 数字信号处理:实时I/O的编程注意事项
数字信号处理:实时I/O的编程注意事项
David Skolnick 和 Noam Levine
现在,我们更仔细地关注实时系统特有的DSP编程问题。本文重点介绍如何为具有各种I/O接口的DSP系统开发算法。
“实时”是什么意思?在模拟系统中,每项任务都是通过连续的信号和处理“实时”执行的。在数字信号处理(DSP)系统中,信号用一组样本表示,即离散时间点的值。因此,根据采样率,在DSP系统中处理给定数量的样本的时间可以“实时”进行任意解释。本系列的第一篇文章介绍了采样的概念和奈奎斯特准则,即在实时应用中,采样频率必须至少是(模拟)信号中感兴趣的最高频率分量(奈奎斯特速率)频率的两倍。样本之间的时间称为采样间隔。要将系统视为“实时”运行,必须在新数据到达之前完成对给定数据集(一个或多个样本,取决于算法)的所有处理。
实时的这种定义意味着,对于以给定时钟速率运行的处理器,输入数据的速度和数量决定了可以在不落后于数据流的情况下对数据进行多少处理。对于模拟设计人员来说,处理数据的时间有限的想法可能看起来很奇怪,因为这个概念在模拟系统中没有并行。在模拟系统中,信号被连续处理。慢速系统中唯一的惩罚是有限的频率响应。相比之下,数字系统处理部分信号,足以进行非常精确的近似,但只能在有限的时间内。图 1 显示了一个比较。实时DSP可以受到在算法时间预算内可以完成的数据量或处理类型的限制。例如,处理以 48 kHz(音频信号)采样的数据值的给定 DSP 处理器处理这些数据值的时间比一个采样 8 kHz 语音频段数据的时间更少。
在本系列前面描述的滤波器示例中,输入采样率为8 kHz。为了使示例中的DSP跟上实时数据,所有处理都必须在1/(8 kHz)或125 μs的时间预算内完成。在 33MHz 数字信号处理器(每周期 30ens)上,时间预算提供 125 μs/30 ns 或 4166 个指令周期,以完成处理和任何其他必需的任务。
由于执行任何给定算法可以预算的时间有限,因此管理时间是DSP系统软件设计的核心部分。时间管理策略确定处理器如何获得有关事件的通知、影响数据处理以及塑造处理器通信。
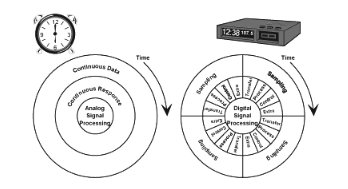
图1.模拟和数字信号处理的比较。a. 模拟:响应值对应于所有时刻的每个数据值。b. 数字:对于每个样品,必须传输和处理数据,事件标志着处理(控制)的结束,并且在指定过程发生后,周期内的其他任务可能需要额外的时间。
事件通知: 中断:人们可以对DSP进行编程,以使用处理“事件”(数据到达)的几种策略之一来处理数据。可以定期读取状态位或标志引脚,以确定新数据是否可用。但是,“轮询”会浪费处理器周期。数据可能会在上次民意调查后到达,但直到下一次民意调查才能知道它的存在。这使得开发实时系统变得困难。
第二种策略是让数据在到达时中断处理器。使用中断通知处理器是有效的,尽管编程不那么容易;在等待中断期间可能会浪费时钟周期。然而,事件驱动的中断编程非常适合快速处理真实世界的信号,大多数DSP都旨在有效地处理它们。事实上,它们旨在非常快速地响应中断。ADSP-2181对中断的响应时间约为三个处理器周期;即,在75 ns内,DSP已停止执行其正在执行的操作,并正在处理中断事件(矢量)。
在许多基于DSP的系统中,基于输入数据采样速率的中断速率通常与DSP的时钟速率完全无关。在本系列前面的 FIR 示例中,处理器以 125 μs 的间隔中断以接收新数据。
中断处理和中断向量:由于中断处理是DSP系统中至关重要的元素,因此处理器通常具有内置的硬件机制来有效地处理中断。硬连线机制比单独的软件更有效,因为 DSP 的中断服务例程 (ISR) 可能必须满足以下所有需求:
快速上下文切换 – 从一个任务及其数据(上下文)切换到另一个上下文,而不会因编写程序以保存寄存器内容和芯片状态信息而浪费时间和复杂性。
嵌套中断处理 – “同时”处理不同优先级的多个中断。DSP 一次处理一个中断,但优先级较高的中断可能优先于优先级较低的中断的处理。
继续接受数据/记录状态 - 当 DSP 服务中断时,现实世界中不断发生事件,数据不断到达。为了跟上“现实世界”的步伐,DSP必须记录这些事件并接受数据,然后在完成中断服务后处理它们。
在ADI公司的DSP上,使用两组数据寄存器实现快速上下文切换。一次只有一个集处于活动状态,其中包含该上下文期间处理的所有数据。处理中断时,计算机可以从活动集切换到备用集,而无需将数据临时保存在内存中。这有助于在任务之间快速切换。
为了处理多个中断,ADI公司的DSP记录每个中断的状态。处理器状态信息保存在位于 DSP 程序序列器中的一组状态“堆栈”上。“堆栈”由一组硬件寄存器组成。事件发生时,当前状态信息被“推送”到堆栈上。这种堆栈机制还允许嵌套中断;优先级较高的一个可以中断优先级较低的一个。
中断锁存器和自动I/O两种硬件特性使ADI公司的DSP在处理中断时能够及时了解“现实世界”。锁存器可防止 DSP 在处理中断时错过重要事件。另一个功能包括各种形式的自动I/O(包括串行端口、DMA、自动缓冲等),允许外部设备将数据泵入DSP的存储器,而无需DSP的干预。因此,当DSP“繁忙”时,不会丢失任何数据。
当外部源或内部资源生成中断请求时,DSP 处理器会自动存储其当前操作状态,并准备执行中断例程。中断例程是从中断向量表调度的。中断向量表是程序存储器中的一个区域,其中的指令地址分配给特定的DSP中断功能。例如,在下表中,ADSP-1处理器串行端口1(SPORT2181)上的发送(Tx)中断将导致下一条指令在程序存储器(PM)位置0x0020执行,然后通过0x0023(中断例程)执行接下来三个位置的内容。如表中的12项所示,ADSP-2181可以处理来自11个位置(外部硬件、DMA端口和串行端口)和处理器复位的中断。该表列出了分配给存储器位置中每个中断向量源的编程指令,0x0000 FIR滤波器程序0x002F。
Jump start; nop; nop; nop; /* PM(0x0000-03): Reset vector */
rti; nop; nop; nop; /* PM(0x0004-07): IRQ2 vector */
rti; nop; nop; nop; /* PM(0x0008-0B): IRQL1 vector */
rti; nop; nop; nop; /* PM(0x000C-0F): IRQL0 vector */
ar = dm(stat_flag); ar = pass ar; if eq_rti; jump next_cmd;
/* PM(0x0010-13): SPORT0 Tx vector */
jump input_samples; nop; nop; nop;
/* PM(0x0014-17): SPORT0 Rx vector */
jump irqe; nop; nop; nop; /* PM(0x0018-1B): IRQE vector */
rti; nop; nop; nop; /* PM(0x001C-1F): BDMA vector */
rti; nop; nop; nop; /* PM(0x0020-23): SPORT1 Tx vector */
rti; nop; nop; nop; /* PM(0x0024-27): SPORT1 Rx vector */
rti; nop; nop; nop; /* PM(0x0028-2B): Timer vector */
rti; nop; nop; nop; /* PM(0x002C-2F): Powerdown vector */
每个中断向量有四个指令位置。通常,这些指令将导致处理器跳转到另一个内存区域以处理数据,如重置(0x0000时)、SPORT0 Rx (0x0014) 和 IRQE (0x0018) 中断向量所示。如果只有几个步骤(例如读取值、检查状态或加载内存)可以在四个可用指令位置内完成,则直接对其进行编程,如 SPORT0 Tx 矢量 (0x0010-13) 所示。任何未使用的中断向量都要求从中断返回 (rti),并带有三个 nop(无操作)指令。
nop 指令用作占位符 – 指令空间,用于确保正确的中断操作与硬件指定的中断向量对齐。每个未使用的矢量位置开头的 rti 指令既是占位符又是安全阀。如果未使用的中断被错误地取消屏蔽或无意中触发,“rti”会导致恢复正常执行。
数据 I/O
在DSP系统中,中断通常是由数据的到达或提供新输出数据的要求产生的。每个样本都可能发生中断,也可能在收集一帧数据后发生中断。这些差异极大地影响了DSP算法处理数据的方式。
对于逐个样本运行的算法,可能需要DSP软件来处理每个传入和传出的数据值。每个 DSP 串行端口包含两个数据 I/O 寄存器,一个接收寄存器 (Rx) 和一个发送寄存器 (Tx)。收到串行字时,端口通常会生成接收中断。处理器停止它正在执行的操作,开始在中断向量位置执行代码,将来自 Rx 寄存器的传入值读取到处理器数据寄存器中,然后对该数据值进行操作或返回到其后台任务。在上表中,计算机跳转到程序段“input_samples”,执行在该段中编程的任何指令,并直接从中断或通过返回中断向量返回。
为了传输数据,串行端口可以产生传输中断,表示可以将新数据写入SPORT Tx寄存器。然后,DSP 可以在 SPORT Tx 中断向量处开始执行代码,并且通常将值从数据寄存器传输到 SPORT Tx 寄存器。如果数据输入和输出由同一采样时钟控制,则只需要一个中断。例如,如果程序段由接收中断计时启动,则会在中断例程期间读取新数据;然后,要么传输先前计算的结果(保存在寄存器中),要么计算新结果并立即传输 - 作为中断例程的最后一步。
所有这些机制都有助于DSP能够模拟模拟系统的自然功能——实时连续处理数据——但具有数字精度和灵活性。此外,在高效编程的数字系统中,处理数据集之间剩余的备用处理器周期可用于处理其他任务。
编程注意事项
在“实时”系统中,处理速度至关重要。通过使用 SPORT 自动缓冲,数据 I/O 不会浪费任何时间。相反,数据管理目标是确保所选地址指向新数据。
在FIR滤波器示例中(模拟对话31-3,第15页),当输入自动缓冲器已满时,会生成SPORT接收中断请求,这意味着DSP已收到三个数据字:状态、左通道数据和右通道数据。由于此简化应用程序使用单通道数据,因此算法仅使用驻留在位置 rx_buf+1 的数据值。
过滤器算法扩展在其他应用程序中,数据处理可能更加复杂。例如,如果将示例的FIR滤波器扩展到双通道实现,则无需更改核心DSP算法代码。但是,必须修改与数据处理相关的代码,以考虑第二个数据流和第二组系数。
在筛选器代码中,内存中需要两个新缓冲区来处理额外的数据流和额外的系数集。核心滤波器环路可以作为单独的“可调用”函数进行隔离。无论输入数据值如何,此技术都允许使用相同的代码。这种编程风格的优点包括可读代码、可重用算法和减小代码大小。如果不采用模块化方法,则必须使用额外的DSP存储器空间重复滤波器环路。
然后,SPORT 接收中断例程将包括指针设置和调用过滤器。修订后的筛选器例程显示在以下清单中:
Filter: cntr = taps - 1;
mr = 0, mx0 = dm(i2,m1), my0 = pm(i5,m5);
/* clear accumulator, get first data
and coefficient value */
do filt_loop until ce; /* set-up zero-overhead loop */
filt_loop: mr = mr + mx0*my0(ss), mx0 = dm(i2,m1),
my0 = pm(i5,m5); /* MAC and two data fetches */
mr = mr + mx0 * my0 (rnd); /* final multiply, round to 16-bit
result */
if mv sat mr; / * check for overflow*/
rts; /* return */
需要注意的是,对核心过滤器循环的唯一修改是在例程的开头添加了一个标签“Filter:”,并在最后添加了“rts”(从子例程返回)指令。这些新增功能将筛选器代码从独立例程更改为可从其他例程调用的子例程。它不再是一个单一用途的例程,而是一个可重用、可调用的子例程。
通过将核心过滤器设置为可调用的子例程,现在可以满足双通道数据处理要求。为了简化一些编程问题,此示例假定左通道和右通道使用相同的滤波器系数。
在本系列的第三部分中,显示了整个筛选器应用程序程序集代码。在代码清单的顶部,声明了所有必需的内存缓冲区。若要扩展筛选器应用程序以处理两个数据通道,需要声明所需的新变量和缓冲区。对于传入的数据,缓冲区声明,
.var/dm/circ_filt_data[taps];/* 输入数据缓冲区 */
需要替换为两个缓冲区,声明为
.var/dm/circ_filt1_data[taps];/* 左通道输入数据缓冲区 */ .var/dm/
circ_filt2_data[taps];/* 右通道输入数据缓冲器 */
由于两个通道将应用相同的滤波器系数,因此数据缓冲区的长度相等。
过滤器循环子例程期望使用特定的地址寄存器访问某些数据和系数值。具体而言,地址寄存器 I2 必须指向最早的数据样本,I5 必须指向调用筛选器例程之前的正确系数值。
由于左通道和右通道的过滤器将共享相同的内存指针,因此必须有一种机制来区分两个数据流。对于数据指针,I2,需要定义两个新变量,“filter1_ptr”和“filter2_ptr”。
内存中的这些位置将用于存储适用于每个数据流的地址值。ADSP-2181的循环缓冲功能用于确保每当执行滤波器时,数据指针始终位于缓冲器中的正确位置。由于子例程现在处理两个缓冲区,因此在完成每个通道的处理时需要保存指针位置。
要设置指针,需要在数据存储器中声明两个变量,如下所示:
.var/dm filter1_ptr;/* 左通道数据的数据指针 */ .var/
dm filter2_ptr;/* 右通道数据的数据指针 */
然后需要用每个数据缓冲区的起始地址初始化这些变量;
.init filter1_ptr: ^filt1_data;/* 初始化起点,
左通道 */
.init filter2_ptr: ^filt2_data;/* 初始化起点,
右通道 */
DSP 汇编软件将符号“^”识别为表示“地址”。DSP 链接器软件填写相应的地址值。这样,可执行程序中的指针变量就使用相应内存缓冲区的起始地址进行初始化。
以下清单显示了 FIR 过滤器中断例程如何使用这些新的内存元素。第 3 部分中的原始 Filter 子例程已修改为提供两个单独的筛选通道。例程必须首先加载相应的数据指针,而不是直接启动到筛选器计算中。然后调用筛选器例程,并将生成的输出放置在正确的位置进行传输。
/*--------------------FIR Filter--------------------*/
input_samples:
ena sec_reg; /* use shadow register bank */
/* set up for filter 1 */
i2 = dm(filter1_ptr); /* set data pointer for filter 1 */
ax0 = dm(rx_buf + 1); /* read left channel data */
dm(i2,m1) = ax0; /* write new data into delay line,
pointer now pointing to oldest data */
call filter; /* perform the first filter for left
channel data */
dm(tx_buf+1) = mr1; /* write left-channel output data */
dm(filter1_ptr) = i2; /* save updated filter1 data pointer */
/* set up for filter 2 */
i2 = dm(filter2_ptr); /* set data pointer for filter 2 */
ax0 = dm(rx_buf + 2); /* read right channel data */
dm(i2,m1) = ax0; /* write new data into delay line,
pointer now pointing to oldest data */
call filter; /* perform the filter again for the
right channel data */
dm(tx_buf+2) = mr1; /* write right channel output data */
dm(filter2_ptr) = i2; /* save updated filter2 data pointer */
rti; /* return from interrupt */
由于核心过滤器算法不再处理数据 I/O,因此只需添加更多指针变量并声明更多缓冲区空间(只要存在足够的内存!同样,通过设置包含系数缓冲区指针信息的变量,可以对两个筛选器使用不同的系数。无论哪种情况,都不需要更改过滤器算法。通过使用这种模块化编程风格,用户可以构建一个可调用的DSP函数库。因此,特定系统的差异可以简化为数据处理问题,而不是新算法的开发。虽然这种编程风格不一定允许算法更快地执行其任务,但系统设计人员在确定数据如何流经系统方面具有更大的灵活性。
实时接口问题:到目前为止,我们已经研究了嵌入式系统中的实时编程如何依赖于快速中断响应、高效的数据处理和快速的程序执行。此外,进出处理器的数据流也会影响系统在实时嵌入式环境中的工作情况。
流入和流出数字信号处理器的主数据可以是并行的,也可以是串行的。并行传输通常至少与处理器架构的本机数据字一样宽(ADSP-16系列处理器为2100位,SHARC为32位)。并行传输通过处理器的外部内存总线或外部主机接口总线进行。串行数据传输需要的互连要少得多;它们经常用于与数据转换器通信。®
串行接口:硬件接口的便利性是高效实现DSP系统的重要因素。ADSP-2181 EZ-Kit Lite系统使用AD1847串行编解码器(COder/DECoder)。串行编解码器允许通过 DSP 上的串行端口 (SPORT) 进行数据传输。此串口不是RS-232 PC式异步串口;它是一个 5 线同步接口,可传递位时钟、接收数据、发送数据和帧同步信号。串行接口的主要优点是引脚数少,易于硬件连接。AD1847仅需4个信号即可与DSP接口:串行时钟、接收数据、发送数据和接收帧同步信号。串行数据流是时分复用(TDM),这意味着同一物理线路可以按串行顺序传输多种类型的信息。在上一期启动的EZ-Kit Lite上的AD1847应用中,串行线路同时包含左声道和右声道音频信息,以及编解码器控制和状态信息。
如前所述,处理器具有处理此数据的各种方法。SPORT 中断由串行端口硬件自动生成,用于接收或传输数据以及单个字或字块(图 2)。数字信号处理器和I/O设备之间的串行接口
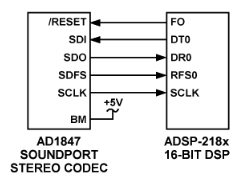
图2.数字信号处理器和 I/O 设备之间的串行接口。
并行接口:即使串行位时钟的运行速度与DSP处理器一样快,串行接口也会牺牲数据传输速度以简化布线,以DSP处理器速度的一小部分传输数据字。对于需要更高数据速率的系统性能,可以使用并行接口。并行接口时,DSP使用其外部数据和地址总线,以读取或写入外设的数据。在ADSP-2181上,总线最多可连接16位数据。
并行数据传输始终比串行传输更快。DSP可以在每个处理器周期执行外部访问,但这需要能够跟上它的非常快速的并行外设,例如快速SRAM芯片。与其他实体的并行数据传输通常在每个处理器周期不到一个的情况下发生。
串行接口和并行接口的中断处理是不同的。由于DSP处理器的外部数据总线是处理各种数据的通用实体,因此它没有用于中断生成和控制的专用信号线;但是,其他 DSP 资源也可用。在ADSP-2181上,多个外部硬件中断线(例如用于I/O存储器选择的中断线)可用于由外部器件(如A/D转换器或编解码器)触发。这种接口如图3所示,涉及一个并行器件和ADSP-2181 DSP。用于 DSP 的并行 I/O 接口
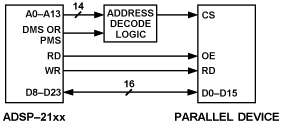
图3.用于 DSP 的并行 I/O 接口。
当响应并行数据的中断时,处理器读取适当的源,并通常通过执行类似于此处所示的指令将该数据值放在内存中:
irq2_svc: ax0 = IO(ad_converter);dm(i2,m1) = ax0;RTI;
“ad_converter”是 I/O 空间中先前定义的地址。
本文旨在详细介绍DSP开发人员在处理实时系统中的I/O和其他事件时面临的编程问题。引入的问题包括实时数据(样本和帧)、中断和中断处理、自动 I/O 以及通用化例程以创建可调用的子例程。这篇简短的文章无法公正地描述与每个主题相关的许多细节层次。更多信息可在以下参考资料中找到。本系列中的后续主题将继续基于此应用程序进行构建。下一篇文章将为我们不断增长的示例程序添加更多功能,并描述软件验证(即调试)技术。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
19312浏览量
230025 -
dsp
+关注
关注
553文章
8011浏览量
349120 -
滤波器
+关注
关注
161文章
7833浏览量
178240
发布评论请先 登录
相关推荐
AT89S51单片机的I/O端口的特点及使用注意事项有哪些
设计AVR单片机通用I/O口有哪些注意事项呢
数字信号处理器(DSP)
基于双数字信号处理器(DSP)的实时相关图像处理系统的设计
TN:选择数字信号处理器ADSP-21161与TMS360C6711/12的注意事项






 工商网监
工商网监
评论