 Python字符编码转换
Python字符编码转换

UNICODE字符串可以与任意字符编码的字节进行相互转换,如图:
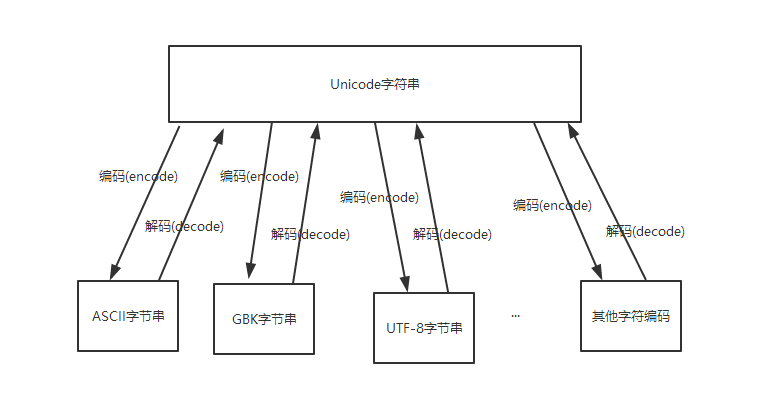
那么大家很容易想到一个问题,就是不同的字符编码的字节可以通过Unicode相互转换吗?答案是肯定的。
Python2中的字符串进行字符编码转换过程是:
字节串-->decode('原来的字符编码')-->Unicode字符串-->encode('新的字符编码')-->字节串
#!/usr/bin/env python
# -*- coding:utf-8 -*-
utf_8_a = '我爱中国'
gbk_a = utf_8_a.decode('utf-8').encode('gbk')
print(gbk_a.decode('gbk'))
输出结果:
我爱中国
Python3中定义的字符串默认就是unicode,因此不需要先解码,可以直接编码成新的字符编码:
字符串-->encode('新的字符编码')-->字节串
#!/usr/bin/env python
# -*- coding:utf-8 -*-
utf_8_a = '我爱中国'
gbk_a = utf_8_a.encode('gbk')
print(gbk_a.decode('gbk'))
输出结果:
我爱中国
最后需要说明的是,Unicode不是有道词典,也不是google翻译器,它并不能把一个中文翻译成一个英文。正确的字符编码的转换过程只是把同一个字符的字节表现形式改变了,而字符本身的符号是不应该发生变化的,因此并不是所有的字符编码之间的转换都是有意义的。怎么理解这句话呢?比如GBK编码的“中国”转成UTF-8字符编码后,仅仅是由4个字节变成了6个字节来表示,但其字符表现形式还应该是“中国”,而不应该变成“你好”或者“China”。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
编码
+关注
关注
6文章
1041浏览量
57194 -
字符
+关注
关注
0文章
237浏览量
26303 -
python
+关注
关注
59文章
4891浏览量
90388
发布评论请先 登录
相关推荐
热点推荐
C++字符编码转换的基本方法
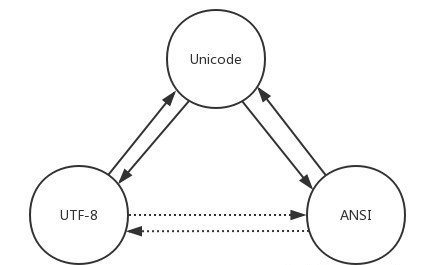
这篇文章介绍了如何在最常见的编码方式(Unicode, UTF-8, ANSI)之间进行转换,结合代码实例,清晰明了,方便读者理解,例子也可以直接拿来使用。本文推荐给经常对文字字符串进行处理的程序员阅读,使其掌握
发表于 09-20 09:50
•2572次阅读

从5个方面来解析计算机中的字符编码概念
字符编码是计算机编程中不可回避的问题,不管你用 Python2 还是 Python3,亦或是 C++, Java 等,我都觉得非常有必要厘清计算机中的

Python转义字符使用总结资料免费下载
本文档的主要内容详细介绍的是Python转义字符使用总结资料免费下载主要内容包括了:Python转义字符,Python
发表于 01-17 17:24
•6次下载


C++中字符编码的转换
。 这篇文章介绍了如何在最常见的编码方式(Unicode, UTF-8, ANSI)之间进行转换,结合代码实例,清晰明了,方便读者理解,例子也可以直接拿来使用。本文推荐给经常对文字字符串进行处理的程序员阅读,使其掌握
2.2 python字符串类型
2.2 python字符串类型 1. 如何定义字符串? 字符串是Python中最常用的数据类型之一。 使用单引号或双引号来创建
python字符串有哪些特定方法
python字符串序列操作也适用于列表和元组。
python字符串还有独有方法,即字符串对象的函数,其他对象不可调用,只有
Python字符与字节
的不同的表示方法就是指字符编码,比如字母A-Z都可以用ASCII码表示(占用一个字节),也可以用UNICODE表示(占两个字节),还可以用UTF-8表示(占用一个字节)。字符编码的作用
Python编码与解码
先做下科普:UNICODE字符编码,也是一张字符与数字的映射,但是这里的数字被称为代码点(code point), 实际上就是十六进制的数字。 Python官方文档中对Unicode
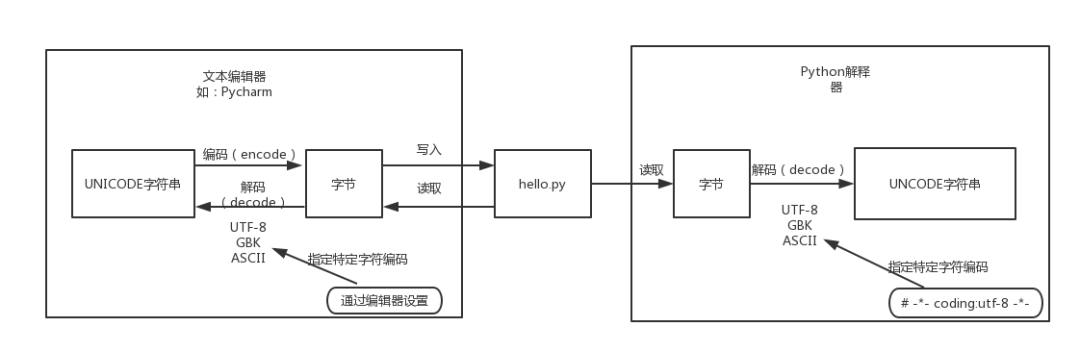
Python中的默认编码
####1. Python源代码文件的执行过程 我们都知道,磁盘上的文件都是以二进制格式存放的,其中文本文件都是以某种特定编码的字节形式存放的。对于程序源代码文件的字符编码是由编辑器指
Python2与Python3中对字符串的支持
其实Python3中对字符串支持的改进,不仅仅是更改了默认编码,而是重新进行了字符串的实现,而且它已经实现了对UNICODE的内置支持,从这方面来讲
mysql数据库默认字符编码是什么
编码是一种将字符映射到二进制数据的方式。它定义了字符在计算机中的存储和传输方式,决定了计算机如何解读和显示不同的字符。 为什么需要字符
如何解决Python爬虫中文乱码问题?Python爬虫中文乱码的解决方法
决Python爬虫中文乱码问题。 一、了解字符编码 在解决乱码问题之前,我们首先需要了解一些基本的字符编码知识。常见的



评论