 一个GPU工作负载的调查
一个GPU工作负载的调查

GPU 是专门为高速处理大量数据而设计的。他们拥有大量的计算资源,称为流式多处理器( SMs ),以及一系列保持数据供应的设施:高带宽的内存、相当大的数据缓存,以及在活动团队数据耗尽时切换到其他工作团队( warp )而无需任何开销的能力。
然而,数据饥饿仍可能发生,许多代码优化都集中在这个问题上。在某些情况下, SM 渴望的不是数据,而是指令。这篇文章介绍了一个 GPU 工作负载的调查,该工作负载由于指令缓存未命中而速度减慢。它描述了如何识别这个瓶颈,以及消除它以提高性能的技术。
认识到问题
这项研究的起源源于基因组学领域的一项应用,其中需要解决将 DNA 样本的小片段与参考基因组比对的许多小而独立的问题。背景是众所周知的 Smith-Waterman 算法(但这本身对讨论并不重要)。
在强大的 NVIDIA H100 Hopper GPU,具有 114 个 SM,显示出良好的前景。使用 NVIDIA Nsight Compute( NCU )工具分析程序,可以证实 SM 在 GPU 上进行有用的计算,但也存在问题。
组成整体工作负载的许多小问题(每个问题由自己的线程处理)可以同时在 GPU 上运行,因此并非所有的计算资源都一直被完全使用。这被表示为一个小的非整数数量的波。 GPU 的工作被划分为称为线程块的块,一个或多个可以驻留在 SM 上。如果一些 SM 接收到的线程块比其他 SM 少,则它们将耗尽工作,并且在其他 SM 继续工作时必须空闲。
用螺纹块完全填满所有 SM 构成一个波。 NCU 尽职尽责地报告每个 SM 的波数。如果这个数字恰好是 100 . 5 ,这意味着并非所有 SM 都有相同的工作量要做,有些 SM 被迫闲置。但分布不均的影响并不大。大多数时候, SM 上的负载是平衡的。例如,如果波浪的数量仅为 0 . 5 ,则情况会发生变化。在更大比例的时间里, SM 经历了不均衡的工作分配,这被称为“尾部”效应。
解决尾部效应
这种现象正是基因组学工作量所体现的。海浪的数量只有 1 . 6 次。显而易见的解决方案是给 GPU 更多的工作要做(更多的线程,导致每个线程 32 个线程的更多翘曲),这通常不是问题。最初的工作量相对较小,在实际环境中需要解决更大的问题。然而,通过将子问题的数量增加一倍( 2x )、三倍( 3x )和四倍( 4x )来增加工作负载( 1x ),性能非但没有提高,反而恶化。是什么导致了这种结果?
NCU 关于这四种工作量规模的综合报告揭示了这一情况。在名为 Warp State 的部分中,列出了线程无法取得进展的原因,“ No Instruction ”的值随着工作负载大小的增加而显著增加(图 1 )。
“无指令”表示无法从内存以足够快的速度向 SM 提供指令“长记分牌”表示 SM 无法以足够快的速度从内存中获得数据。及时获取指令至关重要,因此 GPU 提供了许多站点,一旦获取指令,就可以将其放置在这些站点,以使其靠近 SM 。这些站点被称为指令缓存,其级别甚至比数据缓存更多。
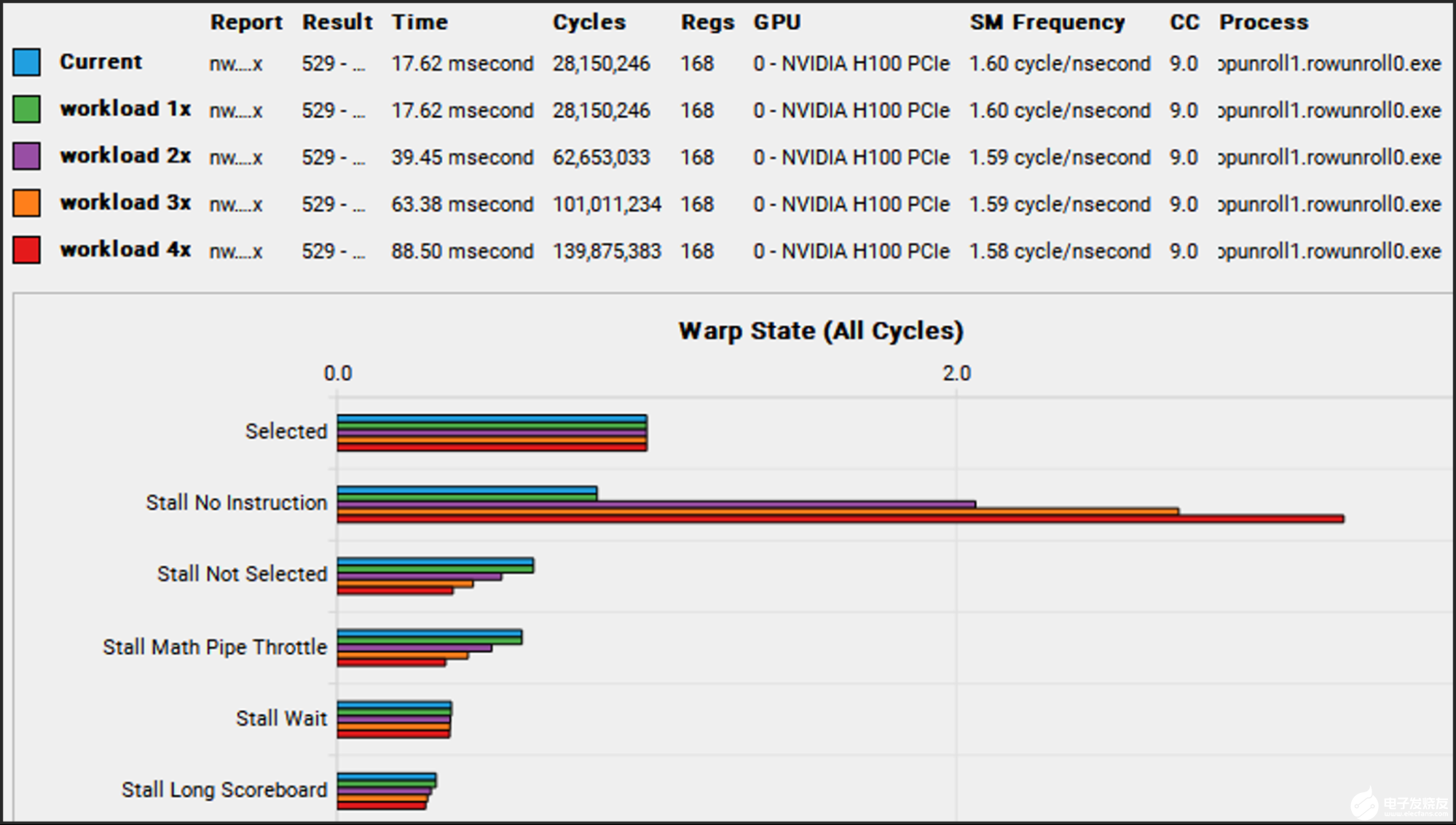 图 1 。 NVIDIA Nsight Compute 合并报告中四种工作负载大小的扭曲失速原因截图
图 1 。 NVIDIA Nsight Compute 合并报告中四种工作负载大小的扭曲失速原因截图
为了了解指令缓存瓶颈发生在哪里,我们的团队再次运行了相同的工作负载,但这次指示 NCU 使用名为 Metrics 的功能收集比以前更多的信息。此功能用于指定未包含在常规性能报告中的性能计数器的用户定义列表。在这种特殊情况下,使用了与指令缓存相关的大量计数器:
gcc__raw_l15_instr_hit, gcc__raw_l15_instr_hit_under_miss, gcc__raw_l15_instr_miss, sm__icc_requests, sm__icc_requests_lookup_hit, sm__icc_requests_lookup_miss, sm__icc_requests_lookup_miss_covered, sm__icc_requests_lookup_miss_to_gcc, sm__raw_icc_covered_miss, sm__raw_icc_covered_miss_tpc, sm__raw_icc_hit, sm__raw_icc_hit_tpc, sm__raw_icc_request_tpc_1b_apm, sm__raw_icc_true_hits_tpc_1b_apm, sm__raw_icc_true_miss, sm__raw_icc_true_miss_tpc, sm__raw_icc_unlock_all_tpc, sm__raw_l0icache_hits_sctlall, sm__raw_l0icache_requests_sctlall, sm__raw_l0icache_requests_to_icc_sctlall, smsp__l0icache_fills, smsp__l0icache_requests, smsp__l0icache_requests_hit, smsp__l0icache_requests_miss, smsp__raw_l0icache_hits, smsp__raw_l0icache_requests_to_icc
结果是,在所有测量的数量中,成本相对较高的 icc 缓存未命中尤其会随着工作负载大小的增加而不成比例地增加(图 2 )。 icc 缓存是一个指令缓存,位于 SM 本身,非常接近实际的指令执行引擎。
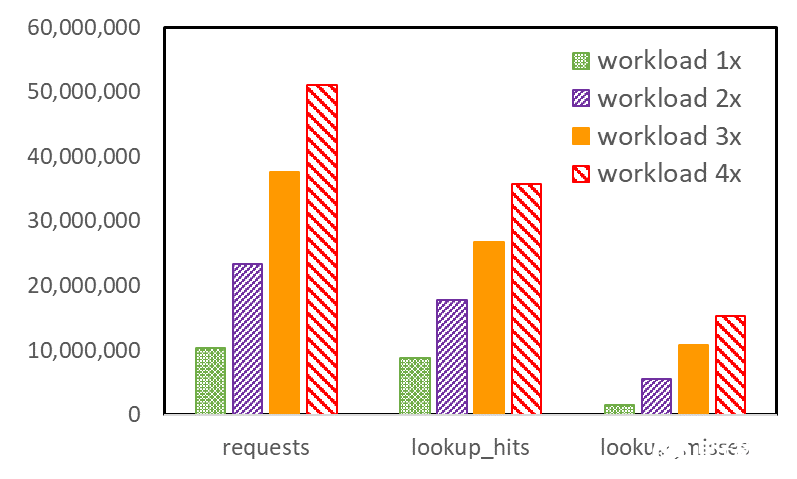 图 2 :与 icc 指令缓存请求相关的性能计数器,包括快速增加的 icc 未命中,用于不断增加的大小的工作负载
图 2 :与 icc 指令缓存请求相关的性能计数器,包括快速增加的 icc 未命中,用于不断增加的大小的工作负载
icc 未命中的增加如此之快,这意味着,首先,并非代码中最繁忙部分的所有指令都适合 icc 。其次,随着工作负载大小的增加,对更多不同指令的需求也会增加。后者的原因有些微妙。由扭曲组成的多个线程块同时驻留在 SM 上,但并非所有扭曲都同时执行。
SM 内部分为四个分区,每个分区通常每个时钟周期可以执行一条 warp 指令。当一个经线由于任何原因而停滞时,另一个同样位于 SM 上的经线可以接管。每个扭曲都可以独立于其他扭曲执行自己的指令流。在这个程序的主内核开始时,在每个 SM 上运行的扭曲大多是同步的。他们从第一个指令开始,一直在蹒跚前行。
然而,它们并没有明确地同步,随着时间的推移,扭曲轮流空转和执行,它们将在执行的指令方面越来越偏离。这意味着随着执行的进行,一组不断增长的不同指令必须是活动的,这反过来意味着 icc 溢出的频率更高。指令缓存压力增大,会发生更多未命中。
解决问题
扭曲指令流的逐渐漂移无法控制,除非通过同步这些流。但同步通常会降低性能,因为在没有基本需求的情况下,它需要扭曲来相互等待。然而,可以尝试减少整个指令占用空间,这样从 icc 溢出的指令发生的频率就会降低,而且可能根本不会发生。
有问题的代码包含嵌套循环的集合,并且大多数循环都是展开的。展开通过使编译器能够:
重新排序(独立)指令以实现更好的调度
消除循环的连续迭代可以共享的一些指令
减少分支
为循环的不同迭代中引用的同一变量分配不同的寄存器,以避免必须等待特定寄存器可用
展开循环带来了许多好处,但它确实增加了指令的数量。它还倾向于增加所使用的寄存器数量,这可能会降低性能,因为同时存在于 SM 上的翘曲可能更少。这种扭曲占用率的降低带来了更少的延迟隐藏。
内核最外层的两个循环是焦点。实际的展开最好留给编译器,它有无数的启发式方法来生成好的代码。也就是说,用户通过在循环的顶部之前使用提示(在 C ++中称为 pragmas )来表达展开的预期好处。其形式如下:
#pragma unroll X
其中X可以是空的(规范展开),编译器只被告知展开可能是有益的,但没有给出任何建议要展开多少迭代。或者是(n),其中n是一个正数,表示按组展开n迭代。为了方便起见,采用了以下符号。展开因子 0 表示根本没有展开杂注,展开因子 1 表示没有任何数字的展开杂注(规范),展开因子为n大于 1 表示:
#pragma unroll (n)
下一个实验包括一组运行,其中代码中最外层两个循环的两个级别的展开因子都在 0 到 4 之间变化,从而为四种工作负载大小中的每一种产生性能数据。不需要进行更多的展开,因为实验表明,编译器不会为该特定程序的较高展开因子生成不同的代码。图 3 显示了套件的结果。
顶部水平轴显示最外层循环(顶层)的展开系数。底部水平轴显示第二级循环的展开因子。四条性能曲线中的任何一条上的每个点(越高越好)对应于两个展开因子,一个用于水平轴上所示的最外循环中的每一个。
图 3 还显示了对于展开因子的每个实例,可执行文件的大小(以 500KB 为单位)。虽然人们的期望可能是随着每一个更高级别的展开,可执行文件的大小都会增加,但事实并非总是如此。展开杂注是编译器可能会忽略的提示,如果它们不被认为是有益的。
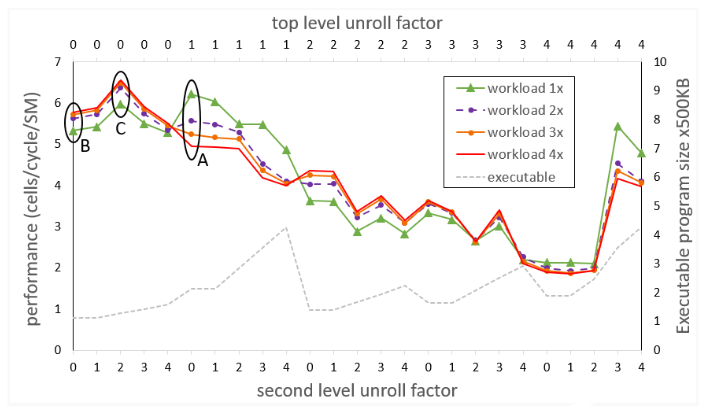 图 3 。Smith Waterman 码在不同工作负载大小和不同循环展开因子下的性能
图 3 。Smith Waterman 码在不同工作负载大小和不同循环展开因子下的性能
对应于代码的初始版本(由标记为 A 的椭圆指示)的测量用于顶层循环的规范展开,而不用于第二级循环的展开。代码的异常行为是显而易见的,由于 icc 未命中的增加,较大的工作负载大小会导致较差的性能。
在下一个孤立的实验中(由标记为 B 的椭圆表示),在全套运行之前尝试,最外面的两个循环都没有展开。现在,异常行为已经消失,更大的工作负载大小会带来预期的更好性能。但是,绝对性能会降低,尤其是对于原始工作负载( 1x )大小。 NCU 揭示的两个现象有助于解释这一结果。由于指令占用空间较小,对于所有大小的工作负载, icc 未命中几乎已降至零。然而,编译器为每个线程分配了相对大量的寄存器,因此可以驻留在 SM 上的扭曲数量不是最佳的。
对展开因子进行全面扫描表明,标记为 C 的椭圆中的实验是众所周知的最佳点。它对应于不展开顶级循环,而展开第二级循环的因子 2 。 NCU 仍然显示出几乎没有 icc 未命中,并且每个线程的寄存器数量减少,因此与实验 B 相比, SM 上可以容纳更多的扭曲,从而导致更多的延迟隐藏。
虽然最小工作负载的绝对性能仍落后于实验 A ,但差异不大,而且较大的工作负载表现得越来越好,从而在所有工作负载大小中获得最佳的平均性能。
结论
指令缓存未命中可能会导致指令占用空间大的内核性能下降,这通常是由大量循环展开引起的。当编译器负责通过杂注展开时,它应用于代码以确定最佳实际展开级别的启发式方法必然很复杂,程序员并不总是可以预测的。试验关于循环展开的不同编译器提示,以获得具有良好扭曲占用率和减少指令缓存未命中的最佳代码,可能是值得的。
-
NVIDIA
+关注
关注
14文章
5721浏览量
110230 -
gpu
+关注
关注
28文章
5317浏览量
136178 -
人工智能
+关注
关注
1821文章
50485浏览量
267632
发布评论请先 登录
优化任何GPU工作负载的峰值性能分析方法
为什么需要专门出现GPU处理图形工作?GPU服务器有什么作用?
GPU是如何工作的?与CPU、DSP有什么区别?
VMware GPU分配/在GPU 1之前首先使用GPU 0
如何测量各种工作负载和GPU配置下收缩操作的性能
英特尔推出 Flex 系列GPU,灵活处理多种工作负载需求

GPU工作原理 如何提高集成GPU的工作频率
为什么需要专门出现GPU处理图形工作?

GPU图像处理的工作原理
深度学习工作负载中GPU与LPU的主要差异

成功案例:象帝先计算技术与Imagination合作——面向现代图形与计算工作负载的专业GPU




评论