 如何使用NVIDIA Triton Inference Server
如何使用NVIDIA Triton Inference Server
人工智能模型无处不在,形式包括聊天机器人、分类和摘要工具、用于分割和检测的图像模型、推荐模型等。人工智能机器学习( ML )模型有助于实现许多业务流程的自动化,从数据中生成见解,并提供新的体验。
Python 是 AI/ML 开发中最受欢迎的语言之一。本文将教您如何使用 NVIDIA Triton Inference Server,并利用新的 PyTriton 接口。
更具体地说,您将学习如何在 Python 开发环境中使用生产类工具对人工智能模型进行原型化和测试推理,以及如何使用 PyTriton 接口进行生产。与 FastAPI 或 Flask 等通用 web 框架相比,您还将了解使用 PyTriton 的优势。这篇文章包括几个代码示例,说明如何激活高性能的批处理、预处理和多节点推理;并实施在线学习。
什么是 PyTriton ?
PyTriton 是一个简单的接口,可让 Python 开发人员使用 Triton 推理服务器为 Python 代码中的人工智能模型、简单处理功能或整个推理管道提供服务。Triton 推理服务器是一款开源的多框架推理服务软件,在 CPU 和 GPU 上具有较高的性能。
PyTriton 可以实现快速原型设计和测试 ML 模型,同时实现高 GPU 利用率的性能和效率。只需一行代码,就可以调出 Triton 推理服务器,提供 动态批处理、并发模型执行以及从 GPU 代码中支持 GPU 和 Python 的优势。
PyTriton 消除了建立模型存储库和将模型从开发环境移植到生产环境的需要。现有的推理管道代码也可以在不进行修改的情况下使用。这对于较新类型的框架(如 JAX )或复杂的管道(它们是 Triton 推理服务器中没有专用后端的应用程序代码的一部分)尤其有用。
Flask 的简单性
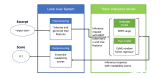
Flask 和FastAPI 是通用的 Python Web 框架,用于部署各种各样的 Python 应用程序。由于它们的简单性和广泛采用,许多开发人员在生产中使用它们来部署和运行人工智能模型。然而,这种方法存在显著的缺点,包括:
通用网络服务器缺乏对人工智能推理功能的支持。没有现成的支持来利用像 GPU 这样的加速器,或者打开动态批处理或多节点推理。
用户需要构建逻辑来满足特定用例的需求,如音频/视频流输入、有状态处理或预处理输入数据以适应模型。
关于计算和内存利用率或推理延迟的指标不容易用于监控应用程序的性能和规模。
Triton Inference Server包含对上述功能以及更多功能的内置支持。PyTriton 提供了 Flask 的简单性和 Python 中 Triton 的示例部署。HuggingFace 文本分类管道使用 PyTriton 如下所示:
import logging import numpy as np from transformers import BertTokenizer, FlaxBertModel # pytype: disable=import-error from pytriton.decorators import batch from pytriton.model_config import ModelConfig, Tensor from pytriton.triton import Triton logger = logging.getLogger("examples.huggingface_bert_jax.server") logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(name)s: %(message)s") tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") model = FlaxBertModel.from_pretrained("bert-base-uncased") @batch def _infer_fn(**inputs: np.ndarray): (sequence_batch,) = inputs.values() # need to convert dtype=object to bytes first # end decode unicode bytes sequence_batch = np.char.decode(sequence_batch.astype("bytes"), "utf-8") last_hidden_states = [] for sequence_item in sequence_batch: tokenized_sequence = tokenizer(sequence_item.item(), return_tensors="jax") results = model(**tokenized_sequence) last_hidden_states.append(results.last_hidden_state) last_hidden_states = np.array(last_hidden_states, dtype=np.float32) return [last_hidden_states] with Triton() as triton: logger.info("Loading BERT model.") triton.bind( model_name="BERT", infer_func=_infer_fn, inputs=[ Tensor(name="sequence", dtype=np.bytes_, shape=(1,)), ], outputs=[ Tensor(name="last_hidden_state", dtype=np.float32, shape=(-1,)), ],
PyTriton 为 Flask 用户提供了一个熟悉的界面,便于安装和设置,并提供了以下好处:
用一行代码调出 NVIDIA Triton
无需设置模型存储库和模型格式转换(对于使用 Triton 推理服务器的高性能实现非常重要)
使用现有推理管道代码而不进行修改
支持许多装饰器来调整模型输入
无论是在generative AI应用程序还是其他模型中,PyTriton 可以让您在自己的开发环境中获得 Triton InferenceServer 的好处。它可以帮助利用 GPU 在很短的时间内(毫秒或秒,取决于用例)生成推理响应。它还有助于以高容量运行 GPU ,并且可以同时为许多推理请求提供服务,且基础设施成本低。
PyTriton 代码示例
本节提供了一些可以用来开始 PyTriton 的代码示例。它们从本地机器开始,这是测试和原型的理想选择,并为大规模部署提供 Kubernetes 配置。
动态配料支持
Flask/FastAPI 和 PyTriton 之间的一个关键区别是,动态批处理允许对来自模型的多个调用应用程序的推理请求进行批处理,同时保留延迟要求。两个示例是HuggingFace BART PyTorch和HuggingFace ResNET PyTorch。
在线学习
在线学习是指在生产中不断从新数据中学习。使用 PyTriton,您可以控制支持推理服务器的不同模型实例的数量,从而使您能够同时训练和服务同一个模型。想要了解更多关于如何使用 PyTriton 在 MNIST 数据集上同时训练和推断模型的信息,请访问 PyTriton 的示例。
大型语言模型的多节点推理
太大而无法放入单个 GPU 内存的大型语言模型(LLM)需要将模型划分为多个 GPU,在某些情况下,还需要跨多个节点进行推理。要查看示例,请访问 Hugging Face OPT 模型在 JAX 中的多节点推理。
想要查看NeMo Megatron GPT 模型部署,使用NVIDIA NeMo 1.3B 参数模型。使用 Slurm 和 Kubernetes 展示了多节点推理部署编排。
稳定扩散
使用 PyTriton ,您可以使用预处理装饰器来执行高级批处理操作,例如使用简单的定义将相同大小的图像批处理在一起:
@batch
@group_by_values("img_size")
@first_value("img_size")
想了解更多信息,请查看此示例,该示例使用 Hugging Face 的 Stable Diffusion 1.5 图像生成管道。
总结
PyTriton 提供了一个简单的接口,使 GPU 开发人员能够使用 NVIDIA Triton InferenceServer 为模型、简单的处理功能或整个推理管道提供服务。这种对 Python 中的 Triton 推理服务器的本地支持使 ML 模型的快速原型设计和测试具有性能和效率。一行代码就会显示 Triton 推理服务器。动态批处理、并发模型执行以及 Python 代码中对 GPU 和 Python 的支持都是其中的好处。 PyTriton 提供了 Flask 的简单性和 Python 中 Triton InferenceServer 的优点。
-
NVIDIA
+关注
关注
14文章
4983浏览量
103006 -
人工智能
+关注
关注
1791文章
47229浏览量
238333 -
python
+关注
关注
56文章
4795浏览量
84646
发布评论请先 登录
相关推荐
GTC2022大会黄仁勋:NVIDIA Triton是AI部署的“中央车站”
Microsoft使用NVIDIA Triton加速AI Transformer模型应用
NVIDIA Triton推理服务器简化人工智能推理
使用NVIDIA Triton推理服务器简化边缘AI模型部署
利用NVIDIA Triton推理服务器加速语音识别的速度
NVIDIA Triton助力腾讯PCG加速在线推理





 工商网监
工商网监
评论