 Macaw-LLM:具有图像、音频、视频和文本集成的多模态语言建模
Macaw-LLM:具有图像、音频、视频和文本集成的多模态语言建模
文章:https://lnkd.in/gcwEeKE3
Python 代码:https://lnkd.in/ggEK6KwU
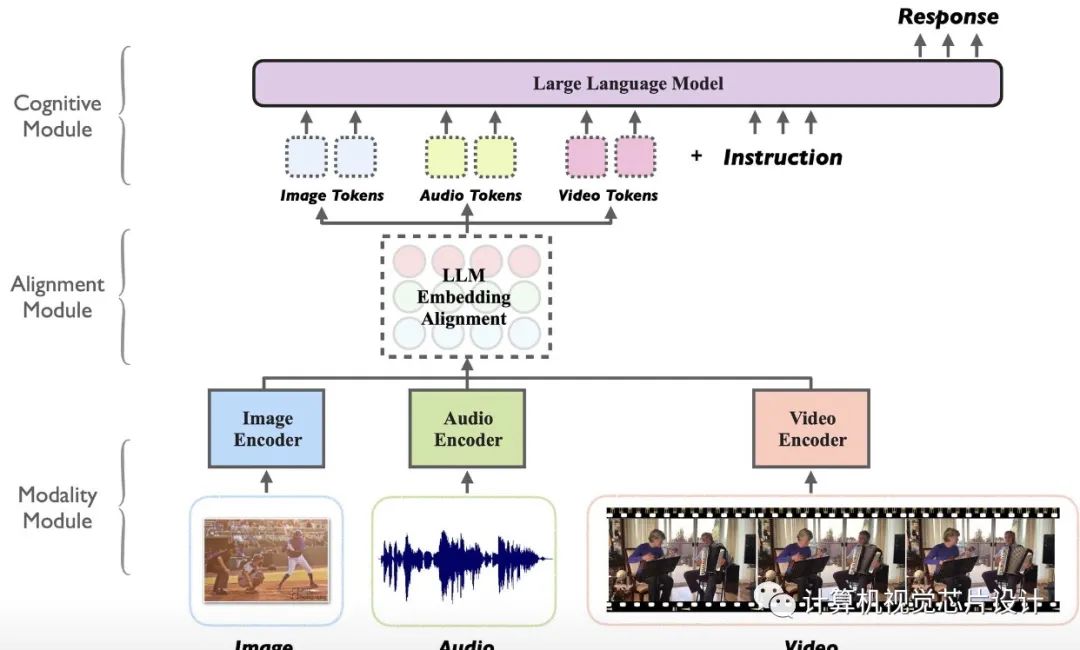
尽管指令调整的大型语言模型 (LLM) 在各种 NLP 任务中表现出卓越的能力,但它们在文本以外的其他数据模式上的有效性尚未得到充分研究。在这项工作中,我们提出了 Macaw-LLM,一种新颖的多模式 LLM,它无缝集成了视觉、音频和文本信息。
Macaw-LLM 由三个主要组件组成:用于编码多模态数据的模态模块、用于利用预训练 LLM 的认知模块以及用于协调不同表示的对齐模块。
我们新颖的对齐模块将多模态特征无缝地连接到文本特征,简化了从模态模块到认知模块的适应过程。
此外,我们在多轮对话方面构建了一个大规模的多模态指令数据集,包括 69K 图像实例和 50K 视频实例。我们已经公开了我们的数据、代码和模型,我们希望这可以为多模态 LLM 的未来研究铺平道路,并扩展 LLM 处理不同数据模态和解决复杂现实场景的能力。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
模块
+关注
关注
7文章
2740浏览量
47828 -
语言建模
+关注
关注
0文章
5浏览量
6281 -
语言模型
+关注
关注
0文章
545浏览量
10356 -
LLM
+关注
关注
0文章
302浏览量
441
原文标题:Macaw-LLM:具有图像、音频、视频和文本集成的多模态语言建模
文章出处:【微信号:计算机视觉芯片设计,微信公众号:计算机视觉芯片设计】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
自然语言处理的图像文本建模相关研究及分析
近年来,图像文本建模研究已经成为自然语言处理领域一个重要的硏究方向。图像常被用于增强句子的语义理解与表示。然而也有硏究人员对
发表于 03-24 11:33
•27次下载

简述文本与图像领域的多模态学习有关问题
模型中的几个分支角度,简述文本与图像领域的多模态学习有关问题。 1. 引言 近年来,计算机视觉和自然语言处理方向均取得了很大进展。而融合二者
复旦&微软提出OmniVL:首个统一图像、视频、文本的基础预训练模型
根据输入数据和目标下游任务的不同,现有的VLP方法可以大致分为两类:图像-文本预训练和视频-文本预训练。前者从图像-
微软多模态ChatGPT的常见测试介绍
研究者将一个基于 Transformer 的语言模型作为通用接口,并将其与感知模块对接。他们在网页规模的多模态语料库上训练模型,语料库包括了文本数据、任意交错的
发表于 03-13 11:23
•881次阅读
如何利用LLM做多模态任务?
大型语言模型LLM(Large Language Model)具有很强的通用知识理解以及较强的逻辑推理能力,但其只能处理文本数据。虽然已经发布的GPT4具备图片理解能力,但目前还未开放
邱锡鹏团队提出SpeechGPT:具有内生跨模态能力的大语言模型
虽然现有的级联方法或口语语言模型能够感知和生成语音,但仍存在一些限制。首先,在级联模型中,LLM 仅充当内容生成器。由于语音和文本的表示没有对齐,LLM 的知识无法迁移到语音

邱锡鹏团队提出具有内生跨模态能力的SpeechGPT,为多模态LLM指明方向
大型语言模型(LLM)在各种自然语言处理任务上表现出惊人的能力。与此同时,多模态大型语言模型,如

基于实体和动作时空建模的视频文本预训练
摘要 尽管常见的大规模视频-文本预训练模型已经在很多下游任务取得不错的效果,现有的模型通常将视频或者文本视为一个整体建模跨

用图像对齐所有模态,Meta开源多感官AI基础模型,实现大一统
最近,很多方法学习与文本、音频等对齐的图像特征。这些方法使用单对模态或者最多几种视觉模态。最终嵌入仅限于用于训练的

VisCPM:迈向多语言多模态大模型时代
随着 GPT-4 和 Stable Diffusion 等模型多模态能力的突飞猛进,多模态大模型已经成为大模型迈向通用人工智能(AGI)目标的下一个前沿焦点。总体而言,面向

大模型+多模态的3种实现方法
我们知道,预训练LLM已经取得了诸多惊人的成就, 然而其明显的劣势是不支持其他模态(包括图像、语音、视频模态)的输入和输出,那么如何在预训练


韩国Kakao宣布开发多模态大语言模型“蜜蜂”
韩国互联网巨头Kakao最近宣布开发了一种名为“蜜蜂”(Honeybee)的多模态大型语言模型。这种创新模型能够同时理解和处理图像和文本数据






 工商网监
工商网监
评论