 构建一个移动端友好的SAM方案MobileSAM
构建一个移动端友好的SAM方案MobileSAM
导读
本文提出一种"解耦蒸馏"方案对SAM的ViT-H解码器进行蒸馏,同时所得轻量级编码器可与SAM的解码器"无缝兼容"。在推理速度方面,MobileSAM处理一张图像仅需10ms,比FastSAM的处理速度快4倍。
SAM(Segment Anything Model)是一种提示词引导感兴趣目标分割的视觉基础模型。自提出之日起,SAM引爆了CV社区,也衍生出了大量相关的应用(如检测万物、抠取万物等等),但是受限于计算量问题,这些应用难以用在移动端。
本文旨在将SAM的"重量级"解码器替换为"轻量级"以使其可在移动端部署应用。为达成该目标,本文提出一种"解耦蒸馏"方案对SAM的ViT-H解码器进行蒸馏,同时所得轻量级编码器可与SAM的解码器"无缝兼容" 。此外,所提方案,只需一个GPU不到一天时间即可完成训练,比SAM小60倍且性能相当,所得模型称之为MobileSAM。在推理速度方面,MobileSAM处理一张图像仅需10ms(8ms@Encoder,2ms@Decoder),比FastSAM的处理速度快4倍,这就使得MobileSAM非常适合于移动应用。
SAM
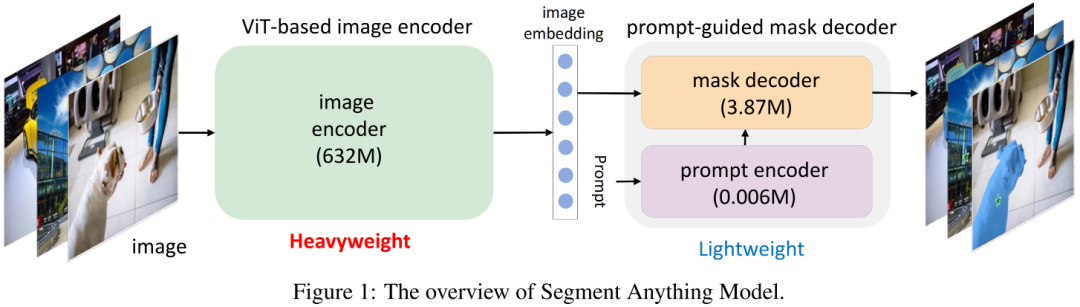
上图给出了SAM架构示意图,它包含一个"重量级"ViT编码器与一个提示词引导Mask解码器。解码器以图像作为输入,输出将被送入Mask解码器的隐特征(embedding);Mask解码器将基于提示词(如point、bbox)生成用于目标分割的Mask。此外,SAM可以对同一个提示词生成多个Mask以缓解"模棱两可"问题。更多关于SAM及衍生技术可参考文末推荐阅读材料。

延续SAM架构体系:采用轻量级ViT解码器生成隐特征,然后采用提示词引导解码器生成期望的Mask。本文目标:构建一个移动端友好的SAM方案MobileSAM,即比原生SAM更快且具有令人满意的性能。考虑到SAM不同模块之间的参数量问题,本文主要聚焦于采用更轻量型的Encoder替换SAM的重量级Encoder。
实现方案
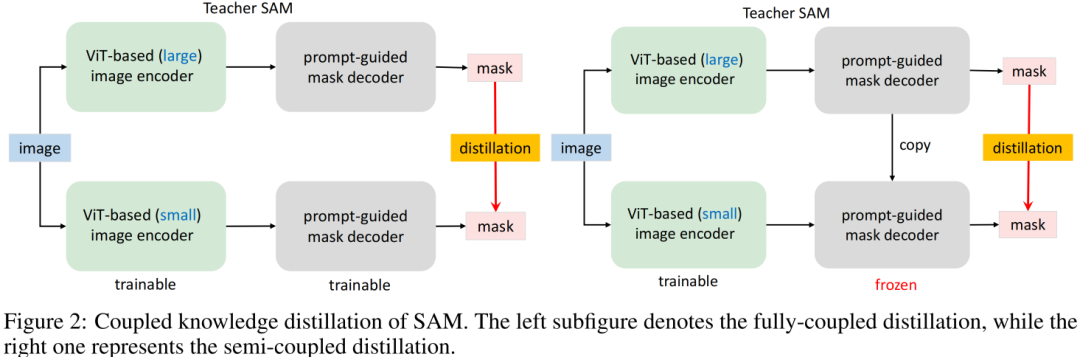
Coupled Distillation 一种最直接的方式是参考SAM方案重新训练一个具有更小Encoder的SAM,见Figure2左图。如SAM一文所提到:SAM-ViT-H的训练需要256个A100,且训练时间达68小时;哪怕Encoder为ViT-B也需要128个GPU。这样多的资源消耗无疑阻碍了研究人员进行复现或改进。此外,需要注意的是SAM所提供数据集的Mask是有预训练SAM所生成,本质上讲,重训练过程也是一种知识蒸馏过程,即讲ViT-H学习到的知识迁移到轻量级Encoder中。
Semi-coupled Distillation 当对原生SAM进行知识蒸馏时,主要困难在于: Encoder与Decoder的耦合优化,两者存在互依赖。有鉴于此,作者将整个知识蒸馏过程拆解为Encoder蒸馏+Decoder微调,该方案称之为半耦合蒸馏(Semi-coupled Distillation),见Figure2右图。也就是说,我们首先对Encoder进行知识蒸馏,然后再与Decoder进行协同微调。
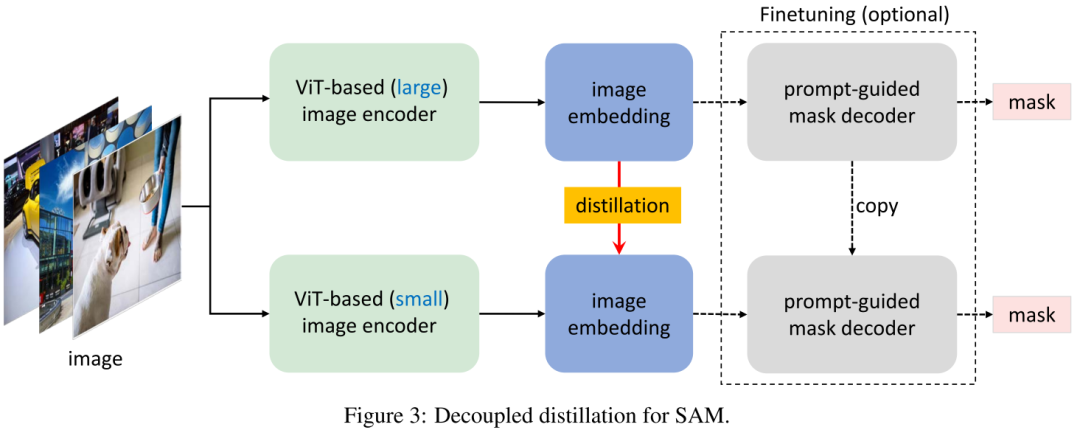
Decoupled Distillation 根据经验,我们发现这种半耦合蒸馏方案仍然极具挑战性,这是因为提示词的选择具有随机性,使得Decoder可变,进而导致优化变难。有鉴于此,作者提出直接对原生SAM的编码器进行蒸馏且无需与Decoder组合,该方案称之为解耦合蒸馏。该方案的一个优势在于:仅需使用MSE损失即可,而无需用于Mask预测的Focal与Dice组合损失。
Necessity of Mask Decoder Finetuning 不同于半耦合蒸馏,经解耦合蒸馏训练得到的轻量级Encoder可能与冻结的Decoder存在不对齐问题。根据经验,我们发现:该现象并不存在。这是因为学生Encoder生成的隐特征非常接近于原始老师Encoder生成的隐特征,因此并不需要与Decoder进行组合微调。当然,进一步的组合微调可能有助于进一步提升性能。
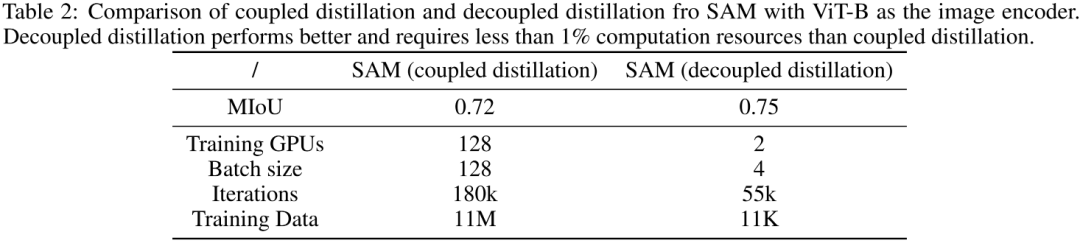
Preliminary Evaluation 上表对比了耦合蒸馏与解耦合蒸馏的初步对比。可以看到:
从指标方面,解耦合蒸馏方案指标稍高,0.75mIoU vs 0.72mIoU;
从训练GPU方面,解耦合蒸馏方案仅需两个GPU,远小于耦合蒸馏方案的128卡,大幅降低了对GPU的依赖;
从迭代次数方面,解耦合蒸馏方案仅需55k次迭代,远小于耦合蒸馏方案的180K,大幅降低了训练消耗;
从训练数据方面,解耦合蒸馏方案仅需11K数据量,远小于耦合蒸馏方案的11M,大幅降低了数据依赖。
尽管如此,但ViT-B对于移动端部署仍然非常困难。因此,后续实验主要基于TinyViT进行。
本文实验

在具体实现方面,作者基于ViT-Tiny进行本文所提方案的有效性验证,所得MobileSAM与原生SAM的参数+速度的对比可参考上表。在训练方面,仅需SA-1B的1%数据量+单卡(RTX3090),合计训练8个epoch,仅需不到一天即可完成训练。


上述两个图给出了point与bbox提示词下MobileSAM与原生SAM的结果对比,可以看到:MobileSAM可以取得令人满意的Mask预测结果。
消融实验
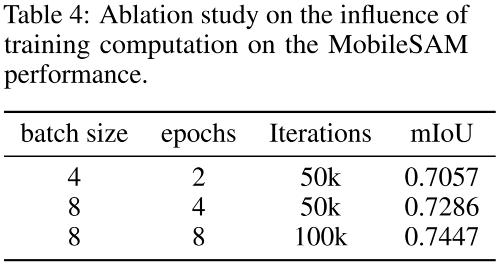
上表从训练超参bs、epoch、iter等维度进行了对比分析,可以看到:
在同等迭代次数下,提升bs可以进一步提升模型性能;
在同等bs下,提升iter可以进一步提升模型性能。

上报对比了FastSAM与MobileSAM,可以看到:
从参数量方面,MobileSAM只有不到10M的参数量,远小于FastSAM的68M;
从处理速度方面,MobileSAM仅需10ms,比FastSAM的40ms快4倍.

上图从Segment everything角度对比了SAM、FastSAM以及MobileSAM三个模型,可以看到:
MobileSAM与原生SAM结果对齐惊人的好,而FastSAM会生成一些无法满意的结果;
FastSAM通常生成非平滑的边缘,而SAM与MobileSAM并没有该问题。
最后,补充一下Segment Anything与Segment Everything之间的区别。
如SAM一文所提到,SAM通过提示词进行物体分割,也就是说,提示词的作用是指定想分割哪些物体。理论上讲,当给定合适的提示词后,任何目标都可以被分割,故称之为Segment Anything。
相反,Segment Everything本质上是物体候选框生成过程,不需要提示词。故它往往被用来验证下游任务上的zero-shot迁移能力。
总而言之,Segment Anything解决了任意物体的提示分割基础任务;Segment Everything则解决了所有物体面向下游任务的候选框生成问题。
-
编码器
+关注
关注
45文章
3585浏览量
134136 -
模型
+关注
关注
1文章
3162浏览量
48709 -
SAM
+关注
关注
0文章
112浏览量
33498
原文标题:Faster Segment Anything
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【爱芯派 Pro 开发板试用体验】+ 图像分割和填充的Demo测试
基于SAM3S4C器件被动红外参考设计
SMART SAM4C微控制器有哪些应用?
法国DREAM方案SAM5504B/SAM5704B音源芯片

中兴联手广州移动实现构建端到端的5G地铁切片
如何构建一个完整的物联网解决方案
一个利用GT-SAM的紧耦合激光雷达惯导里程计的框架

如何构建一个演示移动端应用





 工商网监
工商网监
评论