 ChatGPT热潮席卷全球ChatGPT将带动哪些芯片的需求?ChatGPT带来的启示
ChatGPT热潮席卷全球ChatGPT将带动哪些芯片的需求?ChatGPT带来的启示
最近,ChatGPT热潮席卷全球。
ChatGPT(Chat Generative Pre-trained Transformer)是由OpenAI于2022年12月推出的对话AI模型,仅发布2个月便实现月活突破1亿,成为历史上用户增长最快的消费级应用之一。
ChatGPT火出圈背后是“人类反馈强化模型”的应用。在问答模式的基础上,ChatGPT可以进行推理、编写代码、文本创作等等,这样的特殊优势和用户体验使得应用场景流量大幅增加。
随着ChatGPT用户数快速增长,需求量火爆引发宕机。在庞大用户群涌入的情况下,ChatGPT服务器2天宕机5次,火爆程度引人注目的同时也催生了对算力基础设施建设更高的要求,特别是底层芯片。那么,ChatGPT将带动哪些芯片的需求?
AI服务器需求激增
当前,ChatGPT在问答模式的基础上进行推理、编写代码、文本创作等,用户人数及使用次数均提升,同时在一些新应用场景也产生了较大的流量,比如智能音箱、内容生产、游戏NPC、陪伴机器人等。随着终端用户使用频率提高,数据流量暴涨,对服务器的数据处理能力、可靠性及安全性等要求相应提升。
从技术原理来看,ChatGPT基于Transformer技术,随着模型不断迭代,层数也越来越多,对算力的需求也就越来越大。从运行条件来看,ChatGPT完美运行的三个条件:训练数据+模型算法+算力,需要在基础模型上进行大规模预训练,存储知识的能力来源于1750亿参数,需要大量算力。
资料显示,ChatGPT是基于GPT-3.5优化的一个模型,GPT-3.5是GPT-3.0的微调版本。OpenAI的GPT-3.0模型存储知识的能力来源于1750亿参数,单次训练费用约460万美元,GPT-3.5在微软AzureAI超算基础设施上进行训练,总算力消耗约3640PF-days(即假如每秒计算一千万亿次,需要计算3640天)。
可以说,ChatGPT拉动了芯片产业量价齐升,即不仅对人工智能底层芯片数量产生了更大的需求,而且对底层芯片算力也提出了更高的要求,即拉动了高端芯片的需求。据悉,采购一片英伟达顶级GPU成本为8万元,GPU服务器成本通常超过40万元。支撑ChatGPT的算力基础设施至少需要上万颗英伟达GPU A100,高端芯片需求的快速增加会进一步拉高芯片均价。
随着ChatGPT流量激增,作为算力载体的AI服务器将迎来重要发展机遇。预计,全球AI服务器市场将从2020年的122亿美元成长到2025年288亿美元,年复合增长率达到18.8%。
这些芯片将受益
从芯片构成来看,AI服务器主要是CPU+加速芯片,通常搭载GPU、FPGA、ASIC等加速芯片,利用CPU与加速芯片的组合可以满足高吞吐量互联的需求。
1.CPU
作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。其优势在于有大量的缓存和复杂的逻辑控制单元,擅长逻辑控制、串行的运算;劣势在于计算量较小,且不擅长复杂算法运算和处理并行重复的操作。因此,CPU在深度学习中可用于推理/预测。
目前,服务器CPU向多核心发展,满足处理能力和速度提升需要,比如AMD EPYC 9004核心数量最多可达96个。不过,系统性能优劣不能只考虑CPU核心数量,还要考虑操作系统、调度算法、应用和驱动程序等。
2.GPU
GPU高度适配AI模型构建,由于具备并行计算能力,可兼容训练和推理,目前GPU被广泛应用于加速芯片。以英伟达A100为例,在训练过程中,GPU帮助高速解决问题:2048个A100 GPU可在一分钟内成规模地处理 BERT之类的训练工作负载。在推理过程中,多实例GPU (MIG)技术允许多个网络同时基于单个A100运行,从而优化计算资源的利用率。在A100其他推理性能增益的基础之上,仅结构稀疏支持一项就能带来高达两倍的性能提升。在BERT等先进的对话式AI模型上,A100可将推理吞吐量提升到高达CPU的249倍。
目前,ChatGPT引发了GPU应用热潮。其中,百度即将推出文心一言(ERNIE Bot)。苹果则引入AI加速器设计的M2系列芯片(M2 pro和M2 max)将被搭载于新款电脑。随着ChatGPT的使用量激增,OpenAI需要更强的计算能力来响应百万级别的用户需求,因此增加了对英伟达GPU的需求。
AMD计划推出与苹果M2系列芯片竞争的台积电4nm工艺“Phoenix”系列芯片,以及使用Chiplet工艺设计的“Alveo V70”AI芯片。这两款芯片均计划在今年推向市场,分别面向消费电子市场以及AI推理领域。
3.FPGA
FPGA具有可编程灵活性高、开发周期短、现场可重编功能、低延时、方便并行计算等特点,可通过深度学习+分布集群数据传输赋能大模型。
4.ASIC
ASIC在批量生产时与通用集成电路相比具有体积更小、功耗更低、可靠性提高、性能提高、保密性增强、成本降低等优点,可进一步优化性能与功耗。随着机器学习、边缘计算、自动驾驶的发展,大量数据处理任务的产生,对于芯片计算效率、计算能力和计能耗比的要求也越来越高,ASIC通过与CPU结合的方式被广泛关注,国内外龙头厂商纷纷布局迎战AI时代的到来。
其中,谷歌最新的TPU v4集群被称为Pod,包含4096个v4芯片,可提供超过1 exaflops的浮点性能。英伟达GPU+CUDA主要面向大型数据密集型HPC和AI应用;基于Grace的系统与NVIDIAGPU紧密结合,性能比NVIDIADGX系统高出10倍。百度昆仑2代AI芯片采用全球领先的7nm 制程,搭载自研的第二代 XPU 架构,相比一代性能提升2-3倍;昆仑芯3代将于2024年初量产。
5.光模块
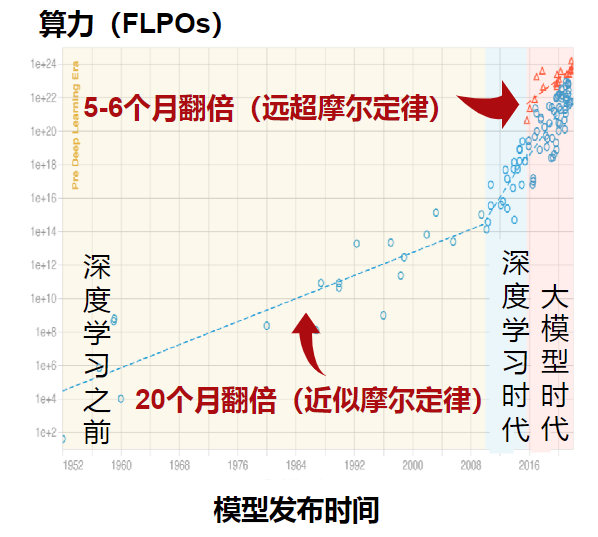
当前,AI时代模型算力需求已经远超摩尔定律的速度增长,特别是在深度学习、大模型时代之后,预计5-6个月翻倍。然而,数据传输速率成为容易被忽略的算力瓶颈。伴随数据传输量的增长,光模块作为数据中心内设备互联的载体,需求量随之增长。
来源:Google Scholar
未来算力升级路径
最近,ChatGPT的兴起推动着人工智能在应用端的蓬勃发展,这也对计算设备的运算能力提出了前所未有的需求。虽然AI芯片、GPU、CPU+FPGA等芯片已经对现有模型构成底层算力支撑,但面对未来潜在的算力指数增长,短期使用Chiplet异构技术加速各类应用算法落地,长期来看打造存算一体芯片(减少芯片内外的数据搬运),或将成为未来算力升级的潜在方式。
1. Chiplet
Chiplet是布局先进制程、加速算力升级的关键技术。Chiplet异构技术不仅可以突破先进制程的封锁,并且可以大幅提升大型芯片的良率、降低设计的复杂程度和设计成本、降低芯片制造成本。不过,虽然Chiplet技术加速了算力升级,但需要牺牲一定的体积和功耗,因此将率先在基站、服务器、智能电车等领域广泛使用。
目前,Chiplet已广泛应用于服务器芯片。AMD是Chiplet服务器芯片的引领者,其基于Chiplet的第一代AMDEPYC处理器中,装载8个“Zen”CPU核,2个DDR4内存通道和32个PCIe通道。2022年AMD正式发布第四代EPYC处理器,拥有高达96颗5nm的Zen4核心,并使用新一代的Chiplet工艺,结合5nm和6nm工艺来降低成本。
英特尔第14代酷睿Meteor Lake首次采用intel 4工艺,首次引入Chiplet小芯片设计,预计将于2023年下半年推出,至少性能功耗比的目标要达到13代 Raptor Lake的1.5倍水平。
2.存算一体
正如上文提到的,AI时代模型算力需求远超摩尔定律的速度增长,单纯靠缩微化制程已经无法满足需求而且成本急速攀升。实际上,从现有芯片架构来看,超过60%时间是花在数据搬运上,超过90%的功耗也损失在数据搬运上,能效非常低。因此,存储墙”成为了数据计算应用的一大障碍。而存算一体是算力需求上升的主要解决技术路线之一。
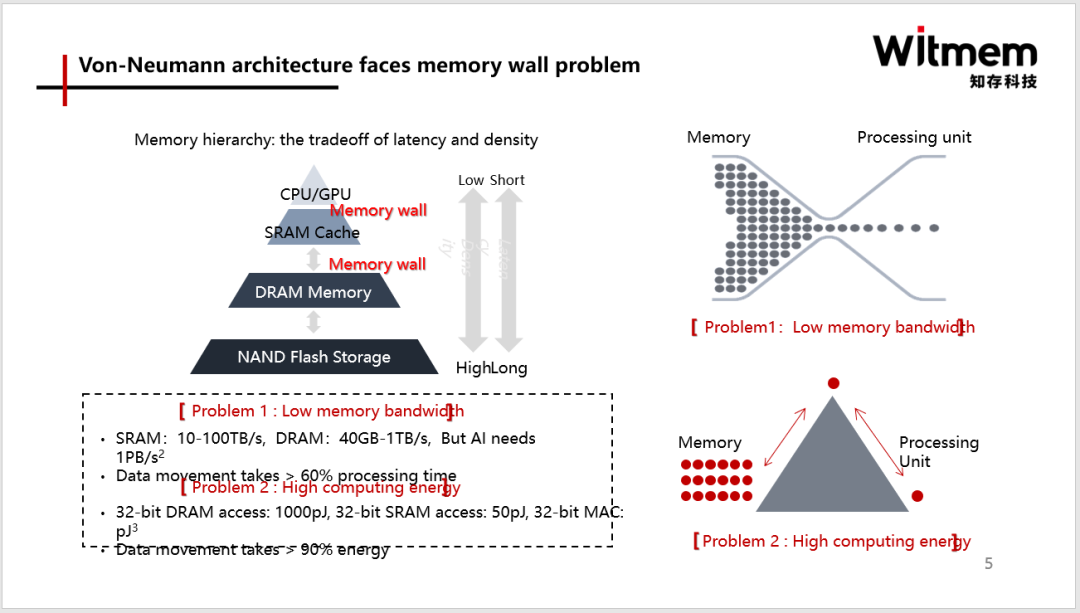
存内计算的计算原理可以理解成是用存储器做计算,其计算单元不再是逻辑器件、CPU、GPU或者NPU,与这些架构是完全不一样的。存内计算直接运算单元是存储单元本身。存算一体技术通过在存储器中叠加计算能力,以新的高效运算架构进行二维和三维矩阵运算。
以上信息由英利检测(Teslab)原创发布,欢迎一起讨论,我们一直在关注这方面的发展,如有引用也请注明出处。
国家高新技术企业;唯一覆盖中国和欧美运营商认证服务机构;业内最为优秀第三方认证服务商之一;专业的人做专业的事;
入库:┆移动┆联通┆电信┆中国广电┆
欧美:┆GCF┆PTCRB┆VzW┆ATT┆TMO┆FCC┆
中国:┆CCC┆SRRC┆CTA┆
号码:┆IMEI┆MAC┆MEID┆EAN┆
-
芯片
+关注
关注
456文章
51157浏览量
426750 -
AI
+关注
关注
87文章
31493浏览量
270129 -
ChatGPT
+关注
关注
29文章
1566浏览量
8007
发布评论请先 登录
相关推荐
ChatGPT新增实时搜索与高级语音功能
苹果iOS 18.2公测版发布,Siri与ChatGPT深度融合
OpenAI推出ChatGPT搜索功能
ChatGPT:怎样打造智能客服体验的重要工具?





 工商网监
工商网监
评论