 为什么传统CNN在纹理分类数据集上的效果不好?
为什么传统CNN在纹理分类数据集上的效果不好?
作者:Trapti Kalra
来源:AI公园,编译:ronghuaiyang
导读
本文分析了常见的纹理数据集以及传统CNN在纹理数据集分类上效果不佳的原因。
在机器视觉任务中,将纹理分析与深度学习结合使用,对于获得更好的结果起到了重要作用。在前一篇文章中,我们已经讨论了什么是纹理的基础知识,不同类型的纹理,以及纹理分析在解决真正的计算机视觉任务中的适用性。我们还解释了一些最常用和值得注意的提取纹理的技术,此外,我们还演示了如何将这些纹理提取技术与深度学习结合起来。
深度学习由多种结构组成,可用于图像分类任务。基于深度学习的模型经常用于图像分类任务,并在许多不同的用例中产生了出色的结果,展示了它们的有效性。几年前,迁移学习的概念出现了,它建议使用使用大数据集训练的模型作为特定用例的骨干,其中,预训练的骨干模型只是通过使用特定案例的数据集来微调权重以解决特定任务。经过图像分类训练的预训练模型也可用于纹理分类任务。为了检验现有传统的基于cnn的纹理分类模型的效率,我们使用一些公共的基于纹理的数据集对其进行性能基准测试。我们观察到,传统的CNN结构(如图5所示)很难产生较好的结果,并不是很有效地应用于纹理分类任务。
纹理分类以及常用的纹理数据集
纹理分析和分类是地形识别、自动医疗诊断、显微图像分析、自动驾驶汽车和爆炸危险检测等领域的关键任务。在执行基于分类的任务时,纹理是一个非常重要的属性。作为人类,我们可以直观地看到、理解和区分纹理,但对于基于人工智能的机器来说,情况并非如此。如果一个人工智能模型能够识别纹理,那么它在分类任务中的应用将会是一个额外的优势。根据物体的视觉效果来理解和分类物体可以使人工智能模型更加高效和可靠。
因此,我们为纹理分类任务构建了模型,并在基于纹理的基准数据集(如DTD、FMD、和KTH)上测试模型的有效性。基于这些数据集上任何模型的准确性,我们可以理解并在一定程度上预测它在其他类似数据集上的性能。下面我们将提供关于上述数据集的详细信息。
- DTD:它是一个基于纹理的图像数据集,由5640张图像组成,根据受人类感知启发的47个类别进行组织。每个类别有120张图片。

图1,DTD中每个类别的图
KTH:KTH通常被称为KTH- tips(在不同的照明、姿势和比例下的纹理)图像数据库被创建来在两个方向上扩展CUReT数据库,通过提供在尺度以及姿态和照明上的变化,并通过在不同的设置中对其材料的子集进行成像得到其他样本。有11类的总样本量是3195。
 图2,KTH-TIPS数据集中11个类别,每个类比4张图
图2,KTH-TIPS数据集中11个类别,每个类比4张图
FMD:建立这个数据库的特定目的是捕捉一系列常见材料(如玻璃、塑料等)在现实世界中的外观。这个数据库中的每一张图片(总共有10个类别,每个类别有100张图片)都是手动从Flickr.com(在创作共用许可下)中选择的,以确保各种照明条件、组合、颜色、纹理和材料子类型。

图3,FMD数据集中每个类比的几张图
传统CNN图像分类
就现有的传统CNN而言,这些大多属于预训练模型本身或使用这些预训练层/权值的模型。在我们的博客中,我们将首先简要概述什么是预训练模型,以及如何将其应用于图像分类任务。
现有的几种CNN模型都是由不同的研究人员针对图像分类的任务提出的,这些模型也可以作为许多其他图像分类相关任务的预训练模型。在图5中,我们可以看到如何将预训练的层合并到传统的基于CNN的架构中。
在纹理分类任务的情况下,这些预先训练的模型也可以通过迁移它们的知识,并将它们用于基于纹理的数据集。由于这些模型是为特定数据集上的图像分类任务而建立的,而我们在一些不同的数据集上使用它们进行纹理分类,我们称它们为预训练模型。进一步介绍了图像分类预训练模型的一些关键思想:
什么是预训练模型?
为了简单地定义一个预先训练的模型,我们可以将其称为由其他人训练的神经网络模型,并为特定的用例提供给其他开发人员使用。
流行的预训练模型通常是通过使用一个庞大的数据集来解决一个复杂的任务。然后,这些模型被贡献为开放源码,因此其他开发人员可以进一步构建或在他们的工作中使用这些模型。通常情况下,使用预先训练的模型来解决类似的问题是一个好主意,而预先训练的模型是为这些问题开发的。在图4中,一个模型为一个源任务训练,这个源模型已经训练(预训练模型)的权值被用于目标任务。对新开发的模型进行了一些修改,将预先训练的模型的权值进行转移,以获得更好和更精确的预测结果。
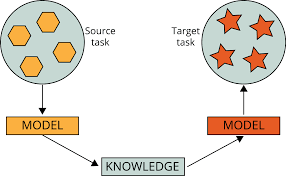
图4,使用预训练模型的方法
使用预训练的模型作为计算机视觉和自然语言处理的各种问题的起点是非常常见的。从零开始构建一个神经网络需要巨大的计算能力、时间和熟练的劳动力。
在这个文章中,我们将着重于应用预训练模型(训练用于图像分类任务)来解决纹理分类任务。
常用的预训练模型
下面是对预训练模型的概述,这些模型经常用于许多图像分类相关的任务。
VGG-16: 2015年发布的最受欢迎的预训练图像分类模型之一。VGG-16是一个深度为16层可调的神经网络,它在ImageNet数据库中的100万张图像上训练。它能够对1000个物体进行分类。
Inception v3:一个由谷歌在同一个ImageNet数据库上开发的预训练模型。它也被称为GoogLeNet。Inception v3是一个深度为50层的神经网络。在2014年的ImageNet竞赛中,InceptionV3获得了第一,而VGG-16获得了亚军。它只有700万个参数,这比以前的模型要小得多,除此之外,它的错误率很低,这是该模型的一个主要成就。
ResNet50:原始模型称为残差网或ResNet,它是微软在2015年开发的。ResNet50是一个深度为50层的神经网络。ResNet50还训练了来自ImageNet数据库的100万张图像。与VGG16相比,ResNet复杂度更低,结果优于VGG16。ResNet50旨在解决梯度消失的问题。
EfficientNet:它是谷歌于2019年训练并向公众发布的最先进的卷积神经网络。在EfficientNet中,作者使用了一种新的缩放方法,称为复合缩放,我们在同一时间缩放固定数量的维度,并且我们均匀地缩放。通过这样做,我们可以获得更好的性能,缩放系数可以由用户自己决定。EfficientNet有8种实现(从B0到B7)。
为我们的用例利用和调整预训练模型的方法
由于我们所处理的数据与预训练模型所训练的数据不同,因此需要根据我们的数据更新模型的权重,以了解特定领域的信息。因此,我们需要对数据的模型进行微调。
下面我们将讨论一些在特定用例中使用预先训练过的模型的机制。
特征提取- 使用预训练模型作为特征提取机制。我们可以移除输出层(即给出了1000个类中每个类的概率),然后使用整个网络作为新数据集的固定特征提取器。
训练一些层,同时冻结其他层- 预训练的模型可以用来部分训练我们的模型,其中我们保持初始层的权重冻结,并重新训练更高层的权重。根据一些实验,我们可以看到有多少层需要冻结,有多少层需要训练。
使用预训练模型的体系结构- 我们可以从模型的体系结构中获得帮助,并使用它随机初始化模型的权重。然后我们可以根据我们的数据集和任务训练模型,这样我们就有了一个很好的架构,可以为我们的任务带来很好的结果。
在处理任何类型的图像分类问题时,微调和使用预先训练的模型是一个聪明的解决方案。此外,这些传统的/预先训练的CNN模型也产生了良好的结果,然而,这些架构在对基于纹理的数据集进行分类时表现不佳。
为什么传统的CNN架构在基于纹理的数据集的分类任务中表现不佳?
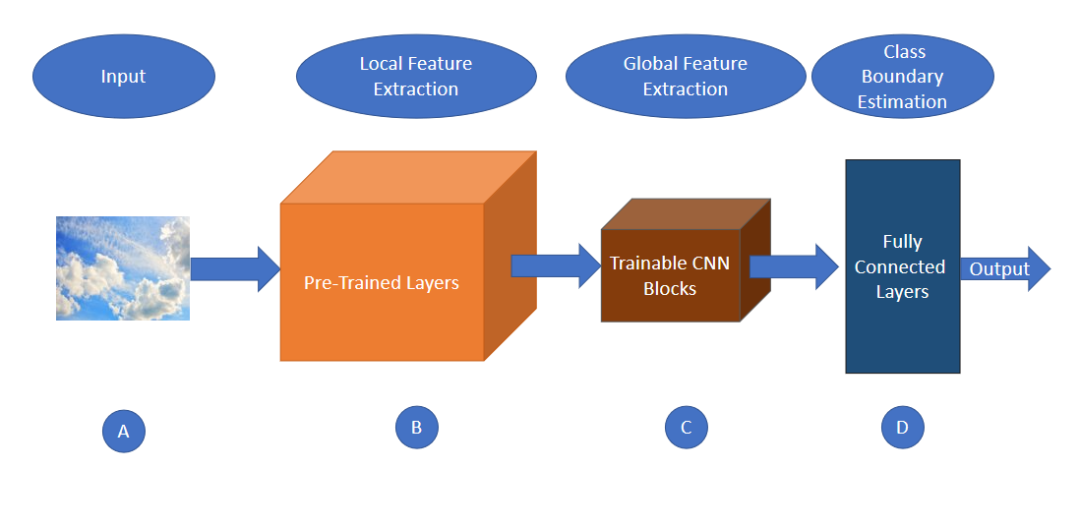
图5,传统CNN结构的4个主要部分传统的CNN架构通常包括预训练层,在此基础上添加一些CNN层的可训练块,然后将其输出传递到全连接层进行类预测。由图5可以看出,传统的CNN架构主要有四个主要组件,用A、B、C、和D四个块来描述。第一个分量是输入层(描述为块A),第二个是预先训练的层/权值(描述为块B),第三个分量是可训练的CNN块(描述为块C),它的输出传递给第四个分量(描述为块D)的全连接层。传递给全连接层的输入通常包括全局特征而不是局部特征。这种通用架构适用于大多数需要图像全局特征来对图像进行分类的任务。然而,这些类型的架构很无法很准确的预测类别,在这些类中,全局特征和局部特征都参与了类的预测。
CNN模型的复杂性随着网络深度的增加而增加,最后一层通常倾向于捕捉图像的复杂特征。从卷积层捕获的特征被发送到全连接层,以获取图像中物体的形状信息并预测其类别。这些关于整体形状和高度复杂特征的信息不适合用于纹理分析,因为纹理是基于复杂度较低的重复局部位置模式,这需要丰富的基于局部的特征提取。
为了利用为图像分类而开发的基于CNN的模型进行纹理分类,利用网络的CNN层输出中提取的特征进行域转移。在使用预先训练的CNN进行基于纹理的分类时,我们面临三个主要缺点,如下所示。
众所周知,任何图像的纹理都是通过其局部结构和局部像素分布来定义的。要分析任何图像的纹理特征,必须研究其基于局部的特征,并将其传递给全连接层。但是传统的CNN不能将基于局部的特征传递给全连接层,因为传统CNN架构的最后一个CNN层是利用复杂的特征来捕捉物体的整体形状,并提取全局特征(如图5所示),而不是捕捉局部特征的模式。这就是传统CNN架构在基于纹理的数据集上表现不佳的原因。
预训练的CNN的更深层可能是非常具体的领域,可能不是很有用的纹理分类
一个固定大小的输入需要发送到CNN,以便它与全连接层兼容。这通常是一项昂贵的任务
全连接的层发布卷积层捕捉图像的空间布局,这对于表示物体的形状很有用,但对于表示纹理却不太有用
在已有的CNNs中加入纹理提取特征技术,可以提高纹理分类任务的结果。表1比较了传统的CNN方法vs方法使用Resnet-50骨干以及一些特征提取技术。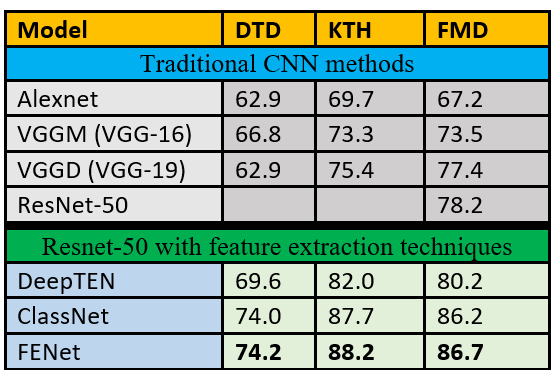 表1,传统CNN模型和使用特征提取技术的Resnet-50在基准数据集上的结果比较将纹理特征提取策略与深度学习相结合的模型往往比传统的深度学习方法产生更好的结果。这是因为传统的CNN模型捕捉了通常对目标检测有用的复杂特征,而纹理是使用局部重复的模式/特征识别的。可以使用自定义的深度卷积网络来改进CNN,在卷积层之后,随着CNN引入各种纹理提取技术。将纹理提取层和预训练层结合在一起的自定义深度卷积网络不如单独使用预训练模型或统计地使用纹理特征提取器灵活。我们将在后面的文章中讨论纹理特征提取和预训练模型。
表1,传统CNN模型和使用特征提取技术的Resnet-50在基准数据集上的结果比较将纹理特征提取策略与深度学习相结合的模型往往比传统的深度学习方法产生更好的结果。这是因为传统的CNN模型捕捉了通常对目标检测有用的复杂特征,而纹理是使用局部重复的模式/特征识别的。可以使用自定义的深度卷积网络来改进CNN,在卷积层之后,随着CNN引入各种纹理提取技术。将纹理提取层和预训练层结合在一起的自定义深度卷积网络不如单独使用预训练模型或统计地使用纹理特征提取器灵活。我们将在后面的文章中讨论纹理特征提取和预训练模型。
原文:https://medium.com/@trapti.kalra_ibm/why-traditional-cnns-may-fail-for-texture-based-classification-3b49d6b94b6f
-
cnn
+关注
关注
3文章
352浏览量
22214
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论