 乘法器的Verilog HDL实现方案
乘法器的Verilog HDL实现方案
1. 串行乘法器
两个N位二进制数x、y的乘积用简单的方法计算就是利用移位操作来实现。
module multi_CX(clk, x, y, result);
input clk;
input [7:0] x, y;
output [15:0] result;
reg [15:0] result;
parameter s0 = 0, s1 = 1, s2 = 2;
reg [2:0] count = 0;
reg [1:0] state = 0;
reg [15:0] P, T;
reg [7:0] y_reg;
always @(posedge clk) begin
case (state)
s0: begin
count <= 0;
P <= 0;
y_reg <= y;
T <= {{8{1'b0}}, x};
state <= s1;
end
s1: begin
if(count == 3'b111)
state <= s2;
else begin
if(y_reg[0] == 1'b1)
P <= P + T;
else
P <= P;
y_reg <= y_reg >> 1;
T <= T << 1;
count <= count + 1;
state <= s1;
end
end
s2: begin
result <= P;
state <= s0;
end
default: ;
endcase
end
endmodule
乘法功能是正确的,但计算一次乘法需要8个周期。因此可以看出串行乘法器速度比较慢、时延大,但这种乘法器的优点是所占用的资源是所有类型乘法器中最少的,在低速的信号处理中有着广泛的应用。
2.流水线乘法器
一般的快速乘法器通常采用逐位并行的迭代阵列结构,将每个操作数的N位都并行地提交给乘法器。但是一般对于FPGA来讲,进位的速度快于加法的速度,这种阵列结构并不是最优的。所以可以采用多级流水线的形式,将相邻的两个部分乘积结果再加到最终的输出乘积上,即排成一个二叉树形式的结构,这样对于N位乘法器需要lb(N)级来实现。
module multi_4bits_pipelining(mul_a, mul_b, clk, rst_n, mul_out); input [3:0] mul_a, mul_b; input clk; input rst_n; output [7:0] mul_out; reg [7:0] mul_out; reg [7:0] stored0; reg [7:0] stored1; reg [7:0] stored2; reg [7:0] stored3; reg [7:0] add01; reg [7:0] add23; always @(posedge clk or negedge rst_n) begin if(!rst_n) begin mul_out <= 0; stored0 <= 0; stored1 <= 0; stored2 <= 0; stored3 <= 0; add01 <= 0; add23 <= 0; end else begin stored0 <= mul_b[0]? {4'b0, mul_a} : 8'b0; stored1 <= mul_b[1]? {3'b0, mul_a, 1'b0} : 8'b0; stored2 <= mul_b[2]? {2'b0, mul_a, 2'b0} : 8'b0; stored3 <= mul_b[3]? {1'b0, mul_a, 3'b0} : 8'b0; add01 <= stored1 + stored0; add23 <= stored3 + stored2; mul_out <= add01 + add23; end end endmodule
从图中可以看出,流水线乘法器比串行乘法器的速度快很多很多,在非高速的信号处理中有广泛的应用。至于高速信号的乘法一般需要利用FPGA芯片中内嵌的硬核DSP单元来实现。
审核编辑:刘清
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
FPGA设计
+关注
关注
9文章
428浏览量
26665 -
HDL
+关注
关注
8文章
328浏览量
47495 -
乘法器
+关注
关注
9文章
206浏览量
37233 -
Verilog语言
+关注
关注
0文章
113浏览量
8311
原文标题:乘法器的Verilog HDL实现
文章出处:【微信号:zhuyandz,微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
verilog中乘法器延时问题
刚刚学习verilog,夏宇闻的《verilog数字系统设计教程(第三版)》中,P143中图10.3,乘法器延时为1个与门和8个全加器的延时,为什么是 8 个?我觉得应该是 10 个全加器延时,请求大神帮忙解答一下,谢了。
发表于 10-10 23:04
FPGA乘法器设计
刚接触学习FPGA,懂得verilog HDL的基础语法,有一块带XILINX的ZYNQ xc7z020的开发板,开发软件用的是vivado;现在要设计一个16位的乘法器,功能已经实现
发表于 02-25 16:03
基于Verilog HDL设计实现的乘法器性能研究
本文在设计实现乘法器时,采用了4-2 和5-2 混合压缩器对部分积进行压缩,减少了乘法器的延时和资源占用率;经Xilinx ISE 和Quartus II 两种集成开发环境下的综合仿真测试,与用
发表于 09-17 11:13
•27次下载

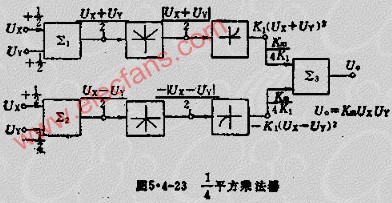
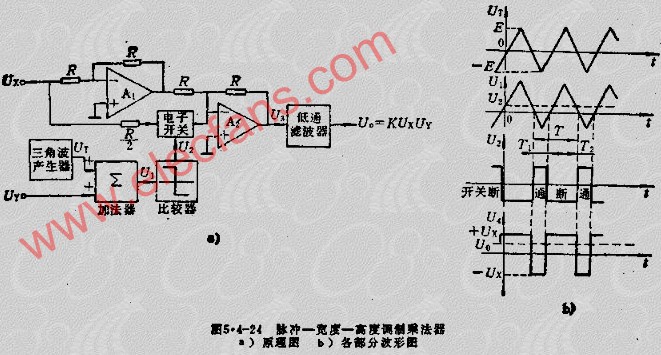
脉冲-宽度-高度调制乘法器
脉冲-宽度-高度调制乘法器
脉冲-宽度-高度调制乘法器双称为时间分割乘法器。这类乘法器电路原理图如图5.4-24A所示。图中,三角波电压UT和模拟输入电压UY
发表于 05-18 14:23
•2086次阅读
基于IP核的乘法器设计
实验目的 1、熟悉Xilinx的ISE 软件的使用和设计流程; 2、掌握Modelsim仿真软件的使用方法; 3、用乘法运算符实现一个16*16 乘法器模块; 4、用IP核实现一个16
发表于 05-20 17:00
•68次下载
使用verilogHDL实现乘法器
本文在设计实现乘法器时,采用了4-2和5-2混合压缩器对部分积进行压缩,减少了乘法器的延时和资源占 用率;经XilinxISE和QuartusII两种集成开发环境下的综合仿真测试,与用
发表于 12-19 13:30
•1.1w次阅读
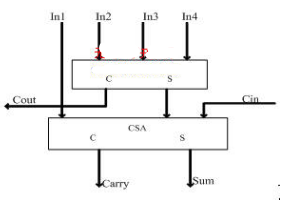
乘法器原理_乘法器的作用
乘法器(multiplier)是一种完成两个互不相关的模拟信号相乘作用的电子器件。它可以将两个二进制数相乘,它是由更基本的加法器组成的。乘法器可以通过使用一系列计算机算数技术来实现。
发表于 02-18 15:08
•2.7w次阅读

采用Gillbert单元如何实现CMOS模拟乘法器的应用设计
在集成电路系统中,模拟乘法器在信号调制解调、鉴相、频率转换、自动增益控制和功率因数校正控制等许多方面有着非常广泛的应用。实现模拟乘法器的方法有很多,按采用的工艺不同,可以分为三极管乘法器





 工商网监
工商网监
评论