 PowerBEV的高效新型端到端框架基于流变形的后处理方法
PowerBEV的高效新型端到端框架基于流变形的后处理方法
摘要
准确地感知物体实例并预测它们未来的运动是自动驾驶车辆的关键任务,使它们能够在复杂的城市交通中安全导航。虽然鸟瞰图(BEV)表示在自动驾驶感知中是常见的,但它们在运动预测中的潜力尚未得到充分探索。现有的从环绕摄像头进行BEV实例预测的方法依赖于多任务自回归设置以及复杂的后处理,以便以时空一致的方式预测未来的实例。在本文中,我们不同于这中范例,提出了一个名为PowerBEV的高效新型端到端框架,采用了几种旨在减少先前方法中固有冗余的设计选择。首先,与其按自回归方式预测未来,PowerBEV采用了由轻量级2D卷积网络构建的并行多尺度模块。其次,我们证明,分割和向心反向流对于预测是足够的,通过消除冗余输出形式简化了先前的多任务目标。基于此输出表示,我们提出了一种简单的基于流变形的后处理方法,可在时间上产生更稳定的实例关联。通过这种轻量化但强大的设计,PowerBEV在NuScenes数据集上胜过了最先进的方法,并为BEV实例预测提供了一种替代范例。
主要贡献
我们提出了PowerBEV,一个新颖而优雅的基于视觉的端到端框架,它只由2D卷积层组成,用于在BEV中执行多个对象的感知和预测。
我们证明,由于冗余表示引起的过度监督会影响模型的预测能力。相比之下,我们的方法通过简单地预测分割和向心反向流来实现语义和实例级别的代理预测。
我们提出的基于向心反向流的提议分配优于以前的前向流结合传统的匈牙利匹配算法。
主要方法
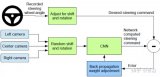
我们的方法的框架如图1所示。它主要由三个部分组成:感知模块、预测模块和后处理阶段。感知模块将M个多视角相机图像作为个时间戳的输入,并将他们转换为个BEV特征图。然后,预测模块融合提取的BEV特征中包含的时空信息,并同时预测一系列分割地图和向心反向流,用于未来帧。最后,通过基于变形的后处理。从预测的分割和流中恢复未来的实例预测。
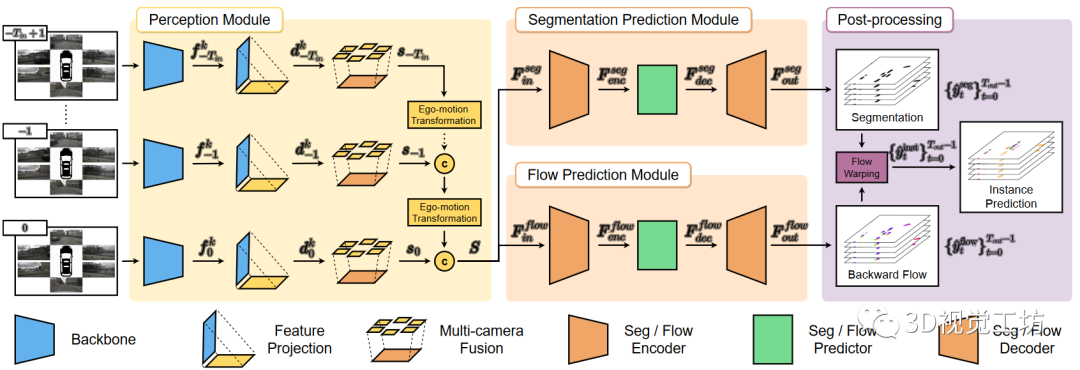 图1:PowerBEV的框架
图1:PowerBEV的框架
1、基于LSS的感知模块
为了获取用于预测的视觉特征,我们遵循之前的工作,并在LSS的基础上建立起从环绕摄像机中提取BEV特征网格。对于每个时间t的每个相机图像,我们应用共享的EfficientNet网络来提取透视特征,其中我们将的前个通道指定为上下文特征,后面的个通道表示分类深度分布。通过外积构造一个三维特征张量。
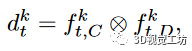
其中,根据估计的深度分布置信度将上下文特征提升到不同的深度中。然后,每个时间戳的每个相机特征分布映射基于对应相机的已知内部参数和外部参数被投影到以车辆为中心的坐标系中。随后,它们沿着高度维度加权,以获得时间戳t处的全局BEV状态,其中是状态通道数量,(H,W)是BEV状态地图的网格大小。最后,所有的BEV状态合并到当前帧中,并像FIERY一样堆叠,因此这追踪表示是独立于自车位置的当前全局动态。
2、多尺度预测模块
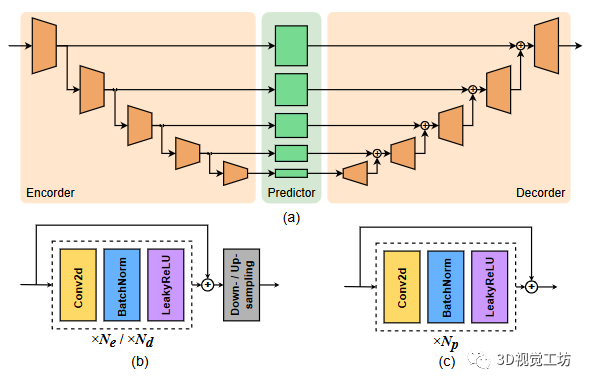 图2:多尺度预测模块的结构
图2:多尺度预测模块的结构
获得过去环境的简洁表示S后,我们使用一个多尺度U-Net类编码器解码器架构,将观察到的BEV特征图作为输入,并预测未来的分割地图和向心反向流场,如图2所示。为了仅使用2D卷积进行时空特征处理,我们将时间和特征维度折叠成一个单一的维度,从而得到输入张量。编码器首先逐步在空间上对进行下采样,生成多尺度BEV特征,其中。在一个中间的预测器阶段,将特征从映射到,获取。最后,解码器镜像编码器,在原始尺度上重建出未来的BEV特征。每个分支分别被监督以预测未来的分割地图或向心反向流场。考虑到任务和监督的差异,我们为每个分支使用相同的架构但不共享权重。与以前基于空间LSTM或空间GRU的工作相比,我们的架构只利用2D卷积,在解决长程时间依赖性方面大大缓解了空间RNN的限制。
3、多任务的设置
现有的方法遵循自下而上的原则,为每个帧生成实例分割,然后根据前向流使用匈牙利匹配算法在帧之间关联实例。因此,需要四个不同的头部:语义分割、中心性、未来前向流和BEV中的每像素向心偏移。这导致由于多任务训练而产生模型冗余和不稳定性。相比之下,我们首先发现,流和向心偏移都是实例掩模内的回归任务,并且流可以理解为运动偏移量。此外,这两个量与中心性在两个阶段中组合:(1)向心偏移将像素分组到每个帧中预测的实例中心,以将像素分配给实例ID;(2)流用于匹配两个连续帧中的中心以进行实例ID关联。基于以上分析,使用统一表示形式直观地解决这两个任务。为此,我们提出了向心反向流场,它是从时间t处的每个前景像素到时间t−1处关联实例标识的对象中心的位移向量。这将像素到像素的反向流向量和向心偏移向量统一为单一表示形式。使用我们提出的流,可以直接将每个占用的像素关联到上一帧中的实例ID。这消除了将像素分配给实例的额外聚类步骤,将先前工作中使用的两阶段后处理简化为单阶段关联任务。此外,我们发现语义分割地图和中心性的预测非常相似,因为中心基本对应于语义实例的中心位置。因此,我们建议直接从预测的分割地图中提取局部最大值来推断对象中心。这消除了分别预测中心的需要,如图3所示。
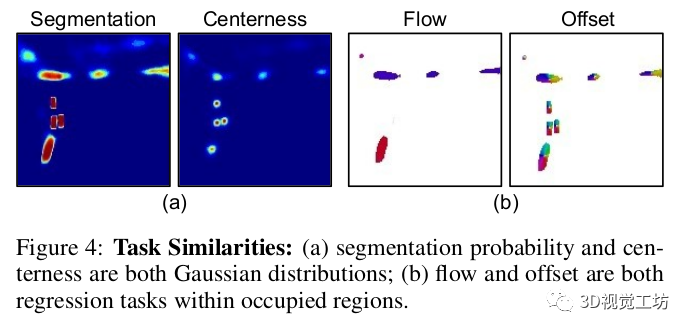
图3:多任务设置
总的来说,我们的网络仅仅产生两个输出,语义分割和向心反向流。我们使用top-k,k=25%的交叉熵作为语义分割损失函数,平滑的L1距离作为流动损失函数。总的损失函数为。
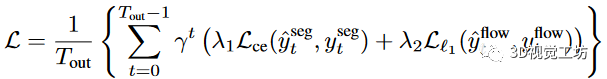
,和使用不确定性权重自动的更新。
4、实例关联
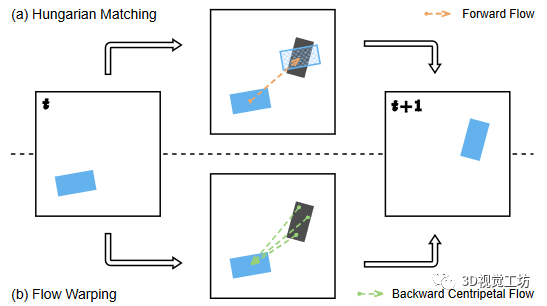 图4:实例关联
图4:实例关联
对于实例预测,我们需要随着时间推移将未来的实例相互关联。现有的方法使用前向流将实例中心投影到下一帧,然后使用匈牙利匹配将最近的代理中心进行匹配,如图4.a所示。这种方法执行实例级别的关联,其中实例身份由其中心表示。因此,仅使用位于对象中心上的流向量用于运动预测。这有两个缺点:首先,没有考虑对象旋转;其次,单个位移向量比覆盖整个实例的多个位移向量更容易出错。在实践中,这可能导致重叠的预测实例,导致错误的ID分配。这在长期预测范围内的近距离物体上尤为明显。利用我们提出的向心反向流,我们进一步提出了基于变形的像素级关联来解决上述问题。我们的关联方法的说明如图4.b所示。对于每个前景网格单元,该操作将实例ID直接从前一个帧中流向量目标处的像素传播到当前帧。使用此方法,每个像素的实例ID都被单独分配,从而产生像素级关联。与实例级别关联相比,我们的方法对严重的流预测错误更具有容忍度,因为真实中心周围的相邻网格单元倾向于共享相同的身份,而错误往往发生在单个外围像素上。此外,通过使用向后流变形,可以将多个未来位置与前一帧中的一个像素关联起来。这对于多模式未来预测是有益的。正如所述,向后关联需要在前一帧中的实例ID。特殊情况是第一个帧(t = 0)的实例分割生成,其没有其前一帧(t = -1)的实例信息可用。因此,仅针对时间戳t = 0,我们通过将像素分组到过去实例中心来分配实例ID。
主要结果
我们首先将我们的方法与其他baseline相比较,结果如表1所示。我们的方法在感知范围设置下的评估指标IoU(Intersection-over-Union)和VPQ(video panoptic quality)均取得了显着的改进。在长距离设置中,PowerBEV的表现优于重新生成的FIERY,在IoU方面提高了1.1%,在VPQ方面提高了2.9%。此外,尽管使用较低的输入图像分辨率和更少的参数,PowerBEV在所有指标上的表现都优于BEVerse。与其他引入模型随机过程的方法相比,PowerBEV是一种确定性方法,能够实现准确的预测。这也展示了反向流在捕捉多模态未来方面的能力。
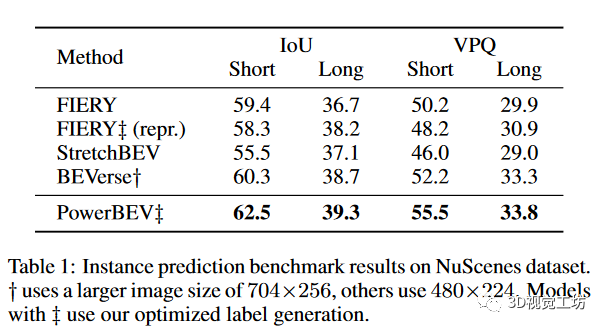 图5:定量评估解决
图5:定量评估解决
下图展示了我们方法的定性结果。我们展示了在三种典型驾驶场景中(城市道路上交通密集的情况、停车场中静态车辆众多的情况和雨天驾驶场景)与FIERY的比较。我们的方法为最常见的交通密集场景提供了更精确、更可靠的轨迹预测,这在第一个例子中变得特别明显,其中车辆转向自车左侧的侧街。而FIERY只对车辆位置作出了一些模糊的猜测,并且难以处理它们的动态特征,与之相反,我们的方法提供了更好地匹配真实车辆形状以及未来可能轨迹的清晰物体边界。此外,从第二个例子的比较中可以看出,我们的框架可以检测到位于较远距离的车辆,而FIERY则失败了。此外,我们的方法还可以检测到在雨天场景中被墙壁遮挡的卡车,即使对于人眼来说也很难发现。
 图6:可视化对比结果
图6:可视化对比结果
责任编辑:彭菁
-
模块
+关注
关注
7文章
2722浏览量
47577 -
框架
+关注
关注
0文章
403浏览量
17513 -
自动驾驶
+关注
关注
784文章
13877浏览量
166618
原文标题:IJCAI2023|PowerBEV:一个强大且轻量的环视图像BEV实例预测框架
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
TCP端到端等效噪声模型及拥塞控制方法研究
SDN中的端到端时延
端到端的自动驾驶研发系统介绍

基于帧级特征的端到端说话人识别方法

采用带有transformer的端到端框架获取对应集合结果

使用FastDeploy在英特尔CPU和独立显卡上端到端高效部署AI模型
新型的端到端弱监督篇幅级手写中文文本识别方法PageNet

PVT++:通用的端对端预测性跟踪框架






 工商网监
工商网监
评论