 PCIe例程理解之用户逻辑接收模块仿真分析
PCIe例程理解之用户逻辑接收模块仿真分析
前言
本文从例子程序细节上(语法层面)去理解PCIe对于事物层数据的接收及解析。参考数据手册:PG054;例子程序有Vivado生成;
为什么将这个内容写出来?
通过写博客,可以检验自己理解了这个设计没有,这像是一个提问题并自我解读的过程,如果你提出了问题,但发现自己解决不了,那问题就在这里。
例程是入门某一个IP核的最好途径,它可以作为你进一步设计的基础。你的后续设计都可以基于此。
正文
理解一个新的设计的最好方法是仿真,Aurora如此,PCIe也是如此,自己定制一个PCIe的IP核,之后右击生成相应的例程。
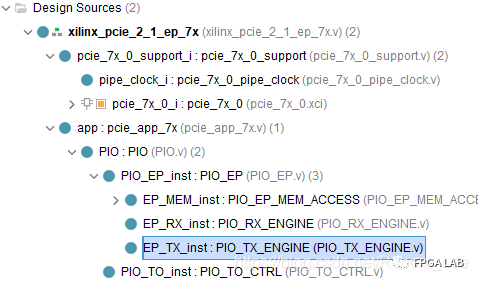
该例程是一个PIO例程,所谓的PIO,其全称为:The Programmed Input/Output (PIO) ,即可编程输入输出。
编程输入/输出(PIO)事务通常由PCI Express系统主机CPU用于访问PCI Express逻辑中的内存映射输入/输出(MMIO)和配置映射输入/输出(CMIO)位置。PCI Express的端点接受内存和I/O写事务,并以带有数据的完成事务来响应内存和I/O读事务。
FPGA端作为Endpoint,PC端作为Root,其对FPGA的存储空间进行读写,读写分为很多类别,可以是存储器读写,也可以是I/O读写,细节可在数据手册上进行学习。
仿真平台
仿真平台的结构图如下:

上面的部分为用户逻辑,我们这里面接收并解析PCIe IP核收到的请求,例如读请求包,我们就会返还一个完成包,或者是一个写请求包,我们负责将写数据写入FPGA RAM空间等等。如:
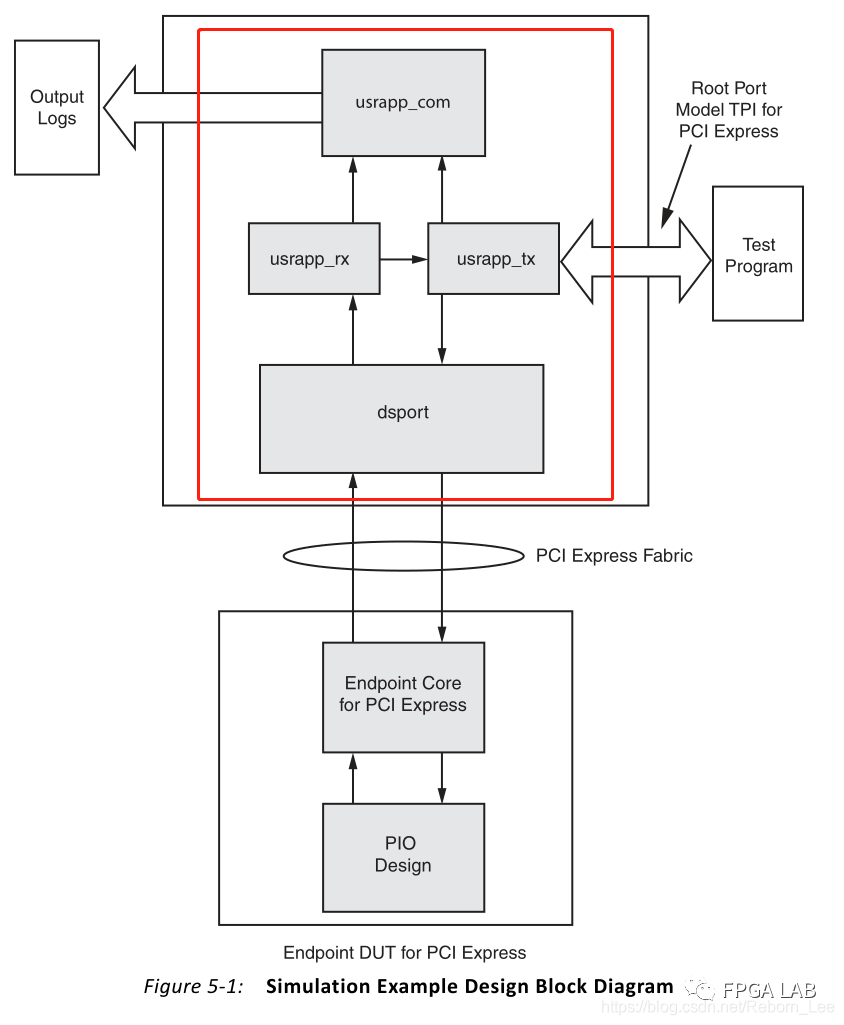
下面部分是PCIe IP经过例程包装后的部分,它与Root端进行高速串行通信。通信速率以及数据带宽根据PCIe IP的配置有关,例如是Gen2 X1就是单通道且链路速率是5Gbps的PCIe;Gen1 X1则是单通道且链路速率为2.5Gbps的 PCIe.

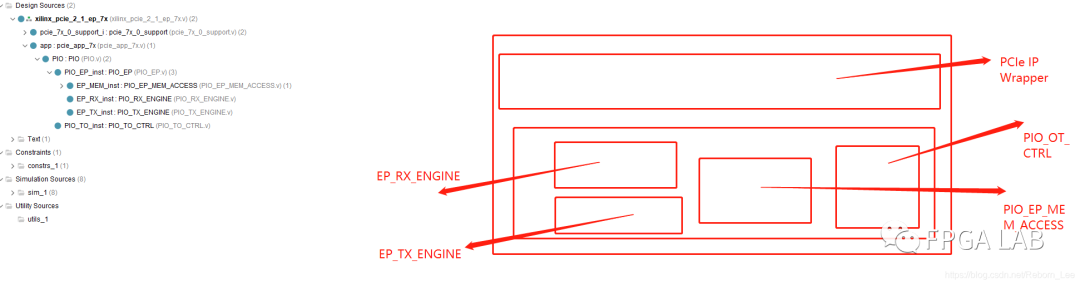
下图是例程中的用户逻辑部分的模块结构图:
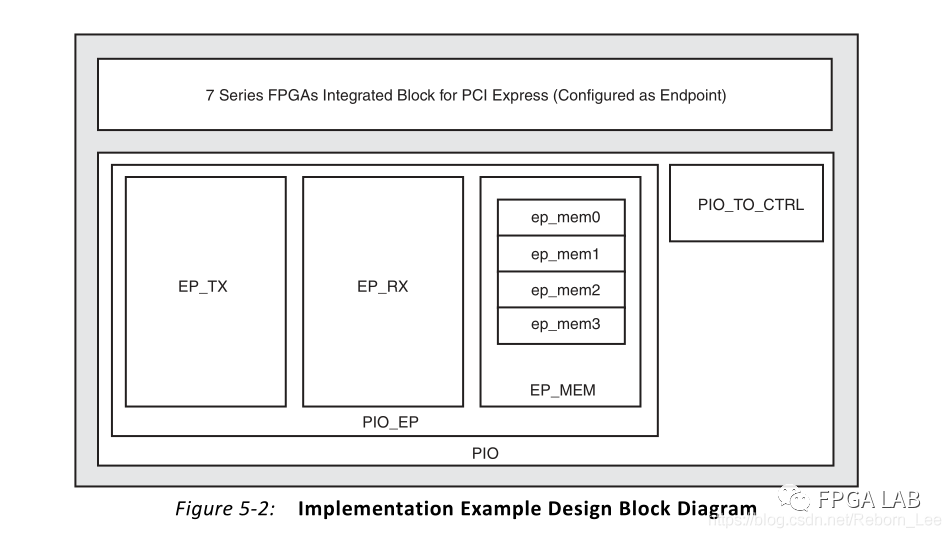
我们常常看到EP作为前缀的命名,其意思就是Endpoint,指的就是FPGA这端。我们都知道PCIe是端对端通信,协议规定的就是PC端为Root,而FPGA端为Endpoint。
可见,上面有如下几个模块:EP_RX:该模块是接收来自PCIe IP核收到的请求,该请求肯定是来自于PC端或者叫Root端,读请求或者是写请求;一般而言,收到一个请求包之后,RX会对其进行解析,如果是读请求,则需要通过另一个发送模块回复一个读完成包。
EP_TX:该模块用来向Root端发送数据包,该包在这个模块组装,然后通过AXI-S协议发送给IP核,进而与Root进行通信。
EP_MEM:该模块的作用很简单,就是一个存储结构,由于Root向EP发送读写请求,例如读,从哪里读数据呢?就在这个模块里呀,写到哪里去呢?也是从这个模块里呀。
PIO_TO_CTRL:这个模块的作用呢?是管理cfg_turnoff_ok这个信号的,具体什么用?需要斟酌!
例程手册程序概括
PIO设计是一个简单的只针对目标的应用程序,它与PCIe核心事务(AXI4-Stream)的端点接口相连接,并被提供作为构建自己设计的起点。
为了直观地理解Root Complex与Endpoint之间的区别,我们以下面的PCIe系统结构图为例,来说明数据的传输情况:
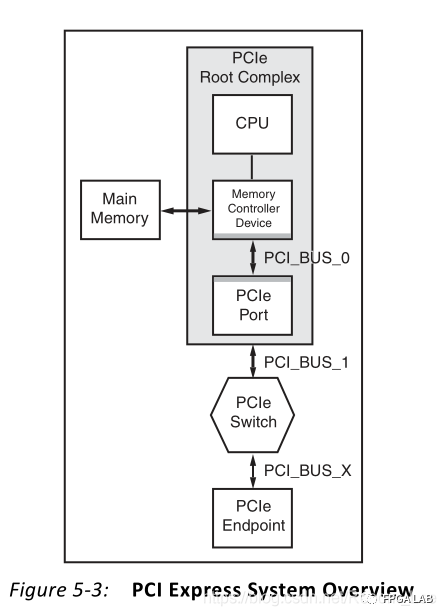
上图中多了一个PCIe Switch结构,不过没关系,我们可以把它当成中间的过渡结构,它不影响我们Endpoint端以及Root complex端的数据处理。
图5-3说明了PCI Express系统结构组件,由一个Root Complex、一个PCI Express交换设备和一个PCIe的Endpoint组成。PIO操作将数据从Root Complex(CPU寄存器)向下游移动到Endpoint,和/或从Endpoint向上游移动到Root Complex(CPU寄存器)。在这两种情况下,移动数据的PCI Express协议请求都是由主机CPU发起的。
当CPU向MMIO地址命令发出存储寄存器时,数据将向下游移动。Root Complex通常会生成一个具有适当MMIO地址的存储器写TLP包和字节使能。当Endpoint接收到存储器写TLP并更新相应的本地寄存器时,事务终止。
当CPU通过MMIO地址命令发出加载寄存器时,数据将向上游移动。Root Complex通常会生成具有适当MMIO位置地址的存储器读TLP包和字节使能。Endpoint在收到“内存读取” TLP后会生成“数据TLP完成包”。将完成操作引导到Root Complex,并将有效负载加载到目标寄存器中,从而完成事务。
此两端较为生涩,放入英文原文:
Data is moved downstream when the CPU issues a store register to a MMIO address command. The Root Complex typically generates a Memory Write TLP with the appropriate MMIO location address, byte enables, and the register contents. The transaction terminates when the Endpoint receives the Memory Write TLP and updates the corresponding local register.
Data is moved upstream when the CPU issues a load register from a MMIO address command. The Root Complex typically generates a Memory Read TLP with the appropriate MMIO location address and byte enables. The Endpoint generates a Completion with Data TLP after it receives the Memory Read TLP. The Completion is steered to the Root Complex and payload is loaded into the target register, completing the transaction.
例程用户逻辑包括如下文件:

应用程序内部数据宽度,即AXI-Stream数据总线宽度根据链路通道数不同而不同,其关系为:

则在程序里也有体现,例如我使用的是X1模式,因此:

该例程的所有模块组件:

则从文件结构也能看出:
应用程序,也即用户逻辑的接口关系为:
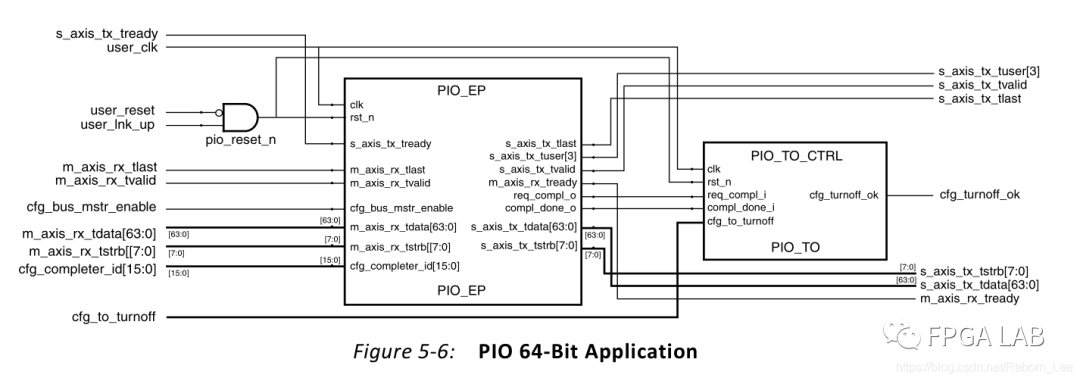
这里是以X1为例。
应用程序中的接收模块:
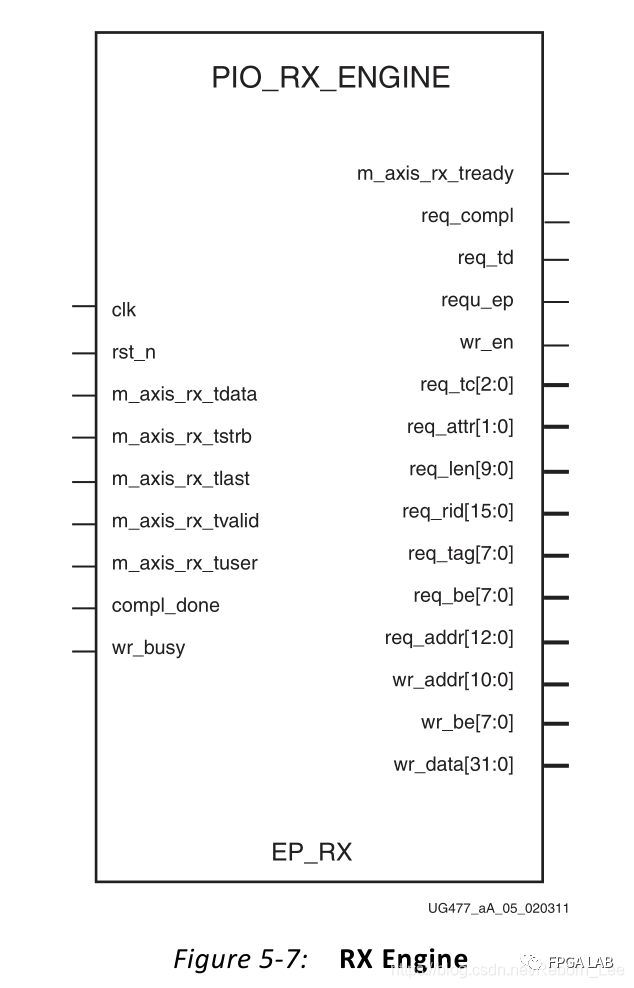
接收来自于PCIe IP核的数据,该模块与PCIe IP模块之间的接口为AXI-Stream,后面就不在赘述,对来自Root Complex端的读写请求包(TLP)进行接收并解析。
假如接收到了Root端的读请求TLP,则输出信号如下:

这都是对接收的数据包进行解析出来的结果,我们都知道PCIe是以包的形式来发送数据或者接收数据。TLP包的结构可见PCIe的事务处包(TLP)的组成,则在数据手册PG054上也是详细描述的。对这个包的输出发送给TX模块,把读出来的数据一同组成一个完成包,发送给PCIe IP核进而发送给Root Complex,这个过程是一个响应,对读请求的一个响应,这需要另一个模块,也即TX模块进行配合。下面会讲到。
如果EP接收到的包是写请求包,则EP_RX会生成另外一些信号:

输出给存储器访问模块,对存储器模块进行写数据。
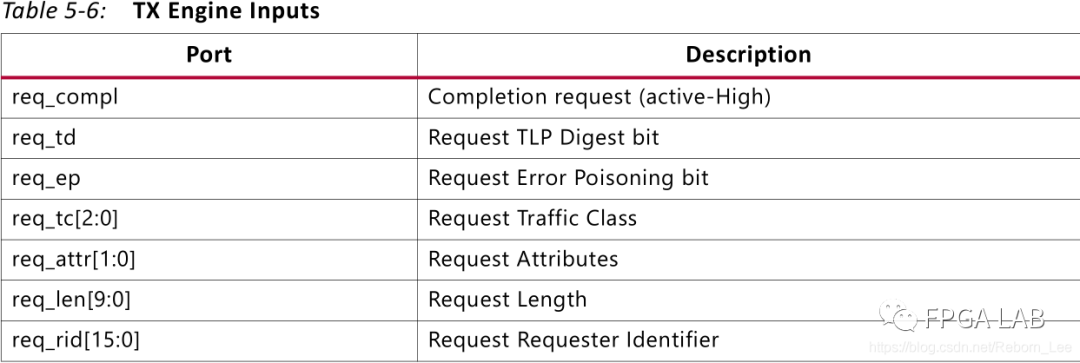
发送模块的接口示意图:

右端为输出的接口,为AXI-stream接口,与PCIe IP核连接,送出IP核需要的完成包。
其输入与RX的输入对应:

无论是读还是写,总得有个存储器写进入或者读出来才行,这就是这个模块:

其输入输出关系一目了然,不在话下。
按照数据手册得说法就是:
这个模块就是处理来自于存储器以及IO写得TLP包得数据,将其写入存储器,或者呢?用来响应存储器或者IO读TLP包,从存储器中读出数据;
对于写请求包,其接口如下:

对与读,其接口如下:

下面讲下对于读请求事务包及其响应完成包的时序关系:

如图所示,先是接收到一个读请求事务包,但第一个TLP包完成接收的时候,立刻令ready无效,并响应一个完成包。等完成包响应完成之后,拉高信号compl_done,表明响应完成,之后再接收下一个事务包。
下面是写事物请求TLP的时序关系:
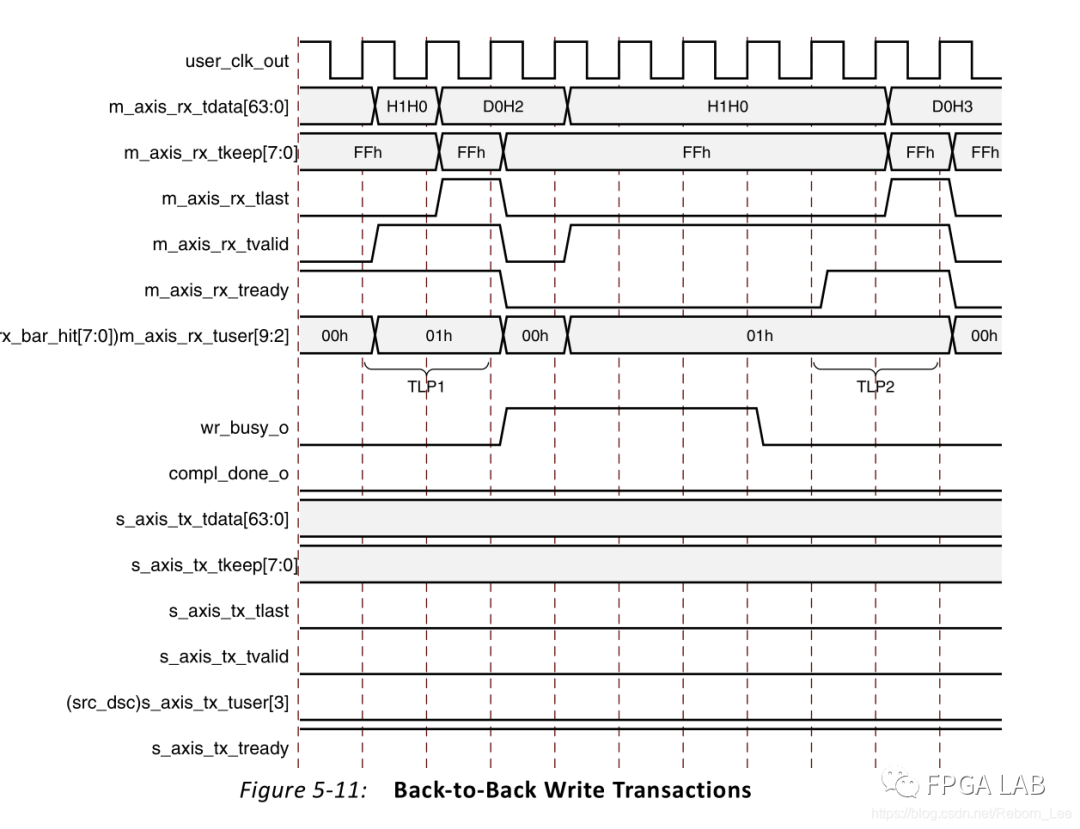
首先接收一个写请求事务包,然后写入存储器,写入的过程中,拉高wr_busy,表明正在写。写入完成之后,令wr_busy无效,表明写入完成。之后再接收另一个写事务包。
这个例程的用户程序消耗的资源为:

这表明使用了4个BRAM,就是用来写入以及读出来自Root请求的数据的存储器。
例程仿真分析
PIO_RX_ENGINE.v 分析:
首先,定义了一个变量in_packet_q,高有效,用来表示接收一个TLP包。
如下:
wire sop; // Start of packet
reg in_packet_q;
always@(posedge clk)
begin
if(!rst_n)
in_packet_q <= # TCQ 1'b0;
else if (m_axis_rx_tvalid && m_axis_rx_tready && m_axis_rx_tlast)
in_packet_q <= # TCQ 1'b0;
else if (sop && m_axis_rx_tready)
in_packet_q <= # TCQ 1'b1;
end
assign sop = !in_packet_q && m_axis_rx_tvalid;
sop表示包的开始,sop有效的条件自然是in_packet_q无效且valid有效;即:
assign sop = !in_packet_q && m_axis_rx_tvalid;
包什么时候有效呢?可以看出是sop有效且ready有效,这时候有人可能就有点晕了,到底是in_packet_q决定sop呢?还是sop决定in_packet_q呢?那必然是in_packet_q决定sop呀,因为sop的含义是包的开始呀。将sop代入in_packet_q有效的条件中去:
always@(posedge clk)
begin
if(!rst_n)
in_packet_q <= # TCQ 1'b0;
else if (m_axis_rx_tvalid && m_axis_rx_tready && m_axis_rx_tlast)
in_packet_q <= # TCQ 1'b0;
else if (!in_packet_q && m_axis_rx_valid && m_axis_rx_tready)
in_packet_q <= # TCQ 1'b1;
end
这就很明白了,其实这段程序的作用(请允许我用程序来代表硬件描述语言)就是判断包有效的标志。valid和ready有效,这packet有效,一直持续到valid,ready,以及last都有效,last表示最后一个数据。可以从仿真图中来观察:

有了包的起始标志,就可以通过判断这个信号有效,进入了包的解析状态机;这里使用了一个状态机来处理接收的TLP,对其进行解析,解析数据:
always @ ( posedge clk ) begin
if (!rst_n )
begin
m_axis_rx_tready <= #TCQ 1'b0;
req_compl <= #TCQ 1'b0;
req_compl_wd <= #TCQ 1'b1;
req_tc <= #TCQ 3'b0;
req_td <= #TCQ 1'b0;
req_ep <= #TCQ 1'b0;
req_attr <= #TCQ 2'b0;
req_len <= #TCQ 10'b0;
req_rid <= #TCQ 16'b0;
req_tag <= #TCQ 8'b0;
req_be <= #TCQ 8'b0;
req_addr <= #TCQ 13'b0;
wr_be <= #TCQ 8'b0;
wr_addr <= #TCQ 11'b0;
wr_data <= #TCQ 32'b0;
wr_en <= #TCQ 1'b0;
state <= #TCQ PIO_RX_RST_STATE;
tlp_type <= #TCQ 8'b0;
end
else
begin
wr_en <= #TCQ 1'b0;
req_compl <= #TCQ 1'b0;
case (state)
PIO_RX_RST_STATE : begin
m_axis_rx_tready <= #TCQ 1'b1;
req_compl_wd <= #TCQ 1'b1;
if (sop)
begin
case (m_axis_rx_tdata[30:24])
PIO_RX_MEM_RD32_FMT_TYPE : begin
tlp_type <= #TCQ m_axis_rx_tdata[31:24];
req_len <= #TCQ m_axis_rx_tdata[9:0];
m_axis_rx_tready <= #TCQ 1'b0;
if (m_axis_rx_tdata[9:0] == 10'b1)
begin
req_tc <= #TCQ m_axis_rx_tdata[22:20];
req_td <= #TCQ m_axis_rx_tdata[15];
req_ep <= #TCQ m_axis_rx_tdata[14];
req_attr <= #TCQ m_axis_rx_tdata[13:12];
req_len <= #TCQ m_axis_rx_tdata[9:0];
req_rid <= #TCQ m_axis_rx_tdata[63:48];
req_tag <= #TCQ m_axis_rx_tdata[47:40];
req_be <= #TCQ m_axis_rx_tdata[39:32];
state <= #TCQ PIO_RX_MEM_RD32_DW1DW2;
end // if (m_axis_rx_tdata[9:0] == 10'b1)
else
begin
state <= #TCQ PIO_RX_RST_STATE;
end // if !(m_axis_rx_tdata[9:0] == 10'b1)
end // PIO_RX_MEM_RD32_FMT_TYPE
PIO_RX_MEM_WR32_FMT_TYPE : begin
tlp_type <= #TCQ m_axis_rx_tdata[31:24];
req_len <= #TCQ m_axis_rx_tdata[9:0];
m_axis_rx_tready <= #TCQ 1'b0;
if (m_axis_rx_tdata[9:0] == 10'b1)
begin
wr_be <= #TCQ m_axis_rx_tdata[39:32];
state <= #TCQ PIO_RX_MEM_WR32_DW1DW2;
end // if (m_axis_rx_tdata[9:0] == 10'b1)
else
begin
state <= #TCQ PIO_RX_RST_STATE;
end // if !(m_axis_rx_tdata[9:0] == 10'b1)
end // PIO_RX_MEM_WR32_FMT_TYPE
PIO_RX_MEM_RD64_FMT_TYPE : begin
tlp_type <= #TCQ m_axis_rx_tdata[31:24];
req_len <= #TCQ m_axis_rx_tdata[9:0];
m_axis_rx_tready <= #TCQ 1'b0;
if (m_axis_rx_tdata[9:0] == 10'b1)
begin
req_tc <= #TCQ m_axis_rx_tdata[22:20];
req_td <= #TCQ m_axis_rx_tdata[15];
req_ep <= #TCQ m_axis_rx_tdata[14];
req_attr <= #TCQ m_axis_rx_tdata[13:12];
req_len <= #TCQ m_axis_rx_tdata[9:0];
req_rid <= #TCQ m_axis_rx_tdata[63:48];
req_tag <= #TCQ m_axis_rx_tdata[47:40];
req_be <= #TCQ m_axis_rx_tdata[39:32];
state <= #TCQ PIO_RX_MEM_RD64_DW1DW2;
end // if (m_axis_rx_tdata[9:0] == 10'b1)
else
begin
state <= #TCQ PIO_RX_RST_STATE;
end // if !(m_axis_rx_tdata[9:0] == 10'b1)
end // PIO_RX_MEM_RD64_FMT_TYPE
PIO_RX_MEM_WR64_FMT_TYPE : begin
tlp_type <=