 一文彻底搞懂YOLOv8(网络结构+代码+实操)
一文彻底搞懂YOLOv8(网络结构+代码+实操)
本文概述了YOLOv8算法的核心特性及改进点,详细介绍了网络结构、Loss计算、数据增强手段、训练策略、模型推理,对网络结构进行了详尽的分析,最后给出实操步骤。
0.引言
Section Name
Yolo系列对比:

1.概述
Section Name
YOLOv8 算法的核心特性和改动可以归结为如下:
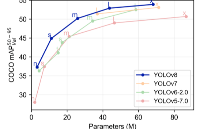
提供了一个全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于 YOLACT 的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
01
Backbone
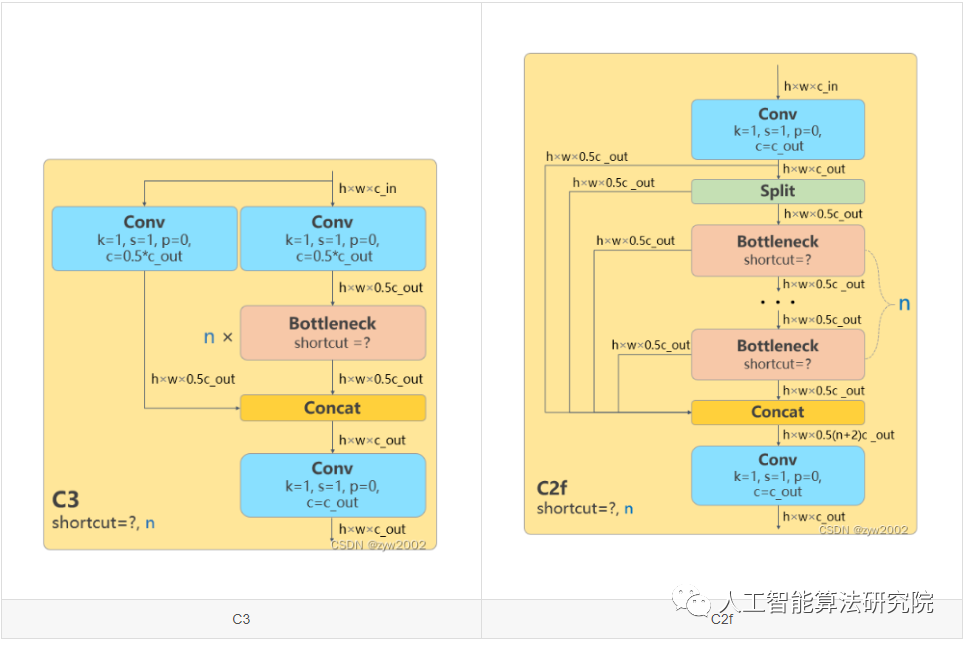
骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数。
属于对模型结构精心微调,不再是无脑一套参数应用所有模型,大幅提升了模型性能。不过这个 C2f 模块中存在 Split 等操作对特定硬件部署没有之前那么友好了
02
Head
Head部分较yolov5而言有两大改进:1)换成了目前主流的解耦头结构(Decoupled-Head),将分类和检测头分离 2)同时也从 Anchor-Based 换成了 Anchor-Free
03
Loss
1) YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner正负样本匹配方式。2)并引入了 Distribution Focal Loss(DFL)
04
Train
训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
从上面可以看出,YOLOv8 主要参考了最近提出的诸如 YOLOX、YOLOv6、YOLOv7 和 PPYOLOE 等算法的相关设计,本身的创新点不多,偏向工程实践,主推的还是 ultralytics 这个框架本身。
下面将按照模型结构设计、Loss 计算、训练数据增强、训练策略和模型推理过程共 5 个部分详细介绍 YOLOv8 目标检测的各种改进,实例分割部分暂时不进行描述。
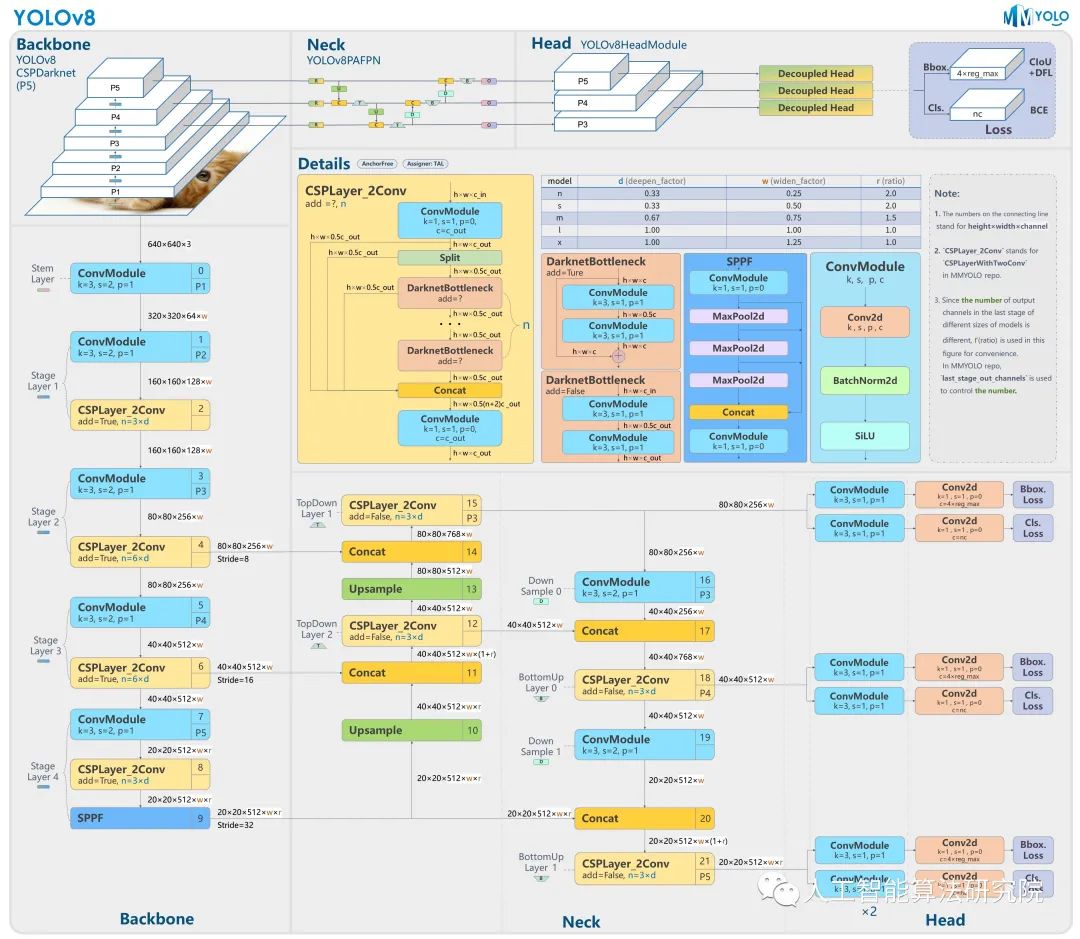
2.模型结构
Section Name
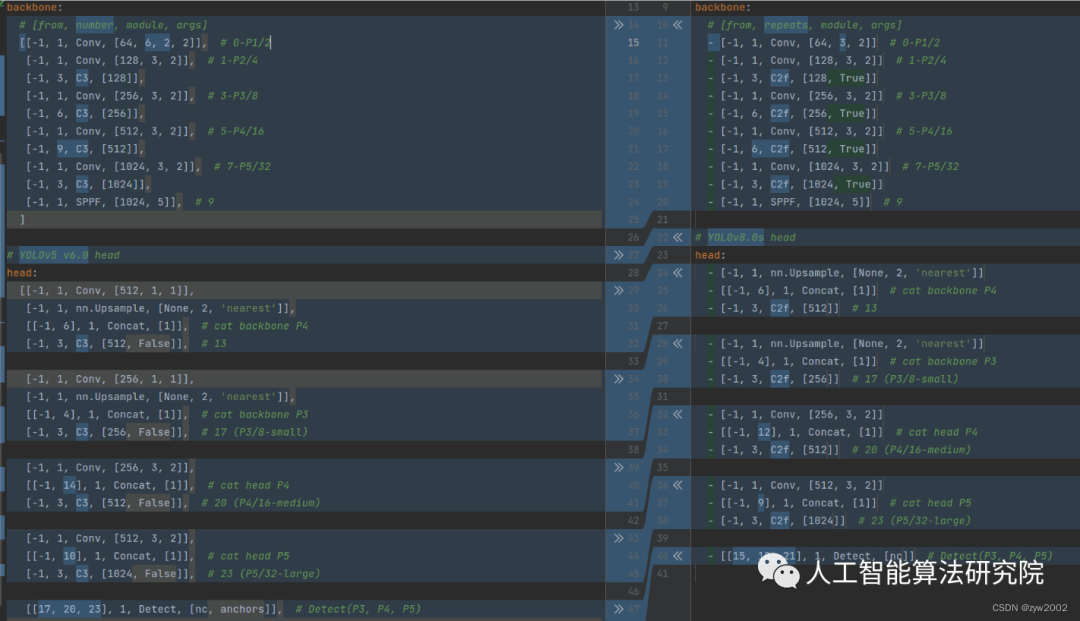
如下图, 左侧为 YOLOv5-s,右侧为 YOLOv8-s。
在暂时不考虑 Head 情况下,对比 YOLOv5 和 YOLOv8 的 yaml 配置文件可以发现改动较小。
01
Backbone和Neck的具体变化
a)第一个卷积层的 kernel 从 6x6 变成了 3x3
b)所有的 C3 模块换成 C2f,结构如下所示,可以发现多了更多的跳层连接和额外的 Split 操作
c)去掉了 Neck 模块中的 2 个卷积连接层
d) Backbone 中 C2f 的 block 数从 3-6-9-3 改成了 3-6-6-3
e) 查看 N/S/M/L/X 等不同大小模型,可以发现 N/S 和 L/X 两组模型只是改了缩放系数,但是 S/M/L 等骨干网络的通道数设置不一样,没有遵循同一套缩放系数。如此设计的原因应该是同一套缩放系数下的通道设置不是最优设计,YOLOv7 网络设计时也没有遵循一套缩放系数作用于所有模型
02
Head的具体变化
从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。
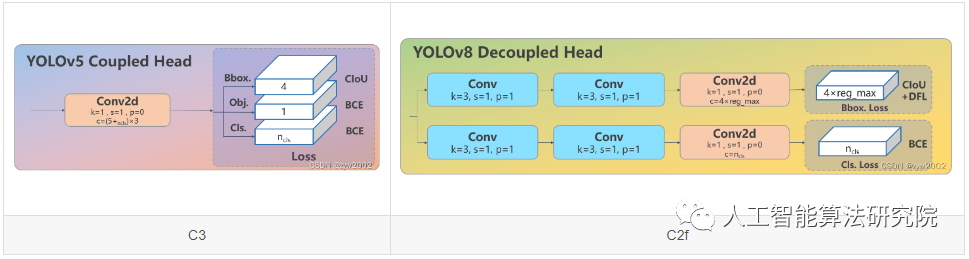
从上图可以看出,不再有之前的 objectness 分支,只有解耦的分类和回归分支,并且其回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法。
3.Loss 计算
Section Name
Loss 计算过程包括 2 个部分:正负样本分配策略和 Loss 计算。
01
正负样本分配策略
现代目标检测器大部分都会在正负样本分配策略上面做文章,典型的如 YOLOX 的 simOTA、TOOD 的 TaskAlignedAssigner 和 RTMDet 的 DynamicSoftLabelAssigner,这类 Assigner 大都是动态分配策略,而 YOLOv5 采用的依然是静态分配策略。考虑到动态分配策略的优异性,YOLOv8 算法中则直接引用了 TOOD 的 TaskAlignedAssigner。
TaskAlignedAssigner 的匹配策略简单总结为:根据分类与回归的分数加权的分数选择正样本。
02
Loss计算
Loss 计算包括 2 个分支:分类和回归分支,没有了之前的 objectness 分支。
分类分支依然采用 BCE Loss。回归分支需要和 Distribution Focal Loss 中提出的积分形式表示法绑定,因此使用了 Distribution Focal Loss, 同时还使用了 CIoU Loss。3 个 Loss 采用一定权重比例加权即可。
4.训练数据增强
Section Name
数据增强方面和 YOLOv5 差距不大,只不过引入了 YOLOX 中提出的最后 10 个 epoch 关闭 Mosaic 的操作。假设训练 epoch 是 500,其示意图如下所示:
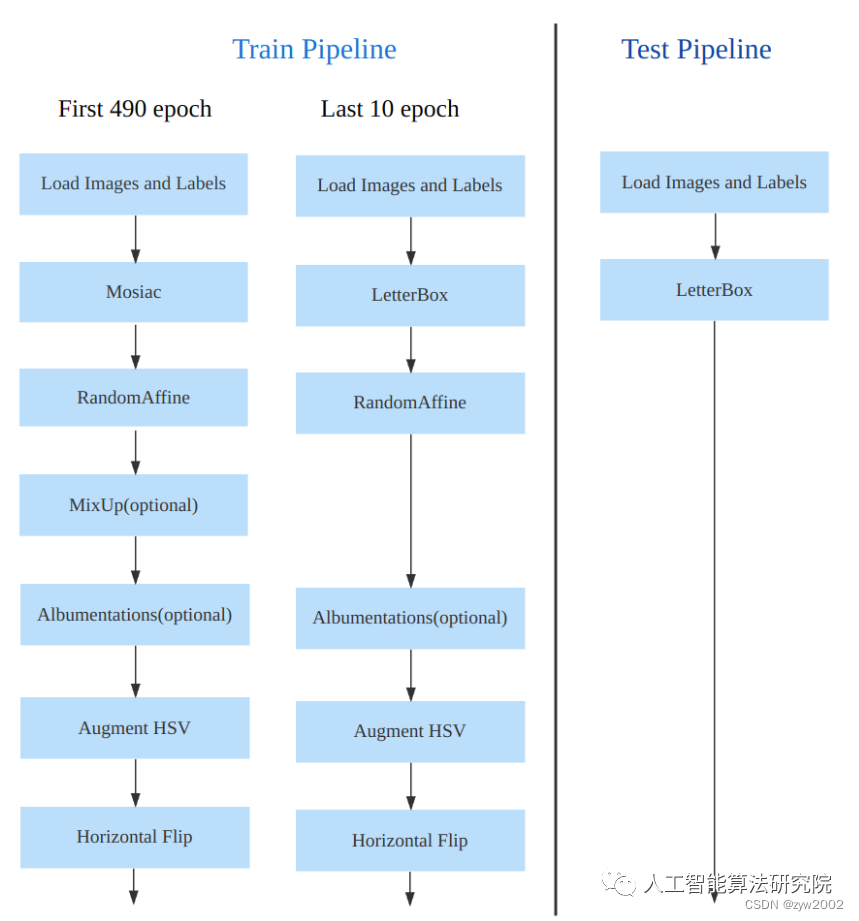
考虑到不同模型应该采用的数据增强强度不一样,因此对于不同大小模型,有部分超参会进行修改,典型的如大模型会开启 MixUp 和 CopyPaste。数据增强后典型效果如下所示:

5.训练策略
Section Name
YOLOv8 的训练策略和 YOLOv5 没有啥区别,最大区别就是模型的训练总 epoch 数从 300 提升到了 500,这也导致训练时间急剧增加。以 YOLOv8-S 为例,其训练策略汇总如下:

6.模型推理过程
Section Name
YOLOv8 的推理过程和 YOLOv5 几乎一样,唯一差别在于前面需要对 Distribution Focal Loss 中的积分表示 bbox 形式进行解码,变成常规的 4 维度 bbox,后续计算过程就和 YOLOv5 一样了。
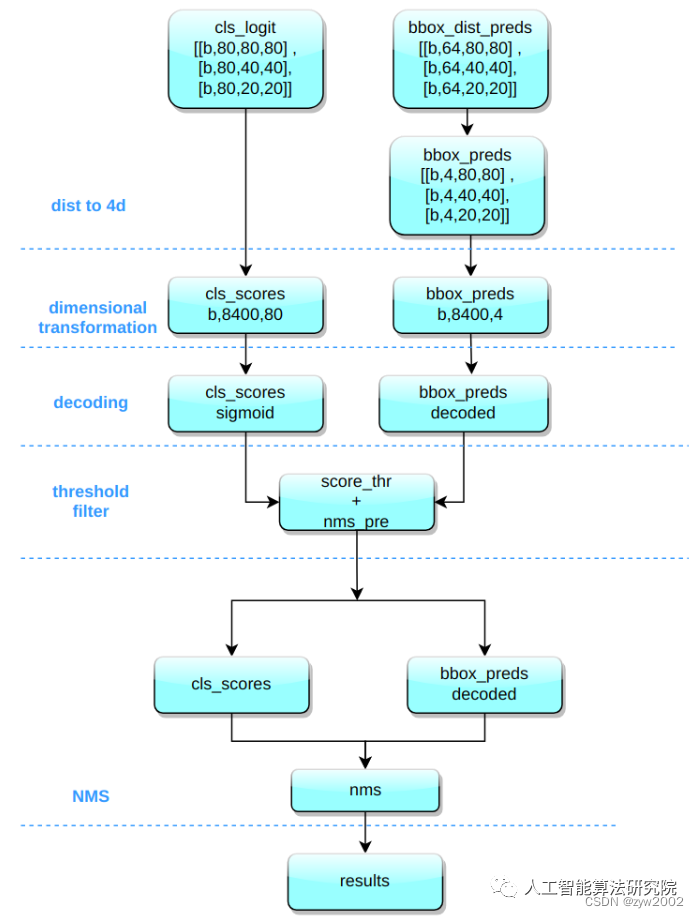
其推理和后处理过程为:
(1) bbox 积分形式转换为 4d bbox 格式
对 Head 输出的 bbox 分支进行转换,利用 Softmax 和 Conv 计算将积分形式转换为 4 维 bbox 格式
(2) 维度变换
YOLOv8 输出特征图尺度为 80x80、40x40 和 20x20 的三个特征图。Head 部分输出分类和回归共 6 个尺度的特征图。将 3 个不同尺度的类别预测分支、bbox 预测分支进行拼接,并进行维度变换。为了后续方便处理,会将原先的通道维度置换到最后,类别预测分支 和 bbox 预测分支 shape 分别为 (b, 80x80+40x40+20x20, 80)=(b,8400,80),(b,8400,4)。
(3) 解码还原到原图尺度
分类预测分支进行 Sigmoid 计算,而 bbox 预测分支需要进行解码,还原为真实的原图解码后 xyxy 格式。
(4) 阈值过滤
遍历 batch 中的每张图,采用 score_thr 进行阈值过滤。在这过程中还需要考虑 multi_label 和 nms_pre,确保过滤后的检测框数目不会多于 nms_pre。
(5) 还原到原图尺度和 nms
基于前处理过程,将剩下的检测框还原到网络输出前的原图尺度,然后进行 nms 即可。最终输出的检测框不能多于 max_per_img。
有一个特别注意的点:YOLOv5 中采用的 Batch shape 推理策略,在 YOLOv8 推理中暂时没有开启,不清楚后面是否会开启,在 MMYOLO 中快速测试了下,如果开启 Batch shape 会涨大概 0.1~0.2。
7.网络模型解析
Section Name
01
卷积神经单元(model.py)
在ultralytics/nn/modules.py文件中定义了yolov8网络中的卷积神经单元。
01
autopad
功能:返回pad的大小,使得padding后输出张量的大小不变。
参数:
k: 卷积核(kernel)的大小。类型可能是一个int也可能是一个序列。
p: 填充(padding)的大小。默认为None。
d: 扩张率(dilation rate)的大小, 默认为1 。普通卷积的扩张率为1,空洞卷积的扩张率大于1。
假设k为原始卷积核大小,d为卷积扩张率(dilation rate),加入空洞之后的实际卷积核尺寸与原始卷积核尺寸之间的关系:k =d(k-1)+1

def autopad(k, p=None, d=1): # kernel(卷积核), padding(填充), dilation(扩张)
# 返回pad的大小,使得padding后输出张量的shape不变
if d > 1: # 如果采用扩张卷积,则计算扩张后实际的kernel大小
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] #
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # 自动pad
returnp
02
Conv
-
功能:标准的卷积
-
参数:输入通道数(
c1), 输出通道数(c2), 卷积核大小(k,默认是1), 步长(s,默认是1), 填充(p,默认为None), 组(g, 默认为1), 扩张率(d,默认为1), 是否采用激活函数(act,默认为True, 且采用SiLU为激活函数)
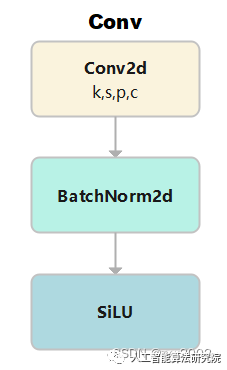
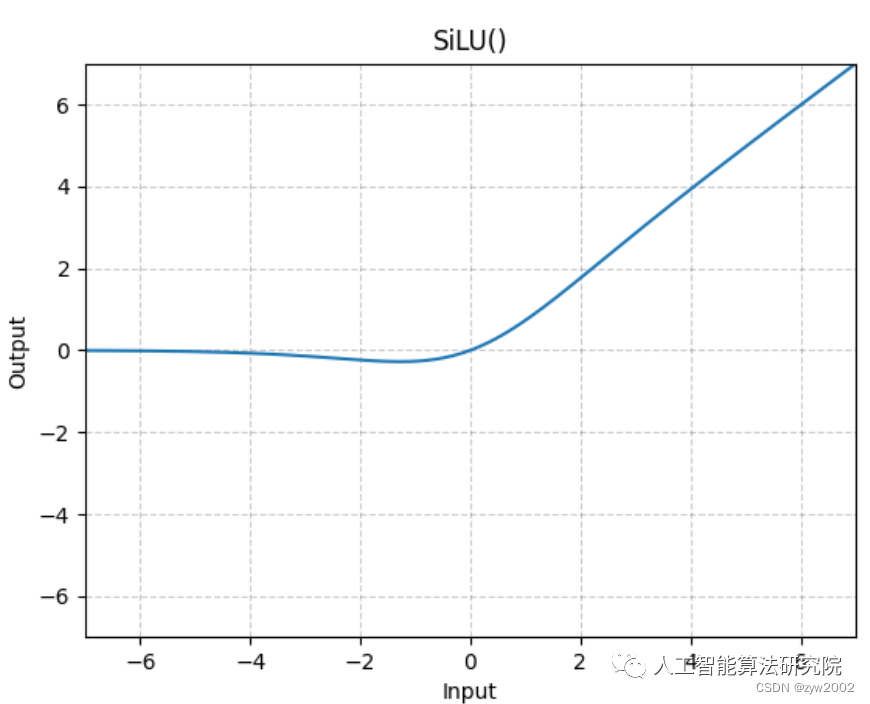
激活函数采用的是SiLU。
class Conv(nn.Module):
# 标准的卷积 参数(输入通道数, 输出通道数, 卷积核大小, 步长, 填充, 组, 扩张, 激活函数)
default_act = nn.SiLU() # 默认的激活函数
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False) # 2维卷积,其中采用了自动填充函数。
self.bn = nn.BatchNorm2d(c2) # 使得每一个batch的特征图均满足均值为0,方差为1的分布规律
# 如果act=True 则采用默认的激活函数SiLU;如果act的类型是nn.Module,则采用传入的act; 否则不采取任何动作 (nn.Identity函数相当于f(x)=x,只用做占位,返回原始的输入)。
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x): # 前向传播
return self.act(self.bn(self.conv(x))) # 采用BatchNorm
def forward_fuse(self, x): # 用于Model类的fuse函数融合 Conv + BN 加速推理,一般用于测试/验证阶段
returnself.act(self.conv(x))#不采用BatchNorm
03
DWConv
深度可分离卷积,继承自Conv。g=math.gcd(c1, c2)分组数是输入通道(c1)和输出通道(c2)的最大公约数。(因为分组卷积时,分组数需要能够整除输入通道和输出通道)
class DWConv(Conv):
# 深度可分离卷积
def __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activation
super().__init__(c1,c2,k,s,g=math.gcd(c1,c2),d=d,act=act)
04
DWConvTranspose2d
带有深度分离的转置卷积,继承自nn.ConvTranspose2dgroups=math.gcd(c1, c2)分组数是输入通道(c1)和输出通道(c2)的最大公约数。(因为分组卷积时,分组数需要能够整除输入通道和输出通道)
class DWConvTranspose2d(nn.ConvTranspose2d):
# Depth-wise transpose convolution
def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0): # 输入通道, 输出通道, 卷积核大小, 步长, padding, padding_out
super().__init__(c1,c2,k,s,p1,p2,groups=math.gcd(c1,c2))
05
ConvTranspose
和Conv类似,只是把Conv2d换成了ConvTranspose2d。
class ConvTranspose(nn.Module):
# Convolution transpose 2d layer
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=2, s=2, p=0, bn=True, act=True):
super().__init__()
self.conv_transpose = nn.ConvTranspose2d(c1, c2, k, s, p, bias=not bn)
self.bn = nn.BatchNorm2d(c2) if bn else nn.Identity()
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
returnself.act(self.bn(self.conv_transpose(x)))
06
DFL(Distribution Focal Loss)
本篇文章(https://ieeexplore.ieee.org/document/9792391)提出了GFL(了Generalized Focal Loss)。GFL具体又包括Quality Focal Loss(QFL)和Distribution Focal Loss(DFL),其中QFL用于优化分类和质量估计联合分支,DFL用于优化边框分支。
class DFL(nn.Module):
# Integral module of Distribution Focal Loss (DFL) proposed in Generalized Focal Loss
def __init__(self, c1=16):
super().__init__()
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1
def forward(self, x):
b, c, a = x.shape # batch, channels, anchors
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
# return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)
07
TransformerLayer

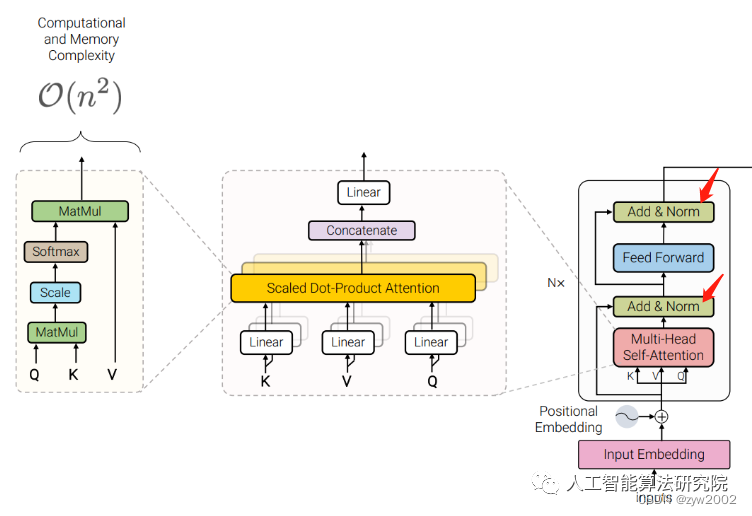
我们可以发现它和yolo中的TransformerLayer部分只是少了层规范化(LayerNorm),以及在Feed-Forward Networks 中只采用了两个不带偏置线性层,且没有采用激活函数。
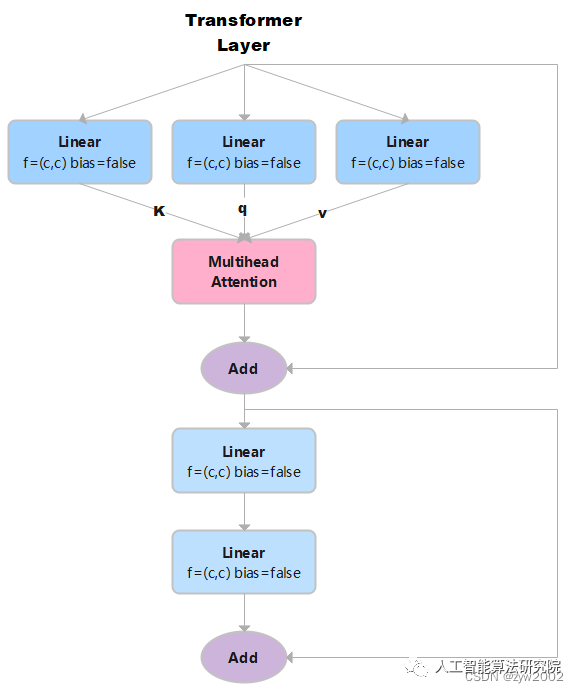
TransformerLayer代码实现如下:
class TransformerLayer(nn.Module):
# Transformer layer (LayerNorm layers removed for better performance)
def __init__(self, c, num_heads): # c: 词特征向量的大小 num_heads 检测头的个数。
super().__init__()
self.q = nn.Linear(c, c, bias=False)# 计算query, in_features=out_features=c
self.k = nn.Linear(c, c, bias=False)# 计算key
self.v = nn.Linear(c, c, bias=False)# 计算value
self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads) # 多头注意力机制
self.fc1 = nn.Linear(c, c, bias=False)
self.fc2 = nn.Linear(c, c, bias=False)
def forward(self, x):
x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x # 多头注意力机制+残差连接
x = self.fc2(self.fc1(x)) + x # 两个全连接层+ 残差连接
returnx
如果输入是x,x的大小是(s,n,c) 。其中n是batch size, s是源序列长度,c是词特征向量的大小(embed_dim)。
然后x分别通过3个Linear层 (线性层的结构相同,但是可学习参数不同)计算得到键k、查询q、值v。因为线性层的输入特征数和输出特征数均等于c, 所以k,q,v的大小也是(s,n,c)。
接着,把k、q、v作为参数输入到多头注意力ma中,返回两个结果attn_output(注意力机制的输出)和attn_output_weights(注意力机制的权重)。在这里,我们只需要注意力机制的输出就可以,因此,我们取索引0 self.ma(self.q(x), self.k(x), self.v(x))[0],它的大小是(s,n,c)。+x 表示残差连接,不改变x的形状。
self.fc2(self.fc1(x)) 表示经过两个全连接层,输出大小是(s,n,c)。+x 表示残差连接,不改变x的形状。因此最终输出的形状大小和输入的形状一样。
08
Transformer Block
TransformerBlock是把若干个TransformerLayer串联起来。
对于图像数据而言,输入数据形状是 [batch, channel, height, width],变换成 [height × width, batch, channel]。height × width把图像中各个像素点看作一个单词,其对应通道的信息连在一起就是词向量。channel就是词向量的长度。
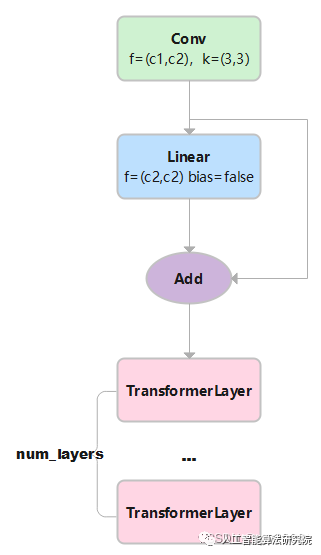
TransformerBlock的实现代码如下:
class TransformerBlock(nn.Module):
def __init__(self, c1, c2, num_heads, num_layers):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
self.linear = nn.Linear(c2, c2) # learnable position embedding
self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
self.c2 = c2
def forward(self, x): # x:(b,c1,w0,h0)
if self.conv is not None:
x = self.conv(x) # x:(b,c2,w,h)
b, _, w, h = x.shape
p = x.flatten(2).permute(2, 0, 1) # flatten后:(b,c2,w*h) p: (w*h,b,c2)
# linear后: (w*h,b,c2) tr后: (w*h,b,c2) permute后: (b,c2,w*h) reshape后:(b,c2,w,h)
returnself.tr(p+self.linear(p)).permute(1,2,0).reshape(b,self.c2,w,h)
1)输入的x大小为(b,c1,w,h)。其中b为batch size, c1 是输入通道数大小, w 和h 分别表示图像的宽和高。
2)经过Conv层:Conv层中的2d卷积,卷积核大小是1x1, 步长为1,无填充,扩张率为1。因此不改变w和h, 只改变输出通道数,形状变为(b,c2,w,h)。Conv层中的BN和SiLU不改变形状大小。输出的x大小为(b,c2,w,h)
3)对x进行变换得到p: x.flatten(2)后,大小变为 (b,c2,w*h) permute(2, 0, 1)后,p的大小为(w*h,b,c2)
4) 将p输入到线性层后,因为线性层的输入特征数和输出特征数相等,因此输出的大小为(w*h,b,c2)。
+p 进行残差连接后,大小不变,仍为(w*h,b,c2)
5) 然后将上一步的结果输入到num_layers个TransformerLayer中。w*h 相当于序列长度,b是批量的大小,c2相当于词嵌入特征长度。每个TransformerLayer的输入和输出的大小不变。经过若干个TransformerLayer后,大小是(w*h,b,c2)。
6)permute(1, 2, 0)后: 形状变为(b,c2,w*h) reshape(b, self.c2, w, h)后:(b,c2,w,h)
09
Bottleneck
先使用 3x3 卷积降维,剔除冗余信息;再使用 3×3 卷积升维。
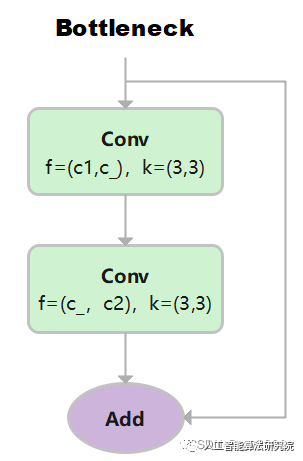
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1) # 输入通道: c1, 输出通道:c_ , 卷积核:3x3, 步长1
self.cv2 = Conv(c_, c2, k[1], 1, g=g) # 输入通道:c_ , 输出通道c2, 卷积核:3x3, 步长1
self.add = shortcut and c1 == c2 # 当传入的shortcut参数为true,且c1和c2相等时,则使用残差连接。
def forward(self, x):
returnx+self.cv2(self.cv1(x))ifself.addelseself.cv2(self.cv1(x))
第一层卷积,输入通道: c1, 输出通道:c_ , 卷积核:3x3, 步长1
第一层卷积,输入通道: c_, 输出通道:c2 , 卷积核:3x3, 步长1
其中c _ = c2/2。当c1和c2相等时,采用残差连接。
10
BottleneckCSP
详细请参考CSPNet的论文和源码。论文《CSPNet: A New Backbone that can Enhance Learning Capability of CNN》
源码https://github.com/WongKinYiu/CrossStagePartialNetworks
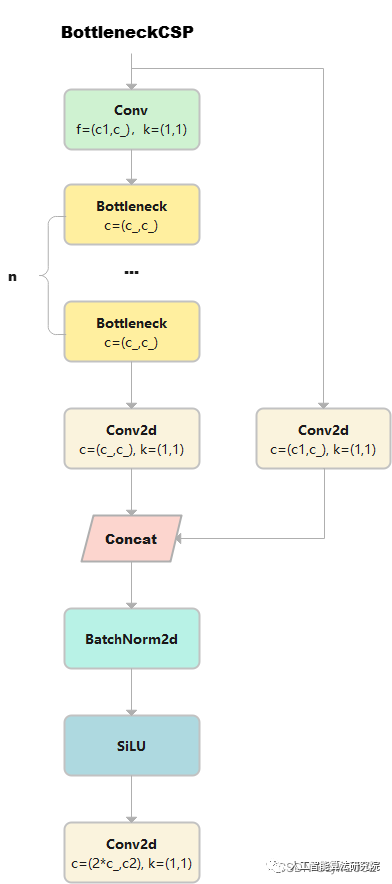
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
# 输出x的大小是(b,c1,w,h)
self.cv1 = Conv(c1, c_, 1, 1) # cv1的大小为(b,c_,w,h)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False) # cv2的大小为(b,c_,w,h)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False) # m通过Conv2d,变成cv3,大小是(b,c_,w,h)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.SiLU()
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
# cv1通过n个串联的bottleneck,变成m,大小为(b,c_,w,h)
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x))) # (b,c_,w,h)
y2 = self.cv2(x) # (b,c_,w,h)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))
# cat后:(b,2*c_,w,h) 返回cv4: (b,c2,w,h)
1)输出x的大小是(b,c1,w,h), 然后有两条计算路径分别计算得到y1和y2。
y1的计算路径:先x通过cv1,大小变成(b,c_,w,h) 。cv1通过n个串联的bottleneck,变成m,大小为(b,c_,w,h)。m通过cv3, 得到y1, 大小是(b,c_,w,h)
y2的计算路径:x通过cv2得到y2,大小是(b,c_,w,h)
2)y1和y2在dim=1处连接, 大小是(b,2*c_,w,h), 然后再通过BN和SiLU,大小不变。
3)最终,通过cv4, 返回结果的大小是(b,c2,w,h)
11
C3
与 BottleneckCSP 类似,但少了 1 个 Conv、1 个 BN、1 个 Act,运算量更少。总共只有3次卷积(cv1,cv2,cv3)。
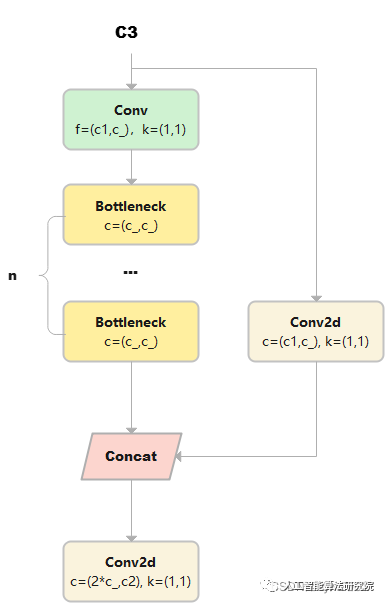
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
returnself.cv3(torch.cat((self.m(self.cv1(x)),self.cv2(x)),1))
12
C2
C2只有两个卷积(cv1,cv2)的CSP Bottleneck。
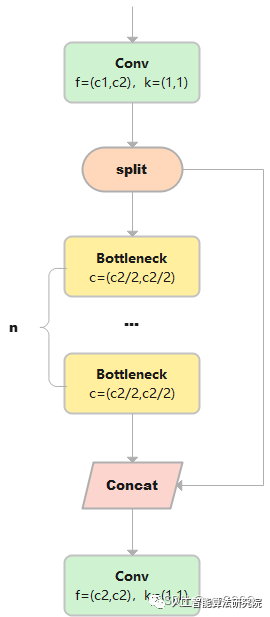
class C2(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
# 假设输入的x大小是(b,c1,w,h)
self.c = int(c2 * e) # hidden channels e=0.5,对输出通道进行平分。
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # cv1的大小是(b,c2,w,h)
self.cv2 = Conv(2 * self.c, c2, 1) # optional act=FReLU(c2)
# self.attention = ChannelAttention(2 * self.c) # or SpatialAttention() #此处可以使用空间注意力或者跨通道的注意力机制。
self.m = nn.Sequential(*(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))) # a通过n个串联的Bottleneck后的到m,m的大小是(b,c,w,h)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), 1)# 对cv进行在维度1进行平分,a和b的大小都是(b,c,w,h)
returnself.cv2(torch.cat((self.m(a),b),1))#把m和b在维度1进行cat后,大小是(b,c2,w,h)。最终通过cv2,大小是(b,c2,w,h)
1)输出x的大小是(b,c1,w,h), 通过Conv层,得到cv1, cv1的大小是(b,c2,w,h)
2) 然后再dim=1的维度上对cv1进行分割,a和b的大小都是(b,c2/2,w,h)。
3) a通过n个串联的Bottleneck后的到m,m的大小是(b,c,w,h)
4) 把m和b在维度1进行cat后,大小是(b,c2,w,h)。最终m通过cv2,输出的大小是(b,c2,w,h)
13
C2f
C2f与C2相比,每个Bottleneck的输出都会被Concat到一起。
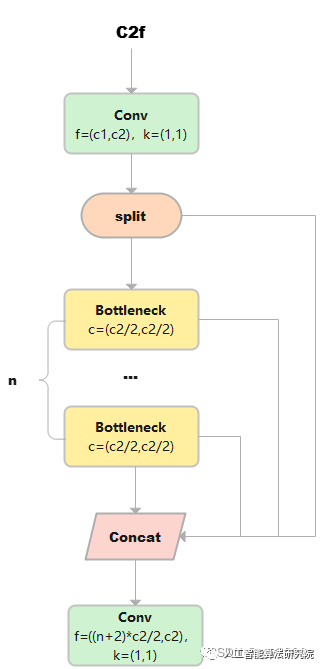
class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
# 假设输入的x大小是(b,c1,w,h)
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # cv1的大小是(b,c2,w,h)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n)) # n个Bottleneck组成的ModuleList,可以把m看做是一个可迭代对象
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
# cv1的大小是(b,c2,w,h),对cv1在维度1等分成两份(假设分别是a和b),a和b的大小均是(b,c2/2,w,h)。此时y=[a,b]。
y.extend(m(y[-1]) for m in self.m)
# 然后对列表y中的最后一个张量b输入到ModuleList中的第1个bottleneck里,得到c,c的大小是(b,c2/2,w,h)。然后把c也加入y中。此时y=[a,b,c]
# 重复上述操作n次(因为是n个bottleneck),最终得到的y列表中一共有n+2个元素。
return self.cv2(torch.cat(y, 1))
# 对列表y中的张量在维度1进行连接,得到的张量大小是(b,(n+2)*c2/2,w,h)。
#最终通过cv2,输出张量的大小是(b,c2,w,h)
1)cv1的大小是(b,c2,w,h),对cv1在维度1等分成两份(假设分别是a和b),a和b的大小均是(b,c2/2,w,h)。此时y=[a,b]。
2)然后对列表y中的最后一个张量b输入到ModuleList中的第1个bottleneck里,得到c,c的大小是(b,c2/2,w,h)。然后把c也加入y中。此时y=[a,b,c]。
3)上述步骤重复上述操作n次(因为是n个bottleneck),最终得到的y列表中一共有n+2个元素。
4)对列表y中的张量在维度1进行连接,得到的张量大小是(b,(n+2)*c2/2,w,h)。
5)最终通过cv2,输出张量的大小是(b,c2,w,h)
14
ChannelAttention
通道注意力模型: 通道维度不变,压缩空间维度。该模块关注输入图片中有意义的信息。
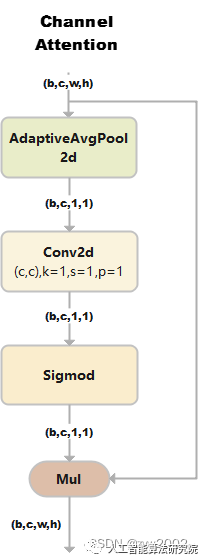
class ChannelAttention(nn.Module):
# Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet
def __init__(self, channels: int) -> None:
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化后,大小为(b,c,1,1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
self.act = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
returnx*self.act(self.fc(self.pool(x)))
1)假设输入的数据大小是(b,c,w,h)
2)通过自适应平均池化使得输出的大小变为(b,c,1,1)
3)通过2d卷积和sigmod激活函数后,大小是(b,c,1,1)
4)将上一步输出的结果和输入的数据相乘,输出数据大小是(b,c,w,h)。
15
SpatialAttention
空间注意力模块:空间维度不变,压缩通道维度。该模块关注的是目标的位置信息。
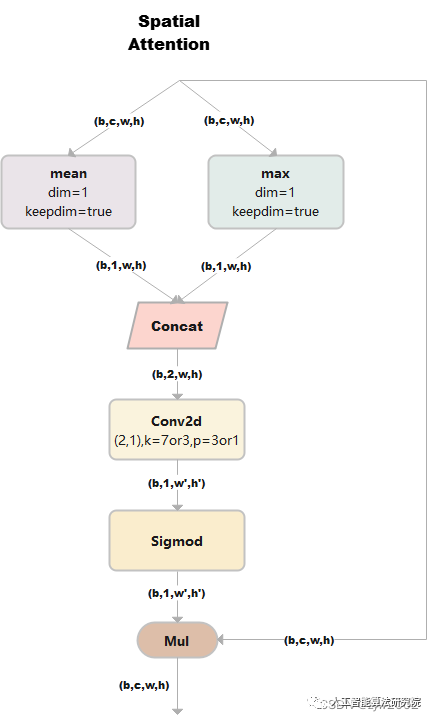
class SpatialAttention(nn.Module):
# Spatial-attention module
def __init__(self, kernel_size=7):
super().__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7' # kernel size 的大小必须是3或者7
padding = 3 if kernel_size == 7 else 1 # 当kernel_size是7时,padding=3; 当kernel_size是3时,padding=1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):
returnx*self.act(self.cv1(torch.cat([torch.mean(x,1,keepdim=True),torch.max(x,1,keepdim=True)[0]],1)))
1) 假设输入的数据x是(b,c,w,h),并进行两路处理。
2)其中一路在通道维度上进行求平均值,得到的大小是(b,1,w,h);另外一路也在通道维度上进行求最大值,得到的大小是(b,1,w,h)。
3) 然后对上述步骤的两路输出进行连接,输出的大小是(b,2,w,h)
4)经过一个二维卷积网络,把输出通道变为1,输出大小是(b,1,w,h)
4)将上一步输出的结果和输入的数据x相乘,最终输出数据大小是(b,c,w,h)。
16
CBAM
CBAM就是把ChannelAttention和SpatialAttention串联在一起。
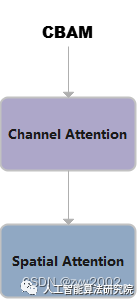
class CBAM(nn.Module):
# Convolutional Block Attention Module
def __init__(self, c1, kernel_size=7): # ch_in, kernels
super().__init__()
self.channel_attention = ChannelAttention(c1)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
return self.spatial_attention(self.channel_attention(x))
17
C1
总共只有3次卷积(cv1,cv2,cv3)的Bottleneck。
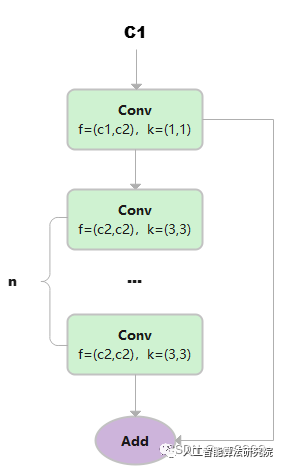
class C1(nn.Module):
# CSP Bottleneck with 1 convolution
def __init__(self, c1, c2, n=1): # ch_in, ch_out, number
super().__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.m = nn.Sequential(*(Conv(c2, c2, 3) for _ in range(n)))
def forward(self, x):
y = self.cv1(x)
returnself.m(y)+y
1)假设输入的数据是(b,c1,w,h)
2) 首先通过一个Conv块,得到y, 大小为(b,c2,w,h)
3) 然后让y通过n个3x3的Conv块,得到m
4) 最后让m和y相加。
18
C3x
C3x 继承自C3, 变换是Bottleneck中的卷积核大小变为(1,3)和(3,3)
class C3x(C3):
# C3 module with cross-convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
self.c_ = int(c2 * e)
self.m=nn.Sequential(*(Bottleneck(self.c_,self.c_,shortcut,g,k=((1,3),(3,1)),e=1)for_inrange(n)))
19
C3TR
C3TR继承自C3, n 个 Bottleneck 更换为 1 个 TransformerBlock。
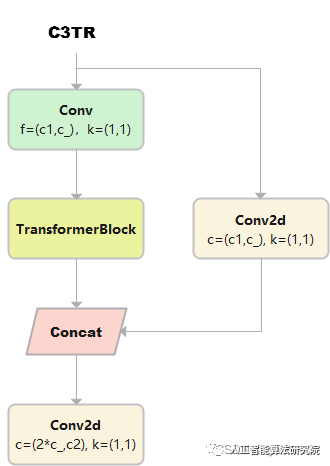
class C3TR(C3):
# C3 module with TransformerBlock()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = TransformerBlock(c_, c_, 4, n)# num_heads=4, num_layers=n
20
SPP
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
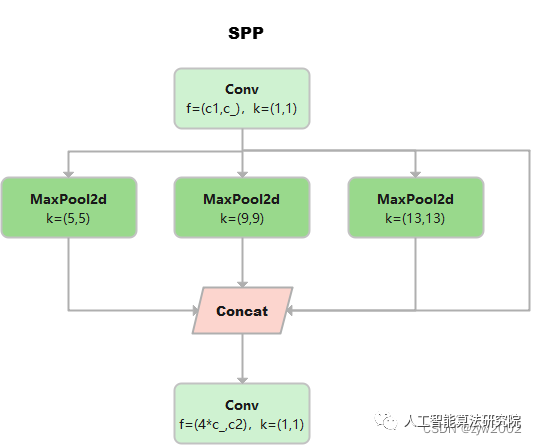
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
returnself.cv2(torch.cat([x]+[m(x)forminself.m],1))
21
SPPF
这个是YOLOv5作者Glenn Jocher基于SPP提出的,速度较SPP快很多,所以叫SPP-Fast。
三个MaxPool 串行连接,kerner size都是5*5。效果等价于SPP,但是运算量从原来的5^2 + 9^2 + 13^2 = 275减少到3* 5^2 =75
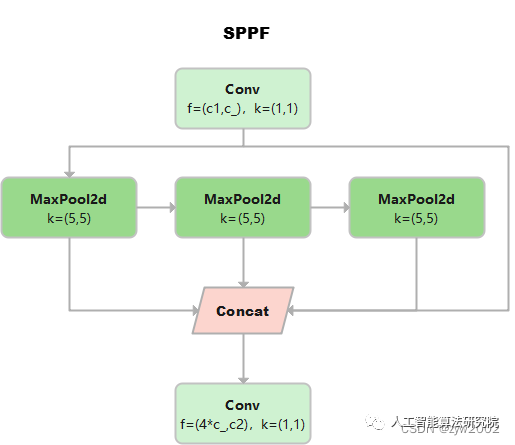
池化尺寸等价于SPP中kernel size分别为5 * 5,9 * 9和13 * 13的池化层并行连接。
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
returnself.cv2(torch.cat((x,y1,y2,self.m(y2)),1))
22
Focus
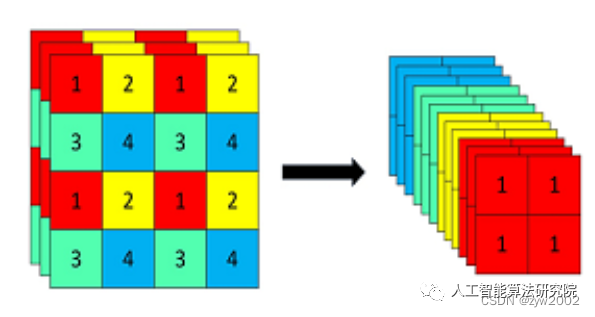
Focus模块在v5中是图片进入backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长的差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
例如:原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。切片操作如下
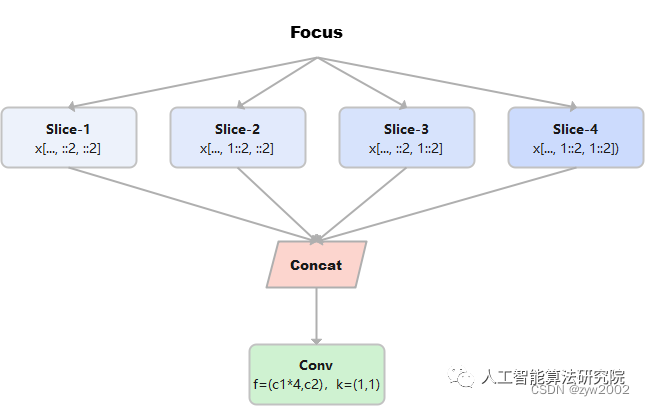
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
#returnself.conv(self.contract(x))
23
GhostConv
Ghost卷积来自华为诺亚方舟实验室,《GhostNet: More Features from Cheap Operations》发表于2020年的CVPR上。提供了一个全新的Ghost模块,旨在通过廉价操作生成更多的特征图。
原理如下图所示:
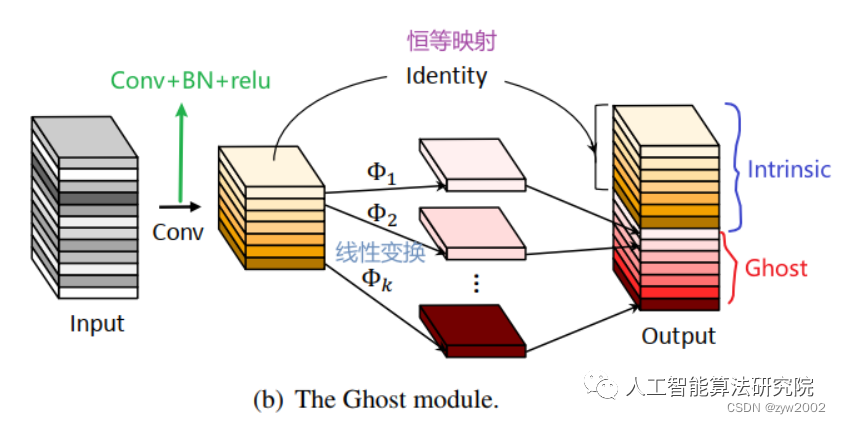
Ghost Module分为两步操作来获得与普通卷积一样数量的特征图:
Step1:少量卷积(比如正常用128个卷积核,这里就用64个,从而减少一半的计算量);
Step2:cheap operations,用图中的Φ表示,Φ是诸如33、55的卷积,并且是逐个特征图的进行卷积(Depth-wise convolutional,深度卷积)。
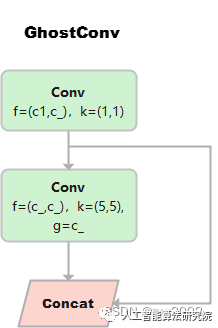
class GhostConv(nn.Module):
# Ghost Convolution https://github.com/huawei-noah/ghostnet
def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
super().__init__()
c_ = c2 // 2 # hidden channels
self.cv1 = Conv(c1, c_, k, s, None, g, act=act)
self.cv2 = Conv(c_, c_, 5, 1, None, c_, act=act) # 分组数=c_=通道数,进行point-wise的深度分离卷积
def forward(self, x):
y = self.cv1(x)
returntorch.cat((y,self.cv2(y)),1)
24
GhostBottleneck
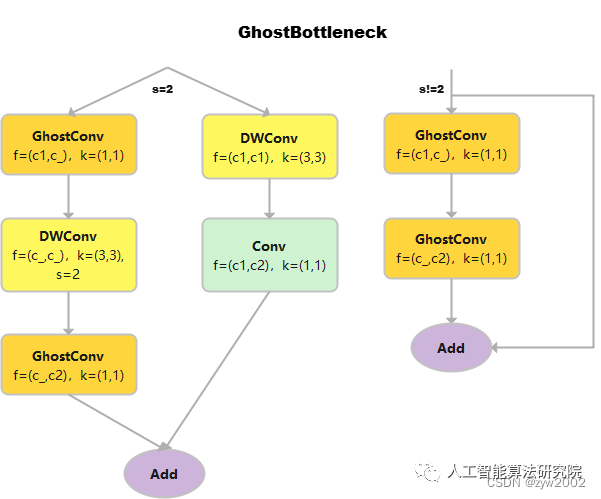
class GhostBottleneck(nn.Module):
# Ghost Bottleneck https://github.com/huawei-noah/ghostnet
def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
super().__init__()
c_ = c2 // 2
self.conv = nn.Sequential(
GhostConv(c1, c_, 1, 1), # 卷积核的大小是1*1,属于point-wise的深度可分离卷积
DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # 输入通道数和输出通道数相等,属于depth-wise的深度可分离卷积
GhostConv(c_, c2, 1, 1, act=False)) #point-wise的深度可分离卷积,且不采用偏置项。
self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False), Conv(c1, c2, 1, 1,
act=False)) if s == 2 else nn.Identity()
def forward(self, x):
returnself.conv(x)+self.shortcut(x)
25
C3Ghost
C3Ghost继承自C3, Bottleneck更换为GhostBottleneck
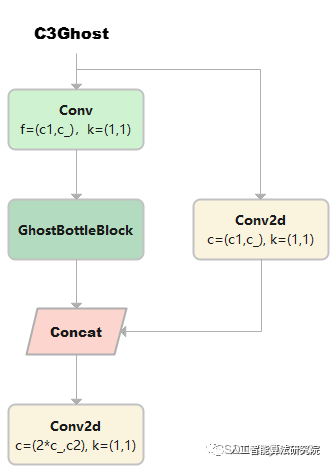
class C3Ghost(C3):
# C3 module with GhostBottleneck()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m=nn.Sequential(*(GhostBottleneck(c_,c_)for_inrange(n)))
26
Concat
当dimension=1时,将多张相同尺寸的图像在通道维度维度上进行拼接。
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
returntorch.cat(x,self.d)
8.Yolov8实操
Section Name
01
下载工程并安装ultralytics
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
pipinstall-e.
02
数据集准备
数据集制作参考:YOLO格式数据集制作
# 训练/验证/测试 数据
train: /data/zyw/project/dataset/finalTrafficLightDataset/train/images
val: /data/zyw/project/dataset/finalTrafficLightDataset/val/images
test: /data/zyw/project/dataset/finalTrafficLightDataset/WPIDataset/images
# 类别个数
nc: 12
# 类别名称
names:["greenCircle","yellowCircle","redCircle","greenLeft","yellowLeft","redLeft","greenRight","yellowRight","redRight","greenForward","yellowForward","redForward"]
03
模型的训练/验证/预测/验证
01
使用CLI
如果你想对模型进行训练、验证或运行推断,并且不需要对代码进行任何修改,那么使用YOLO命令行接口是最简单的入门方法。
YOLO命令行界面(command line interface, CLI) 方便在各种任务和版本上训练、验证或推断模型。CLI不需要定制或代码,可以使用yolo命令从终端运行所有任务。
(1)语法
yolo task=detect mode=train model=yolov8n.yaml args...
classify predict yolov8n-cls.yaml args...
segment val yolov8n-seg.yaml args...
=onnxargs...
(2)训练示例
yolotask=detectmode=trainmodel=yolov8n.ptdata=coco128.yamldevice=0
(3)多GPU训练示例
yolotask=detectmode=trainmodel=yolov8n.ptdata=coco128.yamldevice='0,1,2,3'
(4)重写默认的配置参数
# 语法
yolo task= ... mode= ... arg=val
# 例子:进行10个epoch的检测训练,learning_rate为0.01
=detectmode=trainepochs=10lr0=0.01
(5)重写默认配置文件
# 可以在当前工作目录下创建一个默认配置文件的副本
yolo task=init
# 然后可以使用cfg=name.yaml命令来传递新的配置文件
=default.yaml
02
使用python
允许用户在Python项目中轻松使用YOLOv8。它提供了加载和运行模型以及处理模型输出的函数。该界面设计易于使用,以便用户可以在他们的项目中快速实现目标检测。
(1)训练
方式1:从预训练模型开始训练
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # pass any model type
model.train(epochs=5)
方式2:从头开始训练
from ultralytics import YOLO
model = YOLO("yolov8n.yaml")
model.train(data="coco128.yaml",epochs=5)
(2)验证
训练后验证:
from ultralytics import YOLO
model = YOLO("yolov8n.yaml")
model.train(data="coco128.yaml", epochs=5)
model.val()#It'llautomaticallyevaluatethedatayoutrained.
单独验证:
from ultralytics import YOLO
model = YOLO("model.pt")
# 如果不设置数据的话,就使用model.pt中的data yaml文件
model.val()
# 或者直接设置需要验证的数据。
model.val(data="coco128.yaml")
(3)预测
从源文件预测:
from ultralytics import YOLO
model = YOLO("model.pt")
model.predict(source="0") # accepts all formats - img/folder/vid.*(mp4/format). 0 for webcam
model.predict(source="folder",show=True)#Displaypreds.Acceptsallyolopredictarguments
返回结果:
from ultralytics import YOLO
model = YOLO("model.pt")
outputs = model.predict(source="0", return_outputs=True) # treat predict as a Python generator
for output in outputs:
# each output here is a dict.
# for detection
print(output["det"]) # np.ndarray, (N, 6), xyxy, score, cls
# for segmentation
print(output["det"]) # np.ndarray, (N, 6), xyxy, score, cls
print(output["segment"]) # List[np.ndarray] * N, bounding coordinates of masks
# for classify
print(output["prob"])#np.ndarray,(num_class,),clsprob
04
数据扩充
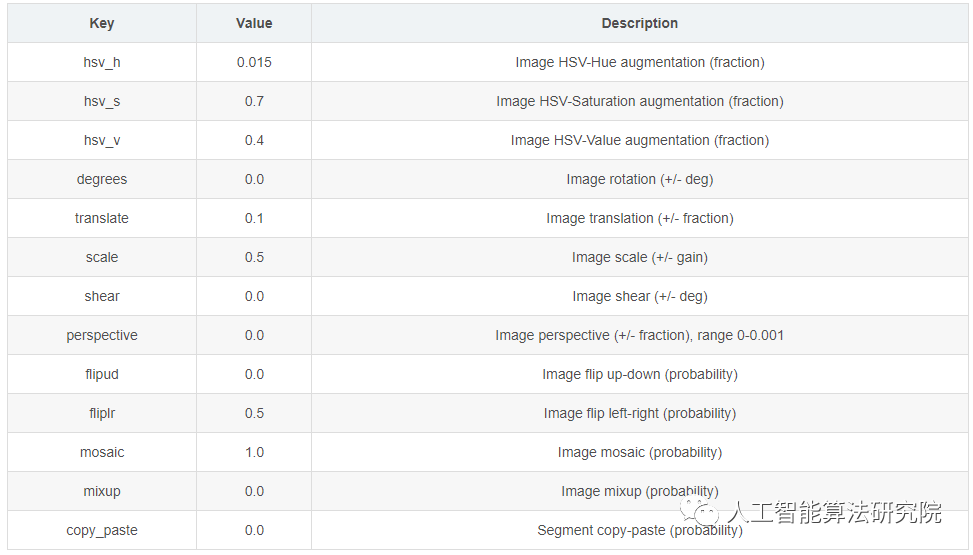
YOLO模型的增强设置是指应用于训练数据的各种变换和修改,以增加数据集的多样性和大小。这些设置会影响模型的性能、速度和精度。一些常见的YOLO增强设置包括应用的转换类型和强度(例如随机翻转、旋转、裁剪、颜色变化),应用每个转换的概率,以及是否存在其他功能,如掩码或每个框多个标签。其他可能影响数据扩充过程的因素包括原始数据集的大小和组成,以及模型正在用于的特定任务。重要的是要仔细调整和实验这些设置,以确保增强后的数据集具有足够的多样性和代表性,以训练高性能的模型。
05
日志、检查点、绘图与文件管理
在训练YOLO模型时,日志记录、检查点、绘图和文件管理是重要的考虑因素。
日志记录:在训练期间记录各种指标和统计数据通常有助于跟踪模型的进展和诊断任何可能出现的问题。这可以通过使用日志库(如TensorBoard)或将日志消息写入文件来实现。
检查点:在训练期间,定期保存模型的检查点是一个很好的做法。如果训练过程被中断,或者你想尝试不同的训练配置,这允许你从之前的点恢复训练。绘图:可视化模型的性能和训练过程,有助于理解模型的行为方式和识别潜在问题。这可以使用matplotlib等绘图库完成,也可以使用TensorBoard等日志库来绘图。
文件管理:管理训练过程中生成的各种文件,例如模型检查点、日志文件和绘图,可能具有挑战性。有一个清晰和有组织的文件结构是很重要的,以便跟踪这些文件,并使其易于根据需要访问和分析它们。
有效的日志记录、检查点、绘图和文件管理可以帮助您跟踪模型的进度,并使其更容易调试和优化训练过程。

-
模型
+关注
关注
1文章
3229浏览量
48813 -
代码
+关注
关注
30文章
4780浏览量
68539 -
网络结构
+关注
关注
0文章
48浏览量
11077
原文标题:【光电智造】一文彻底搞懂YOLOv8(网络结构+代码+实操)
文章出处:【微信号:今日光电,微信公众号:今日光电】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
TensorRT 8.6 C++开发环境配置与YOLOv8实例分割推理演示
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型

YOLOv8版本升级支持小目标检测与高分辨率图像输入
AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型

一文彻底搞懂YOLOv8【网络结构+代码+实操】
教你如何用两行代码搞定YOLOv8各种模型推理

目标检测算法再升级!YOLOv8保姆级教程一键体验
解锁YOLOv8修改+注意力模块训练与部署流程
如何修改YOLOv8的源码
YOLOv8实现任意目录下命令行训练
基于YOLOv8的自定义医学图像分割

基于OpenCV DNN实现YOLOv8的模型部署与推理演示





 工商网监
工商网监
评论