 利用生成式AI进行法律研究
利用生成式AI进行法律研究
概述
本论文(Hallucination is the last thing you need)主要研究的背景是利用生成式AI进行法律研究,但是目前遇到了幻觉(hallucination)问题,这种情况可能导致一些法律错误的生成,对法律行业造成影响。
过去的解决方法包括提高模型对事实的理解、使用搜索和比较算法进行事实检查以及提高模型对法律事实的理解能力等。然而,面对庞杂的法律事实,现有的模型并不理想,容易出现幻觉。
为了解决这一问题,本文提出了三个LLM模型——理解、经验和事实,将它们合成为一个组合模型。还引入了多长度分词的概念来保护关键信息资产,最终探究了现有的公开可用的法律幻觉模型,并提出两种其他解决方案——多长度标记化和垂直对齐组合模型,试图解决幻觉问题。
通过推动三个独立的LLM模型——理解、经验和事实,构成一个组合模型的方式,提高输出的准确性。
本文的方法在法律任务中取得了良好的表现,大大降低了幻觉的发生率,便于人工专业检查,恢复AI在法律行业中的声誉。
重要问题探讨
这篇文章中提到了关于生成式AI在法律研究中可能产生的幻觉问题,你是否听说过或经历过这类问题?你认为这样的错误会给司法系统带来什么影响?
答:文章中提到了一些案例,警示我们当前普遍的AI模型和技术还不能完全保证从法律事实和法律文本上准确解决问题,存在一定的幻觉错误危险。如果这些错误严重影响到司法的公正和权威性,那么很可能会导致法律体系和法律秩序的混乱。
2. 文章讨论了在生成式AI模型中使用多项式tokenization方法来防止普适性幻觉错误。您是否了解或尝试过这种方法?在这种具体情况下,tokenization是如何影响模型输出结果的呢?
答:文章中提到tokenization对于法律文本数据的处理比较特殊,在生成式AI中会受到一定的局限性。多项式tokenization是一种将单词序列转换为被分类器识别的多个序列的方法,这可以更好地控制法律文本素材的准确性和格式化,进而保证输出结果的正确性。但是,这种方法也需要更加结合实际情况再进行分解、重组,研究进行不同领域的优化。
3. 在文章中,作者提到了组合模型(Ensemble Models),这种方法可以有效降低生成式AI的幻觉错误。您怎么理解这种方法?是否有相关的实践应用例子?
答:组合模型是将多个不同输入的AI模型组合于一起,用线性加权的方式改进模型的输出效果。这种方法可以在解决法律案例中提出问题时更加细致地研究每个模型的表现,并利用其各自的优势来消除各自的限制。在实践中,类似的组合模型方法已经被广泛应用于视觉图像识别、自然语言处理等各种AI领域。
4. 您认为,文中与AI模型应用于法律研究相关的这个问题,是否应该得到更广泛的社会关注,比如在立法和监管层级方面?
答:AI模型在法律研究中应用的问题牵涉到繁琐的法律文献数据处理,需要更加权威的机构和领域专家的协助。因此,这个问题确实需要政府和专业组织关注和监管,以确定标准化的数据标注和模型评估方法。此外,随着AI技术应用范围的进一步扩大,对于监管应当适时跟进和调整。
5. 文章中提出的mutli-length tokenisation方法似乎可以为解决语言和翻译模型中的类似问题提供参考。这种思路会对其他自然语言处理(NLP)领域的AI工作产生怎样的影响呢?
答:multi-length tokenisation方法可以应用于语言和翻译模型,以正确地处理从不同角度和语境中产生的各种数据,避免混淆和错误。NLP领域在这一技术的基础上可以进一步改善关键词提取、句子结构分析、语言理解和情感分析等任务,以优化语言模型效果和可用性。
6. 文章指出了尽管高精度的AI技术在法律研究中可以起到很有帮助的作用,但是我们必须保留人类智慧、专业责任和人际沟通等方面的价值。您是否认为这种客观事实需要随着AI技术在司法体系中的应用而得到更广泛的认知和保障?
答:相信的AI的产生是基于人类的智慧和经验,其应用不应取代人类。司法领域对于道德和社会责任等方面,也需要依靠人性的底线,不能完全依赖技术术语和AI算法。因此,保留人类智慧和专业责任是司法计算的基本前提,必须与AI技术相结合,共同促进社会的发展和进步。
-
算法
+关注
关注
23文章
4637浏览量
93535 -
AI
+关注
关注
87文章
32013浏览量
270878 -
ai技术
+关注
关注
1文章
1304浏览量
24561 -
生成式AI
+关注
关注
0文章
519浏览量
574
原文标题:概述
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
MCU或MPU上生成AI算法,进行对嵌入式设备操控
AI冲入法律界,律师也开始变得更智能
GTC23 | 生成式 AI 最前沿研究和实践!请关注这场分会
在线研讨会 | 9 月 19 日,利用 GPU 加速生成式 AI 图像内容生成

利用 NVIDIA Jetson 实现生成式 AI
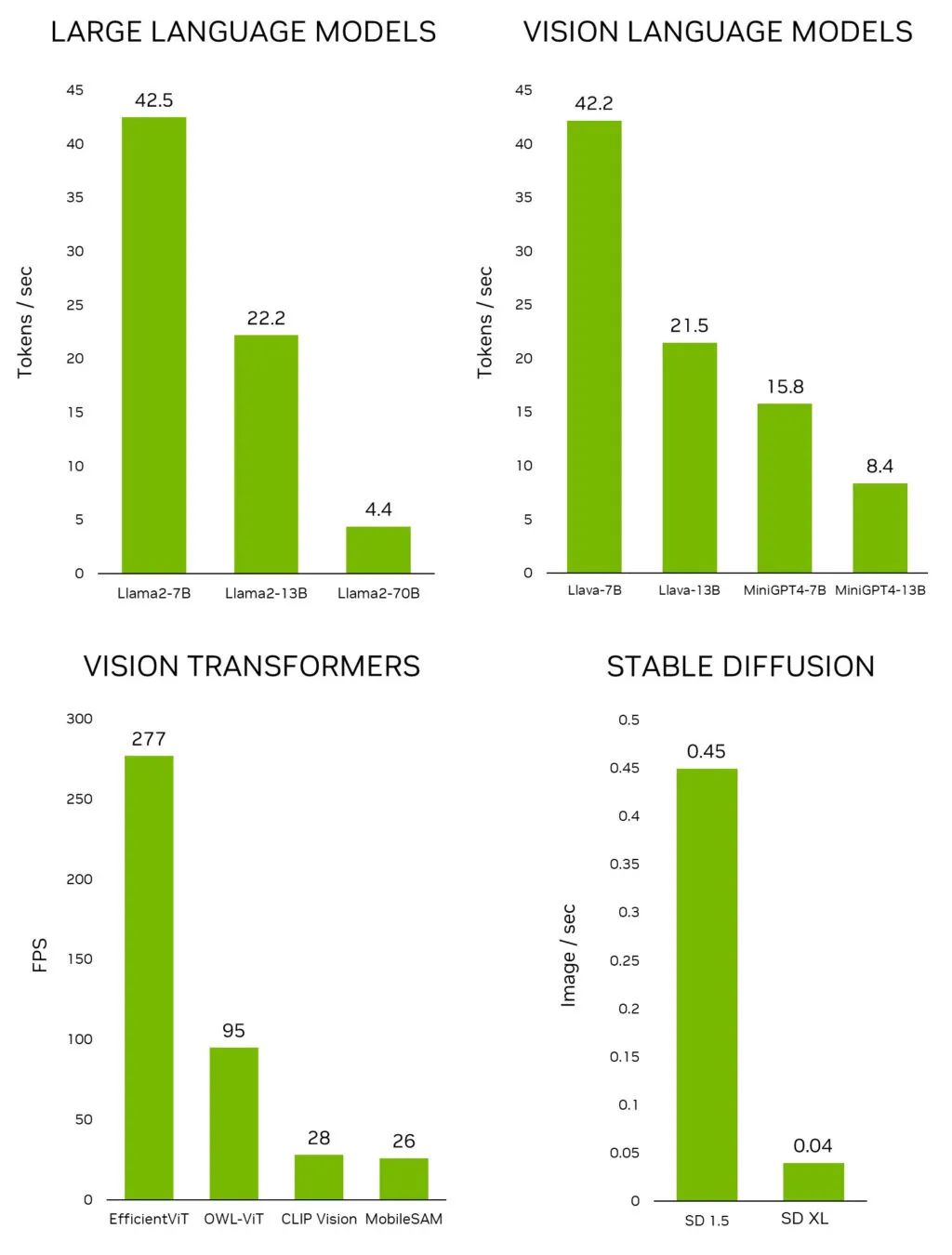
NVIDIA生成式AI研究实现在1秒内生成3D形状

Bria利用NVIDIA NeMo和Picasso为企业打造负责任的生成式AI

生成式AI的基本原理和应用领域
LexLegis.ai在印度利用人工智能推动法律研究转型,并将向全球推广






 工商网监
工商网监
评论