 谷歌教你用"注意力"提升产品体验
谷歌教你用"注意力"提升产品体验

【导读】让用户在体验过程中关注主要部分,得先抓住用户的眼球。
人每时每刻都在接收海量的信息,例如每秒进入视网膜的数据量就达到了10的10次方比特,但人类会选择性地关注一些任务相关或感兴趣的区域以进一步处理,比如记忆、理解和采取行动等。
如何将人类的注意力进行建模,即显著性模型(saliency model)在神经科学、心理学、人机交互(HCI)和计算机视觉等领域开始得到广泛关注。
预测「哪些区域可能吸引注意力」的能力在图形、摄影、图像压缩和处理以及视觉质量测量等领域具有许多重要应用。
不过,使用机器学习和基于智能手机的凝视估计来加速眼动研究需要专门的硬件,每台成本高达三万美元,并不具备广泛推广的条件。
最近,谷歌的研究人员介绍了两篇相关领域的研究论文,分别发表在CVPR 2022和CVPR 2023上,主要研究了如何利用「人类注意力的预测模型」来实现更好的用户体验,例如用图像编辑操作以最大限度地减少视觉混乱、分心或伪影等问题,使用图像压缩来更快地加载网页或应用程序,并引导机器学习模型实现更直观的类人解释和模型性能。
这两篇论文主要关注图像编辑和图像压缩,并讨论了在具体应用场景下,对注意力建模的相关最新进展。
注意力引导的图像编辑
对人体注意力进行建模,通常需要把眼睛看到的图像作为输入,如自然图像或网页的屏幕截图等,并将预测的热力图作为输出。
预测得到的热力图会根据「眼球跟踪器」或「鼠标悬停/点击」等收集到的实时注意力近似值进行评估。
之前的模型大多利用手工制作的视觉线索特征,如颜色/亮度对比度、边缘和形状等,最近也有一些方法转向基于深度神经网络来自动学习判别特征,使用的模型包括卷积、递归神经网络以及视觉Transformer网络等。
谷歌在CVPR2022上发表的一篇论文中,利用深度显著性模型(deep saliency models)进行视觉逼真的编辑(visually realistic edits),可以显著改变观察者对不同图像区域的注意力。

论文链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Aberman_Deep_Saliency_Prior_for_Reducing_Visual_Distraction_CVPR_2022_paper.pdf
比如移除背景中分散注意力的物体可以降低照片中的杂乱程度,从而提高用户满意度;同样,在视频会议中,减少背景中的混乱度也可以增加对主要发言者的关注度。
为了探索哪些类型的编辑效果是可实现的,以及这些效果如何影响观众的注意力,研究人员开发了一个优化框架,以用于使用可区分的预测显著性模型来引导图像中的视觉注意力。
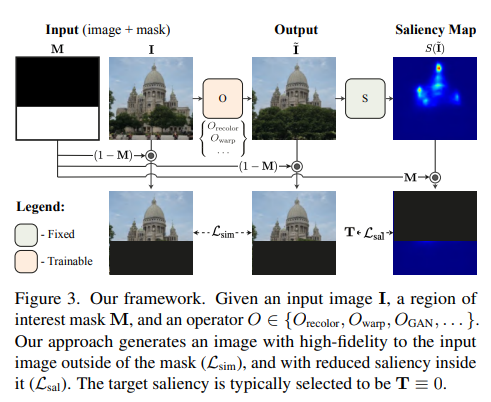
给定输入图像和表示干扰物区域的二元遮罩,使用显著性预测模型对遮罩内的像素提供指导并编辑图像,降低遮罩区域内的显著性。
为了确保编辑后的图像自然且逼真,研究人员精心选择了四种图像编辑操作符,其中包括两个标准图像编辑操作(即重新着色和图像扭曲);以及及两个可学习的操作符,即多层卷积滤波器和生成模型(GAN)。
利用这些操作符,该框架可以产生各种强大的效果,包括重新着色、修复、伪装、对象编辑、插入以及面部属性编辑,并且所有这些效果都是由单个预训练的显着性模型驱动的,没有任何额外的监督或训练。
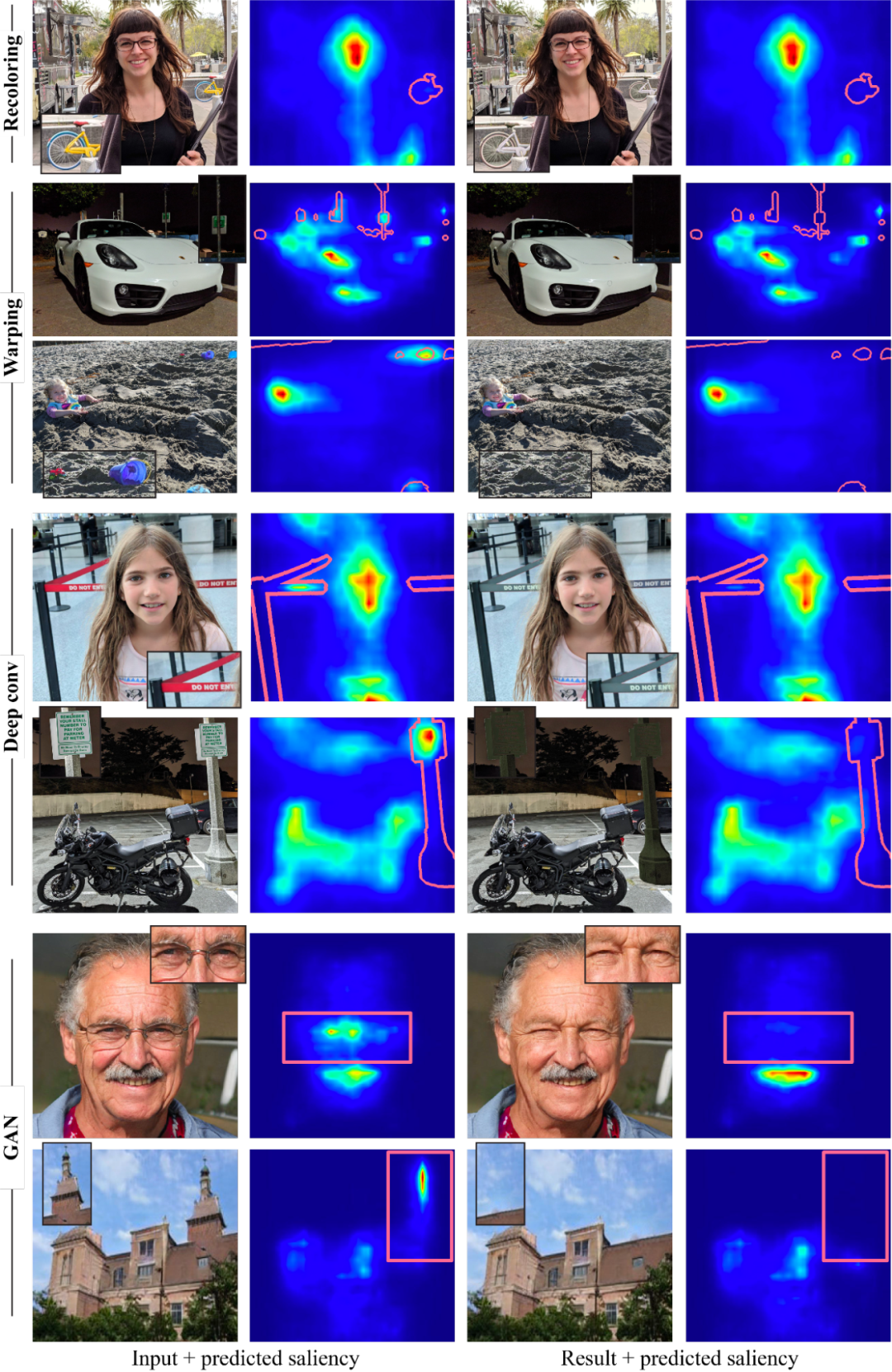
减少视觉干扰的例子,由显著性模型与几个操作符引导,干扰物区域被标记在显著性图(红色边框)的顶部
需要注意的是,研究人员的目标不是与产生每种效果的专用方法竞争,只是演示如何通过嵌入在深度显著性模型中的知识来指导多个编辑操作。
个性化的显著性建模
之前的研究假定单个显著性模型即可完成对全部人群的预测任务,不过人类的注意力在个体之间是不同的:虽然对显著线索的检测是一致的,但具体的顺序、解释和注视分布可以有很大的区别,这一问题也提供了为个人或团体创建个性化用户体验的机会。
在CVPR2023的一篇论文中,谷歌的研究人员引入了一个用户感知的显著性模型,也是首个仅用单模型就可以完成预测某个用户、一组用户和通用人群注意力的框架。

论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Chen_Learning_From_Unique_Perspectives_User-Aware_Saliency_Modeling_CVPR_2023_paper.pdf
该框架的核心是将每个参与者的视觉偏好与每个用户的注意力热力图和自适应用户遮罩进行组合,需要每个用户的注意力标注在训练过程中都是可用的,可用的数据集包括用于自然图像的OSIE移动的凝视数据集、网页的FiWI和WebSaliency数据集。
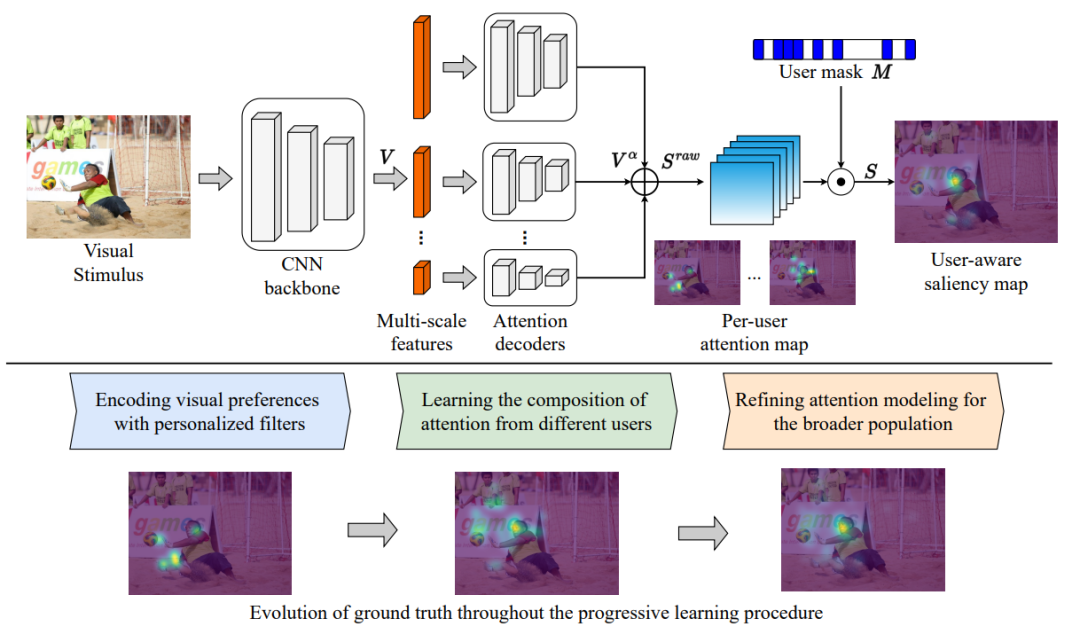
该模型并没有预测表示所有用户的注意力的单个显著性热力图,而是预测每个用户的注意力图以编码个体的注意力模式。
此外,该模型采用用户掩码(大小等于参与者数量的二进制向量)来指示当前样本中参与者的存在,使得模型可以选择一组参与者,并将偏好组合成单个热力图。
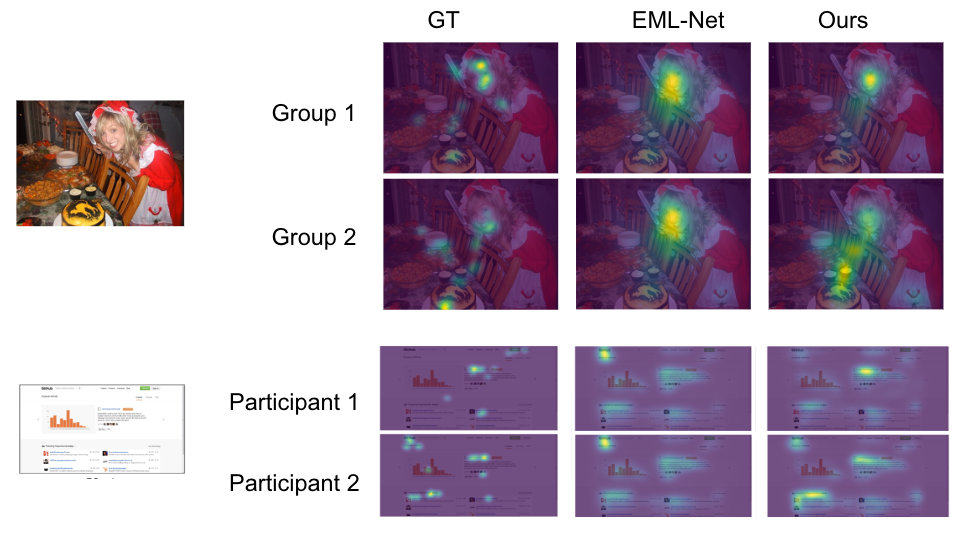
预测注意力与GT值,EML-Net是最先进模型的预测,对于两个参与者/组具有相同的预测;Ours提出的用户感知显著性模型的预测,可以正确预测每个参与者/组的独特偏好。第一个图像来自OSIE图像集,第二个图像来自FiWI。
以显著特征为中心的渐进式图像解码
除了图像编辑,人类注意力模型也可以改善用户的浏览体验。
在上网时,最让人感到不舒服的用户体验之一就是等待加载带有图像的网页,特别是在网速很慢的情况下,一种改善用户体验的方式是图像的渐进式解码,可以随着数据逐渐下载再解码,并显示越来越高分辨率的图像,直到全分辨率图像准备就绪。
渐进式解码通常按顺序进行(例如,从左到右、从上到下),使用预测注意力模型,就可以基于显著性对图像进行解码,从而可以首先发送显示最显著区域的细节所需的数据。
例如,在肖像中,用于面部的字节可以优先于用于失焦背景的字节,因此用户更早地感知到更好的图像质量,并体验到显著减少的等待时间。
基于这个想法,预测注意力模型可以帮助图像压缩和更快地加载具有图像的网页,改善大型图像和流媒体/VR应用的渲染。
结论
上面两篇论文展示了人类注意力的预测模型如何通过具体的应用场景实现令人愉快的用户体验,例如图像编辑操作,可以减少用户图像或照片中的混乱、分心或伪影,以及渐进式图像解码,可以大大减少用户在图像完全渲染时的感知等待时间。
文中提出的用户感知显著性模型可以进一步为个人用户或群体个性化上述应用程序,从而实现更丰富、更独特的体验。
-
谷歌
+关注
关注
27文章
6264浏览量
112156 -
神经网络
+关注
关注
42文章
4845浏览量
108326 -
图像
+关注
关注
2文章
1097浏览量
42473
原文标题:CVPR 2023 | 谷歌教你用"注意力"提升产品体验
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
亚马逊正在公司内部大规模部署其自研AI产品"MeshClaw"
IBM发布"AI运营模式"蓝图
从"端子排丛林"到"总线拓扑":海纳A8/H8互联式温控器的嵌入式系统剖析
从"替代人力"到"智能协同":履带式巡检机器人的产业跃迁
选EtherCAT模块,别只看价格,先看"体检报告"

机械臂越复杂越&amp;quot;卡顿&amp;quot;?别让控制器拖了后腿
L3试点落地,和芯星通如何成为车企突围的&amp;quot;隐形守护者&amp;quot;?

Vishay Vitramon Touch &quot;N&quot; Tune™ MLCC套件技术分析
&quot;Access violation&quot; 错误,复位位置,重新打印
光耦合器:电子世界的 &quot;光桥梁&quot;
精密设备的&amp;quot;电力保镖&amp;quot;:优比施UPS如何守护数据与硬件安全?

Modbus RTU通讯协议:瑞银电能表的&quot;普通话&quot;指南
地热发电环网柜局放监测设备:清洁能源电网的&amp;quot;安全卫士&amp;quot;

为什么GNSS/INS组合被誉为导航界的&amp;quot;黄金搭档&amp;quot;?

人形机器人为什么要定制? ——揭秘工业场景的&quot;千面需求&quot;



评论