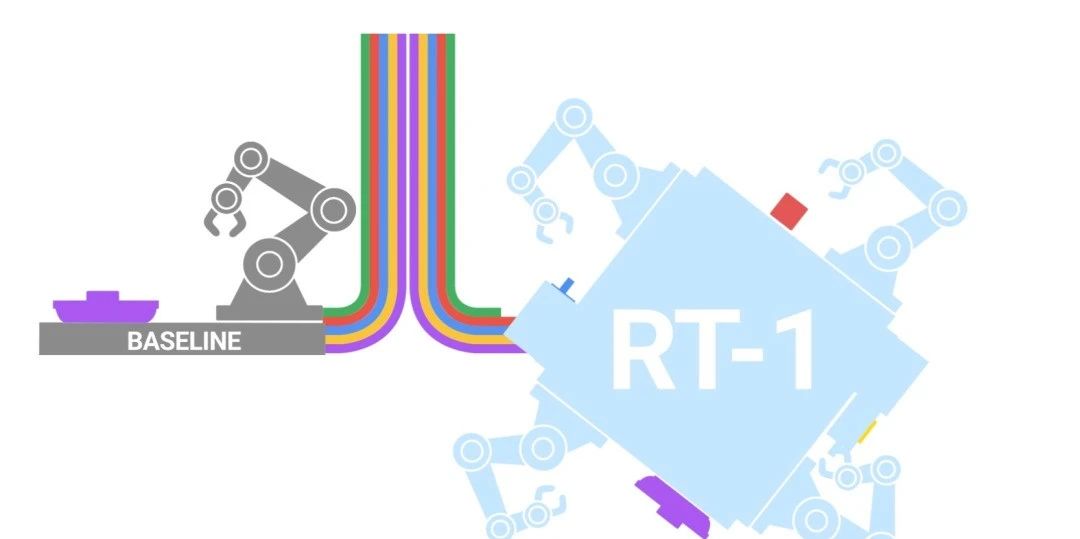
5、通用家用机器人将大幅发展,同样采用大模型
和自动驾驶类似,通用家用机器人也是一个限定的多模态场景,难度可能更大。Google的RT-1已经验证了大模型驱动机器人的模式是可行的。
接下来的核心还是数据!现实场景最大的问题就是数据。那么,如果前面基于视频的多模态学习能很好实现,那么人型机器人就非常好办,看无数的视频,然后映射到人形机器人的动作上。再通过仿真环境做强化学习来解决corner case,从而人型机器人将能实现大的突破,走入家庭在10年内不是梦!
6、自然语言成为新的编程语言

如果你Prompt足够多,一定也会有Andrej Karpathy一样的想法!所以,现在的小孩学编程可能意义不大,未来大部分人将直接通过自然语言编程和AI交互。
7、AI for Science将突飞猛进,越来越多科学领域被AI突破
刚看到微软发布的ClimaX,天气预测也是大模型加持。还有什么是大模型不能做的呢?
是否存在足够通用处理器完成AGI
一、AGI特征
1、涌现
“涌现”并不是一个新概念,凯文·凯利在他的《失控》中就提到了这一概念,指的是众多个体的集合会涌现出超越个体特征的某些更高级的特征。在大模型领域,“涌现”指的是当模型参数突破某个规模时,性能显著提升,并且表现出让人惊艳的、意想不到的能力,比如语言理解能力、生成能力、逻辑推理能力等等。
对于外行来说,涌现能力可以简单地用“量变引起质变”来解释:随着模型参数的不断增加,终于突破了某个临界值,从而引起了质的变化,让大模型产生了许多更加强大的、新的能力。如果想详细了解大模型“涌现”能力的详细分析,可以参阅谷歌的论文《Emergent Abilities of Large Language Models》。然而,目前,大模型发展还是非常新的领域,对“涌现”能力的看法也存在不同的声音。例如,斯坦福大学的研究者对大语言模型“涌现”能力的说法提出了质疑,认为其是人为选择度量方式的结果。
2、多模态
每一种信息的来源或者形式,都可以称为一种模态。例如,人有触觉、听觉、视觉等;信息的媒介有文字、图像、语音、视频等;各种类型的传感器,如摄像头、雷达、激光雷达等。多模态指从多个模态表达或感知事物。多模态机器学习指从多种模态的数据中学习并提升自身的算法。
传统的中小规模AI模型基本都是单模态的,例如专门研究语言识别、视频分析、图形识别以及文本分析等单个模态的算法模型。随着基于Transformer的ChatGPT的出现,之后的AI大模型逐渐实现了对多模态的支持。这些模型可以通过文本、图像、语音、视频等多模态的数据进行学习,并且基于其中一个模态学习到的能力,可以应用在另一个模态的推理。
此外,不同模态数据学习到的能力还会融合,形成一些超出单个模态学习能力的新的能力。多模态的划分是人为进行的,多种模态的数据里包含的信息都可以被AGI统一理解,并转换成模型的能力。在中小模型中,人为割裂了很多信息,从而限制了AI算法的智能能力。此外,模型的参数规模和模型架构也对智能能力有很大影响。
3、通用性
自2012年深度学习进入我们的视野以来,各种特定应用场景的AI模型如雨后春笋般涌现。这些模型包括车牌识别、人脸识别、语音识别等,以及一些综合性场景,例如自动驾驶、元宇宙等。每个场景都有不同的模型,并且同一个场景中,不同公司开发的算法和架构也各不相同。因此,这一时期的AI模型极度碎片化。
然而,从GPT开始,我们看到了通用AI的曙光。最理想的AI模型应该是可以接受任何形式、任何场景的训练数据,可以学习到几乎所有的能力,并且可以做出任何需要做出的决策。最关键的是,基于大模型的AGI的智能能力远高于传统的用于特定场合的AI中小模型。完全通用的AI出现后,我们可以将其推广到各种场景中,实现AGI+各种场景的应用。同时,由于算法逐渐确定,AI加速持续优化的空间也得到了扩大,从而可以不断提升AI算力。算力的提升又会推动模型向更大规模参数的演进和升级。
二、通用处理器的可行性有多少?
随着摩尔定律失效,CPU已经难以胜任大量计算任务,因此开始了一轮专用芯片设计的大潮。然而,以DSA为代表的专用芯片并没有像预期的那样成功,反而在AI大模型的加持下,成就了通用GPU的黄金年代。
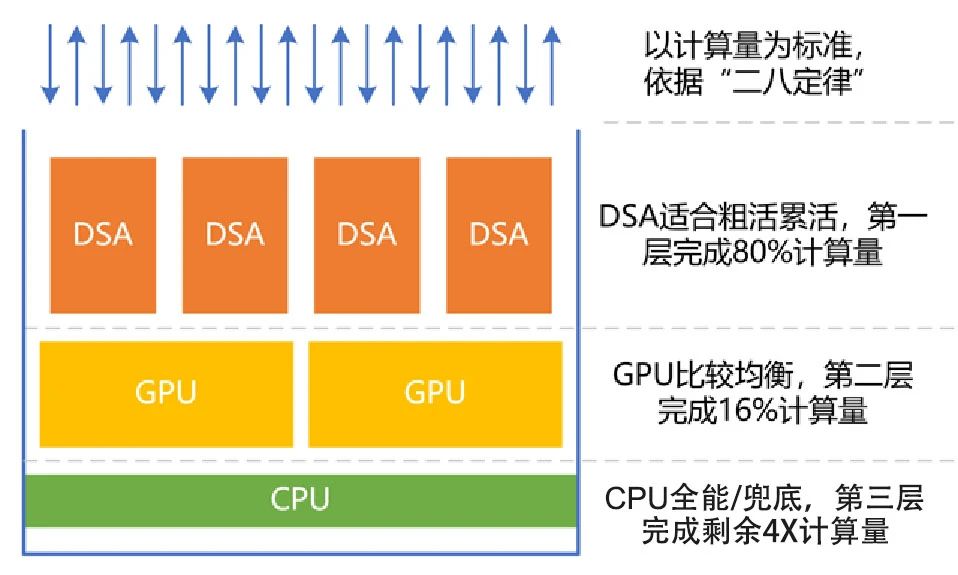
然而,GPU的性能也即将到达上限,支持GPT大模型的GPU集群需要成千上万颗GPU处理器,效率低下,建设和运行成本高昂。因此,是否可以设计更加优化的处理器,即具备通用处理器的特征,同时能够实现更高效率和性能呢?我们可以将计算机上运行的系统拆分为若干个工作任务,并且二八定律表明,很多工作任务是相对确定的,例如虚拟化、网络、存储、安全、数据库、文件系统和人工智能推理等。
即使应用层的计算任务比较随机,仍然包含大量确定性的计算成分,例如安全、视频图形处理和人工智能等。因此,我们可以将处理器按照性能效率和灵活性能力分为三个类型:CPU、GPU和DSA。
根据二八定律,将80%的计算任务交给DSA完成,将16%的工作任务交给GPU完成,而CPU则负责剩余4%的其他工作。CPU的重要工作是兜底。根据性能/灵活性的特征,匹配最合适的处理器计算引擎,可以在实现足够通用的情况下,实现最极致的性能。
三、通用处理器的历史和发展
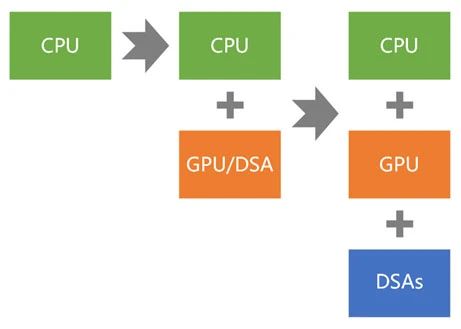
通用计算的演进可以简单地分为三个阶段。第一代通用计算采用CPU同构架构。第二代通用计算则采用CPU+GPU异构架构。第三代通用计算(即新一代)则采用CPU+GPU+DSAs的超异构架构。
1、CPU同构

Intel是CPU的发明者,也是第一代通用计算的代表。在近30年的时间里,CPU成就了Intel在2000年前后的霸主地位。然而,CPU的标量计算性能相对较弱,因此逐渐引入了向量指令集处理的AVX协处理器和矩阵指令集的AMX协处理器等复杂指令集,以不断优化CPU的性能和计算效率,拓展其生存空间。
2、CPU+GPU异构
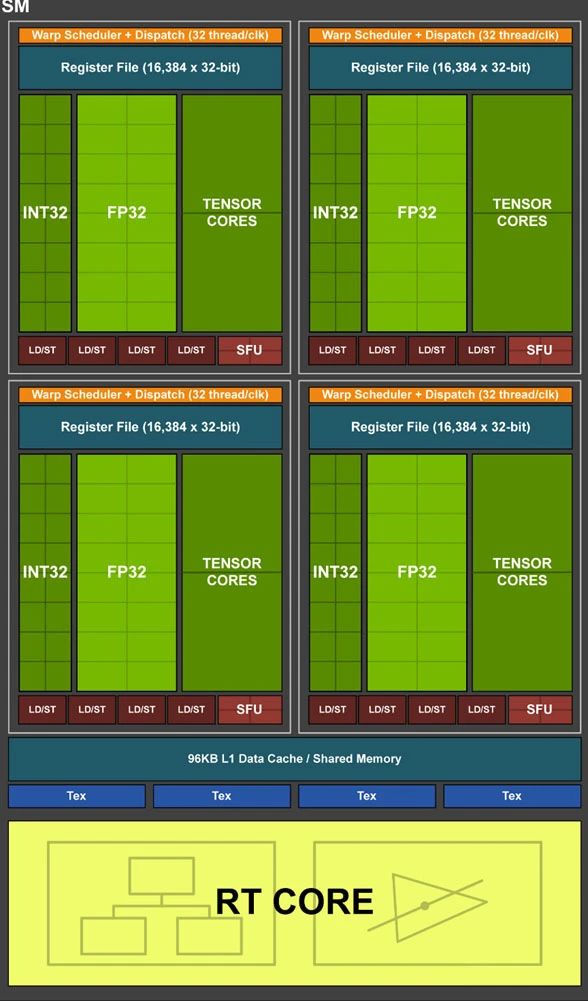
虽然CPU协处理器可以在一些相对较小规模的加速计算场景中勉强使用,但其性能存在上限,并且不适合于大规模加速计算场景,特别是在AI等领域。因此,需要完全独立的、更加重量的加速处理器。
GPU是通用并行计算平台,是最典型的加速处理器。GPU计算需要有Host CPU来控制和协同,因此具体的实现形态是CPU+GPU的异构计算架构。NVIDIA发明了GP-GPU,并提供了CUDA框架,促进了第二代通用计算的广泛应用。随着AI深度学习和大模型的发展,GPU成为最炙手可热的硬件平台,也成就了NVIDIA万亿市值。GPU内部的数以千计的CUDA core,本质上是更高效的CPU小核,因此,其性能效率仍然存在上升的空间。为了进一步优化张量计算的性能和效率,NVIDIA开发了Tensor加速核心。
3、CPU+GPU+DSAs超异构
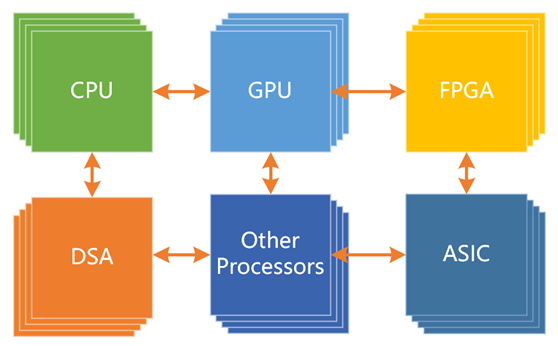
技术发展永无止境,第三代通用计算面向未来更大算力需求场景的挑战,采用多种异构融合的超异构计算。其中,有三个层次的独立处理引擎,即CPU、GPU和DSA,组成CPU+XPU的异构计算架构。超异构计算不是简单的多种异构计算的集成,而是多种异构计算系统在软件到硬件层次上的深度融合。超异构计算的成功必须要实现足够好的通用性。如果不考虑通用性,超异构架构里的计算引擎会使得架构碎片化问题更加严重,软件人员将无所适从。
蓝海大脑的高性能超算异构平台支持多种硬件加速器,包括CPU、GPU、FPGA和AI等,能够满足大规模数据处理和复杂计算任务的需求。采用分布式计算架构,高效地处理大规模数据和复杂计算任务,为AGI算法的研究和开发提供强大的算力支持。具有高度的灵活性和可扩展性,能够根据不同的应用场景和需求进行定制化配置。可以快速部署和管理各种计算任务,提高了计算资源的利用率和效率。为人工智能技术的发展和应用提供强有力的支持。
审核编辑黄宇
-
人工智能
+关注
关注
1799文章
48047浏览量
241944 -
Agi
+关注
关注
0文章
90浏览量
10306 -
深度学习
+关注
关注
73文章
5527浏览量
121832 -
大模型
+关注
关注
2文章
2762浏览量
3413
发布评论请先 登录
相关推荐
大模型应用之路:从提示词到通用人工智能(AGI)
报名开启!深圳(国际)通用人工智能大会将启幕,国内外大咖齐聚话AI
【免费名额30个】手把手教你快速学习和应用人工智能技术
深度学习推理和计算-通用AI核心
人工智能基本概念机器学习算法
【书籍评测活动NO.16】 通用人工智能:初心与未来
《通用人工智能:初心与未来》-试读报告
什么是人类智能 杨学山浅谈通用人工智能的发展途径
聆心智能上榜“北京市通用人工智能大模型行业应用典型场景案例”
软通动力入选“北京市通用人工智能产业创新伙伴计划(第三批)”






 工商网监
工商网监
评论