 利用AMD本能加速器将HPC的可持续性提升到一个新的水平
利用AMD本能加速器将HPC的可持续性提升到一个新的水平
高性能计算 (HPC) 已成为我们现代世界的重要组成部分,执行对科学研究、工程、安全和其他领域至关重要的复杂模拟和计算。然而,随着对HPC的需求不断增长,通常是在超级计算机和大型数据中心,对其环境影响的担忧也在增加。近年来,鉴于对总拥有成本和气候问题的影响,人们越来越关注数据中心的可持续性。在这篇博文中,我们将探讨有关数据中心能效的一些关键问题,并讨论 AMD 帮助减少 HPC 对环境的影响的一些策略。
数据中心面临的最大挑战之一是当您扩展到百万兆次级及更高规模时,它们的能耗。服务器节点消耗大量能量,HPC 需要更多能量,其所有 CPU 和加速器,这使得提高效率成为重要优先事项。随着对 HPC 计算需求的不断增加,我们遇到了能耗是一个门控因素的情况。这种能源消耗不仅给环境带来了压力,也给数据中心运营商的底线带来了压力,因为行业需要更多的计算性能。因此,随着行业迈向下一个里程碑,需要大幅提高每瓦性能。
由于 AMD 是尖端服务器 CPU 和 GPU 的设计者,我们认识到我们在解决这些关键优先事项方面的重要作用。我们专注于提高服务器能效,降低数据中心总拥有成本 (TCO),并提供高性能计算 (HPC),以帮助应对世界上一些最严峻的挑战。早在 2021 年 2 月,AMD 就宣布了一个雄心勃勃的目标,即提高运行处理器的能效......要实现这一目标,AMD 需要以比过去五年中全行业总体改进快 5.<> 倍以上的速度提高计算节点的能效。
AMD Instinct™ 加速器通过在设备和系统级别提供卓越的每瓦性能,从而实现高能效的 HPC 和 AI,从而提高计算的能效。要实现 AMD HPC 和 AI 能效目标,需要围绕架构、内存和互连进行更高水平的思考,这些架构、内存和互连相结合,可加速系统级改进。对于我们的 AMD Instinct MI200 系列加速器,我们从多方面的角度看待它,我们将在下面更详细地解释一些关键技术,以实现每瓦特和效率的领先性能。
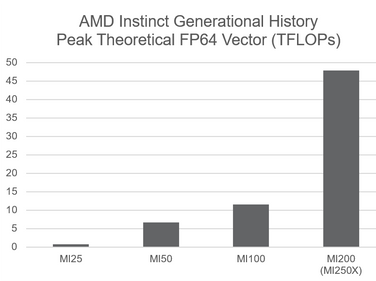
架构技术 – MI2 系列中的 AMD CDNA™ 200 架构通过增强面向 HPC 和 AI 的矩阵核心技术,推动双精度浮点数据和各种矩阵乘法基元的计算能力,代表了与上一代产品相比的重大飞跃。一个特别强调的是使用FP64矩阵和矢量数据的科学计算,以便在橡树岭国家实验室前沿超级计算机等大型系统中扩展时实现百万兆次级的性能,性能为1.1 exaflops。与上一代 MI4 CDNA 架构相比,这些改进使 FP64 矢量 TFLOP/s 和 2.5 倍 FP64 TFLOPS/瓦特相应提高了 100 倍,从而提高了每瓦性能。
封装技术 – 小芯片和先进的封装技术是提高性能和整体效率的巨大杠杆。它们允许您将不同的技术用于不同的功能,组合多个加速器芯片,并使加速器更接近内存等。互连密度越密集,解决方案的效率就越高,并有助于降低昂贵的数据传输能耗。
MCM - 全球首款多芯片 GPU,旨在通过单个封装最大限度地提高计算和数据吞吐量。MI250 和 MI250X 在单个封装中使用两个 AMD CDNA 2 图形内核芯片 (GCD),在高度精简的封装中提供 58 亿个晶体管,与 AMD 上一代加速器相比,内核数量增加了 1.8 倍,内存带宽提高了 2.6 倍 。两个GCD通过高速接口连接在一起,用于芯片到芯片的通信。
高架扇出桥 – 将 AMD CDNA 芯片连接到基板上各自的 HBM2E 内存堆栈,这可以降低复杂性并提高可扩展性,同时降低成本。传统上,硅中介层部署有微凸块以支持高密度互连。这种方法需要一个大的硅衬底来支撑上面的整个硅加HBM组件。
通信技术 – 在开发高性能计算机时,通信是处理大量数据的关键。在处理器和外部世界之间高效移动数据的能力对于向上和向外扩展的系统性能也至关重要。将硅芯片在物理和电气上更紧密地结合在一起,可以大大降低通信能量,同时提供更高的吞吐量潜力。AMD Infinity 架构是我们在 CPU 和 GPU 以及 GPU 到 GPU 之间的高速通信高速公路,我们将在加速器中讨论提高通信效率的两个领域。
芯片到芯片互连 - 封装内 AMD 无限结构™接口是 AMD CDNA 2 系列的关键创新之一,可连接 MI2 或 MI250X 中的 250 个 GCD。它利用封装内 GCD 之间的极短距离,以 25 Gbps 和极低的功耗运行,在 GCD 之间提供高达 400 GB/s 的理论最大双向带宽。
Infinity Architecture – 最新的 AMD Instinct 产品使用我们的第 3 代 Infinity Fabric,与上一代产品相比有了显著的改进。MI200 系列为 AMD Instinct™ MI8(或 MI2X)加速器上的 GPU P250P 或 I/O 提供多达 250 个外部无限结构™链路,提供高达 800 GB/s 的总理论带宽,提供高达 235% 的 GPU P2P(或 I/O)理论带宽性能,是上一代产品 (3)。
结论
如今,AMD 使用我们当前的 EPYC(霄龙)和本能处理器和加速器为一些最高效的超级计算机提供支持。Green500 是超级计算机的行业排名,每年两次通过测量每瓦性能按能效排名。AMD 在最新的 2 年 7 月 Green2023 名单上保持着 #500 到 #<> 的位置,这证明了 AMD CPU 和 GPU 技术不仅提供了一些最强大的超级计算机,而且还提供了名单上一些最节能的超级计算机。
为了推动Zetascale的未来计算里程碑,需要围绕架构、内存和互连进行更高水平的思考,这些架构、内存和互连相结合,以加速系统级改进。AMD 已经迈出了第一步,将关键部分组合成一个新的加速器,其中包括最好的 AMD EPYC(霄龙)™ CPU 和 AMD 本能™加速器,旨在实现比之前的 MI250 设计更高的代际效率和性能提升。这款名为 MI300 的全新 AMD Instinct 加速器将成为全球首款结合 CPU + GPU + 共享 HBM 的集成数据中心 APU,并提供突破性的架构,为未来的百万兆次级 AI 和 HPC 超级计算机提供动力。正是 MI300 上的单片集成利用了刚才讨论的所有方法,实现了比之前的 MI250 设计更大的代际效率提升。
总之,长期提高计算机能效对于降低运营成本和推进高性能计算机、超级计算机和数据中心的可持续发展目标非常重要。AMD Instinct 团队致力于解决设备和系统级别的每瓦性能问题,从而提高计算效率并推进数据中心对 HPC 和 AI 的可持续性。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
10876浏览量
212121 -
加速器
+关注
关注
2文章
802浏览量
37928 -
服务器
+关注
关注
12文章
9222浏览量
85603
发布评论请先 登录
相关推荐
玩游戏能减少延时,超级QQ登陆IP隐藏软件 智雨网络加速器
由采购员提升到采购工程师的四大诀窍
把可持续性运营放在最前线
如何进行电流检测放大器使用,以达到电压提升到可用水平?
使用AMD-Xilinx FPGA设计一个AI加速器通道
英飞凌稳居全球最具可持续性公司行列 再度入选《可持续性年鉴》
手机 UL 110 可持续性标准认证被 EPEAT 认证系统采用
利用以下八个开源AI技术,你的机器学习项目可提升到新水平
欧司朗的Oslon为新概念提升了HX 将驾驶员辅助系统提升到一个新的水平
如何利用物联网将工业自动化提升到新的水平
AMD宣布推出全新AMD Instinct MI200系列加速器







 工商网监
工商网监
评论