 低亮度人脸检测、附源码——CVPR2021之 Low Light Face Detection【一文读懂】
低亮度人脸检测、附源码——CVPR2021之 Low Light Face Detection【一文读懂】
声明:作为全网 AI 领域 干货最多的博主之一,❤️ 不负光阴不负卿 ❤️
10w+读者
论文基本信息【 CVPR2021 】
https://github.com/daooshee/HLA-Face-Codegithub.com/daooshee/HLA-Face-Code
HLA-Face: Joint High-Low Adaptation for Low Light Face Detectionarxiv.org/abs/2104.01984

摘要翻译
0. Abstract
微光下的人脸检测对许多实际应用来说具有挑战性,但却至关重要,例如监控视频、夜间自动驾驶。大多数现有的人脸探测器严重依赖于大量的注释,而收集数据是费时费力的。为了减少在弱光条件下建立新的数据集的负担,我们充分利用现有的正常光数据,探索如何将人脸探测器从正常光适应到弱光。这项任务的挑战在于,对于像素级和物体级来说,普通光和弱光之间的差距太大,太复杂。因此,大多数现有的低光增强和适应方法并没有达到理想的性能。为了解决这个问题,我们提出了一个联合高-低适配(HLA)框架。通过双向的低水平适应和多任务高水平适应方案,我们的HLA-Face即使没有使用黑色面孔标签进行训练,也比最先进的方法表现得更好。
1. Introduction
人脸检测是许多视觉任务的基础,已广泛应用于各种实际应用中,如智慧城市智能监控、人脸解锁、手机美容滤镜等。在过去的几十年里,大量的研究在人脸检测方面取得了很大的进展。然而,在不利光照条件下的人脸检测仍然具有挑战性。在光照不足的情况下拍摄的图像会遭受一系列的退化,例如低能见度、强烈的噪声和色彩。这些退化不仅会影响人类的视觉质量,还会使机器视觉任务的性能恶化,在监控视频分析和夜间自动驾驶中可能会产生潜在的风险。在图1 (a)中,目前最先进的人脸检测器DSFD[1]很难检测到光照不足的人脸,这与它在WIDER face[2]上超过90%的精度形成了直接对比。
为了促进微光人脸检测的研究,构建了一个大尺度基准DARK face[3]。暗脸数据的出现催生了大量的暗脸检测研究[4]。然而,现有的方法依赖于广泛的注释,因此健壮性和可伸缩性较差。
本文基于DARK FACE提供的标杆平台,探讨了如何在不需要DARK FACE标注的情况下,将普通光照人脸检测模型适应于微光场景。我们发现在正常光和弱光之间存在两级间隙。一个是像素级外观上的差距,如照明不足、相机噪音和颜色偏差。另一个是普通灯光场景和弱光场景之间的对象层次语义差异,包括但不限于路灯、汽车前照灯和广告牌的存在。传统的低光照增强方法(5、6)设计用于提高视觉质量,因此不能填补语义空白,如图1所示(b)。典型的适应方法[7,8]主要为场景设计的两个域共享相同的场景,如适应从城市多雾的城市风光[10][9]。但就我们的任务而言,领域差距更大,为适应气候变化提出了更艰巨的挑战
为了适应从正常光照到低光照,我们提出了一种高-低适应人脸检测框架(hlface)。我们考虑联合低水平和高水平的适应。具体来说,对于低水平的适应,典型的方法要么使暗图像变亮,要么使亮图像变暗。然而,由于域隙巨大,它们并没有达到理想的性能。我们不是单向的低到正常或正常到低的翻译,而是双向地使两个领域彼此走向对方。通过使弱光图像变亮,使正常光图像失真,我们建立了介于正常和弱光之间的中间状态。对于高阶自适应,我们使用多任务自监督学习来缩小低阶自适应建立的中间状态之间的特征距离。
通过结合低级和高级自适应,即使我们不使用深色人脸的标签,我们也胜过最先进的人脸检测方法。
主要工作:

墨理学AI
2. Related Works
- Low Light Enhancement.
低照度是一种常见的视觉失真,可能由不良的拍摄条件、错误的相机操作、设备故障等引起。关于低照度增强的文献很多。 直方图均衡化及其变体 [11] 扩展了图像的动态范围。 基于去雾的方法 [12] 将暗图像视为倒置的模糊图像。Retinex 理论假设图像可以分解为光照和反射。 基于 Retinex 理论,大部分作品 [5, 13] 估计光照和反射率,然后单独或同时处理每个组件。 最近的方法主要基于深度学习。 一些设计端到端的处理模型[14],而一些则注入了传统的思想,例如 Retinex 理论 [15,16,6]。 除了处理 8 位 RGB 图像外,还有用于 RAW 图像的模型 [17]。
问题是这些方法主要是为人类视觉而不是机器视觉设计的。 像素级调整如何有益于和指导高级任务尚未得到很好的探索。 在本文中,我们为深色人脸检测提供了相应的解决方案。
- Face Detection.
早期的人脸检测器依赖于手工制作的特征 [18],现在这些特征被从数据驱动的卷积神经网络中学习到的深度特征所取代。 继承通用对象检测,典型的人脸检测器可以分为两类:两阶段和一阶段。 两阶段模型 [19, 20] 首先生成区域提议,然后对其进行细化以进行最终检测。 一阶段模型 [21] 直接预测边界框和置信度。 通用对象和人脸检测之间的区别在于,在人脸检测中,尺度变化通常要大得多。 现有方法通过多尺度图像和特征金字塔 [22, 23] 或各种锚点采样和匹配策略 [24, 25, 26] 解决了这个问题。
尽管人脸检测研究蓬勃发展,但现有模型很少考虑光照不足的场景。 在本文中,我们提出了一种暗脸检测器,even without using dark annotations,其性能也优于最先进的方法。
- Dark Object Detection.
With the rapid development of deep learning, object detection has attracted more and more attention. However, few efforts have been made for dark objects. For RAW images, YOLO-in-the-Dark [27] merges models pre-trained in different domains using glue layers and a generative model. For RGB images, Loh et al. build the ExDark [28] dataset and analyze the low light images using both hand-crafted and learned features. DARK FACE [3] is a large-scale low light face dataset, giving birth to a series of dark face detectors in the UG2 Prize Challenge1 . However, most of these models highly rely on annotations, thus are of limited flexibility and robustness.
为了摆脱对标签的依赖,无监督域适应(Unsupervised Domain Adaptation, UDA)可能是一种简单的解决方案[8,29]。虽然UDA方法在许多应用中已被证明是有效的,但由于正常和微光之间的巨大差距,这些方法在黑暗人脸检测方面的性能有限。本文提出了一种结合低水平和高水平自适应的较优方法。
此处就不继续有道翻译了,了解到 该论文和代码是用于 Low Light Face Detection 任务即可

墨理学AI
环境搭建

官方readME
经测试 pytorch==1.4.0 一样可以顺利运行该代码,因此这里安装的是 pytorch 1.4.0
torch 1.6.0 运行 测试代码 则会遇到一个小的报错
cat /etc/issue
Ubuntu 18.04.5 LTS n l
conda create -n torch14 python=3.6.6
conda activate torch14
conda install pytorch==1.4.0 torchvision==0.5.0 cudatoolkit=10.0 -c pytorch
pip install opencv-python
pip install scipy
pip install thop
pip install easydict
人脸检测测试
模型准备:
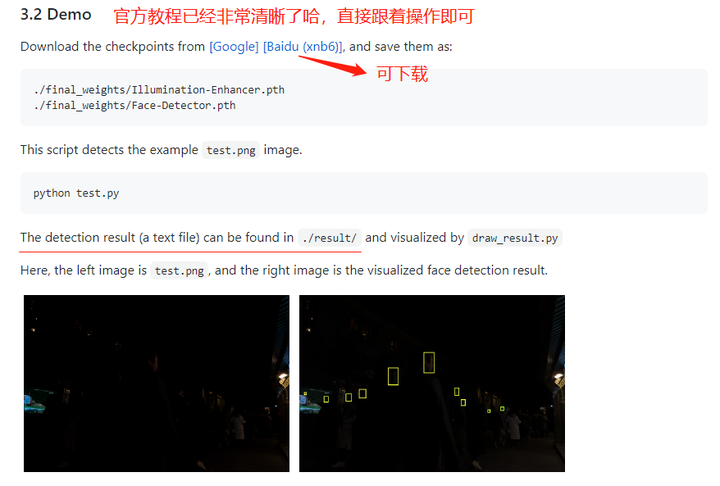
项目结构如下
测试命令如下
python test.py
# 或者指定 gpu 编号
CUDA_VISIBLE_DEVICES=3 python test.py 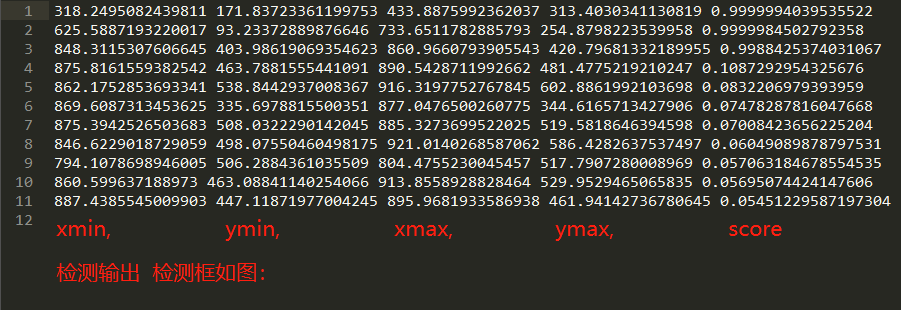
GPU 占用 7539MiB
可视化检测框
# 首先要正确设置 检测图像的 名字
vim draw_result.py +32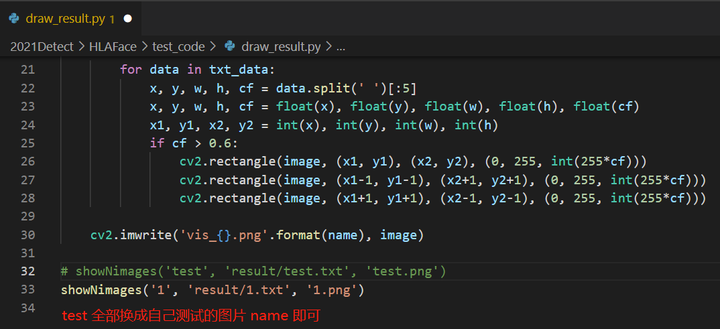
正确设置 检测图像的 名字
> 运行命令如下
python draw_result.py
- 效果如下
- 各位小伙伴,学会此文、可以换其他更有趣图片进行实验哈
可能遇到的报错:RuntimeError: CUDA out of memory
RuntimeError: CUDA out of memory. Tried to allocate 190.00 MiB (GPU 0; 15.75 GiB total capacity; 1.40 GiB already allocated; 144.31 MiB free; 1.84 GiB reserved in total by PyTorch)> 解决方法,使用一块闲置并且 超过 8G的显卡 进行测试即可
CUDA_VISIBLE_DEVICES=3 python test.py 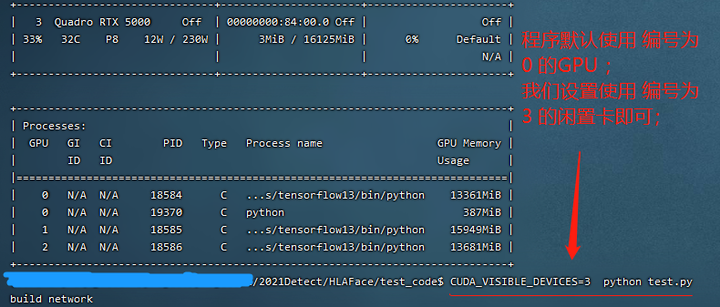
nvidia-smi
此次运行源码+模型+论文
按照此次博文环境搭建教程,即可运行成功
倘若链接失效、请评论区告知
链接:https://pan.baidu.com/s/1zt6j8uQDcj68W5U-0WYCNA
提取码:nice训练 【这里就不展开啦】
官方该代码训练文档 -- 已经足够清晰github.com/daooshee/HLA-Face-Code/tree/main/train_code
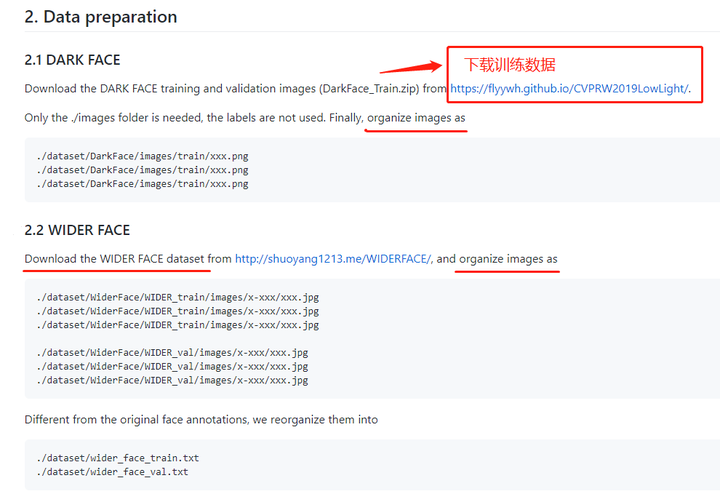
训练数据集准备

魔法加速-即可下载
❤️ 欢迎和墨理一起学AI
点赞 收藏 ⭐留言 都是博主坚持写作、更新高质量博文的最大动力!
各种技术Club : 计算机视觉、超分重建、图像修复、目标检测、模型部署等方向小伙伴可简单交流
审核编辑 黄宇
-
AI
+关注
关注
87文章
32130浏览量
271036 -
源码
+关注
关注
8文章
656浏览量
29688 -
人脸识别
+关注
关注
76文章
4025浏览量
82560
发布评论请先 登录
相关推荐
【飞腾派4G版免费试用】飞腾派SeetafaceEngine人脸检测
【飞腾派4G版免费试用】飞腾派SeetafaceEngine人脸对齐(PART2)
Firefly 百度人脸识别开发套件
【百度人脸识别开发套件】开放人脸识别APP及SDK,加速二次开发进程
opencv和face++如何进行人脸检测吗?
labview调用百度人脸识别SDK
如何使用nnstreamer-examples进行人脸识别?
人脸识别技术大总结1—Face Detection Alignment

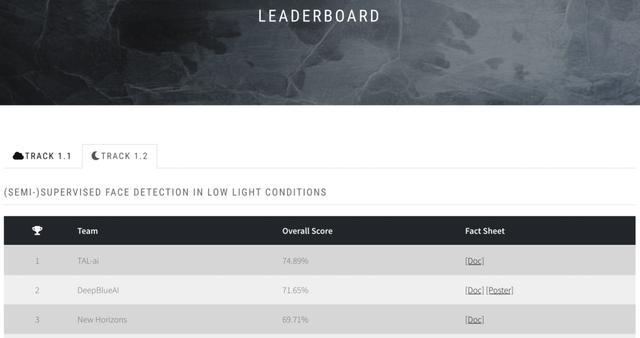
中国团队包揽CVPR 2021弱光人脸检测挑战赛前三名!高分论文已公开播





 工商网监
工商网监
评论