 可视化CNN和特征图
可视化CNN和特征图

作者:Ahzam Ejaz来源:DeepHub IMBA
卷积神经网络(cnn)是一种神经网络,通常用于图像分类、目标检测和其他计算机视觉任务。CNN的关键组件之一是特征图,它是通过对图像应用卷积滤波器生成的输入图像的表示。

理解卷积层
1、卷积操作
卷积的概念是CNN操作的核心。卷积是一种数学运算,它把两个函数结合起来产生第三个函数。在cnn的上下文中,这两个函数是输入图像和滤波器,而得到的结果就是特征图。
2、卷积的层
卷积层包括在输入图像上滑动滤波器,并计算滤波器与输入图像的相应补丁之间的点积。然后将结果输出值存储在特征映射中的相应位置。通过应用多个过滤器,每个过滤器检测一个不同的特征,我们可以生成多个特征映射。
3、重要参数
Stride:Stride 是指卷积滤波器在卷积运算过程中在输入数据上移动的步长。
Padding:Padding是指在应用卷积操作之前在输入图像或特征映射的边界周围添加额外像素。Padding的目的是控制输出特征图的大小,保证滤波窗口能够覆盖输入图像或特征图的边缘。如果没有填充,过滤器窗口将无法覆盖输入数据的边缘,导致输出特征映射的大小减小和信息丢失。有两种类型的填充“valid”和“same”。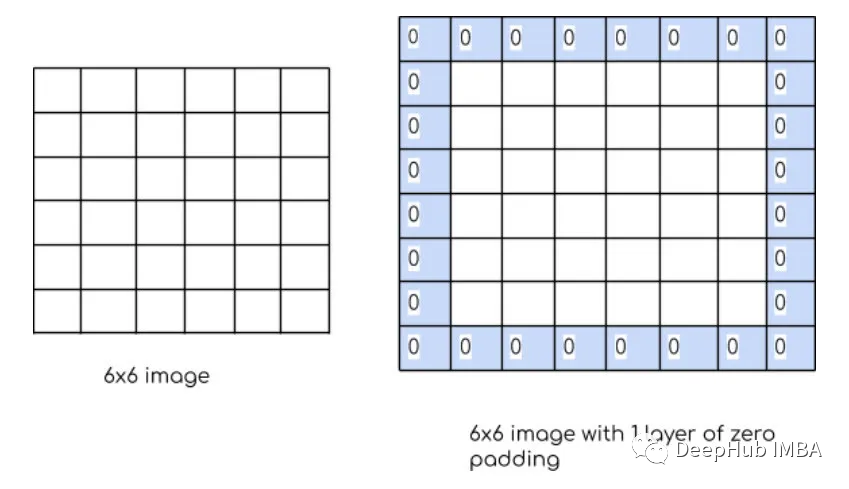 kernel/filter:kernel(也称为filter 或 weight )是一个可学习参数的小矩阵,用于从输入数据中提取特征。在下图中,输入图像的大小为(5,5),过滤器filter 的大小为(3,3),绿色为输入图像,黄色区域为该图像的过滤器。在输入图像上滑动滤波器,计算滤波器与输入图像的相应像素之间的点积。Padding是valid (也就是没有填充)。stride值为1。
kernel/filter:kernel(也称为filter 或 weight )是一个可学习参数的小矩阵,用于从输入数据中提取特征。在下图中,输入图像的大小为(5,5),过滤器filter 的大小为(3,3),绿色为输入图像,黄色区域为该图像的过滤器。在输入图像上滑动滤波器,计算滤波器与输入图像的相应像素之间的点积。Padding是valid (也就是没有填充)。stride值为1。
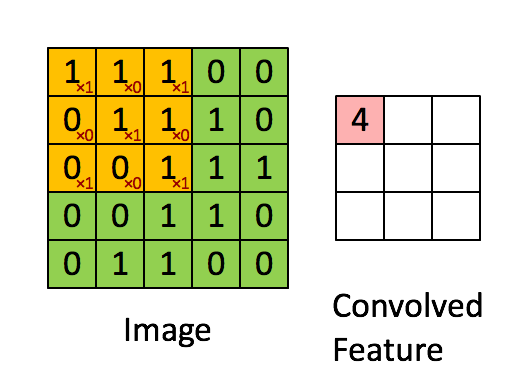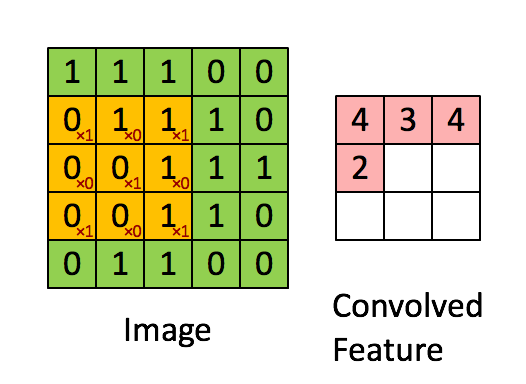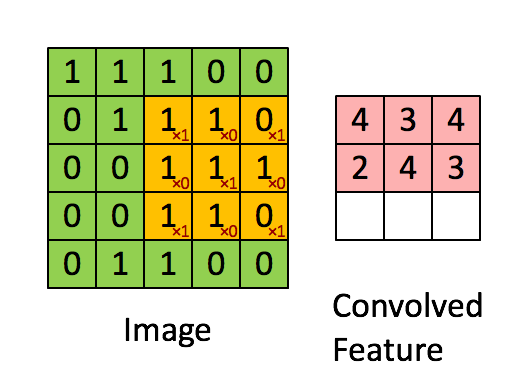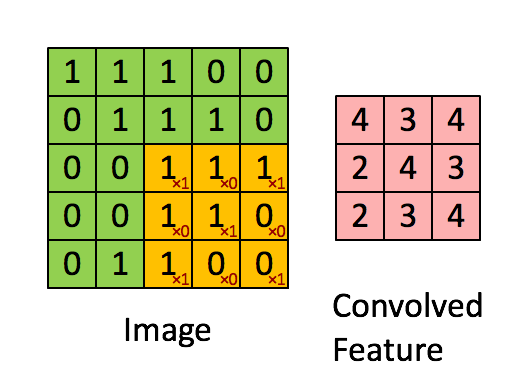
4、特征图特征图是卷积神经网络(CNN)中卷积层的输出。它们是二维数组,包含卷积滤波器从输入图像或信号中提取的特征。卷积层中特征图的数量对应于该层中使用的过滤器的数量。每个过滤器通过对输入数据应用卷积操作来生成单个特征映射。特征图的大小取决于输入数据的大小,卷积操作中使用的过滤器、填充和步幅的大小。通常,随着我们深入网络,特征图的大小会减小,而特征图的数量会增加。特征图的大小可以用以下公式计算:
Output_Size = (Input_Size - Filter_Size + 2 * Padding) / Stride + 1
这个公式非常重要,因为在计算输出时肯定会用到,所以一定要记住来自一个卷积层的特征映射作为网络中下一层的输入数据。随着层数的增加,网络能够学习越来越复杂和抽象的特征。通过结合来自多层的特征,网络可以识别输入数据中的复杂模式,并做出准确的预测。
特征图可视化
这里我们使用TF作为框架进行演示
## Importing libraries#Imageprocessinglibraryimportcv2#Kerasfromtensorflowimportkeras#InKeras,thelayersmoduleprovidesasetofpre-builtlayerclassesthatcanbeusedtoconstructneuralnetworks.fromkerasimportlayers#Forplotinggraphsandimagesimportmatplotlib.pyplotaspltimportnumpyasnp
使用OpenCV导入一张图像,并将其大小调整为224 x 224像素。
img_size=(224,224)file_name="./data/archive/flowers/iris/10802001213_7687db7f0c_c.jpg"img=cv2.imread(file_name) #readingtheimageimg=cv2.resize(img,img_size)
我们添加2个卷积层:
model=keras.Sequential()filters=16model.add(layers.Conv2D(input_shape=(224,224,3),filters=filters,kernel_size=3))model.add(layers.Conv2D(filters=filters,kernel_size=3))
从卷积层中获取过滤器。
filters, bias = model.layers[0].get_weights()min_filter = filters.min()max_filter = filters.max()filters = (filters - min_filter) / (max_filter - min_filter)p
可视化
figure=plt.figure(figsize=(10,20))filters_count=filters.shape[-1]channels=filters.shape[0]index=1forchannelinrange(channels):forfilterinrange(filters_count): plt.subplot(filters_count, channels, index) plt.imshow(filters[channel, :, :, filter]) plt.xticks([]) plt.yticks([]) index+=1plt.show()
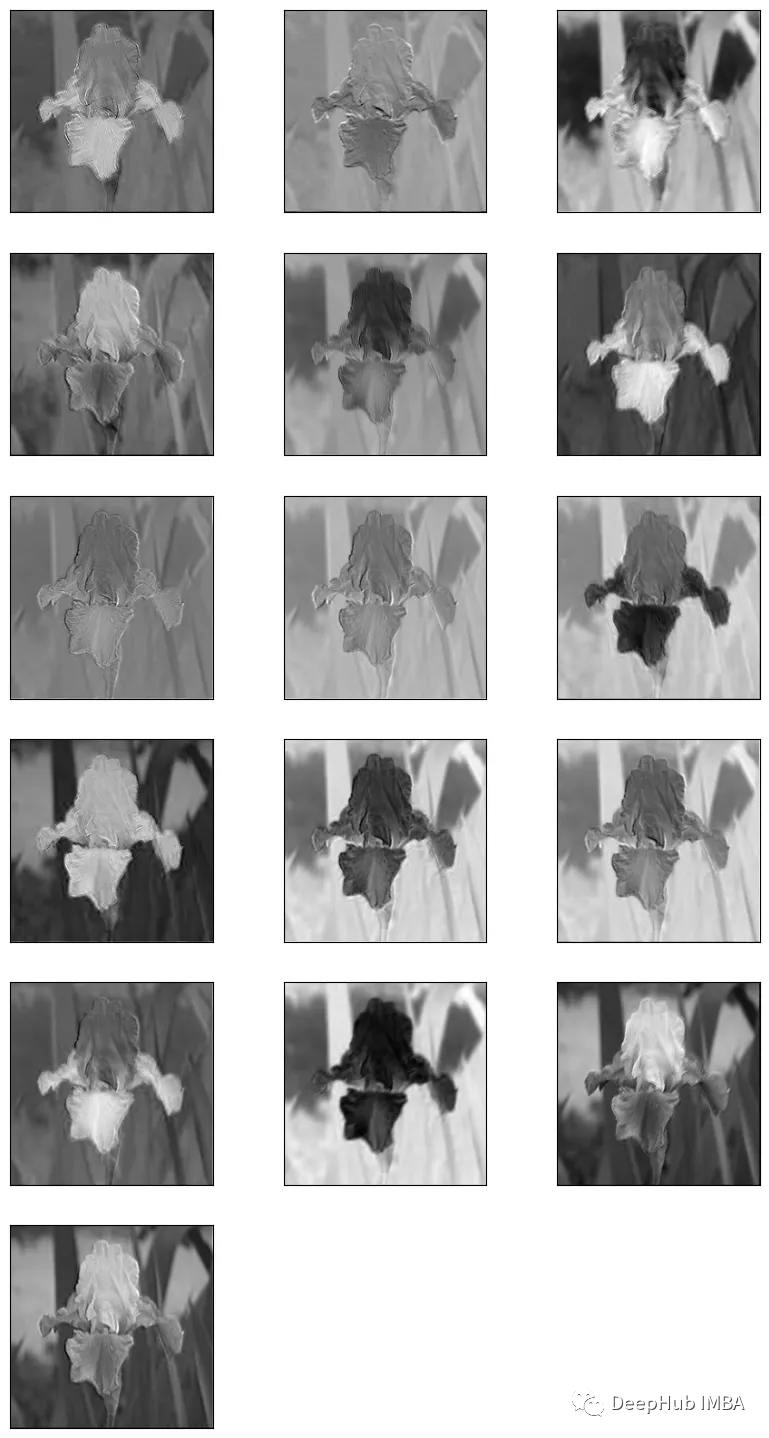
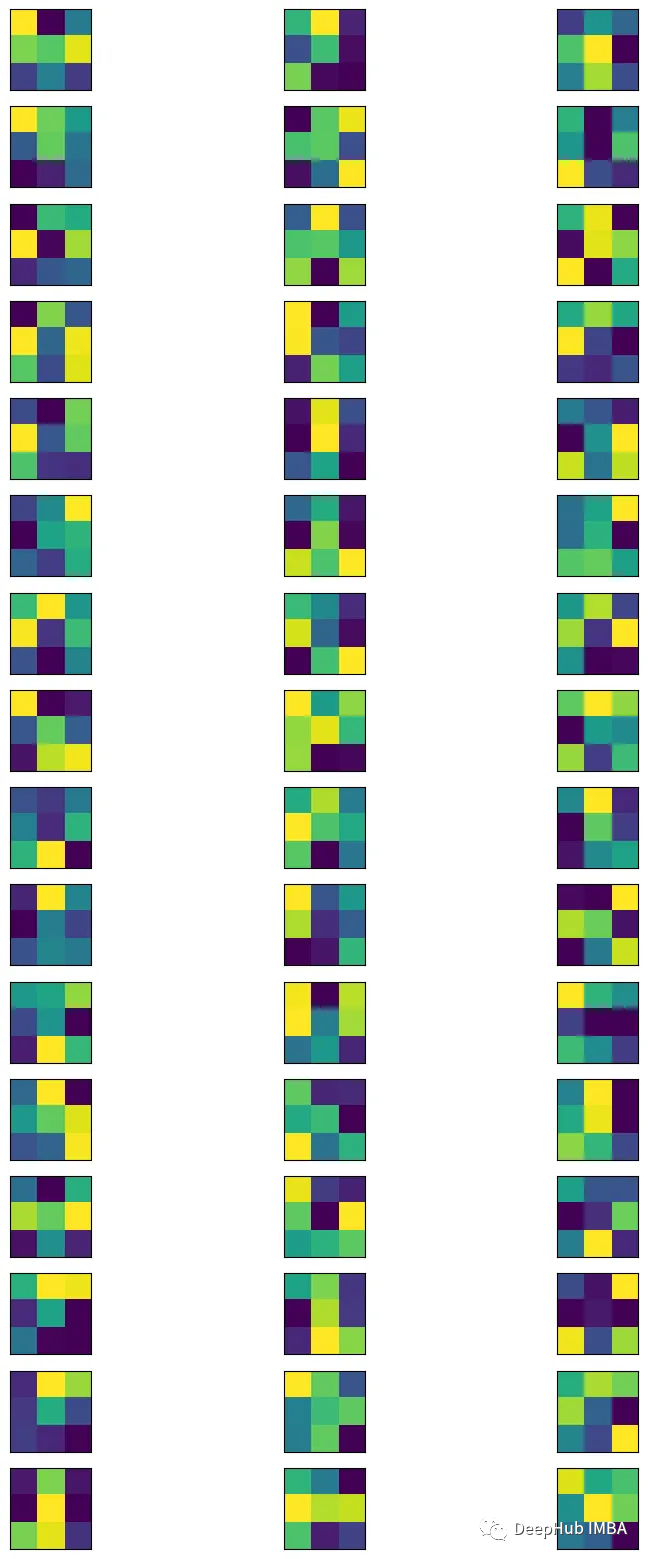 将图像输入到模型中得到特征图
将图像输入到模型中得到特征图
normalized_img=(img-img.min())/(img.max()-img.min())normalized_img=normalized_img.reshape(-1,224,224,3)feature_map=model.predict(normalized_img)
特征图需要进行归一化这样才可以在matplotlib中显示
feature_map = (feature_map - feature_map.min())/ (feature_map.max() - feature_map.min())
提取特征图并显示
total_imgs = feature_map.shape[0]no_features=feature_map.shape[-1]fig=plt.figure(figsize=(10,50))index=1 forimage_noinrange(total_imgs): forfeatureinrange(no_features):#plottingfor16filtersthatproduced16featuremapsplt.subplot(no_features,3,index)plt.imshow(feature_map[image_no,:,:,feature],cmap="gray")plt.xticks([])plt.yticks([])index+=1plt.show()
总结
通过可视化CNN不同层的特征图,可以更好地理解网络在处理图像时“看到”的是什么。例如,第一层可能会学习简单的特征,如边缘和角落,而后面的层可能会学习更抽象的特征,如特定物体的存在。通过查看特征图,我们还可以识别图像中对网络决策过程重要的区域。
-
神经网络
+关注
关注
42文章
4840浏览量
108141 -
cnn
+关注
关注
3文章
356浏览量
23528
发布评论请先 登录
3D系统可视化
森林消防智慧预警技术实现:火灾监测 Web GIS 可视化平台搭建

可视化AR巡检:工业智能化发展的新引擎
基于图扑 HT 数字孪生 3D 风电场可视化系统实现解析

工业数字孪生:图扑可视化技术架构与行业应用解析

图扑 HT 驱动智慧社区数字化转型:多维可视化与系统集成实践

工业可视化平台是什么
光伏电站可视化的实现

数字孪生可视化系统构建行业数字化智能管理生态!

一文读懂 | 晶圆图Wafer Maps:半导体数据可视化的核心工具

如何使用协议分析仪进行数据分析与可视化
工业设备可视化管理系统是什么




评论