 UWA平台支持PowerVR芯片,新增四大GPU模块分析
UWA平台支持PowerVR芯片,新增四大GPU模块分析
日前,游戏和VR应用性能优化平台 UWA 宣布新的 GPU Counter 功能更新:增加了对 PowerVR 品牌 GPU 芯片的支持。针对 PowerVR GPUCounter,UWA提供了 GPU 负载、GPU 着色、GPU 带宽、GPU 图元 4 个模块的分析。最新的 UWA SDK 2.4.4 已发布,下载最新版 SDK,并使用搭载 PowerVR GPU IP 芯片的设备进行测试,即可在GOT Online Overview的GPU模块下查看到对应的数据,掌握GPU压力和性能消耗情况。
以下针对PowerVR GPU Counter,围绕UWA所提供的GPU 负载、GPU着色、GPU带宽、GPU图元4个模块的分析进行详细说明。
1、GPU负载
GPU Counter下的GPU负载包含Non Fragment Utilization和Fragment Utilization两个性能指标,分别代表非片段处理占整体GPU处理耗时百分比和片段处理开销占整体GPU处理开销百分比。
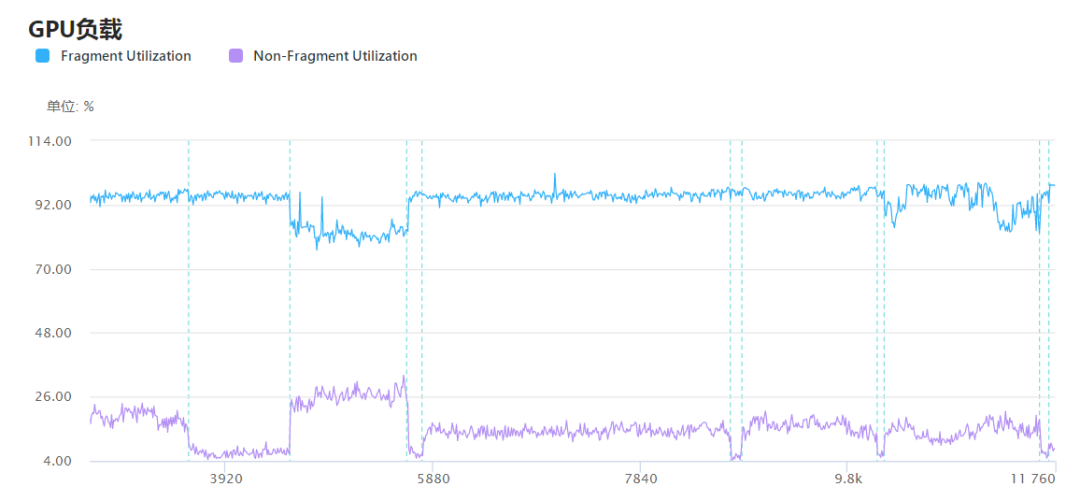
在GPU上运行的工作负载由作业管理器统一协调,该任务管理器负责将工作负载调度到GPU内部的各个处理单元上,它将两个FIFO工作队列,称为作业插槽。其中,一个插槽用于非片段工作负载,另一个插槽则用于片段着色工作负载。当出现GPU瓶颈时,正常情况下Non Fragment Utilization和Fragment Utilization至少有一个是接近100%,如果两者都低于100%,则有可能是Non Fragment和Fragment之间存在数据依赖关系。
当Non Fragment Utilization过高时,开发者可以从顶点数、复杂的Compute Shader的使用情况以及Geometry Shader、Tessellation Shader等角度着手进行优化。当Fragment Utilization过高时,则可以考虑项目中是否存在是否存在片段数目过多、片段Shader过于复杂。
2、GPU着色
包含Overdraw和Cycles/Pixel两个指标。
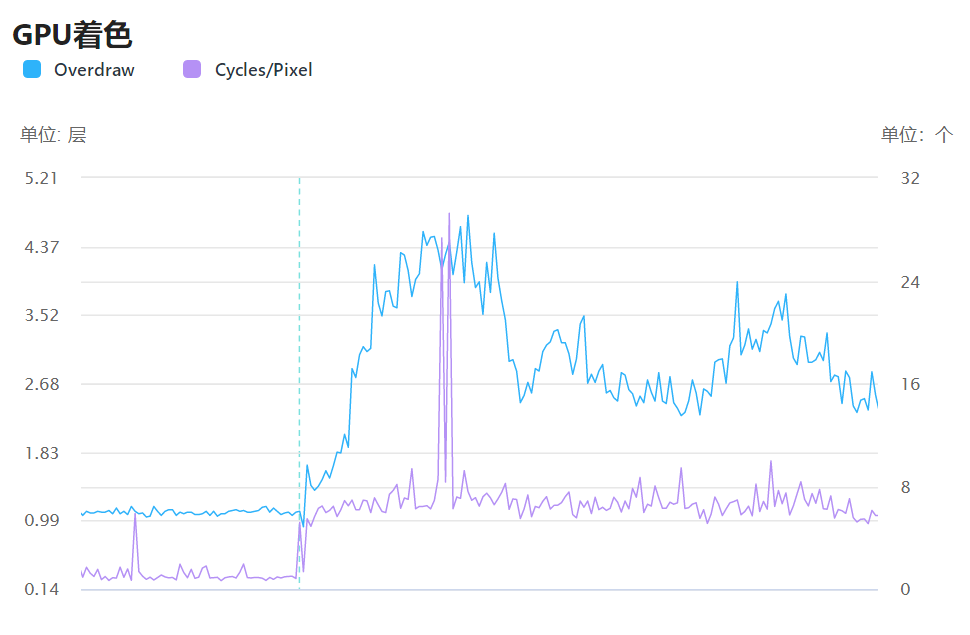
Overdraw(过度绘制)
该项表示项目运行过程中,单帧中整个屏幕被填充的倍数。倍数越高,则GPU的压力越大。在游戏运行过程中,场景中半透明物体的重合会使得同一个像素点在一帧中会被绘制多次,造成Overdraw过高的情况。如下图所示,UI和粒子特效层叠导致容易出现Overdraw。
Cycles/Pixel
表示平均每个像素耗费的GPU时钟周期。一般来说,Shader复杂度会极大地影响GPUCycles占用的情况。当画面的Shader复杂度过高时,GPU需要消耗大量的时钟周期对Shader进行运算,容易造成GPU耗时变高,造成卡顿。
因此,通过查看GPU着色模块,就可以快速定位高Overdraw和高Cycles的场景,判断这个场景的GPU压力较高是Overdraw还是Shader复杂度过高造成的,进行有针对性的优化。
3、GPU带宽
和CPU一样,GPU带宽也是芯片耗电的重要指标。当GPU持续进行高负载外部读写时,掉电就会过快。
UWA的GPU带宽模块统计了测试过程中单帧的读写带宽总量,通过查看GPU带宽模块,可以快速定位测试过程中带宽较高的场景和原因,并进行进一步测试优化。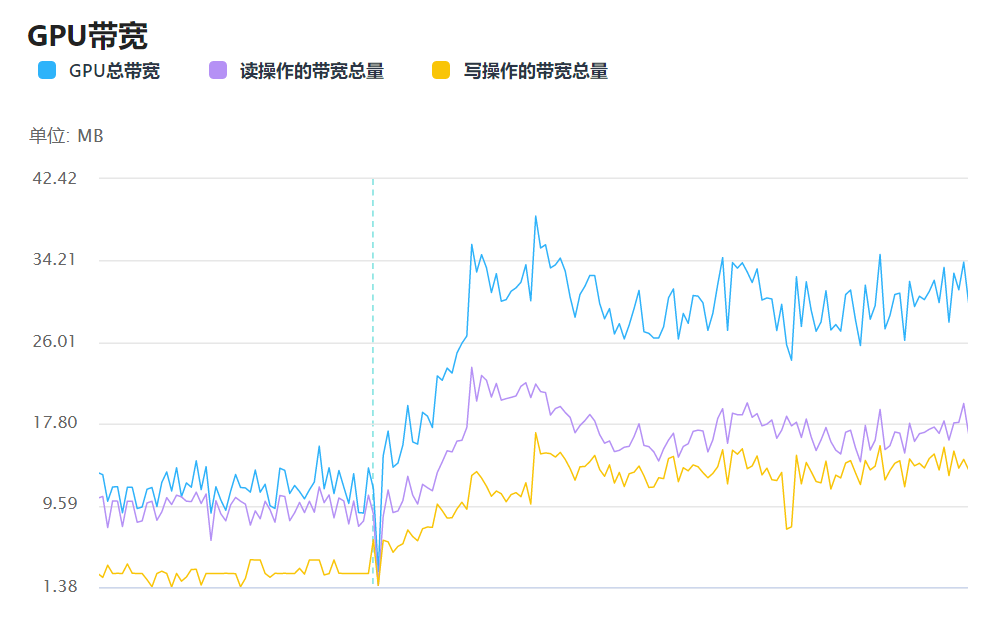
4、GPU图元处理渲染面是产生GPU压力的重要因素之一,我们可以通过 Overview 模式里的 Triangle 指标来查看和分析哪些画面的渲染面较多。
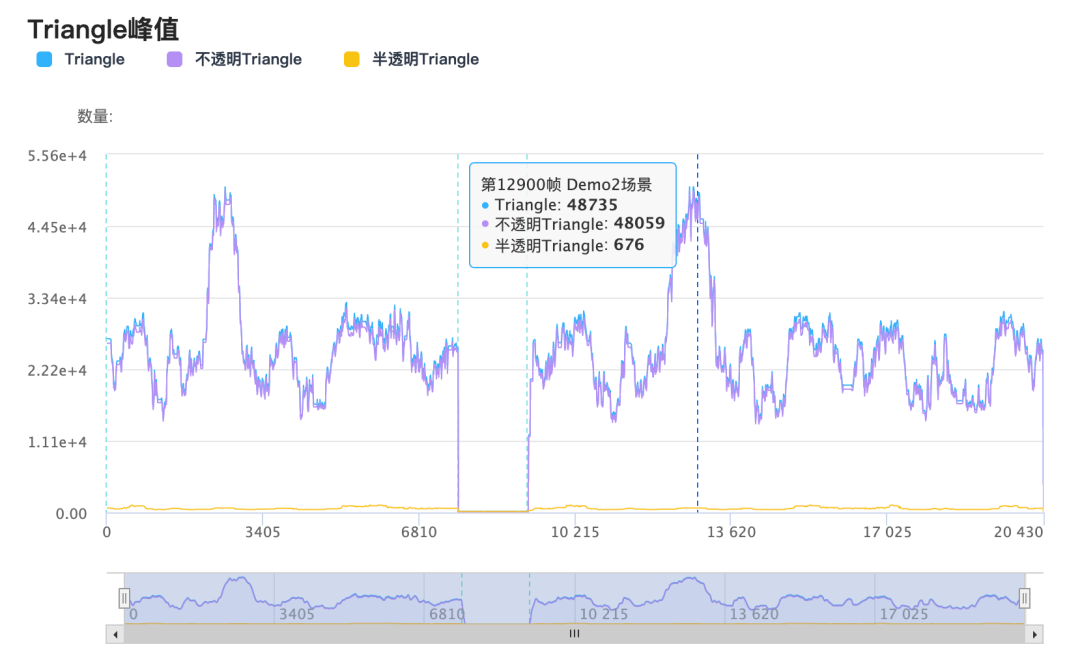
渲染面过多,一方面可能是模型过于复杂,一般可以通过 LOD、HLOD 等常用技术来简化远距离的模型,在不影响画质的情况下显著降低渲染面;另一方面,可能是地形、大建筑物等大面积模型没有进行适当的拆分,导致进入视域体的面片可能不多,但提交GPU的渲染面依然很多。对于第二种情况,我们可以通过新功能“GPU图元”来进行初步的判断。
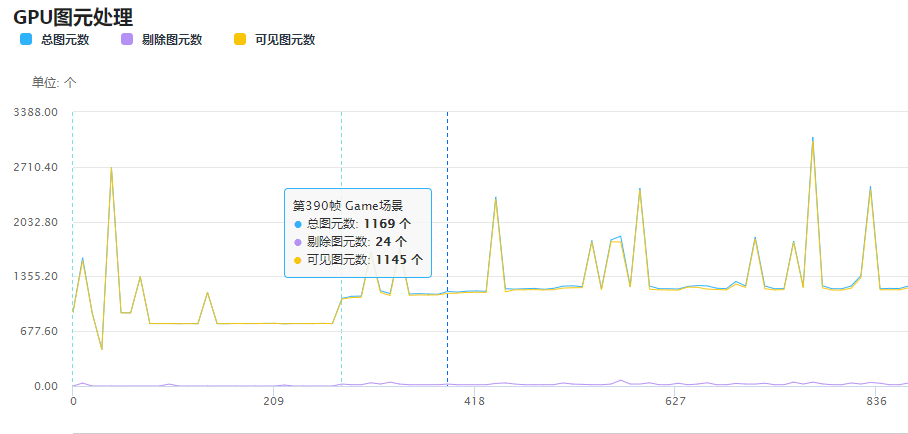
总图元数:提交到GPU端的图元总数,该数值基本等同于引擎端统计的渲染面片总数。可见图元数:在GPU端通过各种裁剪之后,留下的参与渲染的三角面。可见图元不包括:因为在视域体外而被裁剪的三角面,因为朝向而被裁剪的三角面。因此,在3D场景中,比较理想的情况下,可见图元的数量应该接近或高于 50%(对于大部分模型,有一半三角面会因为朝向被裁剪)。如果某些角度下,可见图元的比例非常低,则很可能存在上文提到的第二种情况,从而可以针对性地检查和优化场景中,这个角度下,被提交到GPU的大面积模型。
GPU图元处理数量过多会对设备的带宽和能耗造成较大的影响,应尽量在程序端完成剔除,并减小送往GPU的图元数。
需要注意的是,基于架构不同,同一参数在不同品牌芯片上的推荐值也会存在差异,不同设备间横向对比的意义不大,更推荐大家在相同的设备上进行纵向对比。同时,由于同品牌芯片的架构之间也会存在差异,UWA目前仅支持部分芯片的GPU Counter数据采集,具体支持设备列表可通过下图或登录UWA官网对“Mali/Power VR/Adreno GPUCounter支持设备”列表进行查询:
https://www.uwa4d.com/main/supported.html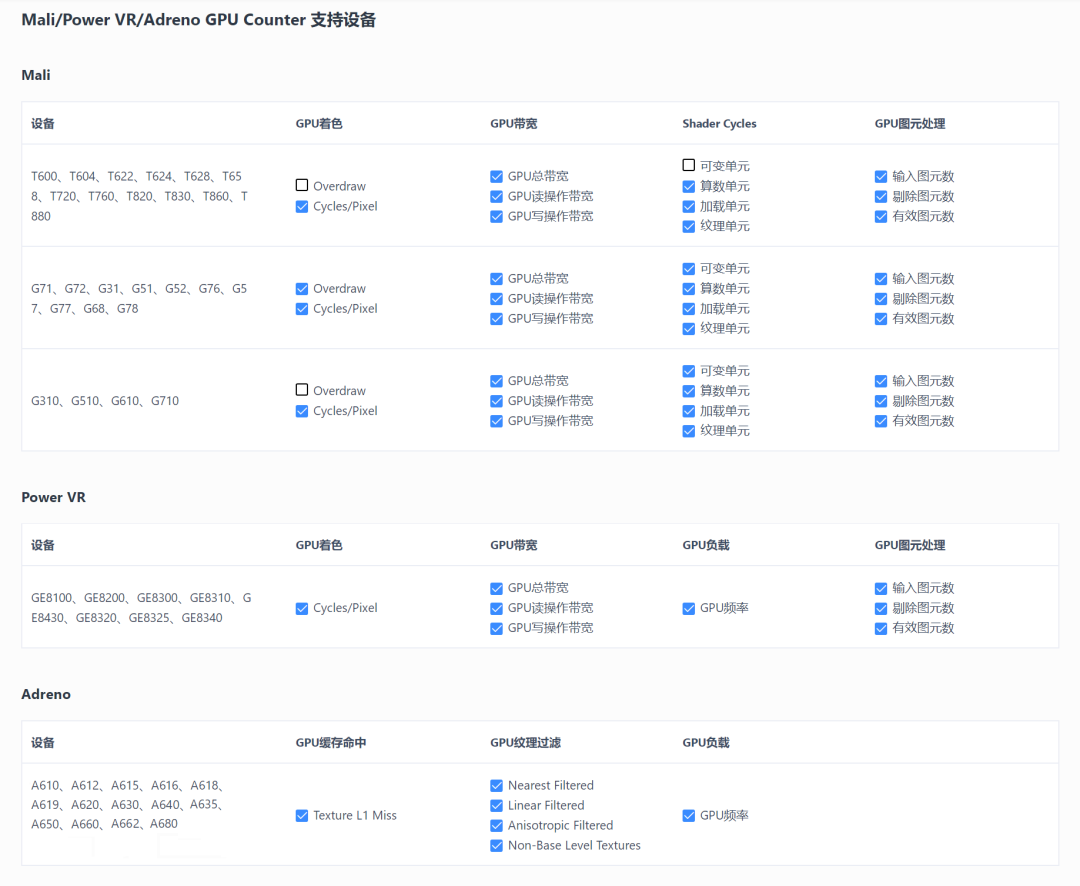 以上就是这次关于搭载 PowerVR GPU IP 芯片的新功能介绍了,希望会对开发者们在 GPU 优化上和项目的整体性能监控上有所帮助。
以上就是这次关于搭载 PowerVR GPU IP 芯片的新功能介绍了,希望会对开发者们在 GPU 优化上和项目的整体性能监控上有所帮助。
-
芯片
+关注
关注
454文章
50689浏览量
423022 -
vr
+关注
关注
34文章
9638浏览量
150191
发布评论请先 登录
相关推荐
赛逸展2025响应四大行业协会倡议,审慎采购美国芯片!
国科微亮相2024 UWA联盟会员大会
UVLED固化机结构的四大模块

《算力芯片 高性能 CPUGPUNPU 微架构分析》第3篇阅读心得:GPU革命:从图形引擎到AI加速器的蜕变
软银升级人工智能计算平台,安装4000颗英伟达Hopper GPU
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--了解算力芯片GPU
Orin芯片的编程语言支持
GPU加速计算平台是什么
GPU算力租用平台是什么
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
探秘四大主流芯片架构:谁将主宰未来科技?

凌科推出M24型连接器卡扣模块升级新品

8芯M16接口四大优点






 工商网监
工商网监
评论