 将高级语义信息隐式地嵌入到检测和描述过程中来提取全局可靠的特征
将高级语义信息隐式地嵌入到检测和描述过程中来提取全局可靠的特征
介绍
以往的特征检测和匹配算法侧重于提取大量冗余的局部可靠特征,这样会导致效率和准确性有限,特别是在大规模环境中挑战性的场景,比如天气变化、季节变化、光照变化等等。
本文将高级语义信息隐式地嵌入到检测和描述过程中来提取全局可靠的特征,即他们设计了一个语义感知检测器,能够从可靠的区域(如建筑物、交通车道)检测关键点,并隐式地抑制不可靠的区域(如天空、汽车),而不是依赖于显式的语义标签。通过减少对外观变化敏感的特征数量,并避免加入额外的语义分割网络,提高了关键点匹配的准确性。此外,生成的描述符嵌入了语义信息后具有更强的鉴别能力,提供了更多的inliers。
论文实验是在Aachen DayNight和RobotCar-Seasons数据集上进行的长时大规模视觉定位测试。
出发点
目前最先进效果最好的特征检测和描述算法都是基于学习的方法,由于有大量的训练数据,这些方法能够通过聚焦于有判别性的特征,即从更可靠的区域(如建筑物、交通车道)中提取关键点,但是训练中缺少语义信息,他们选择全局可靠的关键点的能力有限,如下图所示,他们更喜欢从物体中提取局部可靠的特征,包括那些对长时定位没有帮助的特征(如天空、树、汽车),这导致精度有限。
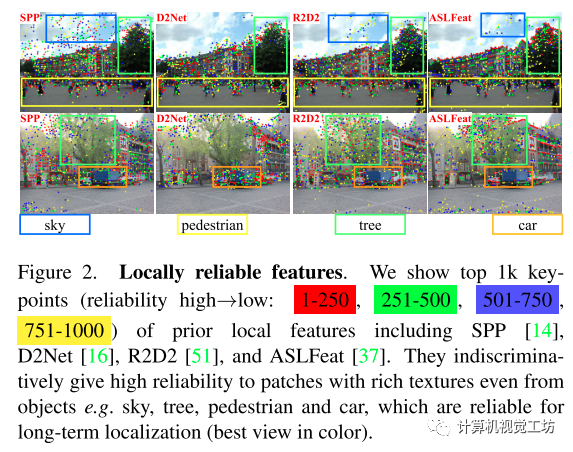 虽然也有方法融入过语义这些高层次信息,但它们需要额外的分割网络在测试时提供语义标签,并且很容易出现分割错误,本文则隐式地融入语义信息到检测和描述中去,以此提高匹配的性能,进而提升下游视觉定位的性能。
虽然也有方法融入过语义这些高层次信息,但它们需要额外的分割网络在测试时提供语义标签,并且很容易出现分割错误,本文则隐式地融入语义信息到检测和描述中去,以此提高匹配的性能,进而提升下游视觉定位的性能。
主要贡献
1.提出了一种新的特征网络,在训练时隐式地将语义融入到检测和描述过程中,使模型能够在测试时产生端到端的语义感知特征。
2.采用语义感知和特征感知相结合的引导策略来使得模型更有效地嵌入语义信息。
3.在长时定位任务上优于以往的局部特征,具有与先进匹配算法相当的精度和较高的效率。
Pipeline
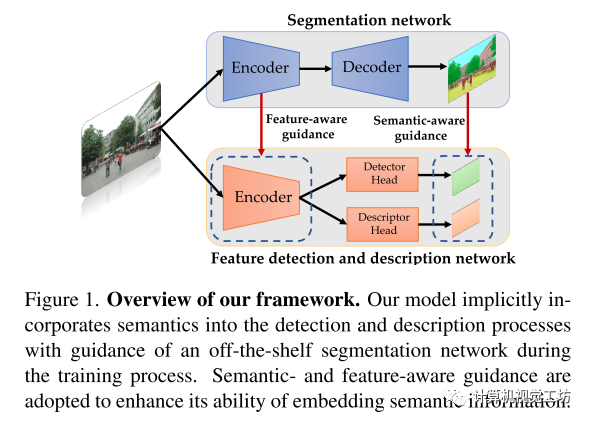
如上图所示,模型由一个编码器和两个解码器组成。一个编码器负责从图像中提取High level的特征,一个解码器预测可靠性图, 一个解码器产生描述符。
语义引导的特征检测:
特征检测器预测的可靠性图为,之前方法预测的可靠性图是由纹理的丰富度主导的。如下图所示,以往的方法只揭示了像素在局部层面的可靠性,缺乏全局层面的稳定性,本文通过考虑局部可靠性和全局稳定性来重新定义特征的可靠性。
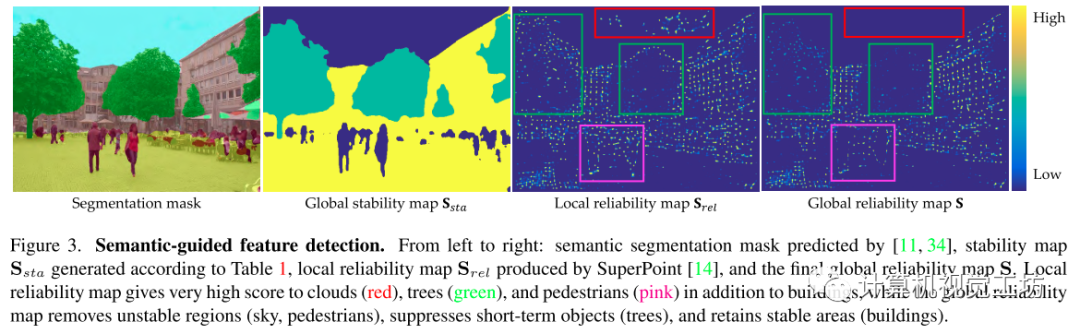
其中局部可靠性这里用super-point预测的可靠性图,全局稳定性是根据像素所属的语义标签来确定其全局稳定性。具体来说,将ADE20k数据集中的120个语义标签按照它们随时间变化的方式分为四类,分别表示为Volatile、Dynamic、Short-term和Long-term。

Volatile(如天空、水)是不断变化的,对于定位来说是多余的。
Dynamic(如汽车、行人)每天都在移动,可能会因为引入错误的匹配而导致定位错误。
Short-term(如树)可以用于短期定位任务(如VO/SLAM),但它们对光照(低反照率)和季节条件的变化很敏感。
Long-term(如建筑、交通灯)不受上述变化的影响,是长时定位的理想对象。
而且他们没有直接过滤不稳定的特征,而是根据期望的抑制程度,根据经验分配的稳定性值对特征重新排序。其中,Long-term对象对于短期和长期定位都是鲁棒的,因此将其稳定性值设置为1.0,Short-term对于短期定位很有用,将其稳定性设置为0.5。Volatile和Dynamic类别的稳定性值被设置为0.1,因为它们对于短期/长期定位都没有用处。重新排序策略鼓励模型优先使用稳定的特征,当发现不稳定的关键点时,使用来自其他对象的关键点作为补偿,增加了模型对各种任务的鲁棒性(如特征匹配、短期定位)。
然后将局部可靠性图与全局稳定性图相乘得到全局可靠性图。
语义引导的特征描述:
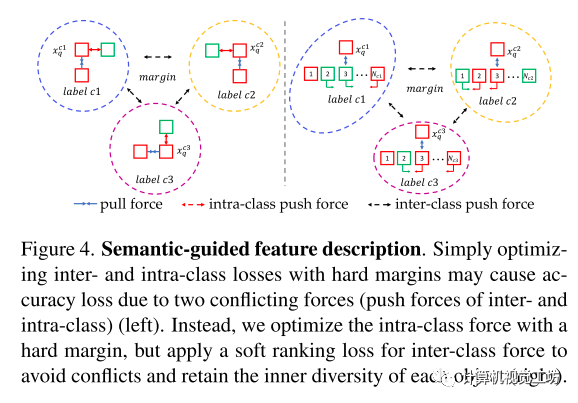
通过在描述符中嵌入语义来增强它们的区分能力。与之前的描述符仅根据局部patch信息区分关键点不同的是,本文的描述符加强了同一类特征的相似性,同时保留了类内匹配的不相似性。但在训练过程中,这两种力量相互冲突,因为类间判别能力需要挤压同一类中描述符的空间,而类内判别能力需要增加空间。
为了解决这个问题,本文基于两种不同的度量设计里类间损失和类内损失。
类间损失:先通过最大化不同标签描述符之间的欧几里德距离来增强特征的语义一致性。这使得特征可以从具有相同标签的候选对象中找到对应,减少了搜索空间,从而提高了匹配的准确性。定义了基于三态损失的类间损失,该损失具有硬边距,用于将一批不同标签的所有可能的正负关键点分离开来。
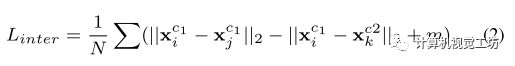
类内损失:为了确保类内损失不会与类间损失冲突,放宽了具有相同标签的描述符之间距离的限制。采用了软排序损失,而不是使用硬边的三重损失,通过优化正样本和负样本的排序而不是它们的距离。通过对所有样本的排序进行优化,而不是像带硬边缘的三态损失那样在正负对之间强制设置硬边界,软排序损失也保持了同一类对象上特征的多样性。
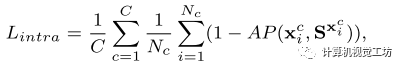
最终的损失为:
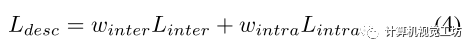
实验
在Aachen (v1.0和v1.1)和RobotCar-Seasons数据集上测试了各种光照、季节和天气条件下的方法。
Aachen v1.0包含了在亚琛城市周围捕获的4328张参考图片和922张(824天,98夜)查询图片。
Aachen v1.1对v1.0进行了扩展,添加了2369张参考图片和93张夜间查询图片。
RobotCar-Seasons有26121个参考图像和11934个查询图像,由于郊区白天(雨、雪、黄昏、冬季)查询图像的条件多样,夜间查询图像的光照条件较差,因此具有一定的挑战性。
采用错误阈值(2◦,0.25m),(5◦,0.5m),(10◦,5m)的成功率作为度量。
baseline:
基线包括经典的方法(C),如AS v1.1、CSL和CPF以及使用语义的方法(S),如LLN、SMC、SSM、DASGIL、ToDayGAN和LBR。
还与学习的特征和稀疏/密集匹配器(M)进行了比较,例如,Superglue (SPG) , SGMNet , ClusterGNN和ASpanFormer , LoFTER , Patch2Pix , Dual-RCNet。
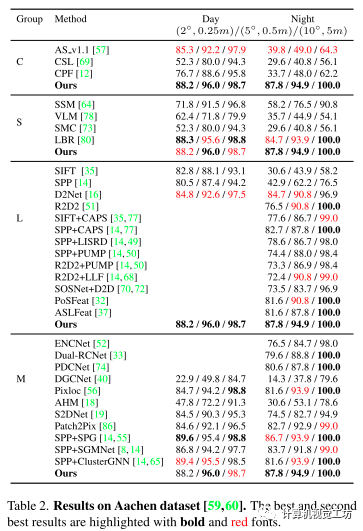
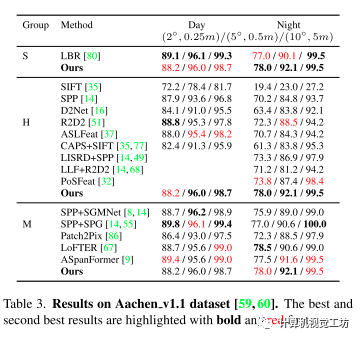
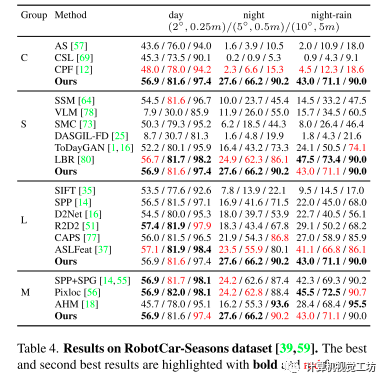
可以看出其方法在定位下游任务和最先进的方法表现持平或超过。
匹配定性结果:

运行时间比较:

其方法可以说是又快又准了!
-
编码器
+关注
关注
45文章
3679浏览量
135395 -
检测器
+关注
关注
1文章
871浏览量
47809 -
数据
+关注
关注
8文章
7193浏览量
89817
原文标题:CVPR 2023 | 融入语义的特征检测和描述,更快更准!
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于OWL属性特征的语义检索研究
模拟电路故障诊断中的特征提取方法
基于TICA和GMM的视频语义概念检测算法

如何提取和检测视频中的文字?数字视频中文字的检测提取技术的分析
高斯过程隐变量模型及相关实践
结合双目图像的深度信息跨层次特征的语义分割模型






 工商网监
工商网监
评论