 微服务应用上/下线发布过程中存在的问题
微服务应用上/下线发布过程中存在的问题
一、微服务应用上/下线发布过程中存在的问题
在应用上下线发布过程中,如何做到流量的无损上/下线,是一个系统能保证 SLA 的关键。如果应用上下线不平滑,就会出现短时间的服务调用报错,比如连接被拒绝、请求超时、没有实例和请求异常等问题。
1.1 上线过程中的问题
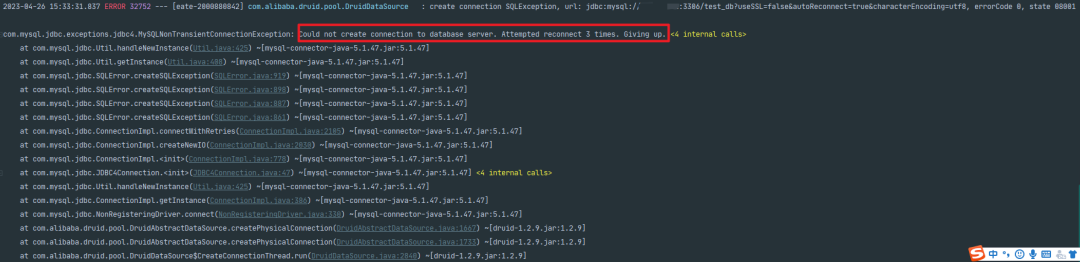
在应用上线发布过程中,由于过早暴露服务,实例可能仍处在 JVMJIT 编译或者使用的中间件还在加载,若此时大量流量进入,可能会瞬间压垮新起的服务实例。我们在实际场景中,曾经遇到 provider 服务启动后,但是数据库连接出现异常,未做好启动前的资源准备,导致该 provider 服务在注册中心暴露后 DB 异常还未修复,无法正常提供被 consumer 调用的能力,导致大量请求异常返回。如下图日志所示,应用初始化时,DB 连接失败(该服务对 DB 是弱依赖)。
1.2 下线过程中的问题
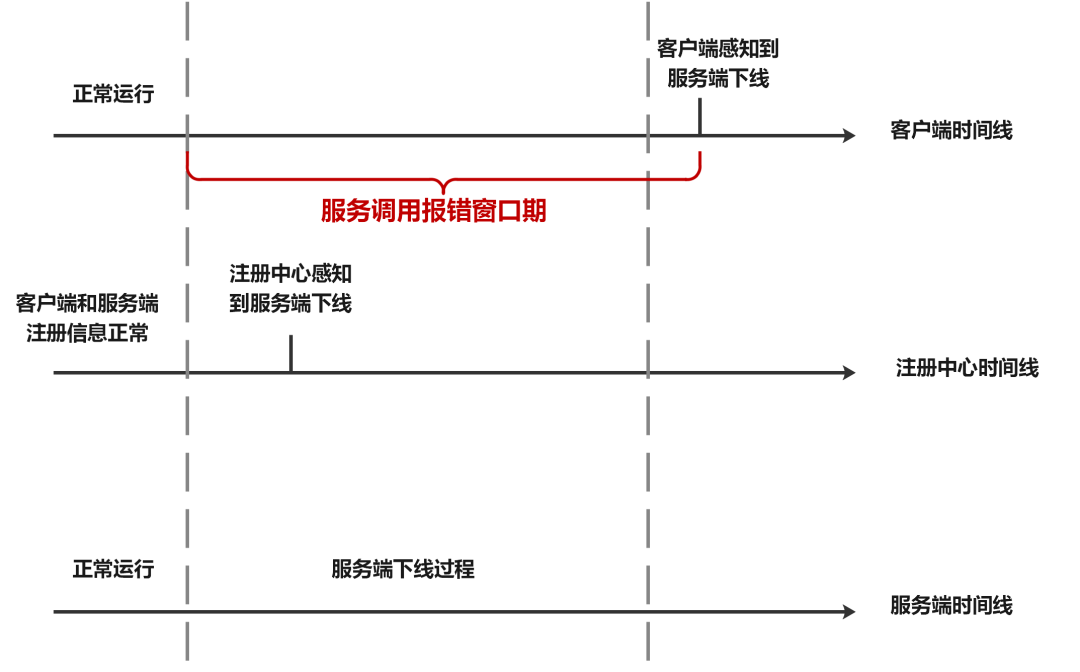
在应用下线过程中,服务消费者感知服务提供者下线有延迟,在一段时间内,被路由到已下线服务提供者实例的请求都抛连接被拒绝异常。其次服务实例在接收到 SIGKILL 信号时,会立即关闭,但是这时候可能在请求队列中存在一部分请求还在处理,如果立即关闭这些请求都会损失掉。实际应用中,我们在环境上部署了 provider 的唯一一个实例,该服务被 consumer 调用,然后再执行 kill-9强杀应用 provider 的唯一实例后,服务进程实际上已经被终止,但是服务的注册信息还会在注册中心(该场景使用的是 ServiceComb)保留一段时间,未及时清除,如下图所示。若此时消费者服务 consumer 调到该实例会报连接拒绝错误。因为消费者 consumer 服务还能发现该实例,获取其 IP 和端口尝试去调用,但是该 provider 服务实例其实已经被销毁了。
二、如何处理应用上/下线问题
那么有哪些优化措施,可以减少应用上/下线中流量的损失?
2.1 处理应用上线问题
应用上线发布主要问题是:其中一个原因是注册太早,过早的暴露了服务;另一个原因是一些应用初始化缓慢,若遇到大量流量,应用容易宕机。可以采取以下优化措施:
1.延迟注册:微服务应用可以采用延迟注册的方式,即在应用启动之后一定时间再进行注册。这样可以确保应用完全就绪后再注册,避免了服务未就绪就被外部访问的情况。
2.健康检查:微服务应用可以实现健康检查接口,通过该接口可以检查服务是否就绪。注册中心可以通过定期调用该接口来判断服务是否可以对外提供服务,从而避免了服务未就绪就被外部访问的情况。
3.预热:对新实例进行预热,而不是突然将所有流量转移到新实例上,从而避免新实例遇到大量流量,应用容易宕机的情况。
4.启动优化:对于整个服务启动的过程,可以进行一些优化措施,比如减少不必要的依赖、调整启动顺序等,从而加快服务启动速度。
2.2 应用合理的上线过程
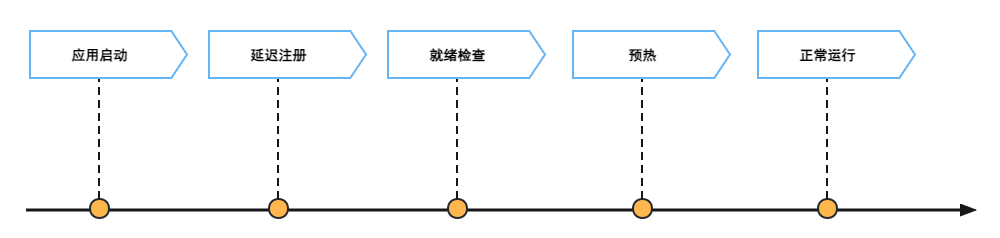
合理的应用上线大致分为这样一个过程:当应用启动后,通过设置延迟注册时间(服务对外暴露的时间)确保应用多久后可提供服务,其次可依赖平台检查服务的就绪状态(比如 K8S 的就绪探针)确保服务对外提供服务为就绪状态,然后通过预热对刚启动应用进行保护,确保流量慢慢进入刚启动的应用,最后流量逐渐增到正常情况。
2.3 处理应用下线问题
应用下线过程最主要问题是:消费者应用无法及时感知到注册中心列表的刷新,导致可能还有新流量访问下线应用。可以采取以下优化措施:
1.减少注册中心缓存时间:将注册中心中服务列表的缓存时间缩短,可以使消费者应用更快地获取到服务列表的最新信息。这样可以减少因服务列表缓存而导致的访问下线应用的流量。
2.实时性优化:在服务消费者和注册中心之间使用长连接、实时通知等机制,从而能够实时获取注册中心中服务列表的变化。
3.实现熔断机制:在消费者应用中实现熔断机制,当某个服务实例出现故障或不可用时,可以快速切换到其他可用的服务实例。这样可以避免将流量发送到已下线的应用程序上,并确保消费者应用的可用性。
2.4 应用合理的下线过程
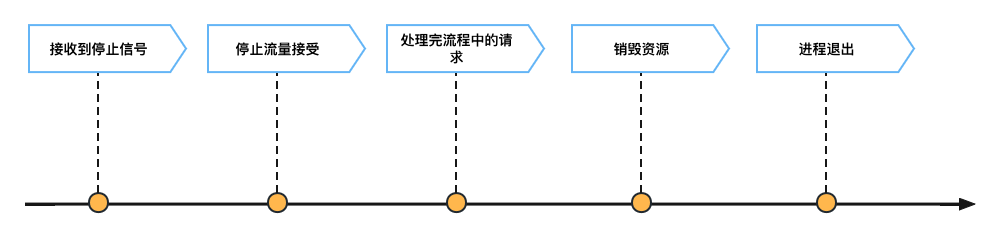
合理的应用下线大致分为这样一个过程:当应用接受到外部的关闭(停止服务)请求后,不能在接收新的业务请求,但是会存在一些正在处理的业务请求,需等这些请求处理完后再销毁应用使用的资源,最后就可以通知主进程退出。
三、应用下线注意点
针对应用下线在虚机场景和容器场景需要关注一些注意点。
3.1 虚机场景
当我们要关闭虚拟机应用时,我们一般会使用 ps-ef|grepxxx 查找到进程 ID,然后再执行 kill-9PID 操作。
kill命令使用科普:
1.kill-9,系统会发出 SIGKILL(9)信号,由操作系统内核完成杀进程操作,该信号不允许忽略和阻塞,应用程序会立即终止(强制杀死)。
2.kill-15,默认使用信号,系统向应用发送 SIGTERM(15)信号,给目标进程一个清理善后工作的机会是一种优雅终止进程的方式,告诉进程需要停止运行并开始清理资源。
因为 kill-9PID 会强制杀死应用,以合理的应用下线流程看,应需处理完相关旧业务请求,清理相关资源后再退出进程,所以当要关闭虚拟机应用时,请执行 killPID——以优雅的方式停止运行。
3.2 容器场景
Kubernetes 目前是业界容器编排领域的事实标准,业界一般默认都是用 K8S 来管理容器。K8S 提供了 Pod 优雅退出机制,允许 Pod 在退出前完成一些清理工作。preStop 会先执行完,然后 K8S 才会给 Pod 发送 TERM 信号。在容器场景利用 K8S 提供的 preStop 机制,配合延迟下线 API 使用,这样就能保证流量的无损下线。
...
spec:
-name:lifecycle-demo-container
image:nginx
lifecycle:
preStop:
exec:
command:["/bin/sh","-c","todoxxx;dosleep30;done"]
...
(1)为什么容器应用(K8S 环境)要配置 preStop?首先要介绍一下 Pod 的终止过程。
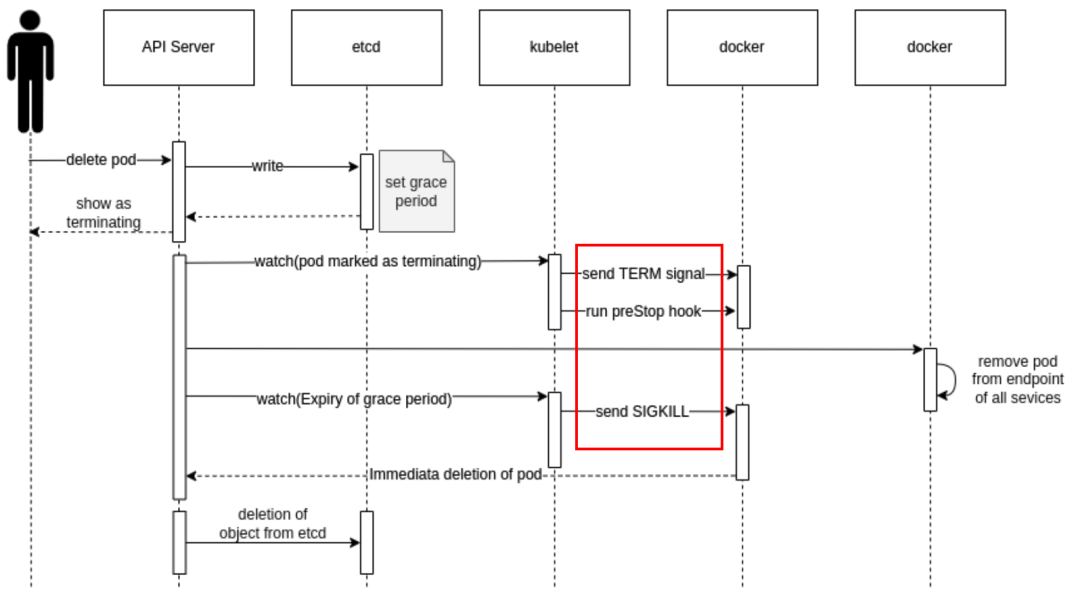
参考:https://kubernetes.renkeju.com/chapter_4/4.5.5.pod_termination_process.html
1.用户发送删除Pod对象的命令。
2.API服务器中的Pod对象会随着时间的推移而更新,在宽限期内(默认为 30 秒),Pod 被视为“dead”。
3.将Pod标记为“Terminating”状态。
4.(与第 3 步同时运行)kubelet在监控到Pod对象转为“Terminating”状态的同时启动Pod关闭程序。
5.(与第 3 步同时运行)端点控制器监控到Pod对象的关闭行为时将其从所有匹配到此端点的Service资源的端点列表中移除。
6.Pod对象中的容器进程收到TERM信号。
7.如果当前当前Pod对象定义了preStop钩子处理器,则在其标记为“Terminating”后即会以同步的方式启动执行;如若宽限期结束后,preStop仍未执行结束,则第 2 步会被重新执行并额外获取一个时长为 2 秒的小宽限期。
8.宽限期结束后,若存在任何一个仍在运行的进程,那么Pod对象即会收到SIGKILL信号。
9.kubelet请求APIServer将此Pod资源的宽限期设置为 0 从而完成删除操作,它变得对用户不在可见。
默认情况下,所有删除操作的宽限期都是 30 秒,不过,kubectldelete命令可以使用“--grace-period=”选项自定义其时长,若使用 0 值则表示直接强制删除指定的资源,不过,此时需要同时为命令使用“--force”选项。
从上述 Pod 终止过程的时序图可知,关闭 Pod 流程(关注红色框),给 Pod 内的进程发送 TERM 信号(即 kill,kill-15),如果配置了 preStop 钩子也会同时处理,最后宽限期结束后,若存在任何一个仍在运行的进程,那么 Pod 对象即会收到 SIGKILL(kill-9)信号。
(2)存在这样一种情况 Pod 中的业务进程接受不到 SIGTERM 信号
存在这样一种情况 Pod 中的业务进程接受不到 SIGTERM 信号(而且没有配置 preStop 钩子),等待一段时间业务进程直接被 SIGKILL 强制杀死了。
为什么业务进程接受不到 SIGTERM 信号?
通常都是因为容器启动入口使用了shell,比如使用了类似/bin/sh-cmy-app或/docker-entrypoint.sh这样的ENTRYPOINT或CMD,这就可能就会导致容器内的业务进程收不到 SIGTERM 信号,原因是:
1.容器主进程是 shell,业务进程是在 shell 中启动的,成为了 shell 进程的子进程。
2.shell进程默认不会处理SIGTERM信号,自己不会退出,也不会将信号传递给子进程,导致业务进程不会触发停止逻辑。
3.当等到K8S优雅停止超时时间(terminationGracePeriodSeconds,默认 30s),发送 SIGKILL 强制杀死 shell 及其子进程。
(3)如何解决上述 Pod 中的业务进程接收不到 SIGTERM 信号问题
1.配置 preStop 钩子(K8S 场景),处理退出前完成一些清理工作,比如使用无损上下线插件的应用服务需在停止前通知实例进行下线。
2.如果可以的话,尽量不使用shell启动业务进程。
3.如果一定要通过shell启动,比如在启动前需要用shell进程一些判断和处理,或者需要启动多个进程,那么就需要在shell中传递下SIGTERM信号了。
所以容器应用(K8S 环境)要配置 preStop,在停止前通知实例进行下线,加了一层防护,保证 Pod 中的业务能优雅的结束。
四、Sermant 如何解决应用上/下线问题
针对应用上下线发布过程中的问题,Sermant 插件提供预热和延迟下线机制,为应用提供无损上下线的能力。预热是无损上线的核心机制,延迟下线是无损下线的核心机制,而且为了无损上线,还做了延迟注册机制。
4.1 上线问题的解决方式

延迟注册:若服务还未完全初始化就已经注册到注册中心提供给消费者调用,很有可能因资源为加载完成导致请求报错。可以通过设置延迟注册,让服务充分初始化后再注册到注册中心对外提供服务。
预热:是基于客户端实现的,当流量进入时,Sermant 会动态调整流量,根据服务的预热配置,对流量进行动态分配。对于开启服务预热的实例,在刚启动时,相对于其他已启动的实例,分配的流量会更少,流量将以曲线方式随时间推移增加直至与其他实例近乎持平。目的是采用少流量对服务实例进行初始化,防止服务崩溃。
4.2 下线问题的解决方式
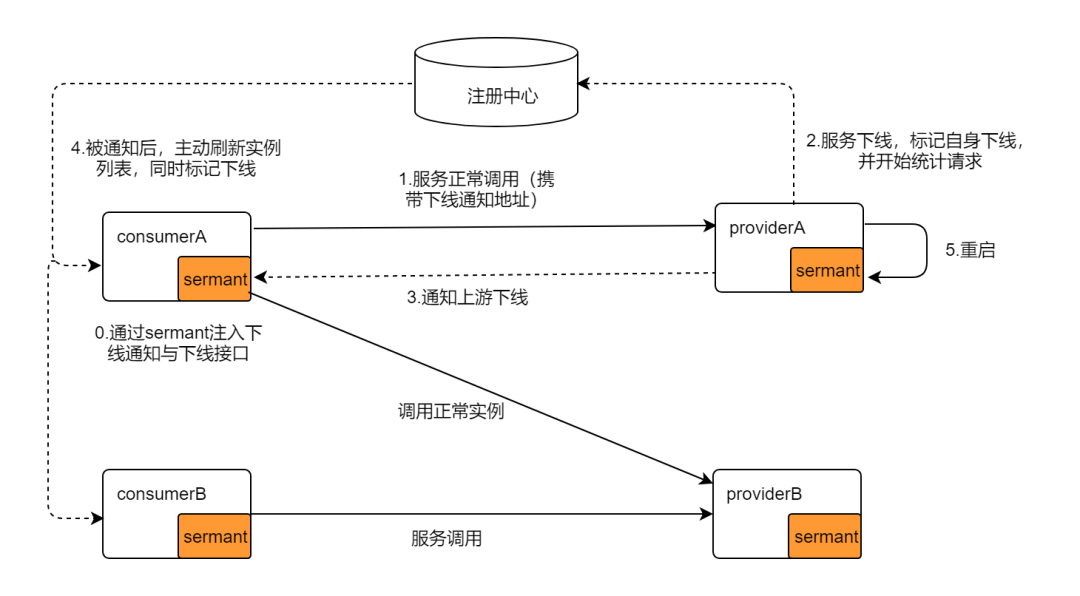
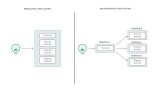
上图描述了 Sermant 是如何解决服务下线问题的:
0.微服务应用 consumerA、providerA、consumerB、providerB 携带 Sermant 启动,并将相关 ip:port 等信息注册到注册中心;
1.微服务应用 consumerA 可以正常调用 providerA 和 providerB;
2.若要重启 providerA,providerA 会标记自身将下线(通知注册中心将下线),并开始统计请求确保当前请求已全部处理完成;
3.providerA 会通知其上游应用其自身的下线信息;
4.consumerA 接受到 providerA 下线信息后,将其从缓存实例列表移除;
5.providerA 在处理完当前的所有请求后,即可重启。
总的来说,Sermant 对于服务下线的机制概括为:
延迟下线:即对下线的实例提供保护,插件基于下线实时通知+刷新缓存的机制快速更新上游的实例缓存,同时基于流量统计的方式,确保即将下线的实例尽可能的将流量处理完成,最大程度避免流量丢失。提供了延迟下线 API,方便在 K8S 环境中配置 preStop。
流量统计:为确保当前请求已全部处理完成,在服务下线时,Sermant 会尝试等待 30s(可配置),定时统计和判断当前实例请求是否均处理完成,处理完成后最终下线。
五、总结
Sermant 插件为微服务应用提供无损上下线的能力,若要下线应用,针对虚拟场景,请使用 killPID;针对容器场景(K8S 环境),请配置 preStop 钩子。
Sermant作为专注于服务治理领域的字节码增强框架,致力于提供高性能、可扩展、易接入、功能丰富的服务治理体验,并会在每个版本中做好性能、功能、体验的看护。
编辑:黄飞
-
容器
+关注
关注
0文章
494浏览量
22060 -
华为云
+关注
关注
3文章
2441浏览量
17383
发布评论请先 登录
相关推荐
使用阿里云ACM简化你的Spring Cloud微服务环境配置管理
微服务架构和CQRS架构基本概念介绍
云芯一号ARM微服务器板卡的方法和过程介绍
微服务与容器技术实践
微服务优势_微服务架构的好处与不足
什么是微服务和容器?微服务和容器的作用是什么
什么是微服务架构_微服务架构的优缺点及应用
微服务使用失败的原因有什么
springcloud微服务架构
docker微服务架构实战
设计微服务架构的原则






 工商网监
工商网监
评论