 SPI NAND驱动性能测试分析与优化
SPI NAND驱动性能测试分析与优化
一.前言
https://mp.weixin.qq.com/s/hgogGTFzBDx83sFjDX8lVw一文中我们详细介绍了SPI NAND,也实现了相关的驱动(如果需要驱动源码可以和我联系)。X1和x4模式的擦除,写,读等都测试OK了。现在我们需要进行性能测试和优化。https://mp.weixin.qq.com/s/uLraKF5kWMTHLpTggh2Q4Q一文中也介绍了ONFI。
二. 性能测试
既然是追求性能,所以我们后面就都基于X4模式进行了。
我们分别进行擦除,写,读全盘测试(128MB),然后使用定时器计算操作的时间。
性能测试代码如下:
nand_set_qe(1,3); /* 使能QE模式 */
/* 擦除 */
pre = iot_timer_get_time();
for(uint32_t block=0; block < dev.blocks_per_lun*dev.luns; block++)
{
if(0 != (res = nand_block_erase(block*dev.pages_per_block)))
{
iot_printf("block %d erase err
",block,res);
}
}
cur = iot_timer_get_time();
if(cur < pre)
{
used = 0xFFFFFFFF - pre + cur;
}
else
{
used = cur-pre;
}
printf("erase time:%duS
",used);
/* 编程 */
memset(w_buffer,0xFF,sizeof(w_buffer));
w_buffer[dev.page_size] = 0xFF; /* 坏块标志不能擦除 */
pre = iot_timer_get_time();
for(uint32_t block=0; block < dev.blocks_per_lun*dev.luns; block++)
{
for(uint32_t page=0; page< dev.pages_per_block; page++)
{
if(0 != (res = nand_write_page_x4(w_buffer, block*dev.pages_per_block+page, 0, dev.page_size+dev.page_spare_size)))
{
iot_printf("write page %d err %d
",block*dev.pages_per_block+page,res);
}
}
}
cur = iot_timer_get_time();
if(cur < pre)
{
used = 0xFFFFFFFF - pre + cur;
}
else
{
used = cur-pre;
}
printf("write time:%duS
",(cur-pre));
/* 读 */
pre = iot_timer_get_time();
for(uint32_t block=0; block < dev.blocks_per_lun*dev.luns; block++)
{
for(uint32_t page=0; page< dev.pages_per_block; page++)
{
if(0 != (res = nand_read_page_x4(r_buffer, block*dev.pages_per_block+page, 0, dev.page_size+dev.page_spare_size)))
{
iot_printf("write page %d err %d
",block*dev.pages_per_block+page,res);
}
}
}
cur = iot_timer_get_time();
if(cur < pre)
{
used = 0xFFFFFFFF - pre + cur;
}
else
{
used = cur-pre;
}
printf("read time:%duS
",(cur-pre));
测试结果如下
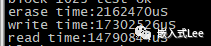
对于写
128MB花了17.40S
所以速度是7.36MB/S
三. 性能分析
我们使用逻辑分析仪抓取总线波形,用于进行性能分析
参考文章https://mp.weixin.qq.com/s/bCdgCNsGPbYjSzjv8VJyRA
我们以编程为例,擦除和读类似。
编程PAGE的代码如下,有三个步骤
即先写数据到CACHE,然后写使能,最后执行CACHE到PAGE的数据编程。
int nand_write_page_x4(uint8_t* buffer, uint32_t pageaddr, uint16_t start, uint16_t len)
{
int res = 0;
res = nand_write_to_cache_x4(start, len, buffer);
if(res == 0)
{
res = nand_write_enable();
if(res == 0)
{
res = nand_write_cache_to_page(pageaddr,NAND_PROG_CHECK_RETRY);
if(res == 0)
{
return 0;
}
else
{
return -3;
}
}
else
{
return -2;
}
}
else
{
return -1;
}
}
查看逻辑分析仪抓取到的数据如下,对应如下三个步骤

(1)总线上写数据到NAND的Cache
(2)写使能,并查询写使能OK
(3)执行CACHE到PAGE编程,并查询完成
从以上时间戳可以看到三个步骤分别对应的时间是
第一次开始
19:48:31.513.198.648,PROGRAM LOAD x4(32),0000, ,FF,FF,FF,FF,FF,FF,FF,FF,........,
开始写使能
19:48:31.513.259.134,WRITE ENABLE(06), , , , , , , , , , , ,
开始编程
19:48:31.513.273.890,PROGRAM EXECUTE(10),0040BE, , , , , , , , , , ,
编程完成
19:48:31.513.344.141,GET FEATURE(0F),C0, ,00, , , , , , , ,.,
下一次开始
19:48:31.513.435.474,PROGRAM LOAD x4(32),0000, ,FF,FF,FF,FF,FF,FF,FF,FF,........,
一个PAGE编程的周期
所以一个PAGE的编程时间是下一次开始和前一次开始的时间间隔
435.474-198.648=236.826uS
一次操作是写2048+128字节,对应236.826uS,换算就是8.76MB/S比使用软件定时器测试的7.36MB/S大一点,因为软件额外一些逻辑处理需要一些时间,比如获取定时器时间,块之间的循环切换等。
波形如下

总线上数据传输时间
总线写数据时间即第一次开始到开始写使能,
259.134-198.648=60.486uS
如下如图,后面6.96uS是两次传输之间的间隔,即软件完成一次传输到下一次传输之间的时间,也算在这个阶段了。

写使能时间
由于编程完之后,NAND会自动写禁止,所以每次都需要重新写使能。
执行写使能后要回读是否设置成功(当然回读也可以省略但是出于可靠性考虑还是建议回读,如果回读未使能再重试)。
对应如下
273.890-259.134=14.756uS

编程时间
344.141-273.890=70.251

软件处理时间
从下可以看出编程完成到下一次开始,还有
91uS

这一部分是软件处理时间,主要是软件从NAND控制器的缓存区中将数据搬运到用户存储中去。
所以整理下各阶段的时间消耗如下
| 总线传输 | 写使能 | 编程 | 软件处理 | 总 | |
|---|---|---|---|---|---|
| 时间 | 60.49 | 14.76 | 70.25 | 91 | 236.5 |
| 占比 | 25.58% | 6.24% | 29.7% | 38.48% | 100% |
可以看出软件处理实际占用时间比例最大,主要是从控制器的缓冲区中将数据搬运到用户存储的时间。
四. 性能优化
针对以上性能分析过程,对各个阶段考虑优化
1. 总线传输
已经使用了X4模式, 如果还要缩短该阶段的时间,只能继续提高频率了,目前是80M的时钟,手册中参数是3.3V快读可达133MHz。
针对读还可以使用DTR双边沿模式但是这时最大时钟频率只有70MHz,双边沿也就是140M所以比133M也大不了多少。

2. 写使能时间
由于每次编程之后,NAND自动写禁止,所以该步骤不能少,可以减少回读操作大约节省7uS,但是出于可靠性设计,建议还是回读,如果回读不成功则重试。
3. 编程时间
手册中描述的时间是不使能ECC也最少要300uS,我们实测是70uS左右,所以手册已经写的很保守了,这里也没有优化空间了。

4软件处理时间
这一部分主要是软件在用户存储和NAND控制器的缓存之间拷贝数据的时间。
最好是这一部分工作由控制器完成,而不是软件去搬运,比如软件指定一个地址,控制器自动从这个地址读,或者写入这个地址,而不是通过缓存再转一遍,减少拷贝时间。
软件时间还包括逻辑处理时间,比如一次传输到下一次传输,需要配置寄存器,进行判断,等逻辑处理。
由于软件是分层设计包括HW层寄存器的封装,HAL层传输的接口,以设备驱动层,
对于HW层封装可以使用宏或者内联函数替代函数,减少函数调用时间,HW层和HAL不做参数检查,因为接口调用频繁等,在设备驱动层做参数检查。
/**
* n int nfc_set_datalen(uint8_t id, uint16_t len)
* param[in] id port id
* param[in] len data len
*
etval 0 ok
*
etval < 0 param err
*
*/
NFC_INLINE int nfc_set_datalen(uint8_t id, uint16_t len)
{
uint32_t tmp;
(void)id;
tmp = NFC_READ_REG(CFG_NFC_ENA_ADDR);
tmp &= ~NFC_DATA_LEN_MASK;
tmp |= (len < < NFC_DATA_LEN_OFFSET);
NFC_WRITE_REG(CFG_NFC_ENA_ADDR,tmp);
return 0;
}
六.波形文件
这里分享一些实际抓取到的波形文件供参考
波形文件使用软件Acute TravelLogic Analyzer打开查看。
链接:https://pan.baidu.com/s/103HHT4qcvFjGn1q-jJhAUg?pwd=iqlm
提取码:iqlm
七. 总结
从以上分析可以看出最大的优化空间是减少软件从控制器缓冲区去搬运数据的时间,这一部分时间占最大头,可IP设计优化直接硬件搬运数据到用户存储。
审核编辑:汤梓红
-
NAND
+关注
关注
16文章
1685浏览量
136227 -
存储
+关注
关注
13文章
4328浏览量
85942 -
SPI
+关注
关注
17文章
1711浏览量
91748 -
性能测试
+关注
关注
0文章
211浏览量
21349
发布评论请先 登录
相关推荐
使用逻辑分析仪Acute TravelLogic Analyzer进行SPI NAND驱动开发调试

雷龙CS SD NAND:贴片式TF卡体验与性能测试
SPI NAND FLASH 的简介和优点
怎样对基于NK-980IOT开发板的SPI NAND Flash进行读写测试呢
SPI Nand Flash 简介
《现代CPU性能分析与优化》---精简的优化书
《现代CPU性能分析与优化》--读书心得笔记
SPI Nand Flash简介

SD NAND和SPI NAND的区别
SD NAND、SPI NAND和eMMC的区别对比分析

华为云 X 实例 CPU 性能测试详解与优化策略






 工商网监
工商网监
评论