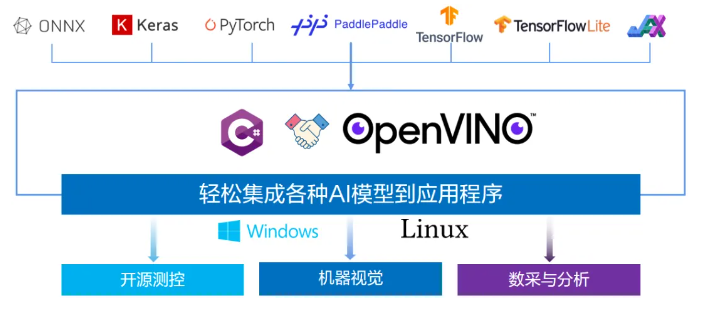
 使用OpenVINO解锁AI更轻松部署和加速的潜力
使用OpenVINO解锁AI更轻松部署和加速的潜力

OpenVINO
2023.0
最新版本来袭
随着 OpenVINO5周年纪念日的临近,我们想花点时间对您在过去五年中对OpenVINO的持续使用表示最深切的感谢。到目前为止,这是一段不可思议的旅程,我们很自豪您能成为我们社区中的一员。社区的持续支持使我们的下载量超过了 100 万次。
在我们纪念这一重要里程碑之际,我们激动地发布我们的最新版本OpenVINO2023.0,它具有一系列新的特性和功能,将使开发人员能够更轻松地部署和加速人工智能。
2023.0 版本的重点是通过最大限度地减少离线转换、扩大模型支持和推进硬件优化来改善开发者之旅。完整的发布说明可在此获得:
亮点包括:
尽量减少 AI 开发者在采用和维护代码时的代码修改并更好的与各深度学习框架保持一致
全新的 TensorFlow 体验:简化从训练到部署 TensorFlow 模型的工作流程
现在可用 Conda Forge!对于习惯使用 Conda的 C++ 开发人员来说,更容易安装 OpenVINO运行时库
更广泛的处理器支持:当前 ARM 处理器支持包括 OpenVINOCPU 推理计算,动态输入,完整的处理器性能和广泛的示例代码 Notebook 教程覆盖
扩展 Python 支持:增加了对 Python 3.11 的支持,以获得更多潜在的性能改进
在包括 NLP 在内的更多模型上轻松实现优化和部署,并通过新的硬件特性能力获得更多的 AI 加速
更广泛的模型支持:支持生成式 AI 模型、文本处理模型、Transformer 模型等
GPU 上支持动态输入:当使用 GPU 时,不需要将模型输入改为静态输入,这在编写代码时提供了更多的灵活性,特别是对于 NLP 模型
NNCF 是首选的量化工具:将训练后量化(POT)集成到神经网络压缩框架(NNCF)中,有了它,通过模型压缩,更容易获得巨大的性能提升
通过自动设备发现,负载平衡和跨 CPU, GPU等的动态推理并行,可以直接看到性能的提升
CPU 插件中的线程调度:通过在第12代英特尔酷睿 处理器及以上版本的 CPU 的能效核、性能核或能效核 + 性能核上运行推理来优化性能或能效。
默认推理精度:默认为不同的格式,以在 CPU 和 GPU 上提供最佳性能。
模型缓存扩展:减少 GPU 和 CPU 的首次推理延迟
现在,让我们深入研究一下上面介绍的一些新功能。
探索 OpenVINO 2023.0 中的新功能
全新的 TensorFlow 体验
现在,TensorFlow 开发人员可以更容易地从模型训练转移到模型部署。无需离线将 TensorFlow 或 TensorFlow Lite 格式的模型文件转换为 OpenVINO IR 格式-这会在运行时自动发生。现在,您可以开始试验 Model Optimizer,以改善有限范围模型的转换时间,或者直接在 OpenVINO Runtime 或 OpenVINOModel Server 中加载标准 TensorFlow 或 TensorFlow Lite 模型
下图显示了一个简单的示例:
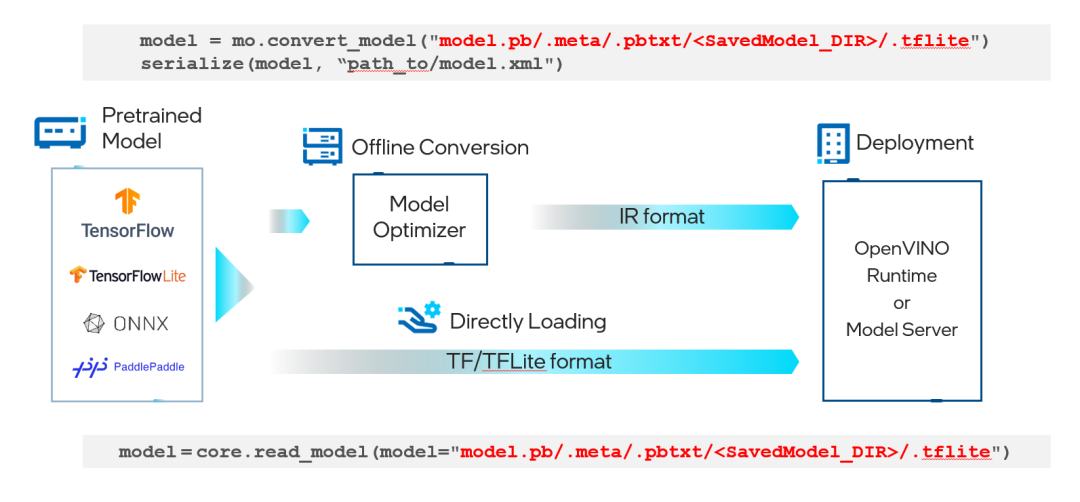
图 1. 部署 TensorFlow/TensorFlow Lite 模型的通用工作流程
更广泛的模型支持
AI 开发者可以找到更多的对生成式 AI 模型支持,例如:
CLIP
BLIP
Stable Diffusion 2.0
带 ControlNet 的 Stable Diffusion
对文本处理模型的支持,对 Transformer 模型的支持,例如,S-BERT,GPT-J 等,对 Detectron2,Paddle Slim,Segment Anything Model(SAM),YOLOv8,RNN-T 等模型的支持。
图 2. 由 stable-diffusion-2-inpainting 模型生成的无限变焦视频效果
图 3. 基于两个条件生成的图像,用 OpenPose 从输入图像提取关键点的 ControlNet 工作流程,然后作为额外条件与文本提示词一起输入到 Stable Diffusion 模型
图 4. 用 Segment Anything Model (SAM) 模型分割给定图片的一切
默认推理精度
最新的更新包括在各种设备上的推理性能的显著提高,这些设备现在默认以高性能模式运行。这意味着对于 GPU 设备,使用 FP16 推理,而 CPU 设备使用 BF16 推理(如果可用)。
关于 BF16 推理请访问:
以前,用户必须自己将 IR 转换为 FP16,才能使 GPU 在 FP16 模式下执行。现在,所有设备都可以自动选择默认推理精度,并且此选择与 IR 精度没有关系。在极少数情况下,使用默认模式可能会影响推理准确性,此时用户也可以通过接口手动调整推理精度。
此外,开发者可以单独控制 IR 精度。默认情况下,我们建议将其设置为 FP16,以便为浮点模型减少 2 倍的模型大小。值得注意的是,IR 精度并不影响设备执行模型的方式,而是通过降低权重精度来压缩模型。

图 5. 自动转换 IR 模型为默认推理精度
NNCF 作为首选的量化工具
NNCF 为 OpenVINO 中的神经网络推理优化提供了一套先进的算法,并具有最小的精度损失。它支持对 PyTorch,TensorFlow,ONNX 和 OpenVINO 模型对象进行量化 。
在这之前,OpenVINO有单独的工具用于训练后优化(POT)和量化感知训练。我们将这两种方法合并到 NNCF 中,其中提供的压缩算法如下所示,见图 6。这有助于减少模型大小、内存占用和延迟,并提高计算效率。
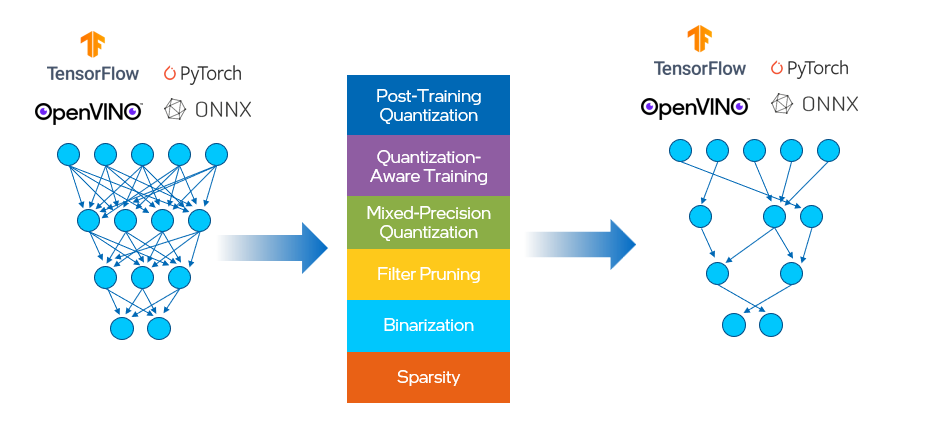
图 6. NNCF 提供的压缩算算法
训练后量化算法从代表性数据集中获取样本,并将其输入到网络中,然后根据所得的权重和激活值对网络进行校准。一旦校准完成,网络中的值就被转换为 8 位整型格式。NNCF 的基本训练后量化流程是将 8 位量化应用于模型的最简单方法:
设置环境并安装依赖项
pip install nncf
准备校准数据集
import nncf calibration_loader = torch.utils.data.DataLoader(...) def transform_fn(data_item): images, _ = data_item return images calibration_dataset = nncf.Dataset(calibration_loader, transform_fn)
向右滑动查看完整代码
运行以获取量化模型
model = ... #OpenVINO/ONNX/PyTorch/TF object quantized_model = nncf.quantize(model, calibration_dataset)
向右滑动查看完整代码
关于如何使用 NNCF 进行模型量化和压缩的教程可以在这里找到,其中我们验证了将训练后量化应用于 YOLOv5 模型,精度几乎没有下降(图7):
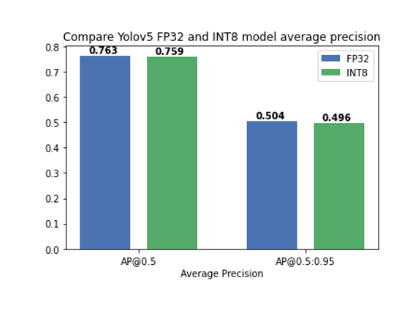
图 7. 将训练后量化应用于 YOLOv5 模型,精度几乎没有下降
CPU 插件中的线程调度
提升英特尔 平台的多线程调度。
有了新的 ov::scheduling_core_type属性,可以通过选择在 {ov::ANY_CORE, ov::PCORE_ONLY, ov::ECORE_ONLY}上运行推理来配置性能优先或能效优先,用于第12代英特尔酷睿及以上的 CPU,HYBRID 平台。
通过将ov::enable_hyper_threading属性设置为 "True",物理核和逻辑核都可以在英特尔平台的性能核上启用,因此通过这种配置带来性能提升。
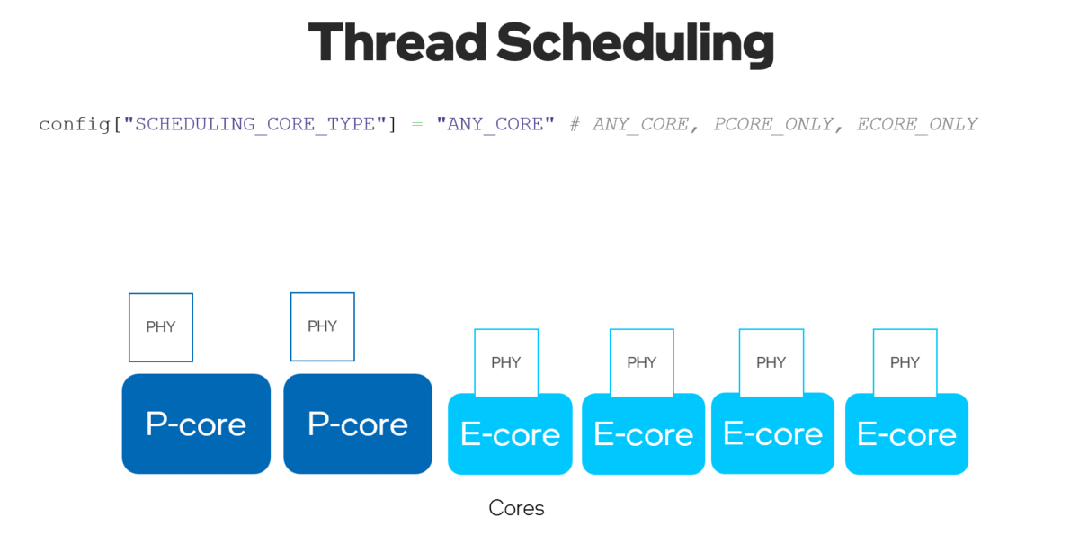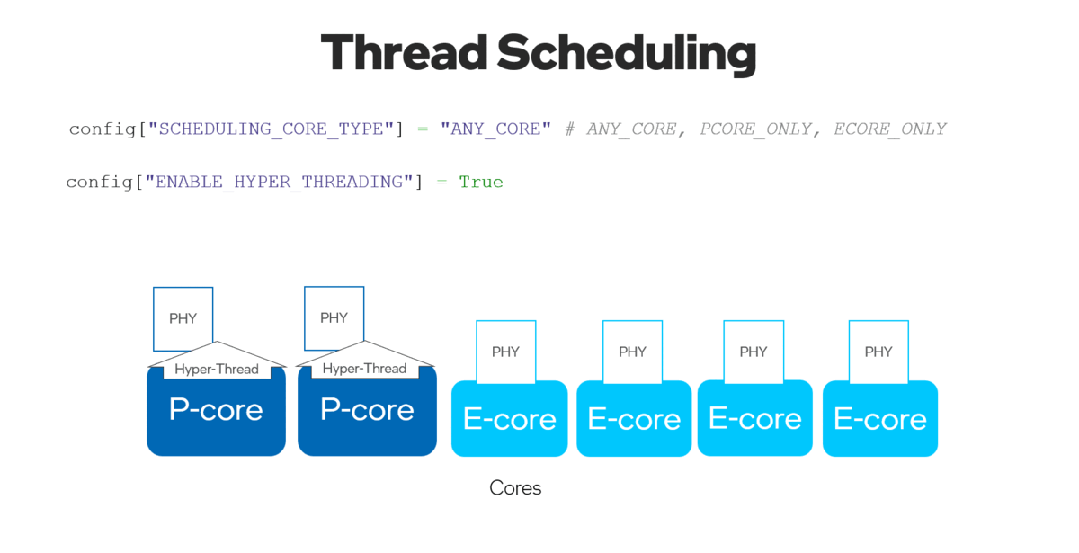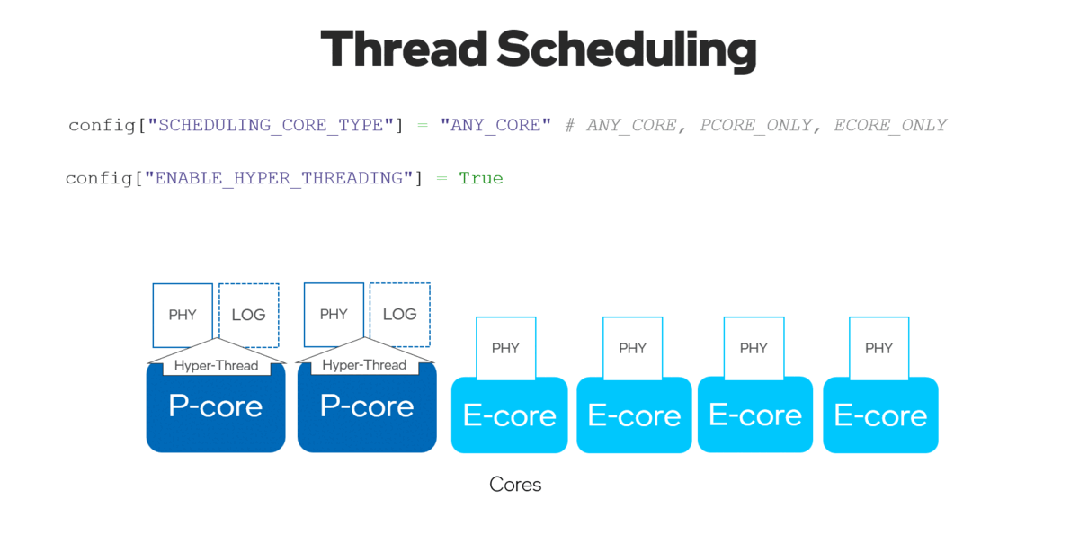
图 8. 启用 "SCHEDULING_CORE_TYPE "和 "ENABLE_HYPER_THREADING",在CPU插件中提升了多线程。
另一个新属性是 ov::enable_cpu_pinning。默认情况下,ov::enable_cpu_pinning 被设置为 “True”, 这意味着用于运行多个深度学习模型的推理请求的多个线程将由 OpenVINO运行时(TBB)调度。在这种模式下,具有多个线程的一个深度学习模型的推理将被视为一个整体图,其中每个线程将绑定到 CPU 处理器,而不会引起缓存丢失和额外的开销。但是,在同时运行两个神经网络的推理的情况下,可能在相同的 CPU 处理器上调度不同深度学习模型推理请求的多个线程,从而导致对相同处理器资源上的竞争(如图 9 所示)。
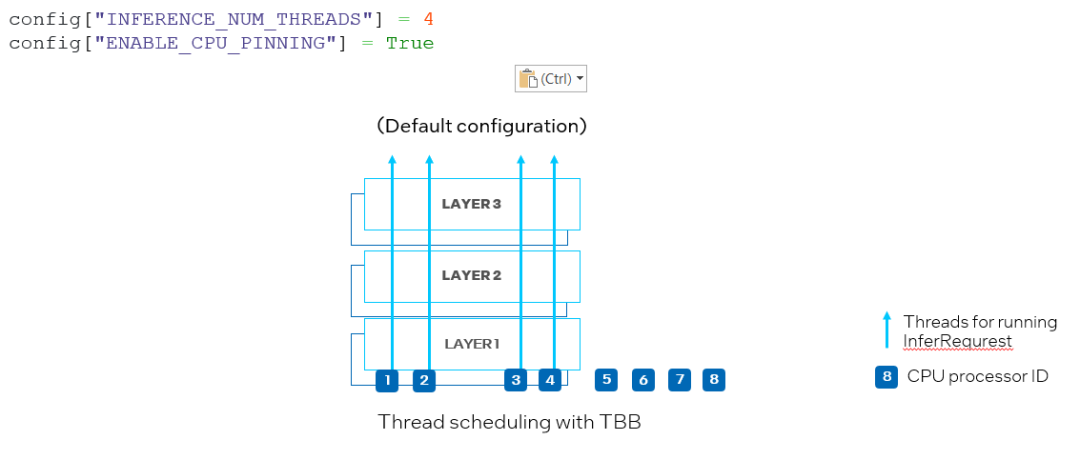
图 9. 在 CPU 插件中设置 "ENABLE_CPU_PINNING "为 "True",为多线程启用 TBB 调度
为了避免 CPU 处理器资源竞争,我们可以通过将 ov::enable_cpu_pinning 设置为 “False”来禁用处理器绑定属性,并让操作系统为神经网络的每个线程调度处理器资源。在这种模式下,同一深度学习模型不同层上的推理可能会在不同的处理器之间切换,从而导致缓存丢失和额外的开销(如图 10 所示),此时开发者可以根据实际的测试结果,选择最合适的方案进行部署。
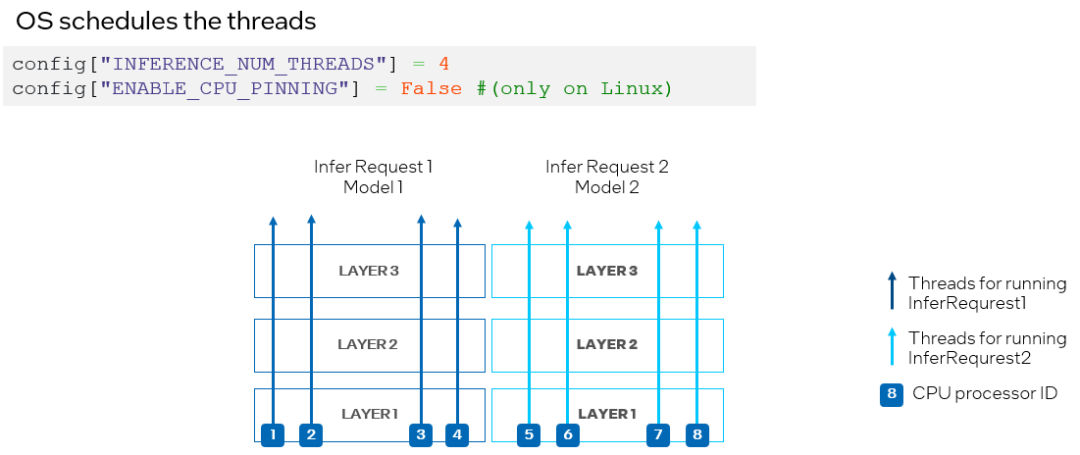
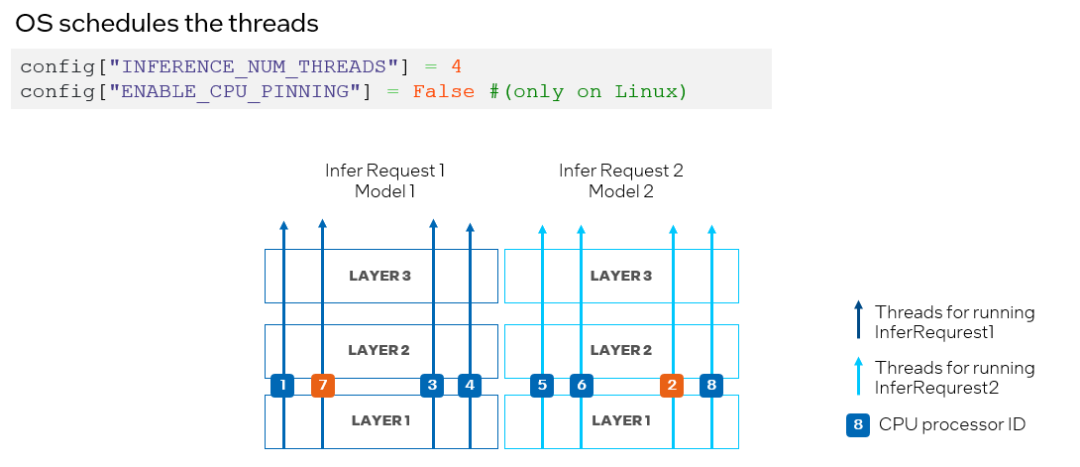
图 10. 在 CPU 插件中设置 "ENABLE_CPU_PINNING "为 "False",由操作系统调度多线程
升级到 OpenVINO 2023.0
OpenVINO从头到尾都能让您的 AI 应用发挥最大的作用。有了您的持续支持,我们可以为各地的开发人员提供有价值的升级。凭借其智能和全面的功能,OpenVINO就像在您身边有自己的性能工程师。
您可以使用以下命令升级到 OpenVINO2023.0:
但是请确保检查所有的依赖项,因为升级可能会更新 OpenVINO之外的其他包。如果您希望安装 C/ C++ API,拉取预构建的 Docker 镜像或从其他存储库下载,请访问下载页面以找到适合您的需求的包。
审核编辑:汤梓红
-
处理器
+关注
关注
68文章
20371浏览量
255554 -
英特尔
+关注
关注
61文章
10335浏览量
181289 -
AI
+关注
关注
91文章
41885浏览量
302993 -
模型
+关注
关注
1文章
3865浏览量
52325 -
python
+关注
关注
59文章
4891浏览量
90395
原文标题:使用OpenVINO™解锁 AI 更轻松部署和加速的潜力
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
C#集成OpenVINO™:简化AI模型部署

如何使用OpenVINO C++ API部署FastSAM模型
如何部署OpenVINO™工具套件应用程序?
OpenVINO加速多领域AI产业创新发展
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型

AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型

在AI爱克斯开发板上用OpenVINO™加速YOLOv8-seg实例分割模型
在AI爱克斯开发板上用OpenVINO™加速YOLOv8-seg实例分割模型
OpenVINO赋能BLIP实现视觉语言AI边缘部署
OpenVINO™ 赋能 BLIP 实现视觉语言 AI 边缘部署

基于OpenVINO Python API部署RT-DETR模型
简单三步使用OpenVINO™搞定ChatGLM3的本地部署

简单两步使用OpenVINO™搞定Qwen2的量化与部署任务

C#中使用OpenVINO™:轻松集成AI模型!



评论