 LeCun世界模型首个研究!自监督视觉像人一样学习和推理!
LeCun世界模型首个研究!自监督视觉像人一样学习和推理!

让 AI 像人类一样学习和推理,这是人工智能迈向人类智能的重要一步。图灵奖得主 Yann LeCun 曾提出自监督 + 世界模型的解决方案,如今终于有了第一个实实在在的视觉模型。
去年初,Meta 首席 AI 科学家 Yann LeCun 针对「如何才能打造出接近人类水平的 AI」提出了全新的思路。他勾勒出了构建人类水平 AI 的另一种愿景,指出学习世界模型(即世界如何运作的内部模型)的能力或许是关键。这种学到世界运作方式内部模型的机器可以更快地学习、规划完成复杂的任务,并轻松适应不熟悉的情况。
LeCun 认为,构造自主 AI 需要预测世界模型,而世界模型必须能够执行多模态预测,对应的解决方案是一种叫做分层 JEPA(联合嵌入预测架构)的架构。该架构可以通过堆叠的方式进行更抽象、更长期的预测。
6 月 9 日,在 2023 北京智源大会开幕式的 keynote 演讲中,LeCun 又再次讲解了世界模型的概念,他认为基于自监督的语言模型无法获得关于真实世界的知识,这些模型在本质上是不可控的。

今日,Meta 推出了首个基于 LeCun 世界模型概念的 AI 模型。该模型名为图像联合嵌入预测架构(Image Joint Embedding Predictive Architecture, I-JEPA),它通过创建外部世界的内部模型来学习, 比较图像的抽象表示(而不是比较像素本身)。
I-JEPA 在多项计算机视觉任务上取得非常不错的效果,并且计算效率远高于其他广泛使用的计算机视觉模型。此外 I-JEPA 学得的表示也可以用于很多不同的应用,无需进行大量微调。
举个例子,Meta 在 72 小时内使用 16 块 A100 GPU 训练了一个 632M 参数的视觉 transformer 模型,还在 ImageNet 上实现了 low-shot 分类的 SOTA 性能,其中每个类只有 12 个标签样本。其他方法通常需要 2 到 10 倍的 GPU 小时数,并在使用相同数据量训练时误差率更高。
相关的论文《Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture》已被 CVPR 2023 接收。当然,所有的训练代码和模型检查点都将开源。

论文地址:https://arxiv.org/abs/2301.08243
GitHub 地址:https://t.co/DgS9XiwnMz
通过自监督学习获取常识型知识
I-JEPA 基于一个事实,即人类仅通过被动观察就可以了解关于世界的大量背景知识,这些常识信息被认为是实现智能行为的关键。
通常,AI 研究人员会设计学习算法来捕获现实世界的常识,并将其编码为算法可访问的数字表征。为了高效,这些表征需要以自监督的方式来学习,即直接从图像或声音等未标记的数据中学习,而不是从手动标记的数据集中学习。
在高层级上,JEPA 的一个输入中某个部分的表征是根据其他部分的表征来预测的。同时,通过在高抽象层次上预测表征而不是直接预测像素值,JEPA 能够直接学习有用的表征,同时避免了生成模型的局限性。
相比之下,生成模型会通过删除或扭曲模型输入的部分内容来学习。然而,生成模型的一个显著缺点是模型试图填补每一点缺失的信息,即使现实世界本质上是不可预测的。因此,生成模型过于关注不相关的细节,而不是捕捉高级可预测的概念。
自监督学习的通用架构,其中系统学习捕获其输入之间的关系。
迈向能力广泛的 JEPA 的第一步
I-JEPA 的核心思路是以更类似于人类理解的抽象表征来预测缺失信息。与在像素 /token 空间中进行预测的生成方法相比,I-JEPA 使用抽象的预测目标,潜在地消除了不必要的像素级细节,从而使模型学习更多语义特征。
另一个引导 I-JEPA 产生语义表征的核心设计是多块掩码策略。该研究使用信息丰富的上下文来预测包含语义信息的块,并表明这是非常必要的。
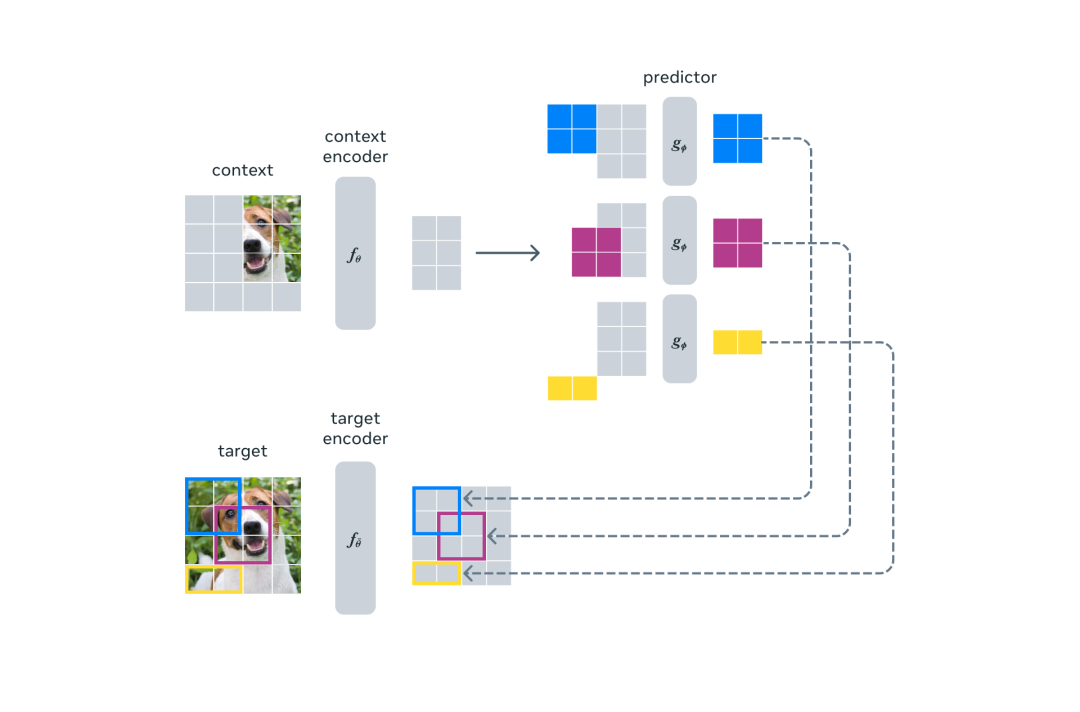
I-JEPA 使用单个上下文块来预测源自同一图像的各种目标块的表征。
I-JEPA 中的预测器可以看作是一个原始的(和受限的)世界模型,它能够从部分可观察的上下文中模拟静态图像中的空间不确定性。更重要的是,这个世界模型是语义级的,因为它预测图像中不可见区域的高级信息,而不是像素级细节。

预测器如何学习建模世界的语义。对于每张图像,蓝框外的部分被编码并作为上下文提供给预测器。然后预测器输出它期望在蓝框内区域的表示。为了可视化预测,Meta 训练了一个生成模型, 它生成了由预测输出表示的内容草图,并在蓝框内显示样本输出。很明显,预测器识别出了应该填充哪些部分的语义(如狗的头部、鸟的腿、狼的前肢、建筑物的另一侧)。
为了理解模型捕获的内容,Meta 训练了一个随机解码器,将 I-JEPA 预测的表示映射回像素空间,这展示出了探针操作后在蓝框中进行预测时的模型输出。这种定性评估表明,I-JEPA 正确捕获了位置不确定性,并生成了具有正确姿态的高级对象部分(如狗的头部、狼的前肢)。
简而言之,I-JEPA 能够学习对象部分的高级表示,而不会丢弃它们在图像中的局部位置信息。
高效率、强性能
I-JEPA 预训练在计算上也很高效,在使用更多计算密集型数据增强来生成多个视图时不会产生任何开销。目标编码器只需要处理图像的一个视图,上下文编码器只需要处理上下文块。
实验发现,I-JEPA 在不使用手动视图增强的情况下学习了强大的现成语义表示,具体可见下图。此外 I-JEPA 还在 ImageNet-1K 线性探针和半监督评估上优于像素和 token 重建方法。
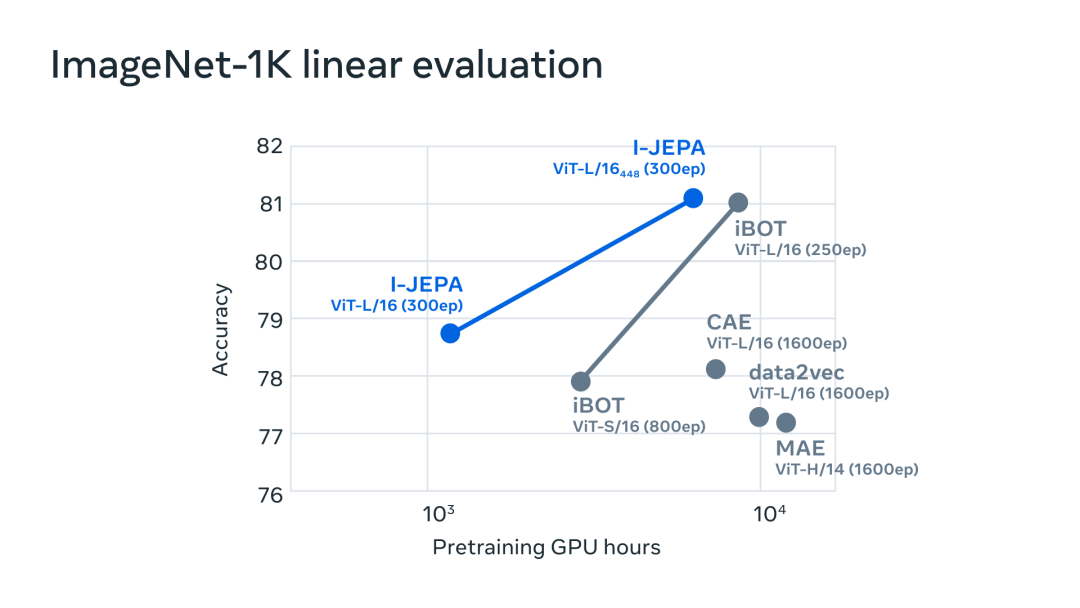
ImageNet-1k 数据集上的线性评估。
I-JEPA 还能与以往在语义任务上依赖手动数据增强的方法竞争。相比之下,I-JEPA 在对象计数和深度预测等低级视觉任务上取得了更好的性能。通过使用较小刚性归纳偏置的更简单模型,I-JEPA 适用于更广泛的任务集合。
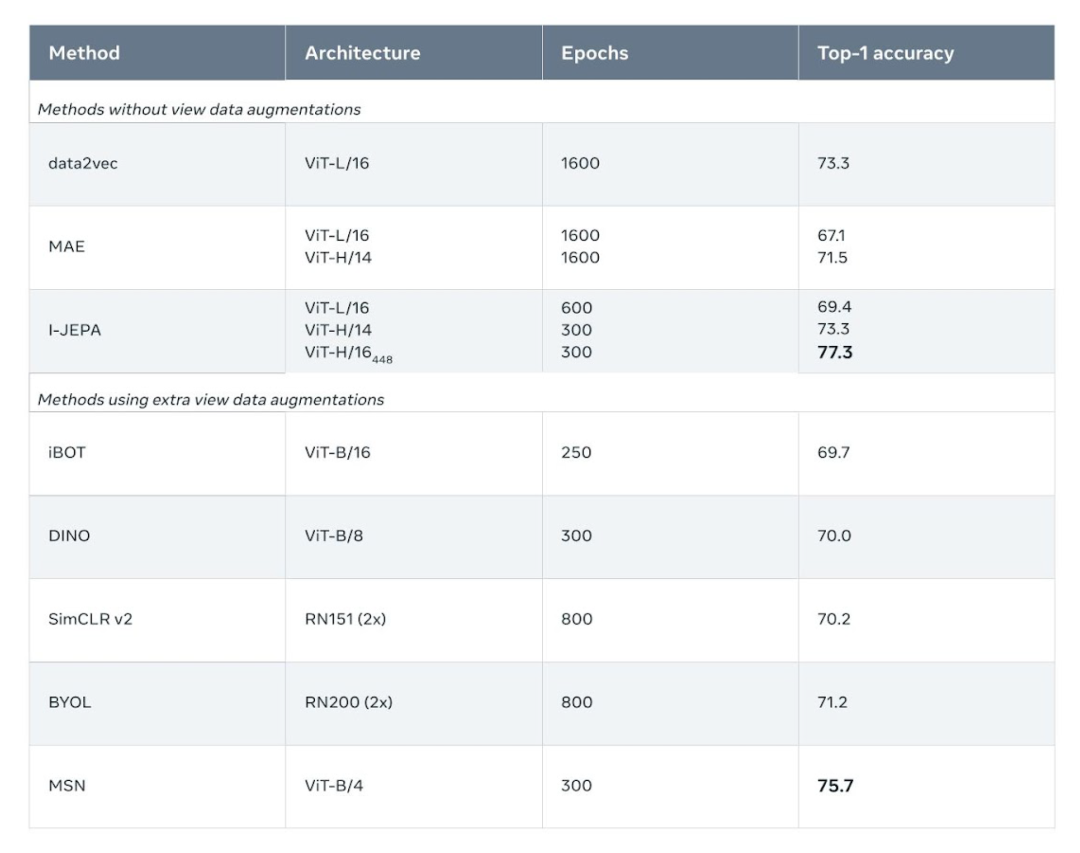
low shot 分类准确性:使用 1% 标签时 ImageNet-1k 上的半监督评估结果(每类只有 12 张标签图像)。
AI 智能向人类水平更近了一步
I-JEPA 展示了无需通过手动图像变换来编码额外知识时,学习有竞争力的现成图像表示的潜力。继续推进 JEPA 以从更丰富模态中学习更通用世界模型将变得特别有趣,比如人们从一个短上下文中对视频中的将来事件做出长期空间和时间预测,并利用音频或文本 prompt 对这些预测进行调整。
Meta 希望将 JEPA 方法扩展到其他领域,比如图像 - 文本配对数据和视频数据。未来,JEPA 模型可以在视频理解等任务中得到应用。这是应用和扩展自监督方法来学习更通用世界模型的重要一步
-
人工智能
+关注
关注
1820文章
50363浏览量
267015 -
模型
+关注
关注
1文章
3831浏览量
52280 -
语言模型
+关注
关注
0文章
575浏览量
11345
原文标题:CVPR 2023 | LeCun世界模型首个研究!自监督视觉像人一样学习和推理!
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
大模型推理显存和计算量估计方法研究
机器鱼能像真鱼一样游泳
机器能像婴儿一样通过眼睛学习世界?
如何使机器像人一样对物理世界直观理解?
世界上第一台能够像植物卷须一样卷曲和攀爬的软机器人问世
自监督学习与Transformer相关论文
新加坡大学研发首个拥有像人一样的触感智能泡沫
研究团队设计出像大白一样的拥抱机器人

人的大脑和自监督学习模型的相似度有多高?
LeCun世界模型首项研究来了:自监督视觉,已开源
基础模型自监督预训练的数据之谜:大量数据究竟是福还是祸?




评论