 基于预训练模型和语言增强的零样本视觉学习
基于预训练模型和语言增强的零样本视觉学习
在一些非自然图像中要比传统模型表现更好
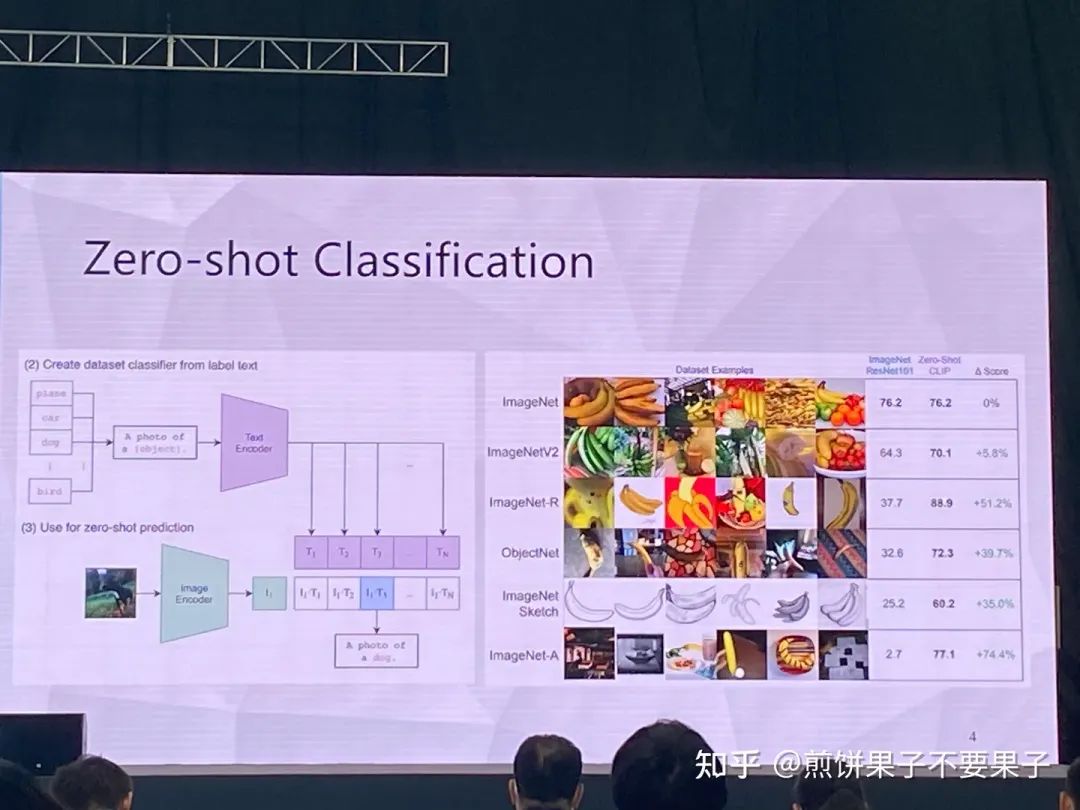
CoOp 增加一些 prompt 会让模型能力进一步提升

怎么让能力更好?可以引入其他知识,即其他的预训练模型,包括大语言模型、多模态模型
也包括 Stable Diffusion 多模态预训练模型

考虑多标签图像分类任务——每幅图像大于一个类别
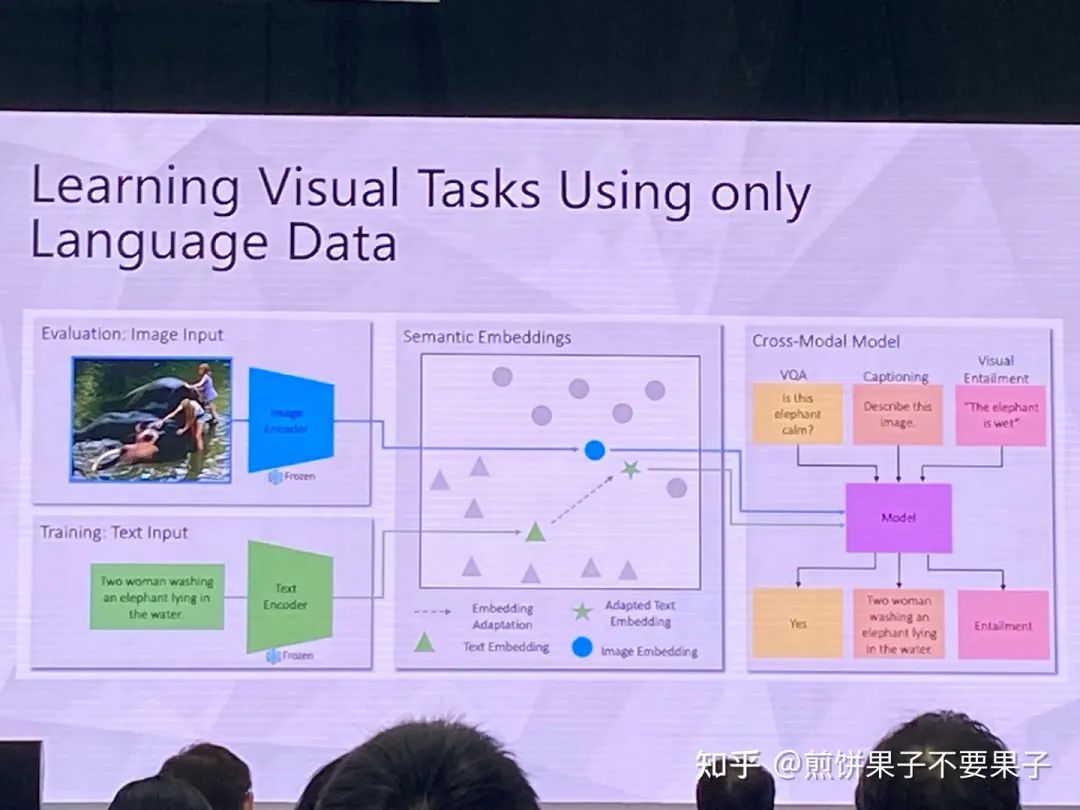
如果已有图文对齐模型——能否用文本特征代替图像特征

训练的时候使用文本组成的句子
对齐总会有 gap,选 loss 的时候使用 rank loss,对模态 gap 更稳定
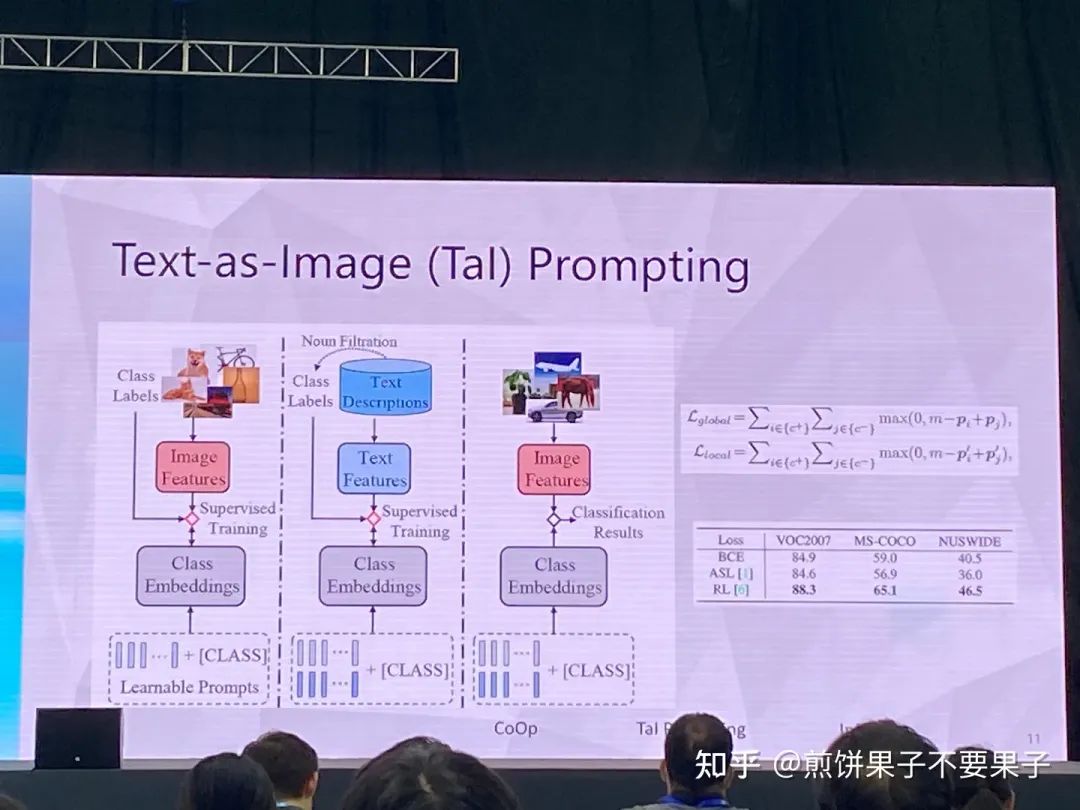
拿到文本后有几种选择,比如 Coco 只要其中的 caption 不要图像,或是 Google 搜句子,抑或是语言模型生成
最后选择第一种,因为稳定性和效果更好,能够保证同样数据集(同分布?)
可以建一个同义词表

两种 prompt,global 关注句子里有没有猫,local 关心这个词是不是跟猫有关系

测试的时候就将句子变成图像,global 不变,local 变成了跟图像里的 token 做比较
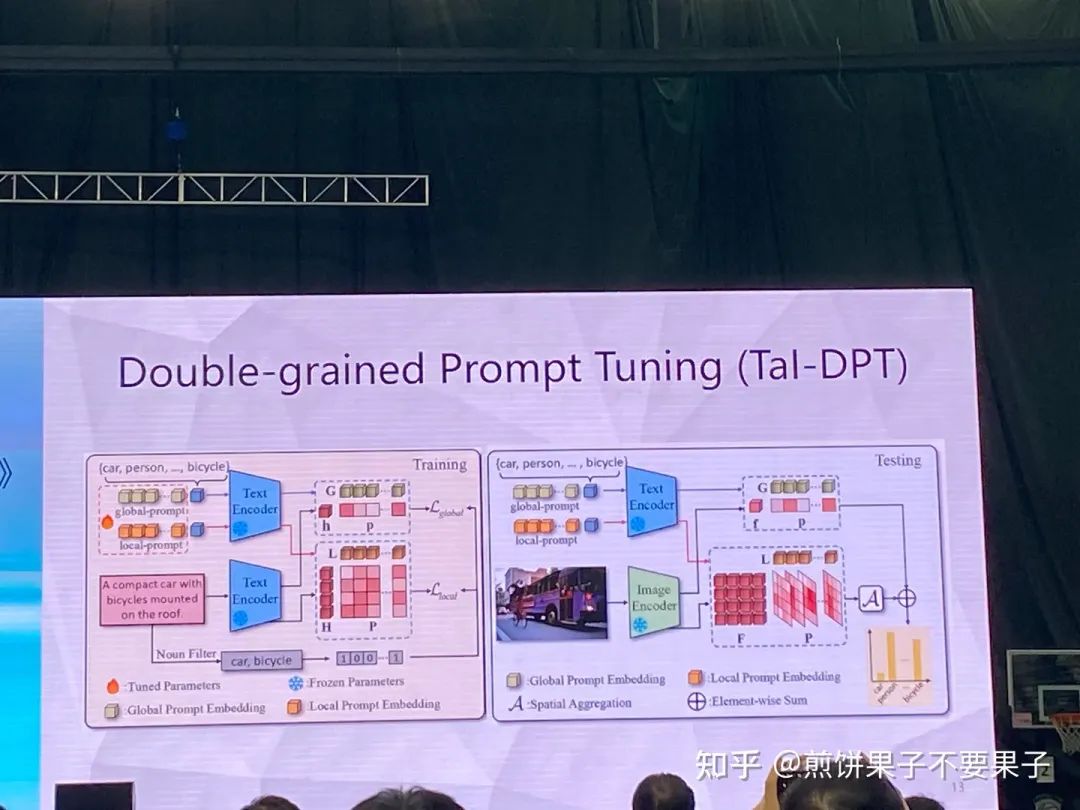
如果再加上少量文本(大量句子和少量文本)性能会进一步提升

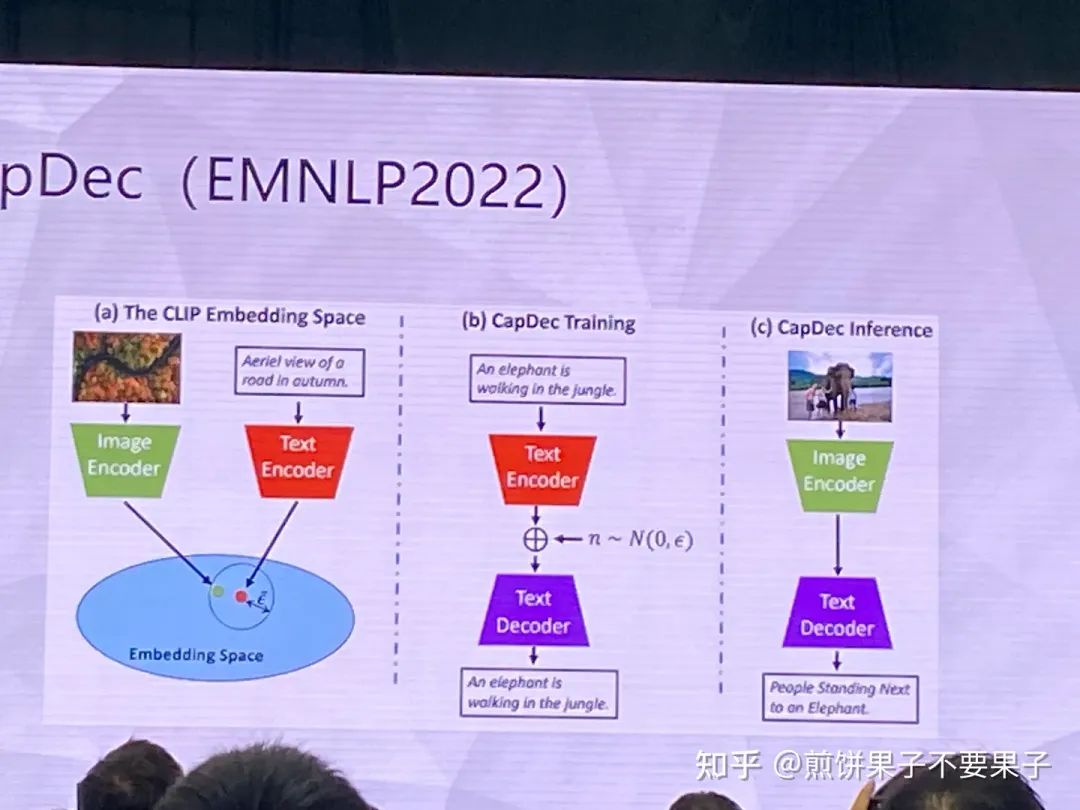
一些相关工作,提完文本特征加一些噪声提高鲁棒性,消解图文 gap
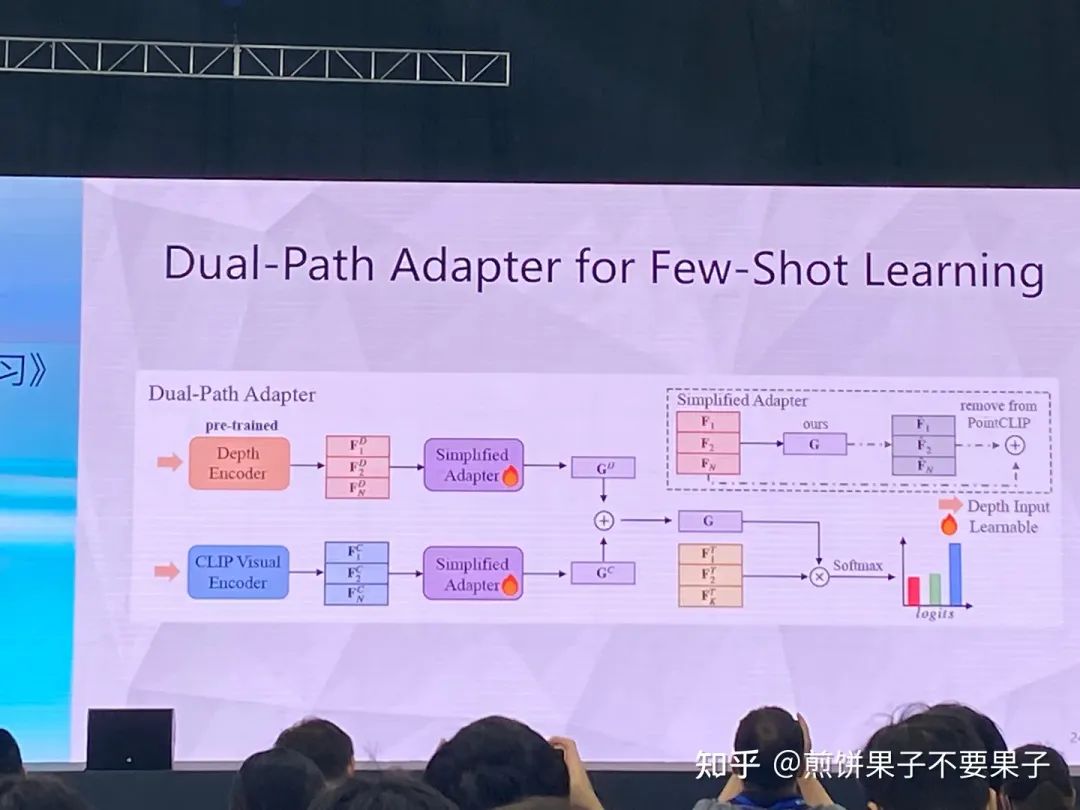
3d 样本较难,因为点云-文本对较少,很难获取
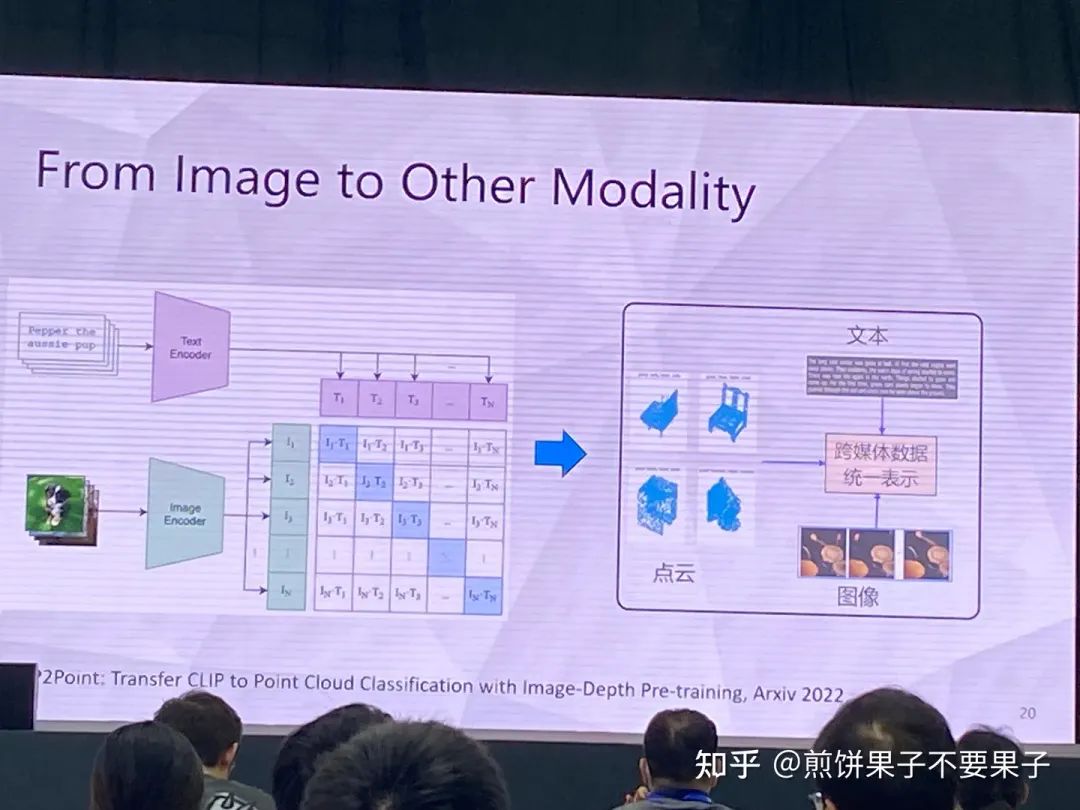
投影后的 3d 点云可以被视作 2d 图像处理,使用图像 encoder
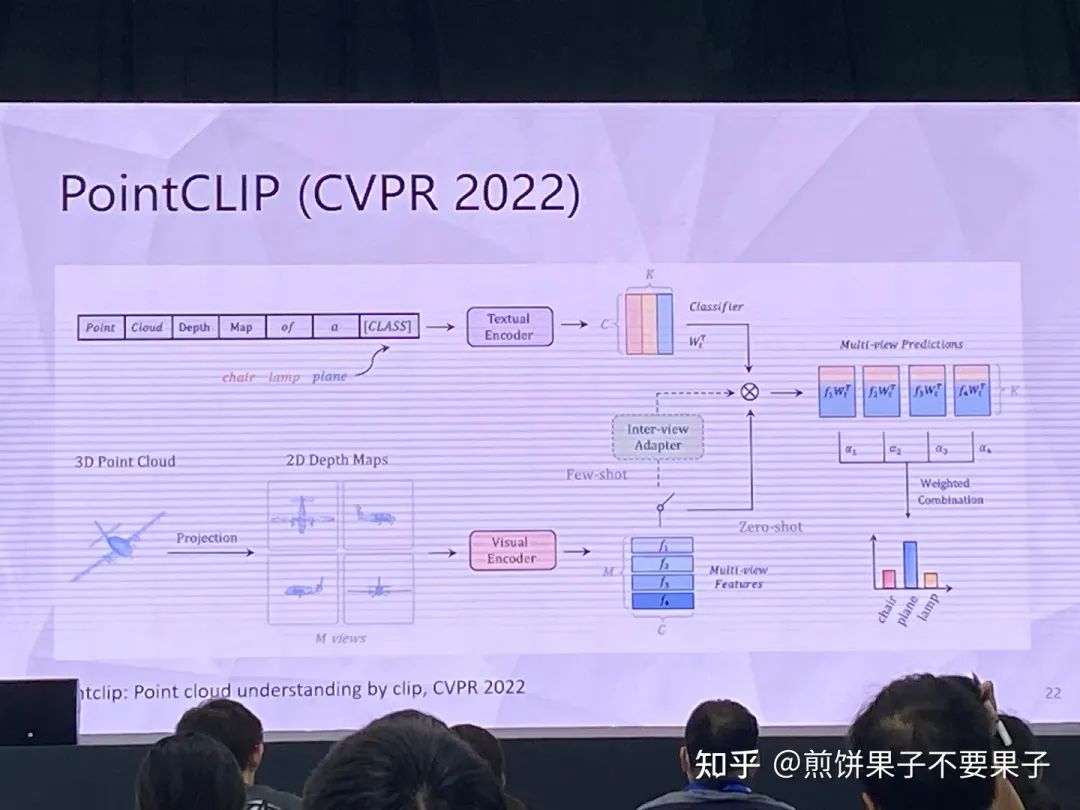
但投影点云依然与图像存在 gap,于是采取另一种思路
投影的确与图像相关,但依然有调整空间,所以转换成某个方向的图像和该方向点云的投影图像做匹配
投影和图像对齐,图像和文本对齐,因此就可以实现零样本学习
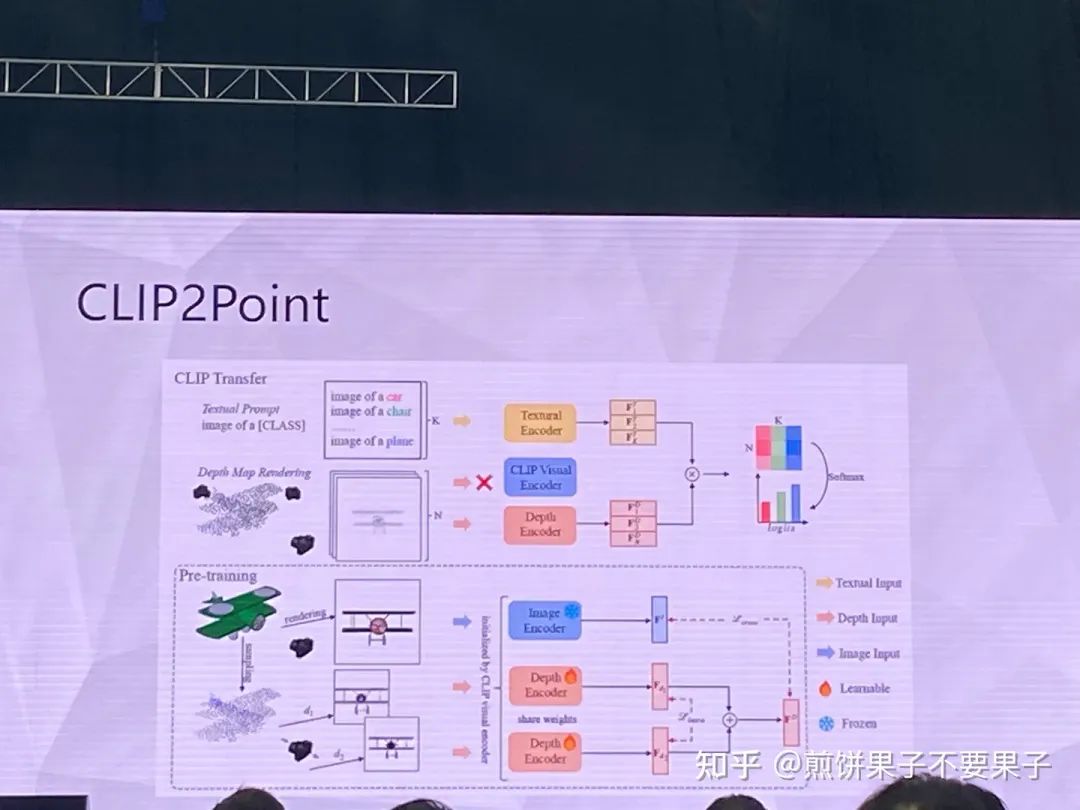
如果有一些少量的有标签监督,相当于 few-shot,效果也相当好
全监督效果也很好
当时觉得图像可以做中介,那么红外、热成像等其他模态都可以
ImageBind 以图像为中介将六种模态对齐到一起,重新训练
但大家依然可以做自己领域相关的方向,以图像作为中介对比,还有很大的空间

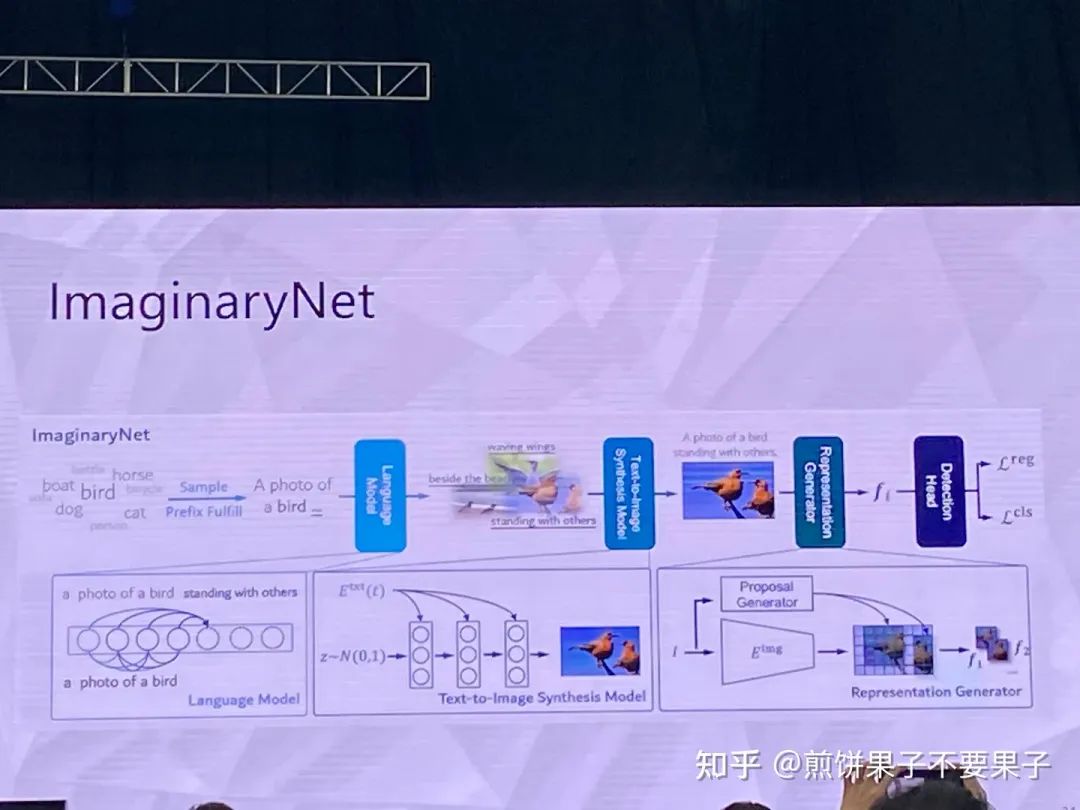
用想象的方式开展学习

假设有一些类别,使用语言模型生成一些句子,再根据句子使用生成模型生成图像
因此有了图像和类别匹配对(弱监督目标检测)
希望即使使用合成图像,模型在真实图像上也可以比较好
因为类别本身和图像会比较简单,但如果使用语言模型,比如猫变成趴着的猫,这样图像多样性会很高

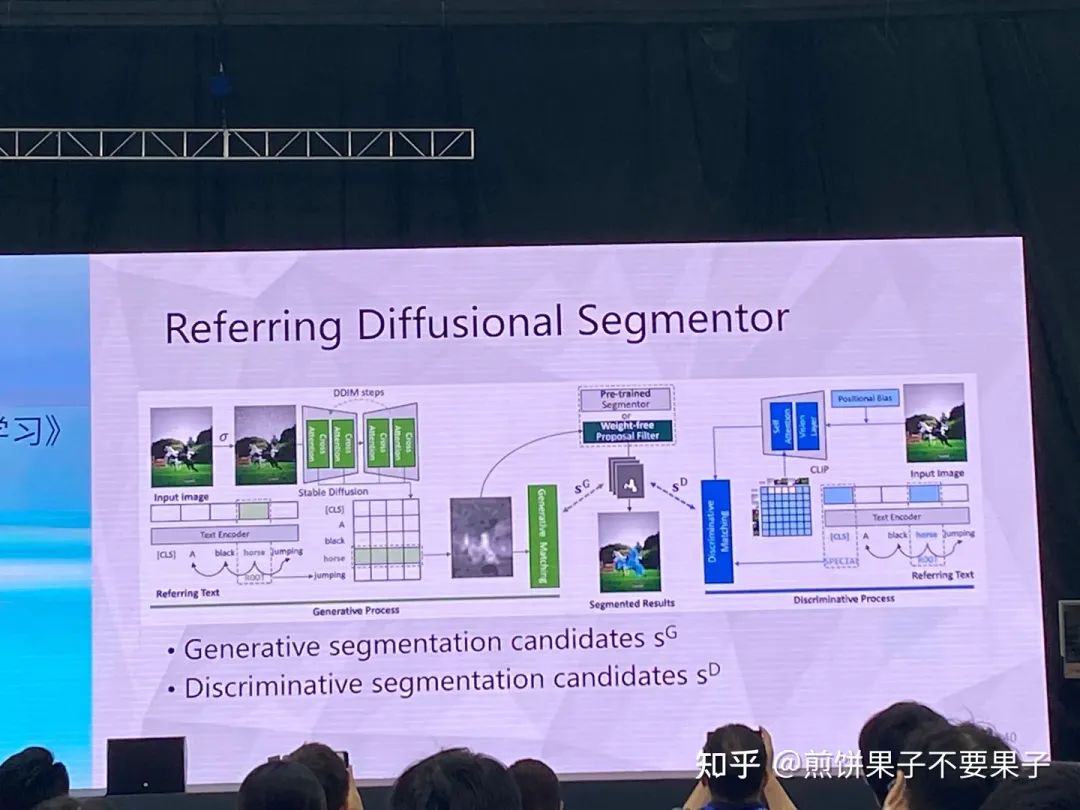
考虑 SAM 和 Stable diffusion 特定完成分割任务
通过 SAM 得到的 proposal 提取特征

责任编辑:彭菁
-
语言模型
+关注
关注
0文章
532浏览量
10300 -
训练模型
+关注
关注
1文章
36浏览量
3872
原文标题:VALSE 2023 | 左旺孟教授:预训练模型和语言增强的零样本视觉学习
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一文详解知识增强的语言预训练模型
【大语言模型:原理与工程实践】大语言模型的预训练
【大语言模型:原理与工程实践】大语言模型的应用
基于深度学习的自然语言处理对抗样本模型

如何更高效地使用预训练语言模型
如何充分挖掘预训练视觉-语言基础大模型的更好零样本学习能力
预训练数据大小对于预训练模型的影响
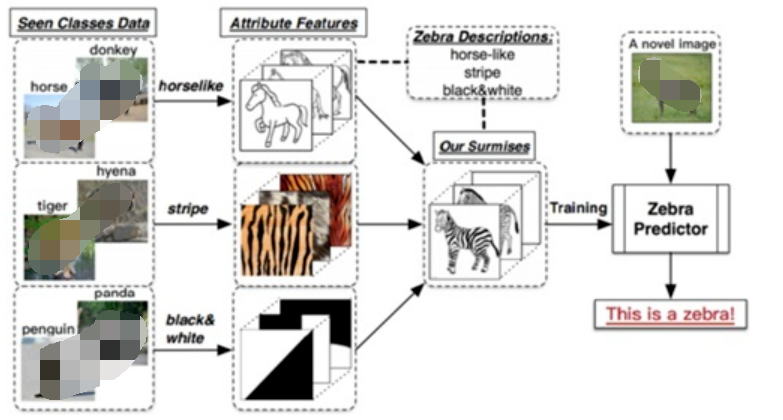
什么是零样本学习?为什么要搞零样本学习?





 工商网监
工商网监
评论