 基于边界点优化和多步路径规划的机器人自主探索
基于边界点优化和多步路径规划的机器人自主探索

论文题目:Autonomous Robotic Exploration Based on Frontier Point Optimization and Multistep Path Planning
中文题目:基于边界点优化和多步路径规划的机器人自主探索
作者:Baofu Fang ;Jianfeng Ding ; Zaijun Wang
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8681502
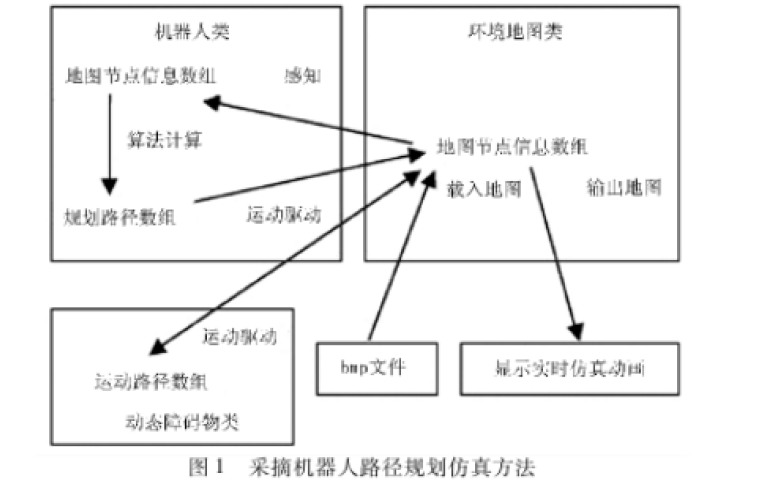
机器人对未知环境的自主探索是机器人智能化的关键技术。为了提高搜索效率,作者提出了一种基于边界点优化和多步路径规划的搜索策略。他们主要对边界点优化、边界点选择、路径规划三个方面对路径规划算法进行改进。在边界点优化部分,提出了一种随机边界点优化(RFPO)算法,选择评价值最高的边界点作为目标边界点。综合考虑信息增益、导航成本和机器人定位精度,来确定边界点的评价函数。在路径规划部分,提出了一个多步探索策略。没有直接规划从机器人当前位置到目标边界点的全局路径,而是设置了局部探索路径步长。当机器人的运动距离达到局部探索路径步长时,重新选择当前最优边界点进行路径规划,以减少机器人走一些重复路径的可能性。最后,通过相关实验验证了该策略的有效性。
1 前言
机器人自主探索是机器人领域的一个重要研究课题。主要目标是让机器人在有限时间且无需人工干预的情况下,获得最完整、最准确的环境地图。许多现有的地图探索策略都是基于边界,边界定义为未知空间与已知空间的分界线。基于边界的探索策略的思想是引导机器人到未知区域完成探索任务,因此自主探索任务一般分为三个步骤:生成边界点、选择评价值最高的边界点、规划前往所选边界点的路径。
边界点的生成以基于边界的探索策略为前提。在现有的研究中,常见地边界点生成算法有:
基于数字图像处理的边缘检测和区域提取技术:为了提取边界边缘,必须对整个地图进行处理,随着地图的扩展,处理它将消耗越来越多的计算资源。
Keidar和Kaminka后来提出了一种只处理新的激光读取数据的边界检测算法,加快了计算速度,降低了计算资源的消耗。
快速探索随机树(rapid-exploration Random Tree, RRT)算法:由于RRT算法的随机性,生成的边界点分布不均匀。
基于广度优先搜索(BFS)的方法:这种方法简单便捷,不重不漏,但在大地图环境下,相对于其他算法可能计算速度稍慢
目标边界点的选择是有效探索的关键。以边界为基础的战略是由Yamauchi首先提出的。所使用的探索策略是识别当前地图中的所有边界区域,然后驱动机器人前往最近的边界点。这种方法对于探索任务有两个缺点。首先,它平等对待所有边界。其次,它仅限于一个信息来源:寻找新边界区域。因此很多研究者提出了多种不同的边界点选择算法,来改善这一情况。这篇文章是综合考虑信息增益、导航成本和机器人定位精度,来确定边界点的评价函数。
最后是机器人的路径规划部分,对于机器人自主探索中路径规划的研究已经存在很多高效的算法:
基于A*的路径规划算法
基于RRT算法生成机器人搜索路径的算法
带有信息论目标函数的部分可观察马尔可夫决策过程(POMDP)
基于遗传算法(GA)的路径规划方法
为传统的基于边界的探测策增加一个概率决策步骤,以决定在计划路径上进一步移动到下一个传感位置是否可取。
2 最优边界点提取
2.1边界点的生成
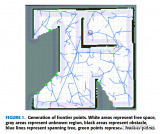
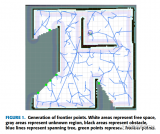
文中采用ROS平台下常见的SLAM算法--GMapping构建二维占用网格图,然后使用RRT算法在地图中生成边界点,如果新生成的点位于未知区域,则认为该点为边界点。它会被标记在地图上,然后我们停止这棵树的生长。将当前机器人的位置作为新的根节点,我们构建一个新的快速探索随机树来生成边界点。边界点生成示例如下图所示。
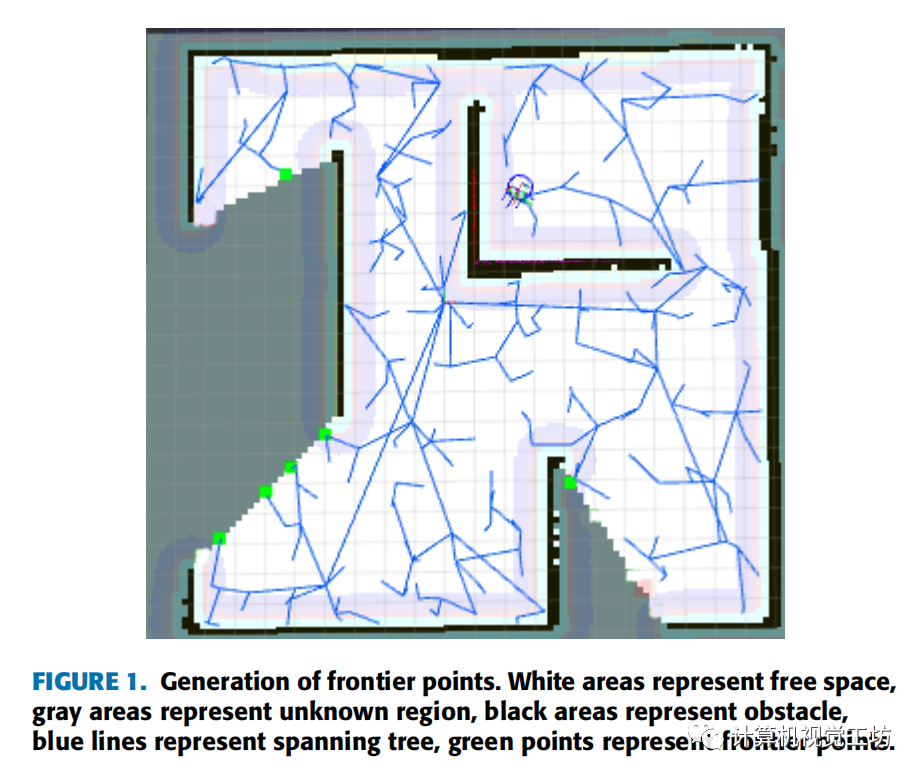
2.2边界点评价函数
文章从边界点的信息增益、导航成本和机器人定位精度三个方面对边界点进行评估。
信息增益被定义为对于一个给定边界点预期被探索的未知区域面积。本文采用直接测量目标边界点可见区域内未检测到的空间大小的方法计算信息增益。以边界点为圆心,以激光雷达探测距离为半径形成圆。边界点检测圈如下图所示。通过计算圆圈中未知单元格的数量来量化信息增益。
导航成本定义为机器人到达边界点的预期距离,使用机器人当前位置到目标边界点的欧氏距离来表示。
在目标边界点的探测范围内,如果能检测到更多的直线特征或其他特征(如断点、拐角、折线),机器人就能更准确地定位自己。文章用边界点检测圈内障碍物的面积来表示定位精度。通过计算圆圈中被占用的单元数来量化。边界点评价函数定义如下所示:
其中α、β、γ分别为信息增益、导航成本和障碍物面积的权重。这些权重用于调整不同因素的重要性,可根据不同的任务和环境进行设置。如果探索任务要求尽快完成探索,则增加α,降低γ;如果探索任务更注重地图的准确性,则减少α,增加γ。β通常取1表示单位导航成本下的增益值。利用边界点评价函数对所有边界点进行评价。选取值最大的点作为目标边界点。
PS:在计算导航成本时,如果环境地图过于复杂,可以选择使用A*规划出的路径长度作为导航成本项,但会造成过大的资源计算消耗;另外,作者提出的这种计算模型是比较合理的,导航成本在分母上,也就是说距离越大得分越低,信息增益和障碍物面积在分子上,机器人在选择目标点时,肯定倾向于选择信息增益高、导航精度高的目标点。
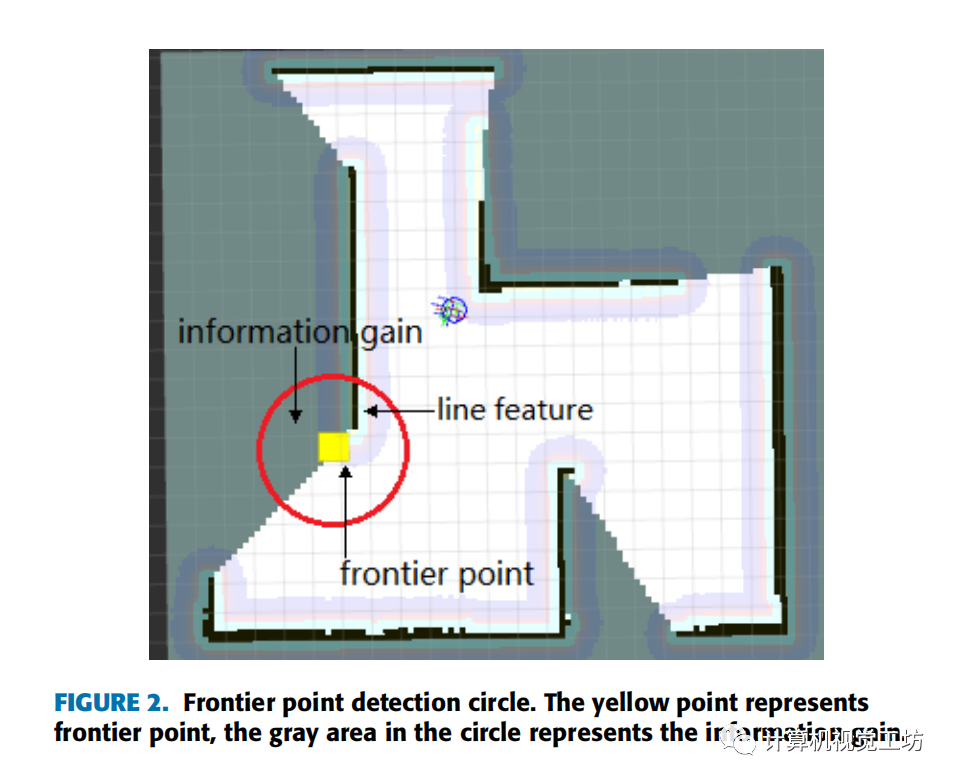
2.3随机边界点优化算法
由于边界点的生成部分始终运行在整个探测过程中,因此随着探测任务的执行,将得到许多边界点。然而,由于RRT算法的随机性,这些边界点的分布是不均匀的。因此,需要对生成的边界点进行优化。文中借鉴GSO算法的思想,提出RFPO算法。GSO算法是一种新型的仿生群体智能优化算法。它模拟了高亮度萤火虫会吸引低亮度萤火虫向其移动的自然现象,使所有萤火虫集中在一个更好的位置,从而实现问题的优化。在RFPO算法中,将每个边界点视为一只萤火虫,并将边界点评价函数的值E作为其绝对亮度值L:
萤火虫会被绝对亮度值更大的萤火虫所吸引,并向其移动。这种吸引力的大小由萤火虫对萤火虫的相对亮度值决定,萤火虫在萤火虫所在位置的亮度强度定义为萤火虫对萤火虫的相对亮度,相对亮度值越大,吸引力越大。然后对相对亮度进行建模。对于每个边界点,都有一个感知半径。它的值应根据感知传感器的范围来设置。在这个范围内,每一个边界点都会找到绝对亮度值大于自己的其他边界点,形成自己的邻域集。在邻域集中使用轮盘赌的方法,选择下一个要移动的目标点。
PS:这里的建模过程不是文章主要内容,就不过多展开,感兴趣可以在原文查看详细推导过程。
3 多步探索策略
采用多步探索的原因:在机器人运动的过程中,会产生一些新的边界点,一些旧的边界点会失效,而新生成的边界点可能会优于当前的最优目标边界点。这可能会导致机器人选择一些重复的路径。
文中解决方法:定义了一个局部探索路径步长。每次当机器人的运动距离达到步长时,就清除无效点,并对所有剩余的边界点进行重新优化和重新选择。在每个局部探索路径步长内,采用动态窗口法进行机器人避障局部路径规划。
PS:动态窗口法是ROS中常见地局部路径规划方法,主要思想是在速度空间中进行采样,生成下一时间步的模拟轨迹,然后根据评估函数选择得分最高的路径,驱动机器人移动。
如下图所示,黄色点为目标边界点。作者在不同的速度集上模拟了许多轨迹。根据他们定义的轨迹评价函数,选取得分最高的轨迹(下图中用红色标记的路径)。可以看出,机器人执行红色轨迹可以快速到达目标边界点。同时,轨迹与墙体有一定的安全距离,墙体边界可以帮助机器人更准确地定位自身。
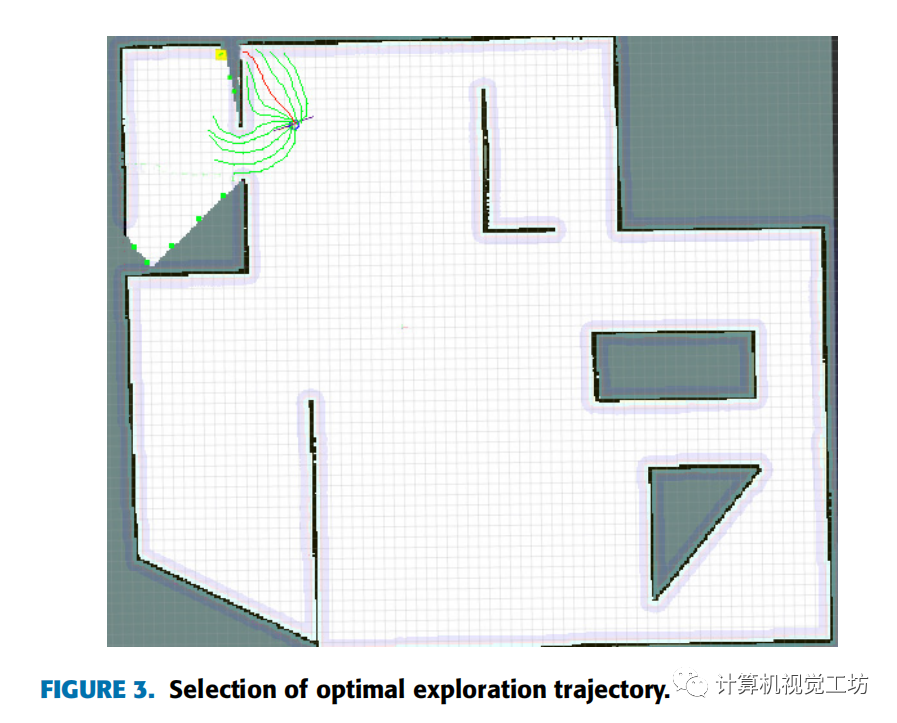
4 实验与结果
4.1 实验设置
通过仿真地图和真实地图对所提出策略的性能进行了实验验证,并与其他策略进行了比较。所有用于比较的策略都是在运行Ubuntu 14.04的Intel core i7 3.60GHz处理器和8GB RAM的计算机上使用ROS库在c++中开发为ROS组件。
文章实验参数表如下:
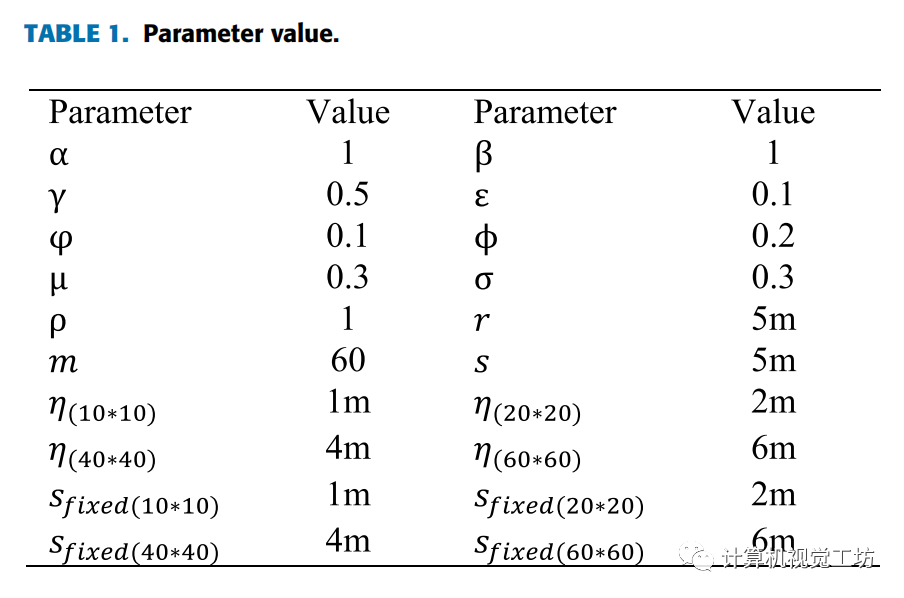
对于仿真环境,我们使用Gazebo模拟器构建一个封闭空间,如下图4(a)所示。考虑到地图尺寸变化的影响,使用了不同的地图尺寸(2020m, 4040m, 6060m)。机器人的半径为0.2m,激光传感器的范围设置为10m。图4(c)为在2020m的模拟环境中建立的二维占用网格图。
在真实环境中,作者利用挡板构建了一个10m * 10m的空间,如下图4(b)所示。实验中使用的移动机器人平台为EAIBOT Dashgo-D1。它配备了一个Hokuyo UST-10LX 2D激光传感器(10米的检测范围和270°视野)。图4(d)为在真实环境中构建的二维占用网格图。

4.2 边界点优化结果
如下图5(a)所示。由于RRT算法的随机性,边界点的位置都是随机的。可以看出,有的边界有很多边界点,有的边界只有很少的边界点。此外,在地图的各个边界上,边界点的分布也不均匀。图5(b)是用文中提出的算法生成的边界点。优化后边界点数量大大减少,各边界上的边界点分布基本均匀。黄色点是根据定义的边界点评价函数计算出的当前情况下的最优边界点。

4.3 多步探索策略的结果
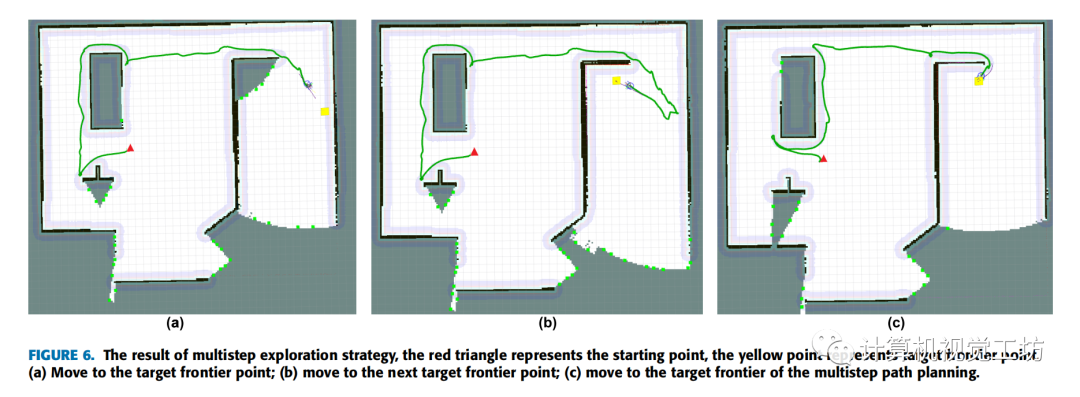
如图6(a)和图6(b)所示,在传统的全局路径规划策略下,机器人直接规划从当前位置到目标边界点的路径,并搜索下一个目标边界点,直到到达前一个目标边界点。
在多步路径规划策略中,每当机器人的运动距离达到确定的局部探索路径步长时,都会重新计算并重新选择最优边界点。从下面的图6(c)可以看出,在机器人到达图6(a)中的目标边界点之前,当前的最优边界点已经发生了变化。因此,机器人已经规划了一条新的路径。结果是图6(c)的路径长度明显短于图6(a)和图6(b)。
4.4 与其他策略的比较
文中总共进行了200组实验,将提出的策略与其他四种策略进行比较。策略1的思想是随机选择边界点进行探索,称之为RANDOM。策略2的思想是选择离机器人最近的边界点,用NEAREST来表示它。策略3采用了贪婪算法的思想,因此将其记为GREEDY。策略4是用UMARI来描述。本文中提出的策略称为RFPO。为了比较不同地图尺寸对探索策略的影响,作者使用了4张不同尺寸的地图进行实验(一张真实地图和3张不同尺寸的模拟地图)。每张地图都要进行50组探索作业。这50次探索分为5组,每组代表一种探索策略。在40*40 m的模拟地图中,对于每种策略,从10次探索运行中选择一个实验结果来显示机器人的探索轨迹。结果如图7所示。
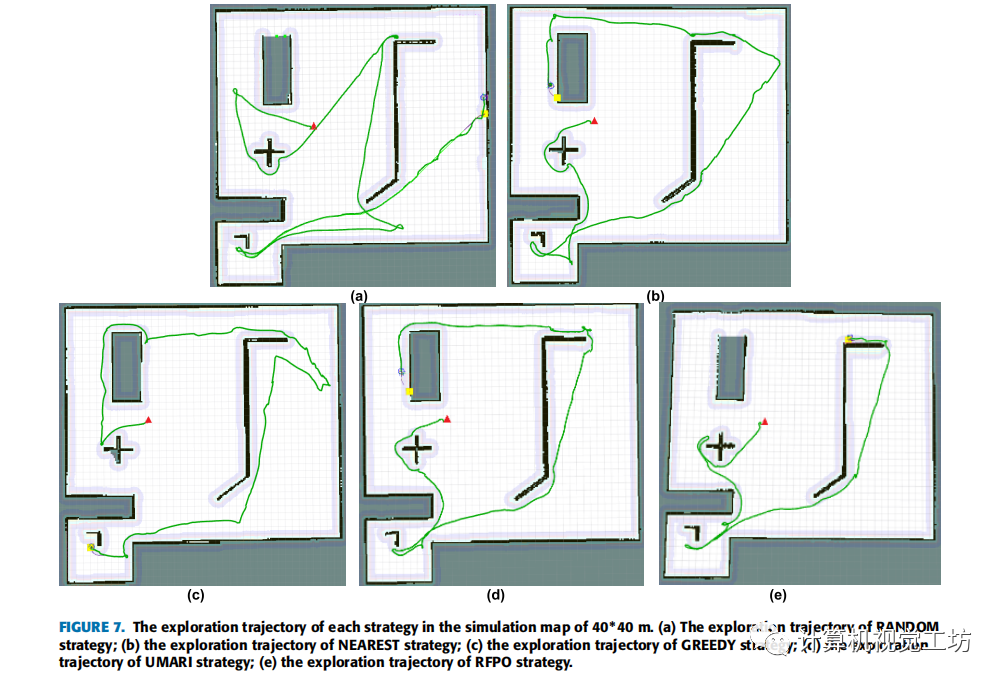
图8为四种不同地图中不同探索策略探索结束时的探索时间,图9为四种不同地图中不同探索策略探索结束时的探索距离。
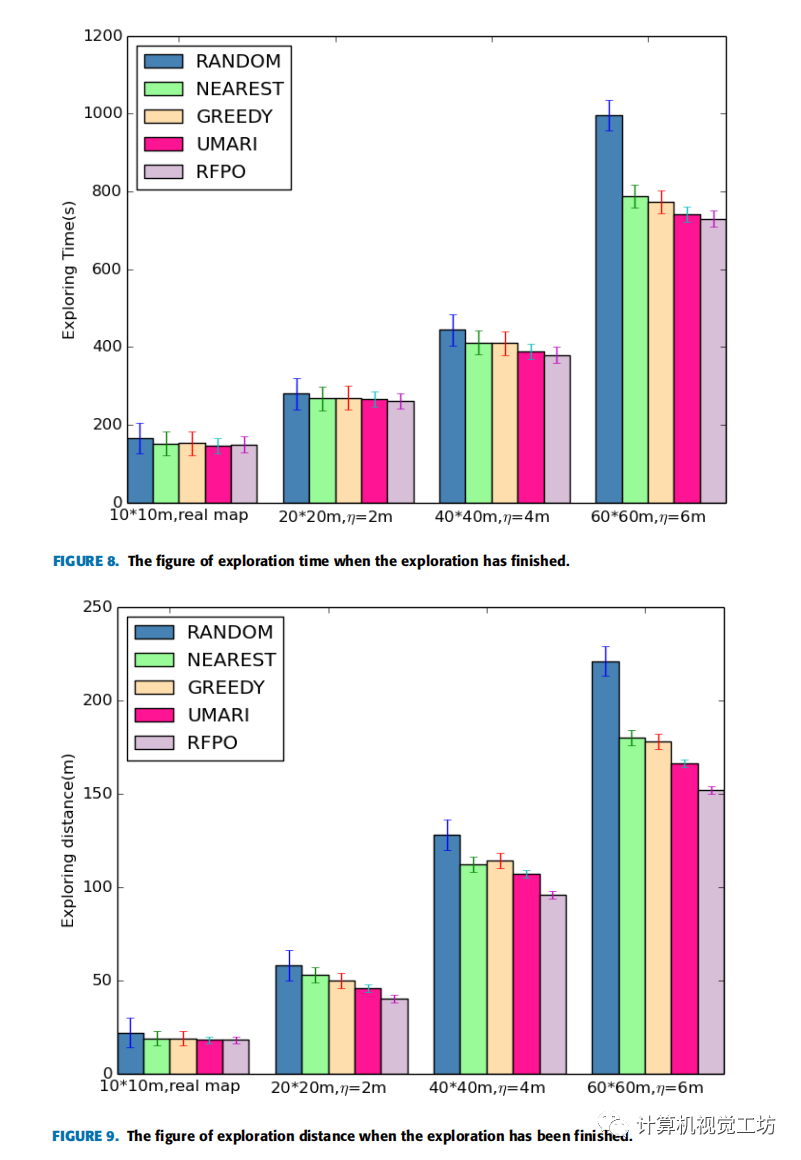
分析:从图中可以看出,地图的尺寸越大,不同策略之间探索效率的差异就越明显。在60*60m的模拟地图上,文中提出的策略与其他四种策略相比,平均探索时间分别减少了26.71%、7.36%、5.56%、1.62%,平均探索距离分别减少了31.22%、15.56%、14.61%、8.43%。
对于RANDOM策略来说,由于每次的目标边界点都是随机选择的,机器人会走很多重复的路线,所以探测时间和探测距离都会增加。
而NEAREST策略和GREEDY策略会导致搜索变成局部最优问题,影响搜索的效率。
UMARI的策略直接规划了机器人从当前位置到探测目标点的路径,这可能会导致图6中的问题。
实验结果表明,无论是与探测时间相比,还是与探测距离相比,文中提出的探测策略的效果都优于其他策略,证明了所提出策略的有效性。
5 总结
本文提出了一种基于边界点优化和多步路径规划的机器人自主探索策略。该策略可以驱动机器人探索未知环境,并在无需人工干预的情况下高效地构建相应的二维占用栅格地图。在这个探索策略中,作者使用RRT算法来生成边界点,并提出RFPO算法来优化这些边界点。然后定义了边界点评价函数,选取当前最优边界点进行探索。在路径规划部分,设置了一个局部探索路径步长,当机器人的运动距离达到局部探索路径步长时,重新选择目标边界点进行探索,以减少机器人走一些重复路径的可能性。最后通过实验,验证了所提策略的有效性。
未来改进:目前只使用里程计数据结合激光传感器数据来构建二维占用网格地图,地图中包含的信息相对较少。
可以将视觉传感器数据融合到自主探索中,视觉传感器数据的优点是可以获得更多的环境信息,这些数据可以被融合在一起,为以后的导航任务和其他相关工作构建具有更丰富信息的地图。
此外,可以尝试协调多个机器人进行高效探索。
-
机器人
+关注
关注
211文章
28837浏览量
209313 -
函数
+关注
关注
3文章
4350浏览量
63195 -
检测算法
+关注
关注
0文章
119浏览量
25277
发布评论请先 登录
相关推荐
【「具身智能机器人系统」阅读体验】2.具身智能机器人的基础模块
labview仿真问题,机器人路径规划
深度解析|机器人自主移动的秘密(三)
SLAM不等于机器人自主定位导航
移动机器人路径规划的实现
基于视觉导航和RBF的移动采摘机器人路径规划研究
移动机器人实现路径规划
基于RRT算法生成机器人搜索路径的算法





 工商网监
工商网监
评论