 单张图像超分辨率和立体图像超分辨率的相关工作
单张图像超分辨率和立体图像超分辨率的相关工作
多阶段策略在图像修复任务中被广泛应用,虽然基于Transformer的方法在单图像超分辨率任务中表现出高效率,但在立体超分辨率任务中尚未展现出CNN-based方法的显著优势。这可以归因于两个关键因素:首先,当前单图像超分辨率Transformer在该过程中无法利用互补的立体信息;其次,Transformer的性能通常依赖于足够的数据,在常见的立体图像超分辨率算法中缺乏这些数据。为了解决这些问题,作者提出了一种混合Transformer和CNN注意力网络(HTCAN),它利用基于Transformer的网络进行单图像增强和基于CNN的网络进行立体信息融合。此外,作者采用了多块训练策略和更大的窗口尺寸,以激活更多的输入像素进行超分辨率。作者还重新审视了其他高级技术,如数据增强、数据集成和模型集成,以减少过拟合和数据偏差。最后,作者的方法在NTIRE 2023立体图像超分辨率挑战的Track 1中获得了23.90dB的分数,并成为优胜者。
1 前言
立体图像超分辨的最终性能取决于每个视图的特征提取能力和立体信息交换能力。相比于卷积神经网络,变换器拥有更大的感受野和自我关注机制,可以更好地模拟长期依赖。但是,其内存和计算成本通常要高得多。因此,作者提出了一种混合架构,利用了变换器的强大长期依赖建模能力和卷积神经网络的信息交换的有效性。在作者的方法中,作者首先使用变换器来保留重要特征,然后使用CNN方法进行信息交换。实验结果表明,该混合架构具有较好的性能。
本文有以下三个贡献:
一种混合立体图像超分辨网络。作者提出了一个统一的立体图像超分辨算法,它集成了变换器和CNN架构,其中变换器用于提取单视图图像的特征,而CNN模块用于交换来自两个视图的信息并生成最终的超分辨图像。
全面的数据增强。作者对多补丁训练策略和其他技术进行了全面研究,并将它们应用于立体图像超分辨。
新的最先进性能。作者提出的方法实现了新的最先进性能,并在立体图像超分辨挑战赛的第一轨中获得了第一名。
2 相关背景
本文这一节介绍了单张图像超分辨率和立体图像超分辨率的相关工作。针对单张图像超分辨率,研究人员一开始使用外部图像或样本数据库来生成超分辨图像,手工制作的特征依赖于先验知识/假设,并存在很多局限性。后来引入了基于CNN的方法,CNN网络通过学习局部结构模式降低了计算成本。最近,基于Transformer的方法也受到越来越多的关注,因为它删除了先前卷积模块使用的局部性先知,并允许更大的接收场。对于立体图像超分辨率,在以前的工作中,大多是从单张图像超分辨率骨干出发的,并提出了通信分支来允许左右视图之间的信息交换。然而,左右视图之间的视差通常沿着基线而大于传统卷积核的接收场。近年来,采用了与单张超分辨率类似的方法,引入了基于CNN和Transformer的方法,以修复立体图像的超分辨率。
3 方法
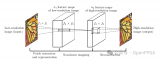
本节中,作者详细介绍所提出的混合Transformer和CNN Attention网络(HTCAN)。所提出的HTCAN是一个多阶段的恢复网络。具体而言,给定低分辨率的立体图像Llr和Rlr,作者首先使用基于Transformer的单图像超分辨率网络将其超分辨到Ls1和Rs1。在第二阶段,作者采用基于CNN的网络来增强Ls1和Rs1的立体效果,并得到增强的图像Lsr和Rsr。在第三阶段,作者使用与第2阶段相同的基于CNN的网络进行进一步的立体增强和模型集成。
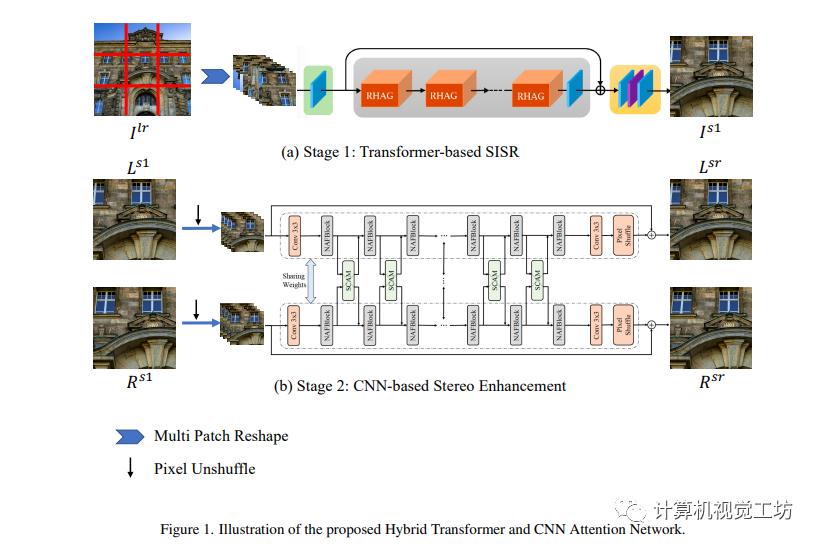
3.1 阶段1: 基于Transformer的单图像超分辨率网络结构
作者提出了一个基于Transformer和CNN Attention网络的立体图像增强网络,可以提高图像分辨率和立体效果。首先采用HAT-L作为单图像超分辨率的骨干,使用多块训练策略和级联残差混合注意力组(RHAG)进行自注意和信息聚合,最终生成高分辨率图像。同时,通过转动和翻转输入图像来实现自集成,使用SiLU激活函数替换GeLU激活函数进一步增强性能。
4.2 阶段2:基于卷积神经网络的立体增强网络架构
作者介绍了基于卷积神经网络的立体增强的第二阶段流程。该流程使用了由NAFSSR-L作为骨干网络,在提取浅层特征后,通过K2个NAF块和SCAM模块对左右图像进行跨视图信息聚合,最终输出立体增强后的图像。为了提高性能,通过自组合策略对模型进行了改进。
4.3 阶段3: 基于卷积神经网络的立体影像融合
作者介绍了一个基于卷积神经网络的立体影像融合的三阶段流程。在第三阶段中,使用第二阶段自组合的输出作为输入,提高了模型的整体性能。虽然第三阶段模型表现与第二阶段类似,但是作为一个集成模型,可以对第二阶段模型进行进一步的改进。
5 实验
5.1 实验细节
本文的实验部分训练了一个 HTCAN 网络,并对该网络进行了三个阶段的训练。在第一阶段的训练中,使用了 Charbonnier 损失和 MSE 损失,同时还使用了各种数据增强技术。在第二阶段中,我们采用 NAFSSR-L 的原始代码在 Flickr1024 图像上进行了训练,并在第二阶段训练中使用 UnshuffleNAFSSR 模型的预训练模型。最后,在第三阶段的训练中,采用与第二阶段相同的设置,将网络进行了微调。我们的方法在 Flickr1024 测试集上进行了评估,并通过与其他单幅图像和立体图像超分辨率方法的比较来证明其有效性。
5.2 实验结果
本文的实验结果显示,与其他状态-艺术单幅图像超分辨率方法和立体图像超分辨率方法相比,作者的方法在多数测试数据集上表现更好。此外,作者的方法在视觉效果上也表现出众,能够显著地恢复图像的细节和纹理。
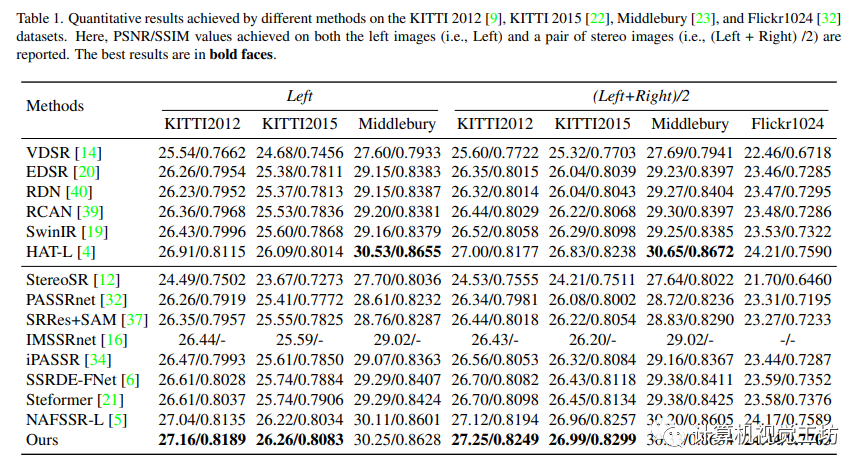
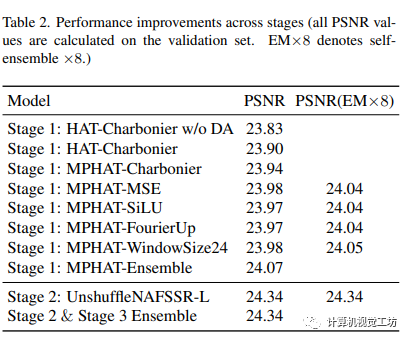
5.3 实验分析
本文介绍了一种基于多块训练、数据增强和自我集成的立体图像超分辨率方法,并引入了基于CNN的立体增强模块来进一步提高性能。实验表明这种方法可以有效地恢复图像纹理和细节。其中,采用较大的接受域和窗口大小,以及自我集成策略可以进一步提高性能。本文提出的多阶段方法将基于Transformer的SISR方法和基于CNN的立体增强方法相结合,进一步恢复了细节。


7 总结
本文介绍了混合Transformers和CNN注意力网络(HTCAN),采用两阶段方法使用基于Transformers的SISR模块和基于CNN的立体增强模块来超分辨低分辨率立体图像。作者提出的多补丁训练策略和大窗口大小增加了SISR阶段激活的输入像素数量,使结果相较于原始的HAT-L架构有0.05dB的收益。此外,作者的方法采用先进的技术,包括数据增强,数据集成和模型集成,以在测试集上实现23.90dB的PSNR并赢得立体图像超分辨率挑战赛第一名。
-
数据
+关注
关注
8文章
6786浏览量
88705 -
变换器
+关注
关注
17文章
2082浏览量
109052 -
Transformer
+关注
关注
0文章
138浏览量
5966
原文标题:CVPR2023 I 混合Transformers和CNN的注意力网络用于立体图像超分辨率
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
新手关于图像超分辨率的问题~
序列图像超分辨率重建算法研究


序列图像超分辨率重建
CVPR2020 | 即插即用!将双边超分辨率用于语义分割网络,提升图像分辨率的有效策略

基于目标检测的海上舰船图像超分辨率研究
基于CNN的图像超分辨率示例





 工商网监
工商网监
评论