 Python字符与字节
Python字符与字节
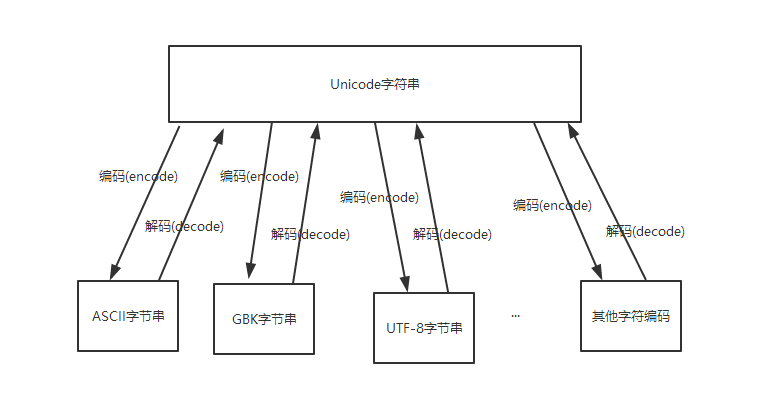
一个字符不等价于一个字节,字符是人类能够识别的符号,而这些符号要保存到计算的存储中就需要用计算机能够识别的字节来表示。一个字符往往有多种表示方法,不同的表示方法会使用不同的字节数。这里所说的不同的表示方法就是指字符编码,比如字母A-Z都可以用ASCII码表示(占用一个字节),也可以用UNICODE表示(占两个字节),还可以用UTF-8表示(占用一个字节)。字符编码的作用就是将人类可识别的字符转换为机器可识别的字节码,以及反向过程。
UNICDOE才是真正的字符串,而用ASCII、UTF-8、GBK等字符编码表示的是字节串。关于这点,我们可以在Python的官方文档中经常可以看到这样的描述"Unicode string" , " translating a Unicode string into a sequence of bytes"
我们写代码是写在文件中的,而字符是以字节形式保存在文件中的,因此当我们在文件中定义个字符串时被当做字节串也是可以理解的。但是,我们需要的是字符串,而不是字节串。一个优秀的编程语言,应该严格区分两者的关系并提供巧妙的完美的支持。JAVA语言就很好,以至于了解Python和PHP之前我从来没有考虑过这些不应该由程序员来处理的问题。遗憾的是,很多编程语言试图混淆“字符串”和“字节串”,他们把字节串当做字符串来使用,PHP和Python2都属于这种编程语言。最能说明这个问题的操作就是取一个包含中文字符的字符串的长度:
- 对字符串取长度,结果应该是所有字符串的个数,无论中文还是英文
- 对字符串对应的字节串取长度,就跟编码(encode)过程使用的字符编码有关了(比如:UTF-8编码,一个中文字符需要用3个字节来表示;GBK编码,一个中文字符需要2个字节来表示)
注意:Windows的cmd终端字符编码默认为GBK,因此在cmd输入的中文字符需要用两个字节表示
>>> # Python2
>>> a = 'Hello,中国' # 字节串,长度为字节个数 = len('Hello,')+len('中国') = 6+2*2 = 10
>>> b = u'Hello,中国' # 字符串,长度为字符个数 = len('Hello,')+len('中国') = 6+2 = 8
>>> c = unicode(a, 'gbk') # 其实b的定义方式是c定义方式的简写,都是将一个GBK编码的字节串解码(decode)为一个Uniocde字符串
>>>
>>> print(type(a), len(a))
(, 10)
>>> print(type(b), len(b))
(, 8)
>>> print(type(c), len(c))
(, 8)
>>>
Python3中对字符串的支持做了很大的改动。
-
编码
+关注
关注
6文章
942浏览量
54814 -
字符
+关注
关注
0文章
233浏览量
25199 -
python
+关注
关注
56文章
4792浏览量
84630
发布评论请先 登录
相关推荐
探究python字节码
字符流和字节流有什么那区别

Python转义字符使用总结资料免费下载

什么是复制字符串?Python如何复制字符串

2.2 python字符串类型

python字符串有哪些特定方法
Python2与Python3中对字符串的支持
Python字符编码转换





 工商网监
工商网监
评论