 Python编码与解码
Python编码与解码
先做下科普:UNICODE字符编码,也是一张字符与数字的映射,但是这里的数字被称为代码点(code point), 实际上就是十六进制的数字。
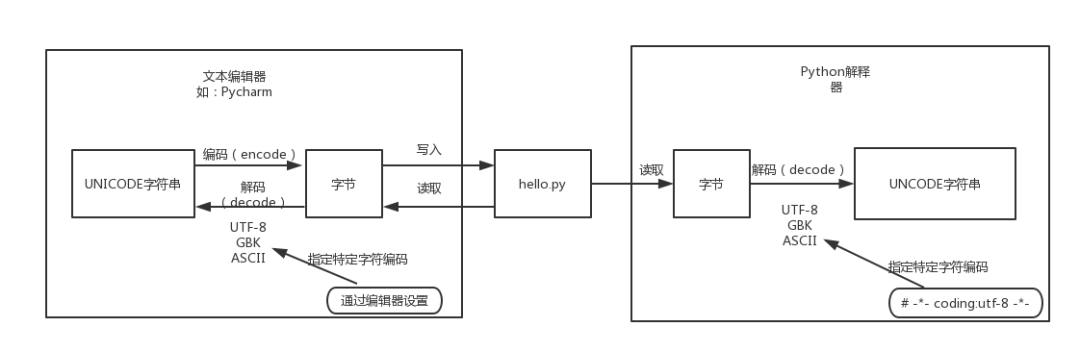
Python官方文档中对Unicode字符串、字节串与编码之间的关系有这样一段描述:
Unicode字符串是一个代码点(code point)序列,代码点取值范围为0到0x10FFFF(对应的十进制为1114111)。这个代码点序列在存储(包括内存和物理磁盘)中需要被表示为一组字节(0到255之间的值),而将Unicode字符串转换为字节序列的规则称为编码。
这里说的编码不是指字符编码,而是指编码的过程以及这个过程中所使用到的Unicode字符的代码点与字节的映射规则。这个映射不必是简单的一对一映射,因此编码过程也不必处理每个可能的Unicode字符,例如:
将Unicode字符串转换为ASCII编码的规则很简单--对于每个代码点:
如果代码点数值《128,则每个字节与代码点的值相同
如果代码点数值》=128,则Unicode字符串无法在此编码中进行表示(这种情况下,Python会引发一个UnicodeEncodeError异常)
将Unicode字符串转换为UTF-8编码使用以下规则:
如果代码点数值《128,则由相应的字节值表示(与Unicode转ASCII字节一样)
如果代码点数值》=128,则将其转换为一个2个字节,3个字节或4个字节的序列,该序列中的每个字节都在128到255之间。
简单总结:
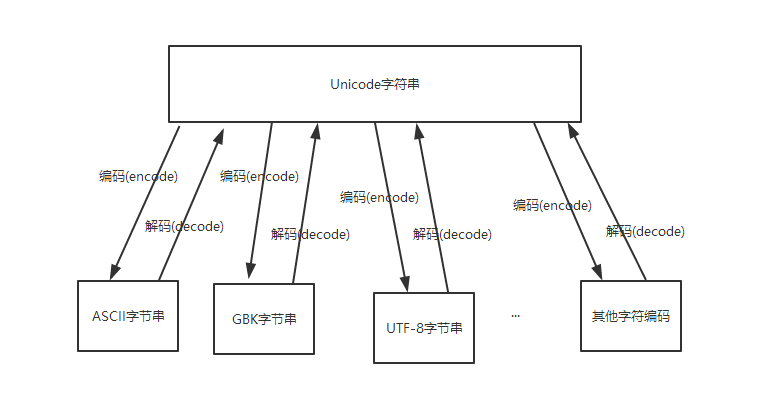
编码(encode):将Unicode字符串(中的代码点)转换特定字符编码对应的字节串的过程和规则
解码(decode):将特定字符编码的字节串转换为对应的Unicode字符串(中的代码点)的过程和规则
可见,无论是编码还是解码,都需要一个重要因素,就是特定的字符编码。因为一个字符用不同的字符编码进行编码后的字节值以及字节个数大部分情况下是不同的,反之亦然。
-
编码
+关注
关注
6文章
935浏览量
54759 -
python
+关注
关注
56文章
4781浏览量
84441
发布评论请先 登录
相关推荐
正交编码解码原理及解码思路
什么是音频的编码和解码/HZ(赫兹)
短信编码与解码C语言
java实现的哈夫曼编码与解码

NVIDIA推出适用于Python的VPF,简化开发GPU加速视频编码/解码
STM32的音频编码与在PC端的解码

基于transformer的编码器-解码器模型的工作原理
Python中的默认编码
Python字符编码转换





 工商网监
工商网监
评论