 DPU特征结构系列(一)DPU是以数据为中心IO密集的专用处理器
DPU特征结构系列(一)DPU是以数据为中心IO密集的专用处理器

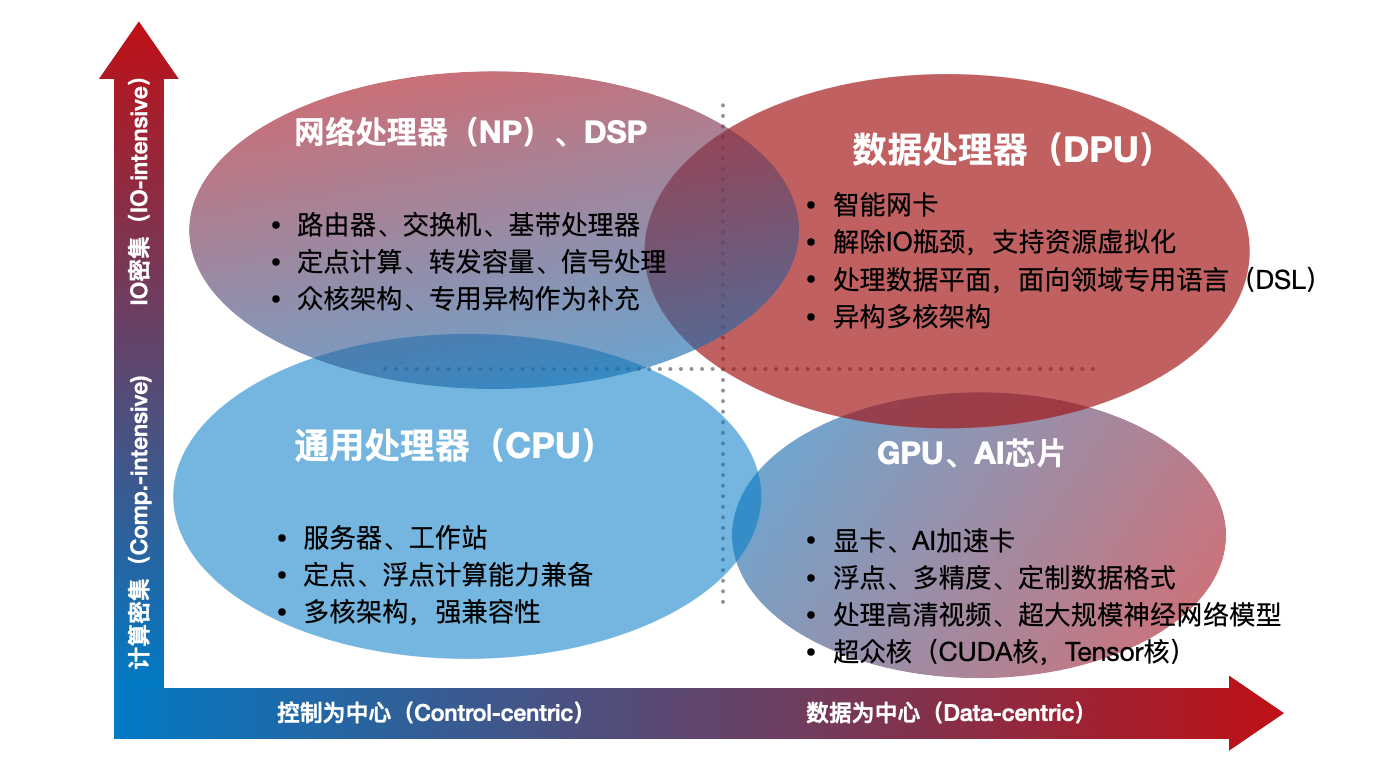
从应用特征来看,可以把应用分为“IO密集型”和“计算密集型”两类,如下图所示。IO密集型应用,通常体现为较高的输入和输出带宽,数据直接来自于IO,数据通常具备流式特征,数据局部性不显著,如果处理性能与带宽匹配,片上缓存的作用就可以弱化。例如处理路由转发、数据加密、压缩等。计算密集型应用,体现为较高的计算密度,通常浮点性能突出,数据来自主存,数据局部性显著,复用性高,主存的大小对于问题求解的性能有直接影响。例如求解线性代数方程组,大规模神经网络训练、推理等。
图不同类型的处理器的特征结构
一个处理器芯片是“IO密集”还是“计算密集”只部分决定了芯片的结构特征,并不能完全定义芯片的主体架构。无论是IO密集,还是计算密集,即可以以通用CPU为核心构造主体计算架构,也可以以专用加速器为核心构造主体计算架构。前者可称之为以控制为中心(control-centric)的模式,后者称之为以数据为中心(data-centric)的模式。控制为中心的核心是实现“通用”,数据为中心的核心是通过定制化实现“高性能”。以应用特征和架构特征这两个维度粗略划分处理器芯片类型分布,如图2-1所示。
通用CPU是偏向于控制为中心结构,理论上看就是要“图灵完备”,要支持完备的指令集,通过编程指令序列来定义计算任务,通过执行指令序列来完成计算任务,因此具备极其灵活的编程支持,可以任意定义计算的逻辑实现“通用”——这也是CPU最大的优势。同时,为了提高编程的开发效率,降低编译器复杂度,缓存管理和细粒度并行度的开发通常都是由硬件来完成。类似的,还有大量的用于各种嵌入式、移动设备的微控制器MCU,并不强调高带宽,也是以控制为中心的结构。NP,DSP也是便向于基于通用处理器来做专用化扩展,但是非常注重高通量的性能属性。例如,NP要支持数Tbps的转发带宽,所以大体可以视为控制为中心、但是IO密集的处理器类型。
GPU是以数据为中心的结构,形式上更倾向于专用加速器。GPU的结构称之为数据并行(data-parallel)结构,优化指令并行度并不是提升性能的重点,通过大规模同构核进行细粒度并行来消化大的数据带宽才是重点。例如,最新的NVIDIA TITAN RTX GPU有4608个CUDA核、576个Tensor核,而且单片GPU通常配置数十GB的超大显存。同时缓存管理多采用软件显示管理,降低硬件复杂度。这类超众核结构是以数据为中心、执行计算密集型任务的代表性架构。
DPU也偏向于数据为中心的结构,形式上集成了更多类别的专用加速器,牺牲一定的指令灵活性以获得更极致的性能。但是与GPU不同,DPU要应对更多的网络IO,既包括外部以太网,也包括内部虚拟IO,所以DPU所面临的数据并行更多可能是数据包并行,而不是图像中的像素、像块级并行。而且DPU也会配置少数通用核(如ARM,MIPS)来处理一定的控制面的任务,运行轻量级操作系统来管理DPU上的众多的异构核资源,所以体现了一定“通用”性,但性能优势主要不源于这些通用核,而是大量专用计算核。早期的一些网络处理器采用过类似Tile64的通用众核结构,以增加核的数量来应对多路处理的数据,实现并发处理,但单路延迟性能通常都比较差。因此,DPU更偏向于以数据为中心,执行IO密集任务。
DPU是软件定义的技术路线下的重要产物。在软件定义网络中,将数据面与控制面分离是最核心的思想。DPU被定义为强化了数据面性能的专用处理器,配合控制面的CPU,可以实现性能与通用性的更佳的平衡。
来源:专用数据处理器(DPU)技术白皮书,中国科学院计算技术研究所,鄢贵海等
-
DPU
+关注
关注
0文章
419浏览量
27173
发布评论请先 登录
隼瞻科技完成近亿元天使+轮融资,加速领域专用处理器敏捷设计的落地应用
BK7259 具备边缘AI能力的高级音视频Wi-Fi +蓝牙SOC芯片/规格书/原理图
深入剖析STA2065:高性能信息娱乐应用处理器
STA2064:高度集成的信息娱乐应用处理器
恩智浦全新i.MX 93W应用处理器重磅发布
支持蓝牙Piconet和Scatternet组网协议的高性能32位蓝牙音频应用处理器-BP1048B2



探索NXP i.MX 93应用处理器家族:高效边缘计算的理想之选
探索i.MX 91应用处理器家族:为边缘应用带来新可能
NVIDIA推出全新BlueField-4 DPU
恩智浦推出i.MX 952人工智能应用处理器
RISC-V DPU,重塑数据中心算力格局?
第三届NVIDIA DPU黑客松开启报名
中科驭数携DPU全栈产品亮相福州数博会,赋能智算时代算力基建




评论