 python文件操作是什么
python文件操作是什么
一、什么是文件操作
一个完整的程序一般都包括数据的存储和读取;我们在前面写的程序数据都没有进行实际的存储,因此python解释器执行完数据就消失了
实际开发中,我们经常需要从外部存储介质(硬盘、光盘、U盘等)读取数据,或者将程序产生的数据存储到文件中,实现“持久化”保存
1.1. 文件分类按文件中数据组织形式,我们把文件分为文本文件和二进制文件两大类:
文本文件文本文件存储的是普通“字符”文本,python默认为 unicode 字符集,可以使用记事本程序打开
二进制文件二进制文件把数据内容用“字节”进行存储,无法用记事本打开, 必须使用专用的软件解码。
常见的有:MP4视频文件、MP3音频文件、JPG图片、doc文档等等
1.2. 常用编码在操作文本文件时,经常会操作中文,这时候就经常会碰到乱码问题。 为了解决中文乱码问题,需要学习下各个编码之前的问题。
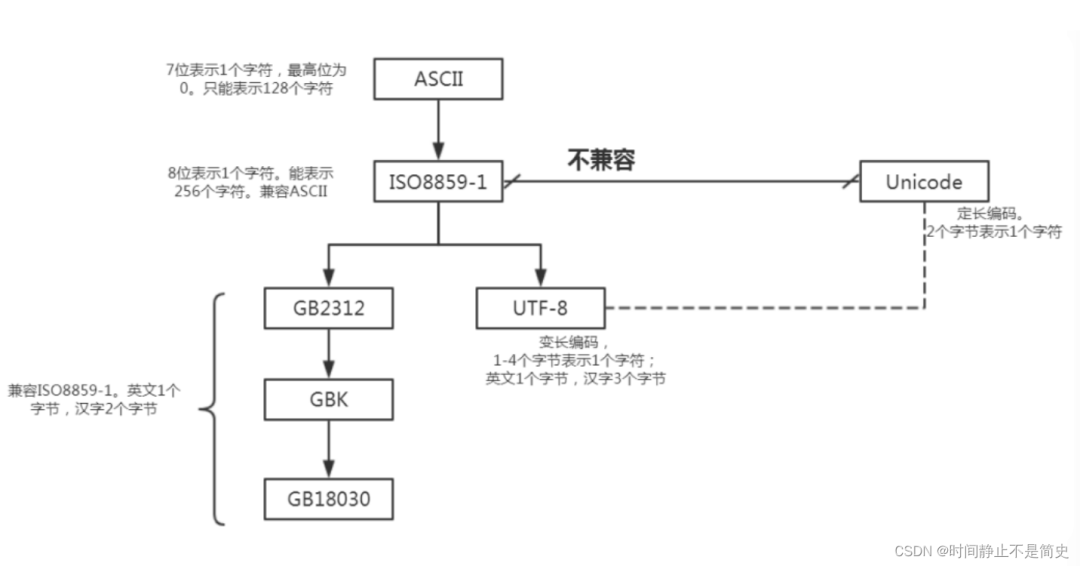
常用编码之间的关系如下:
ASCII
全称为 American Standard Code for Information Interchange
,美国信息交换标准代码,这是世界上最早最通用的单字节编码系统,主要用来显示现代英语及其他西欧语言
注意事项:
ASCII 码用7位表示,只能表示128个字符。 只定义了2^7=128个字符,用7bit即可完全编码, 而一字节8bit的容量是256,所以一字节
ASCII 的编码最高位总是0
ASCll 码对应码表如下: ASCll 码表
GBK
GBK即汉字内码扩展规范,英文全称Chinese Internal Code Specification.
GBK编码标准兼容GB2312,共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。GBK采用双字节表示,总体编码范围为8140-FEFE,首字节在81-FE
之间,尾字节在40-FE 之间
Unicode
Unicode
编码设计成了固定两个字节,所有的字符都用16位2^16=65536表示,包括之前只占8位的英文字符等,所以会造成空间的浪费Unicode 完全重新设计,不兼容
iso8859-1 ,也不兼容任何其他编码
UTF-8
对于英文字母, unicode 也需要两个字节来表示, 所以 unicode 不便于传输和存储。 因此而产生了 UTF编码 , UTF-8 全称是(
8-bit UnicodeTransformation Format )
注意事项
UTF 编码兼容 iso8859-1 编码,同时也可以用来表示所有语言的字符
UTF 编码是不定长编码,每一个字符的长度从1-4个字节不等。英文字母都是用一个字节表示,而汉字使用三个字节
一般项目都会使用 UTF-8我们之所以倾向于使用UTF-8 , 是因为其不定长编码可以在节省内存的同时能够完全兼容中文
刚进入名为人偶悬廊的外围, 小知便看到了异样: 自己的僵尸小弟没有按照自己的命令继续攻略地下城, 而是在地图外围漫无目的徘徊着。
而且不仅仅是自己的僵尸小弟, 甚至还看到了冒险家, 只不过他们也是像僵尸一样, 如机械般的行动轨迹甚至让小知怀疑他们是否还活着。 为了能够更近距离的观察异样,
小知决定趁机弄晕一个冒险家, 然后自己加装被控制的冒险家来进行调查.
-
程序
+关注
关注
117文章
3795浏览量
81334 -
python
+关注
关注
56文章
4807浏览量
84984
发布评论请先 登录
相关推荐




Python文件操作教程免费下载

python的文件操作教程详细说明








 工商网监
工商网监
评论