 Spark 3.4用于分布式模型训练和大规模模型推理
Spark 3.4用于分布式模型训练和大规模模型推理
Apache Spark是一个业界领先的平台,用于大规模数据的分布式提取、转换和加载( ETL )工作负载。随着深度学习( DL )的发展,许多 Spark 从业者试图将 DL 模型添加到他们的数据处理管道中,以涵盖各种用例,如销售预测、内容推荐、情绪分析和欺诈检测。
然而,结合 DL 培训和推理,从历史上看,大规模数据一直是 Spark 用户面临的挑战。大多数 DL 框架都是为单节点环境设计的,它们的分布式训练和推理 API 通常是经过深思熟虑后添加的。
为了解决单节点 DL 环境和大规模分布式环境之间的脱节,有多种第三方解决方案,如 Horovod-on-Spark、TensorFlowOnSpark 和 SparkTorch,但由于这些解决方案不是在 Spark 中本地构建的,因此用户必须根据自己的需求评估每个平台。
随着 Spark 3.4 的发布,用户现在可以访问内置的 API,用于分布式模型训练和大规模模型推理,如下所述。
分布式培训
对于分布式培训,有一个新的 TorchDistributor PyTorch 的 API,它遵循 spark-tensorflow-distributorTensorFlow 的 API。这些 API 通过利用 Spark 的屏障执行模式,在 Spark executors 上生成分布式 DL 集群节点,从而简化了将分布式 DL 模型训练代码迁移到 Spark 的过程。
一旦 Spark 启动了 DL 集群,控制权就基本上通过main_fn传递给TorchDistributorAPI
如下面的代码所示,使用这个新的 API 在 Spark 上运行标准的分布式 DL 培训只需要进行最小的代码更改。
from pyspark.ml.torch.distributor import TorchDistributor
def main_fn(checkpoint_dir):
# standard distributed PyTorch code
...
# Set num_processes = NUM_WORKERS * NUM_GPUS_PER_WORKER
output_dist = TorchDistributor(num_processes=2, local_mode=False, use_gpu=True).run(main_fn, checkpoint_dir)
一旦启动,运行在执行器上的流程就依赖于其各自 DL 框架的内置分布式训练 API 。将现有的分布式训练代码移植到 Spark 应该很少或不需要修改。然后,这些进程可以在训练期间相互通信,还可以直接访问与 Spark 集群相关的分布式文件系统(图 1 )。
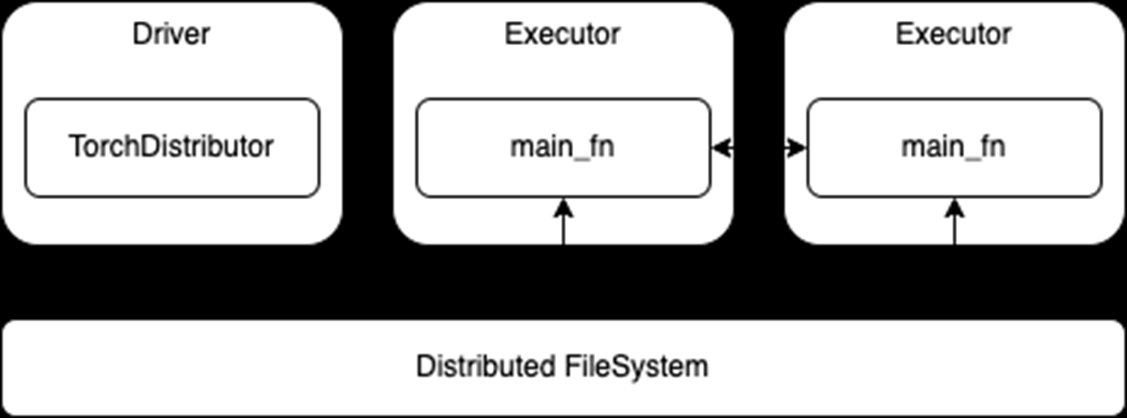 图 1 。分布式培训使用TorchDistributorAPI
图 1 。分布式培训使用TorchDistributorAPI
然而,这种迁移的方便性也意味着这些 API 不使用 Spark RDD 或 DataFrames 进行数据传输。虽然这消除了在 Spark 和 DL 框架之间转换或序列化数据的任何需要,但它也要求在启动训练作业之前完成任何 Spark 预处理并持久化到存储中。主要训练功能可能还需要适于从分布式文件系统而不是本地存储读取。
分布式推理
对于分布式推理,有一个新的predict_batch_udfAPI ,它建立在Spark Pandas UDF以便为 DL 模型推断提供更简单的接口。 pandas 与基于行的 UDF 相比, UDF 提供了一些优势,包括通过Apache Arrow以及通过Pandas。有关详细信息,请参阅Introducing Pandas UDF for PySpark.
然而,尽管 pandas UDF API 可能是 ETL 用例的一个很好的解决方案,但它仍然不适合 DL 推理用例。首先, pandas UDF API 将数据表示为 pandas 系列或数据帧,这同样适用于执行 ETL 操作,如选择、排序、数学转换和聚合。
然而,大多数 DL 框架都期望NumPy数组或标准 Python 数组作为输入,这些数组通常由自定义张量变量包装。因此,pandas UDF 实现至少需要将传入的 pandas 数据转换为 NumPy 数组。不过,根据用例和数据集的不同,准确的转换可能会有很大的差异。
其次, pandas UDF API 通常在数据分区上运行,数据分区的大小由数据集的原始写入者或分布式文件系统决定。因此,很难对传入的数据进行适当的批处理以进行优化计算。
最后,仍然存在在 Spark 执行器和任务之间加载 DL 模型的问题。在正常的 Spark ETL 工作中,工作负载遵循函数编程范式,其中可以对数据应用无状态函数。然而,对于 DL 推理,预测函数通常需要从磁盘加载其 DL 模型权重。
Spark 具有通过任务序列化和广播变量将变量从驱动程序序列化到执行器的能力。然而,这两者都依赖于 Python pickle 序列化,这可能不适用于所有 DL 模型。此外,如果操作不当,加载和序列化非常大的模型可能会带来极高的性能成本。
解决当前限制
为了解决这些问题predict_batch_udf引入了以下方面的标准化代码:
将 Spark 数据帧转换为 NumPy 数组,因此最终用户 DL 推理代码不需要从 pandas 数据帧进行转换。
为 DL 框架批处理传入的 NumPy 数组。
在执行器上加载模型,避免了任何模型序列化问题,同时利用 Sparkspark.python.worker.reuse配置以在 Spark 执行器中缓存模型。
下面的代码演示了这个新的 API 如何隐藏将 DL 推理代码转换为 Spark 的复杂性。用户只需定义make_predict_fn函数,使用标准的 DL API 加载模型并返回predict作用然后predict_batch_udf函数生成一个标准PandasUDF,负责处理幕后的其他一切。
from pyspark.ml.functions import predict_batch_udf def make_predict_fn(): # load model from checkpoint import torch device = torch.device("cuda") model = Net().to(device) checkpoint = load_checkpoint(checkpoint_dir) model.load_state_dict(checkpoint['model']) # define predict function in terms of numpy arrays def predict(inputs: np.ndarray) -> np.ndarray: torch_inputs = torch.from_numpy(inputs).to(device) outputs = model(torch_inputs) return outputs.cpu().detach().numpy() return predict # create standard PandasUDF from predict function mnist = predict_batch_udf(make_predict_fn, input_tensor_shapes=[[1,28,28]], return_type=ArrayType(FloatType()), batch_size=1000) df = spark.read.parquet("/path/to/test/data") preds = df.withColumn("preds", mnist('data')).collect()
请注意,此 API 使用标准 Spark DataFrame 进行推断,因此执行器将从分布式文件系统读取数据并将该数据传递给predict函数(图 2 )。这也意味着,根据需要,数据的任何处理都可以与模型预测一起进行。
还要注意,这是一个data-parallel体系结构,其中每个执行器加载模型并对数据集的各自部分进行预测,因此模型必须适合执行器内存。
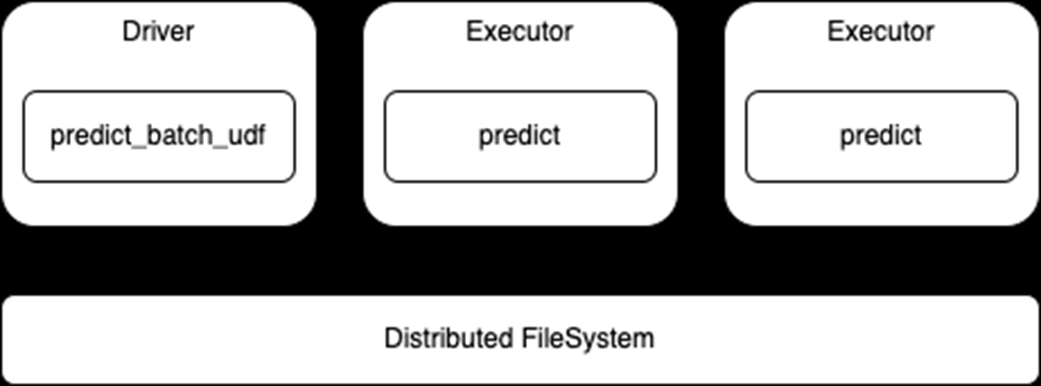 图 2 :分布式推理使用predict_batch_udfAPI
图 2 :分布式推理使用predict_batch_udfAPI
Spark 深度学习的端到端示例
-
NVIDIA
+关注
关注
14文章
5087浏览量
103917 -
人工智能
+关注
关注
1797文章
47867浏览量
240846 -
深度学习
+关注
关注
73文章
5521浏览量
121661
发布评论请先 登录
相关推荐
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践
【大语言模型:原理与工程实践】揭开大语言模型的面纱
【大语言模型:原理与工程实践】大语言模型的基础技术
分布式对象调试中的事件模型
基于代理模型的分布式聚类算法
大规模分布式机器学习系统分析


Google Brain和DeepMind联手发布可以分布式训练模型的框架
如何使用TensorFlow进行大规模和分布式的QML模拟
超大Transformer语言模型的分布式训练框架

探究超大Transformer语言模型的分布式训练框架
DGX SuperPOD助力助力织女模型的高效训练
使用NVIDIA DGX SuperPOD训练SOTA大规模视觉模型
基于PyTorch的模型并行分布式训练Megatron解析






 工商网监
工商网监
评论