 RAPID可能带来的性能提升的重要性
RAPID可能带来的性能提升的重要性
HDBSCAN 是一种最先进的基于密度的 聚类算法,已在主题建模、基因组学和地理空间分析等领域流行。
RAPIDS cuML 自 2021 10 月 21.10 发布以来,提供了加速 HDBSCAN ,详见 GPU-Accelerated Hierarchical DBSCAN with RAPIDS cuML – Let’s Get Back To The Future 。然而,不包括对 软聚类(也称为模糊聚类)的支持。使用软聚类,为每个点创建值向量(而不是单个聚类标签),表示该点是每个聚类成员的概率。
在 CPU 上执行 HDBSCAN 软群集速度缓慢。由于繁重的计算负担,中型数据集可能需要数小时甚至数天的时间。现在,在 22.10 RAPIDS release 中, cuML 为 HDBSCAN 提供了加速的软聚类,使该技术能够在大型数据集上使用。
这篇文章强调了使用软聚类来更好地捕捉下游分析中的细微差别以及 RAPID 可能带来的性能提升的重要性。在文档聚类示例中,在 CPU 上花费数小时的软聚类可以在 GPU 上使用 cuML 在几秒内完成。
软聚类代码
在基于 CPU 的 scikit-learn-contrib/hdbscan library 中,软集群通过 all_points_membership_vectors 顶级模块功能可用。
cuML 与此 API 匹配:
import cuml blobs, labels = cuml.datasets.make_blobs(n_samples=2000, n_features=10, random_state=12) clusterer = cuml.cluster.hdbscan.HDBSCAN(prediction_data=True) clusterer.fit(blobs) cuml.cluster.hdbscan.all_points_membership_vectors(clusterer)
为什么选择软群集
在许多聚类算法中,数据集中的每个记录要么被分配给单个聚类,要么被认为是噪声,而不被分配给任何聚类。然而,在现实世界中,许多记录并不完全适合一个集群。 HDBSCAN 通过表示每个点属于每个集群的程度来提供软集群机制,从而承认了这一现实。这类似于其他算法,例如混合模型和模糊 c 均值。
想象一篇关于体育主题音乐剧的新闻文章。如果你想将文章分配给一个集群,它是属于体育集群还是音乐集群?也许是专门为体育主题音乐剧打造的一个较小的集群?或者它应该在两个集群中都有一定程度的成员资格?
通过强制选择一个标签,这种细微差别就消失了,当聚类结果用于下游分析或行动时,这种差别可能会很重要。如果只指定了一个体育标签,那么推荐系统是否会将文章呈现给同样对音乐剧感兴趣的读者?那么反过来呢(读者对其中一个感兴趣,但对另一个不感兴趣)?对这两个主题中的一个或两个感兴趣的读者来说,这篇文章应该是潜在的。
软集群解决了这个问题,它支持基于每个类别的阈值的操作,并创建提供更好体验的应用程序。
文档聚类示例
您可以使用文档集群来衡量 cuML 加速软集群的潜在实际性能优势和影响。
许多现代文档群集工作流由以下步骤组成:
将每个文档转换为数字表示(通常使用神经网络嵌入)
降低数字转换文档的维数
对降维数据集执行聚类
根据结果采取行动
如果您想在系统上运行工作流,可以通过访问 GitHub 上的 hdbscan-blog.ipynb 获得 Jupyter 笔记本。
准备数据集
本例使用 Kaggle 的 A Million News Headlines 数据集,其中包含来自澳大利亚广播公司的 100 多万条新闻标题。
下载数据集后,将每个标题转换为嵌入向量。为此,使用 Sentence Transformers library 中的全 MiniLM-L6-v2 神经网络。请注意,稍后将使用导入的其他一些库。
import numpy as np
import pandas as pd
import cuml
from sentence_transformers import SentenceTransformer
N_HEADLINES = 10000
model = SentenceTransformer('all-MiniLM-L6-v2')
df = pd.read_csv("/path/to/million-headlines.zip")
embeddings = model.encode(df.headline_text[:N_HEADLINES])
降低维度
嵌入就绪后,使用 cuML 的 UMAP 将维度降到五个特征。本示例仅使用 10000 条记录,作为指南。
为了再现性,设置random_state。在您的计算机上运行时,此工作流中的结果可能略有不同,具体取决于 UMAP 结果。
umap = cuml.manifold.UMAP(n_components=5, n_neighbors=15, min_dist=0.0, random_state=12) reduced_data = umap.fit_transform(embeddings)
软聚类
接下来,在数据集上拟合 HDBSCAN 模型,并通过设置prediction_data=True启用使用all_points_membership_vectors进行软聚类。也设置min_cluster_size=50,这意味着少于 50 个标题的分组将被视为另一个集群(或噪声)的一部分,而不是单独的集群。
clusterer = cuml.cluster.hdbscan.HDBSCAN(min_cluster_size=50, metric='euclidean', prediction_data=True)
clusterer.fit(reduced_data)
soft_clusters = cuml.cluster.hdbscan.all_points_membership_vectors(clusterer)
soft_clusters[0]
array([0.01466704, 0.01035215, 0.0220814 , 0.01829496, 0.0127591 ,
0.02333117, 0.01993877, 0.02453639, 0.03369896, 0.02514531,
0.05555269, 0.04149485, 0.05131698, 0.02297594, 0.03559102,
0.02765776, 0.04131499, 0.06404213, 0.01866449, 0.01557038,
0.01696391], dtype=float32)
检查两个集群
在继续之前,请查看指定的标签( -1 表示噪声)。很明显,该数据中有相当多的集群:
pd.Series(clusterer.labels_).value_counts() -1 3943 3 1988 5 1022 20 682 13 367 7 210 0 199 2 192 8 190 16 177 12 161 17 143 15 107 19 86 9 83 11 70 4 68 18 66 6 65 10 61 1 61 14 59 dtype: int64
随机选择两个簇,例如簇 7 和簇 10 ,并检查每个簇中的几个点。
df[:N_HEADLINES].loc[clusterer.labels_ == 7].headline_text.head() 572 man accused of selling bali bomb chemicals goe... 671 timor sea treaty will be ratfied shortly martin 678 us asks indonesia to improve human rights record 797 shop owner on trial accused over bali bomb 874 gatecrashers blamed for violence at bali thank... Name: headline_text, dtype: object df[:N_HEADLINES].loc[clusterer.labels_ == 10].headline_text.head() 40 direct anger at govt not soldiers crean urges 94 mayor warns landfill protesters 334 more anti war rallies planned 362 pm criticism of protesters disgraceful crean 363 pm defends criticism of anti war protesters Name: headline_text, dtype: object
然后,使用软聚类成员资格分数来找到一些点,这些点可能属于这两个聚类。根据软聚类得分,确定每个点的前两个聚类。通过过滤簇 7 和簇 10 的软成员资格排除异常值,这两个成员资格都按比例大于其他簇的成员资格:
df2 = pd.DataFrame(soft_clusters.argsort()[:,::-1][:,:2]) df2["sum"] = soft_clusters.sum(axis=1) df2["cluster_7_ratio"] = soft_clusters[:,7] / df2["sum"] df2["cluster_10_ratio"] = soft_clusters[:,10] / df2["sum"] df2[(df2[0] == 7) & (df2[1] == 10) & (df2["cluster_7_ratio"] > 0.1) & (df2["cluster_10_ratio"] > 0.1)] 3824 7 10 0.630313 0.170000 0.160453 6405 7 10 0.695286 0.260162 0.119036
检查这些要点的标题,注意它们都是关于印度尼西亚的,这也在第 7 组标题 678 (上图)中。还要注意,这两个标题都是关于反战与和平的,这是 10 组标题中的几个主题。
df[:N_HEADLINES].iloc[3824] publish_date 20030309 headline_text indonesians stage mass prayer against war in iraq Name: 3824, dtype: object df[:N_HEADLINES].iloc[6405] publish_date 20030322 headline_text anti war fury sweeps indonesia Name: 6405, dtype: object
为什么软集群很重要
您应该有多自信这些结果属于他们分配的集群,而不是另一个集群?如前所述,一些集群包含标题,这些标题有可能位于不同的集群中。
置信度可以通过计算每个点的前两个聚类的成员概率之间的差异来部分量化,如 HDBSCAN 文档中所述。本例排除了噪声点,以说明这不仅发生在“噪声”点上,还发生在那些分配的簇标签上:
soft_non_noise = soft_clusters[clusterer.labels_ != -1] probs_top2_non_noise = np.take_along_axis(soft_non_noise, soft_non_noise.argsort(), axis=1)[:, -2:] diffs = np.diff(probs_top2_non_noise).ravel()
绘制直方图和这些差异的经验累积分布函数表明,许多点接近于被分配不同的聚类标签。事实上,大约 30% 的点的前两个聚类成员概率在 0.2 以内(图 1 )。
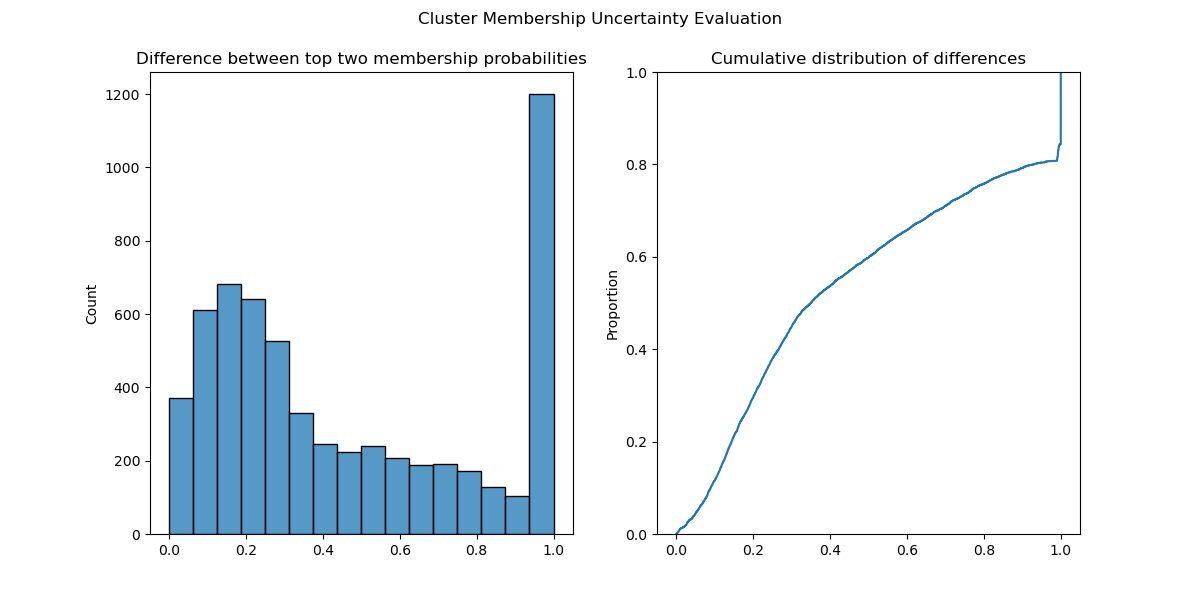 图 1. 数据集的每个点的前两个聚类的成员概率之间的差异的直方图和经验累积分布函数( ecdf )
图 1. 数据集的每个点的前两个聚类的成员概率之间的差异的直方图和经验累积分布函数( ecdf )
使用这些软聚类概率,您可以将这种不确定性结合起来,构建更加健壮的机器学习管道和应用程序。
绩效基准结果
接下来,在不同数量的新闻文章标题上运行前面的核心工作负载,从 25000 行到 400000 行不等。注意, HDBSCAN 参数可以针对更大的数据集进行调整。
在本例中, CPU 基准测试在 3.40 GHz 的 x86 Intel Xeon Gold 6128 CPU 上运行。 GPU 基准测试记录在 NVIDIA Quadro RTX 8000 上,内存为 48 GB 。
在 CPU (由 hdbscan 后端表示)上,软集群性能随着文档数量的增加而松散地线性扩展。 50000 份文件耗时 50 秒; 100000 份文件耗时 500 秒; 200000 份文件耗时 5500 秒( 1.5 小时); 40 万份文件耗时 6 万秒( 17 小时)。详见表 1 。
使用 cuML 中的 GPU 加速软聚类, 40 万个文档的软聚类可以在不到 2 秒的时间内计算,而不是 17 小时。
| Backend | Number of Rows | Soft Clustering Time (s) |
| cuml | 25,000 | 0.008182 |
| hdbscan | 25,000 | 5.795254 |
| cuml | 50,000 | 0.014839 |
| hdbscan | 50,000 | 53.847145 |
| cuml | 100,000 | 0.077507 |
| hdbscan | 100,000 | 485.847746 |
| cuml | 200,000 | 0.322825 |
| hdbscan | 200,000 | 5503.697239 |
| cuml | 400,000 | 1.343359 |
| hdbscan | 400,000 | 62428.348942 |
表 1 。使用 cuML 和 CPU 后端运行 HDBSCAN all_points_membership_vectors所用的时间
如果您想在系统上运行此基准测试,请使用 benchmark-membership-vectors.py GitHub 要点。请注意,性能将根据所使用的 CPU 和 GPU 而变化。
关键要点
我们很高兴报告这些业绩。软聚类可以有意义地改进机器学习支持的工作流。到目前为止,使用 HDBSCAN 这样的集群技术在计算上对几十万条记录都具有挑战性。
随着 HDBSCAN 软聚类的加入, RAPIDS 和 cuML 继续突破障碍,使最先进的计算技术在规模上更易于使用。
要开始使用 cuML ,请访问 RAPIDS 入门页面,其中提供了 conda 包、 pip 包和 Docker 容器。 cuML 也可以在 NVIDIA NGC 上的 NVIDIA optimized PyTorch 和 Tensorflow Docker 容器中使用,这使得端到端工作流更加简单。
致谢
这篇文章描述了 Tarang Jain 在 Corey Nolet 指导下在 NVIDIA 实习期间提供的 cuML 功能。
-
NVIDIA
+关注
关注
14文章
4983浏览量
103008 -
AI
+关注
关注
87文章
30805浏览量
268942
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论