 在NVSHMEM中新的通信方法介绍
在NVSHMEM中新的通信方法介绍
今天的前沿 高性能计算 ( HPC )系统包含数以万计的 GPU 。在 NVIDIA 系统中, GPU 通过 NVLink 扩展互连在节点上连接,并通过 InfiniBand 等扩展网络跨节点连接。 GPU 用于并行通信、共享工作和高效运行的软件库统称为 NVIDIA Magnum IO ,是用于并行、异步和智能数据中心 IO 的架构。
对于许多应用,扩展到这样的大型系统需要 GPU 之间的细粒度通信的高效率。这对于以强伸缩性为目标的工作负载尤其重要,因为在工作负载中添加了计算资源以减少解决给定问题的时间。
NVIDIA Magnum IO NVSHMEM 是一个基于 OpenSHMEM 规范的通信库,它为 HPC 系统中所有 GPU 的存储器提供分区全局地址空间( PGAS )数据访问模型。
由于该库支持 GPU 集成通信,因此对于以强扩展为目标的工作负载而言,它是一个特别适合且高效的工具。在这个模型中,数据是通过单边读、写和原子更新通信例程访问的。
由于与 GPU 架构紧密集成,该通信模型通过 NVLink 实现了细粒度数据访问的高效率。然而,由于主机 CPU 需要管理通信操作,因此节点间数据访问的高效率仍然是一个挑战。
本文在 NVSHMEM 中介绍了一种新的通信方法,称为 InfiniBand GPUDirect 异步( IBGDA ) ,它建立在 GPUDirect Async 系列技术之上。 IBGDA 在 NVSHMEM 2.6.0 中引入,并在 NVSHMEM 2.7.0 和 2.8.0 中进行了显著改进。它使 GPU 在发出节点间 NVSHMEM 通信时绕过 CPU ,而不会对现有应用程序进行任何更改。如我们所示,这将显著提高使用 NVSHMEM 的应用程序的吞吐量和扩展能力。
代理启动的通信
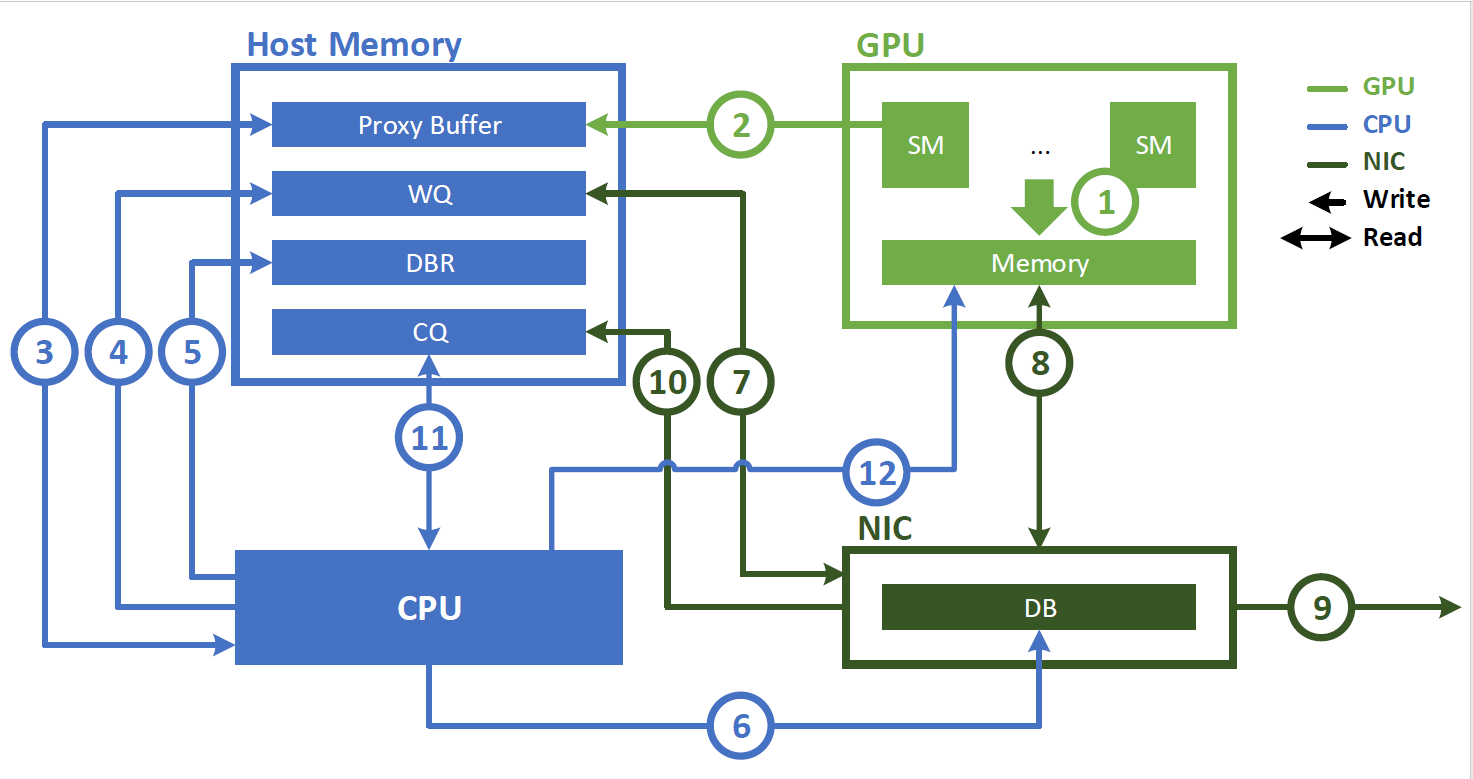 图 1 .使用 CPU 代理启动 NIC 通信的 GPU 通信会导致通信瓶颈
图 1 .使用 CPU 代理启动 NIC 通信的 GPU 通信会导致通信瓶颈
使用 NVLink 进行节点内通信可以通过 GPU 流式多处理器( SM )启动的加载和存储指令实现。然而,节点间通信涉及向网络接口控制器( NIC )提交工作请求以执行异步数据传输操作。
在引入 IBGDA 之前, NVSHMEM InfiniBand Reliable Connection ( IBRC )传输使用 CPU 上的代理线程来管理通信(图 1 )。使用代理线程时, NVSHMEM 执行以下操作序列:
应用程序启动 CUDA 内核,在 GPU 内存中生成数据。
应用程序调用 NVSHMEM 操作(例如nvshmem_put)以与另一个处理元件( PE )通信。当执行细粒度或重叠通信时,可以在 CUDA 内核内调用此操作。 NVSHMEM 操作将工作描述符写入主机内存中的代理缓冲区。
NVSHMEM 代理线程检测工作描述符并启动相应的网络操作。
以下步骤描述了与 NVIDIA InfiniBand 主机通道适配器( HCA )(如 ConnectX-6 HCA )交互时代理线程执行的操作顺序:
CPU 创建一个工作描述符,并将其排入工作队列( WQ )缓冲区,该缓冲区位于主机内存中。
此描述符指示请求的操作(如 RDMA 写入),并包含源地址、目标地址、大小和其他必要的网络信息。
CPU 更新主机内存中的门铃记录( DBR )缓冲区。此缓冲区用于恢复路径,以防 NIC 将写入数据丢弃到其门铃( DB )。
CPU 通过向其 DB ( NIC 硬件中的寄存器)写入来通知 NIC 。
NIC 从 WQ 缓冲区读取工作描述符。
NIC 使用 GPUDirect RDMA 直接从 GPU 内存复制数据。
NIC 将数据传输到远程节点。
NIC 通过将事件写入主机存储器上的完成队列( CQ )缓冲区来指示网络操作已完成。
CPU 轮询 CQ 缓冲器以检测网络操作的完成。
CPU 通知 GPU 操作已完成。如果存在 GDRCopy ,则直接将通知标志写入 GPU 存储器。否则,它会将该标志写入代理缓冲区。 GPU 在相应的存储器上轮询工作请求的状态。
虽然这种方法是便携式的,可以为批量数据传输提供高带宽,但它有两个主要缺点:
CPU 周期被代理线程连续消耗。
由于代理线程存在瓶颈,您无法达到细粒度传输的 NIC 吞吐量峰值。现代 NIC 每秒可以处理数以亿计的通信请求。虽然 GPU 可以以这种速度生成请求,但 CPU 代理的处理速度要低几个数量级,这为细粒度通信模式造成了瓶颈。
InfiniBand GPUDirect 异步
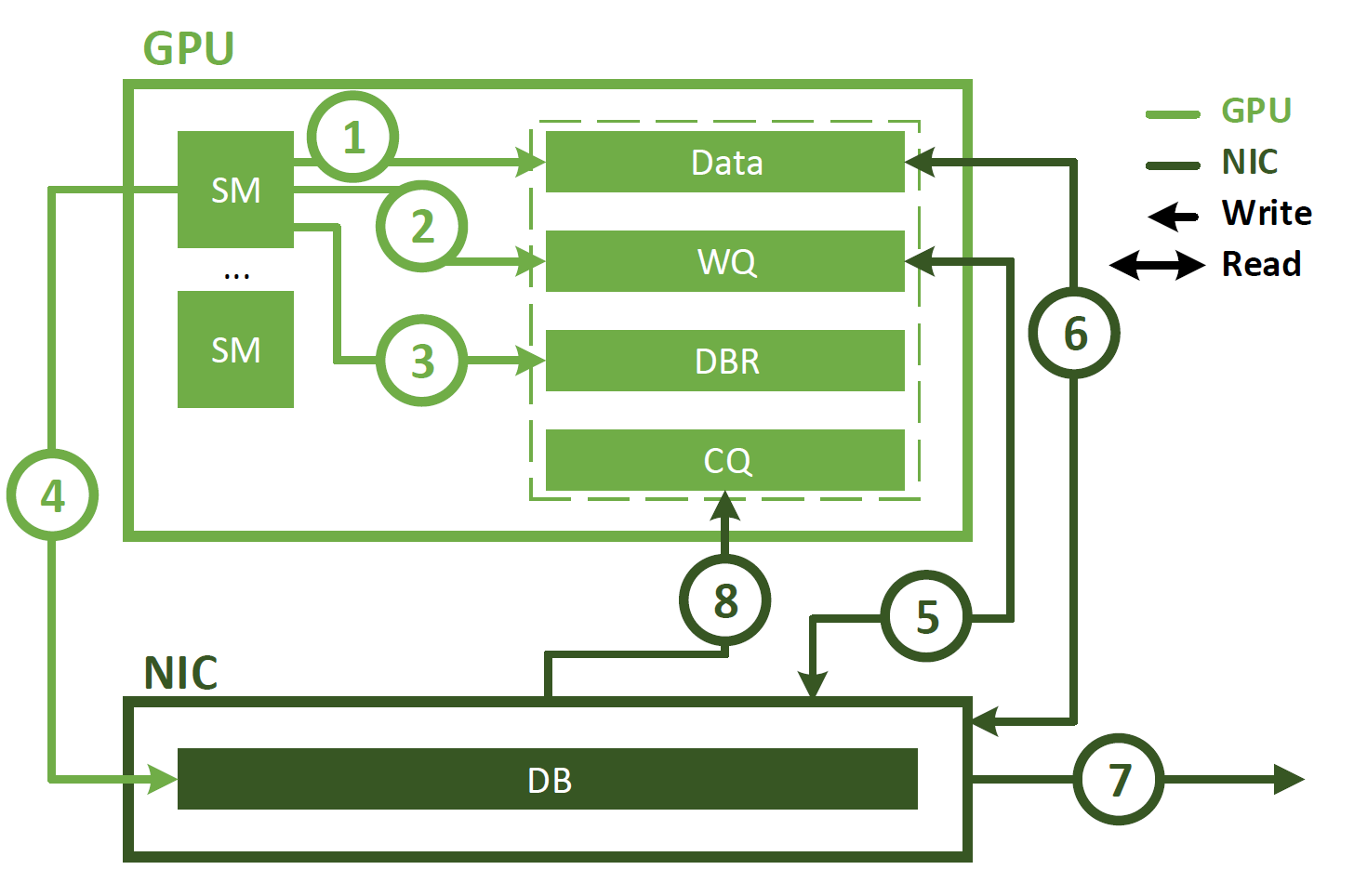 图 2 .使用 IBGDA 的 GPU 通信启用从 GPU SM 到 NIC 的直接控制路径,并从关键路径中删除 CPU
图 2 .使用 IBGDA 的 GPU 通信启用从 GPU SM 到 NIC 的直接控制路径,并从关键路径中删除 CPU
与代理启动的通信不同, IBGDA 使用 GPUDirect Async – Kernel initiated ( GPUDirectAsync – KI )使 GPU SM 能够直接与 NIC 交互。这如图 2 所示,涉及以下步骤。
应用程序启动 CUDA 内核,在 GPU 内存中生成数据。
应用程序调用 NVSHMEM 操作(如nvshmem_put)以与另一个 PE 通信。 NVSHMEM 操作使用 SM 创建 NIC 工作描述符,并将其直接写入 WQ 缓冲区。与 CPU 代理方法不同,此 WQ 缓冲区驻留在 GPU 内存中。
SM 更新 DBR 缓冲区,该缓冲区也位于 GPU 存储器中。
SM 通过写入 NIC 的 DB 寄存器来通知 NIC 。
NIC 使用 GPUDirect RDMA 读取 WQ 缓冲区中的工作描述符。
NIC 使用 GPUDirect RDMA 读取 GPU 内存中的数据。
NIC 将数据传输到远程节点。
NIC 通过使用 GPUDirect RDMA 写入 CQ 缓冲区来通知 GPU 网络操作已完成。
如图所示, IBGDA 从通信控制路径中消除了 CPU 。使用 IBGDA 时, GPU 和 NIC 直接交换通信所需的信息。 WQ 和 DBR 缓冲区也移动到 GPU 存储器,以提高 SM 访问时的效率,同时保留 NIC 通过 GPUDirect RDMA 的访问。
Magnum IO NVSHMEM 评估
我们比较了 NVSHMEMIBGDA 传输和 NVSHMEMIBRC 传输的性能,后者使用代理线程来管理通信。这两种传输都是标准 NVSHMEM 分发的一部分。所有基准测试和案例研究均在通过 NVIDIA ConnectX-6 200 Gb / s InfiniBand 网络和 NVIDIA Quantum HDR 交换机连接的四台 DGX-A100 服务器上运行。
为了突出 IBGDA 的效果,我们禁用了通过 NVLink 的通信。即使 PE 位于同一节点上,这也会强制通过 InfiniBand 网络执行所有传输。
单面输入带宽
我们首先运行了shmem_put_bw基准测试,该测试包含在 NVSHMEM 性能测试套件中,并使用nvshmem_double_put_nbi_block发布数据传输。该测试测量使用单边写入操作在一系列通信参数上传输固定数量的总数据时所获得的带宽。
对于节点间传输,此操作在执行网络通信时使用线程块中的一个线程,而不管线程块中有多少线程。这是已知的,也称为协作线程阵列( CTA )。在不同的 DGX-A100 节点上启动了两个 PE 。设置为每个线程块一个线程,每个线程块有一个 QP ( NIC 队列对,包含 WQ 和 CQ )。
 图 3 shmem_put_bwIBRC 显示了当您扩展到更多的 QP 和 CTA 时, CPU 代理对小消息大小造成的带宽上限
图 3 shmem_put_bwIBRC 显示了当您扩展到更多的 QP 和 CTA 时, CPU 代理对小消息大小造成的带宽上限
图 4 shmem_put_bw IBGDA 证明,随着 CTA 和 QPs 数量的增加,小消息大小的带宽可以扩展
图 3 和图 4 显示了在不同数量的 CTA 和消息大小下,具有 IBRC 和 IBGDA 的shmem_put_bw的带宽。如图所示,对于具有大消息的粗粒度通信, IBGDA 和 IBRC 都可以达到峰值带宽。当应用程序发出来自至少四个 CTA 的通信时, IBRC 可以用小到 16KiB 的消息使网络饱和。
进一步增加 CTA 的数量不会减少我们观察到峰值带宽时的最小消息大小。限制较小消息带宽的瓶颈在 CPU 代理线程中。虽然这里没有显示,但我们也尝试增加 CPU 代理线程的数量,并观察到类似的行为。
通过消除代理瓶颈,当 64 个 CTA 发出通信时, IBGDA 实现了峰值带宽,消息小到 2 KiB 。这一结果突出了 IBGDA 支持更高级别通信并行性的能力以及由此带来的性能改进。
对于 IBRC 和 IBGDA ,每个 CTA 中只有一个线程参与网络操作。换句话说,只需要 64 个线程(而不是 1024 × 64 个线程)就可以在 2 KiB 消息大小下实现峰值带宽。
还表明, IBGDA 带宽继续随着执行通信的 CTA 的数量而扩展,而 IBRC 代理在四个 CTA 时达到其扩展极限。因此, IBGDA 为消息大小小于 1 KiB 的 NVSHMEM 块放入操作提供了高达 9.5 倍的吞吐量。
提高小邮件的吞吐量
shmem_p_bw基准使用标量nvshmem_double_p操作将数据直接从 GPU 寄存器发送到远程 PE 。此操作是线程范围的,这意味着调用此操作的每个线程都传输一个 8 字节的数据字。
在接下来的实验中,我们为每个 CTA 启动了 1024 个线程,并增加了 CTA 的数量,同时保持 QPs 的数量与 CTA 的数目相等。
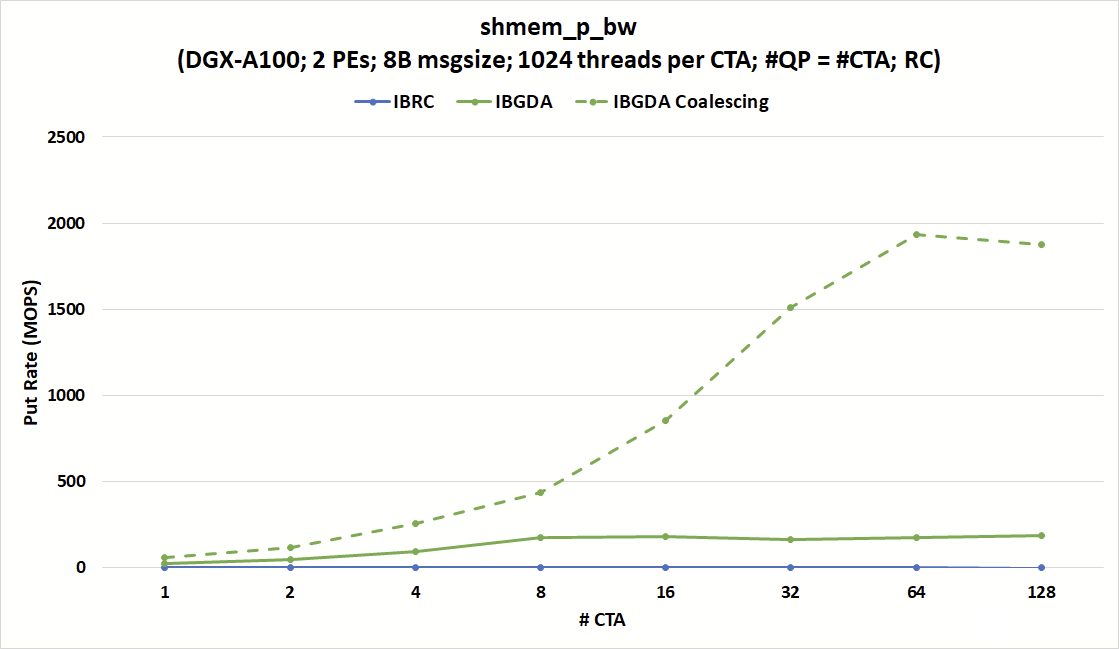 图 5 .国际复兴开发银行和国际银行发展局之间的卖出率比较 shmem_p_bw 显示了 IBGDA 在每秒发送数百万条小消息方面的性能优势
图 5 .国际复兴开发银行和国际银行发展局之间的卖出率比较 shmem_p_bw 显示了 IBGDA 在每秒发送数百万条小消息方面的性能优势
另一方面, IBGDA 的 put 速率可以达到 180 MOPS ,接近 215 MOPS 的峰值 NIC 消息速率限制。该图还显示,如果满足聚结条件, IBGDA 可以达到几乎 2000 MOPS 。
图 5 显示,无论 CTA 和 QP 的数量如何, IBRC 的投入率(单位:百万次操作/秒( MOPS ))上限为 1.7 MOPS 左右。另一方面, IBGDA 的消息速率随着 CTA 的数量而增加,接近 NVIDIA ConnectX-6 InfiniBand NIC 的 215 MOPS 硬件限制,只有 8 个 CTA 。
在该配置中, IBGDA 会根据nvshmem_double_p操作向 NIC 发出一个工作请求。这突出了 IBGDA 在涉及大量小消息的细粒度通信中的优势。
IBGDA 还提供了当目标地址在同一扭曲内连续时的自动数据合并。此功能允许发送一条大消息,而不是 32 条小消息。对于希望将分散的数据直接从 GPU 寄存器传输到目的地的连续缓冲区的应用程序来说,它非常有用。
图 5 显示了当满足数据合并条件时, put 速率可以达到超过 NIC 峰值消息速率。
Jacobi 方法案例研究
分析了 NVSHMEM Jacobi 基准 的性能,以证明 IBGDA 在实际应用中的性能与 IBRC 相比。该存储库包括 Jacobi 解算器的两个 NVSHMEM 实现。
在第一个实现中,每个线程使用标量nvshmem_p操作在数据可用时立即发送数据。众所周知,该实现与 NVLink 配合使用效果良好,但与 IBRC 配合使用效果不佳。
第二种实现在每个 CTA 调用nvshmem_put_nbi_block以发起通信之前将数据聚合到连续的 GPU 缓冲器中。这种数据聚合技术与 IBRC 配合使用很好,但增加了 NVLink 上的开销,其中nvshmem_p操作可以将数据从寄存器直接存储到远程 PE 的缓冲区。这种不匹配突出了优化给定代码以实现放大和缩小时的一个挑战。
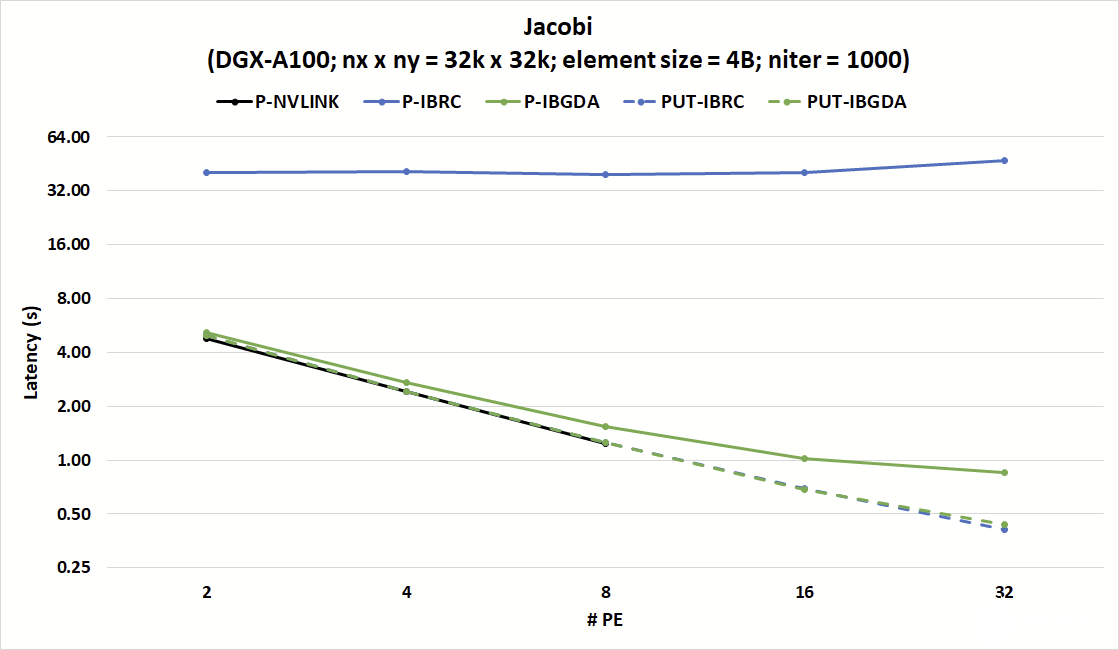 图 6 .使用 P 和 PUT 以及 IBRC 和 IBGDA 的 Jacobi 实现的延迟比较
图 6 .使用 P 和 PUT 以及 IBRC 和 IBGDA 的 Jacobi 实现的延迟比较
图 6 显示, IBGDA 对小消息通信效率的改进有助于解决这些挑战。该图表显示了强缩放实验中 Jacobi 内核 1000 次迭代的延迟,其中 PE 的数量增加,同时保持固定的矩阵大小。使用 IBRC ,nvshmem_p版本的 Jacobi 的延迟是 nvshmem _ put 版本的 8 倍多。
另一方面,nvshmem_p和nvshmem_put版本均与 IBGDA 兼容,并与 NVLink 上nvshmem_p的效率相匹配。 IBGDA nvshmem_p版本与nvshmem_put与 IBRC 的延迟相匹配。
结果表明,与nvshmem_put相比,具有 IBGDA 的nvshmem_p具有略高的延迟。这是因为与发送许多小消息相比,发送一条大消息会导致较低的网络开销。
虽然这些开销是网络的基础,但 IBGDA 可以通过并行向 NIC 提交许多小消息传输请求来使应用程序隐藏这些开销。
全对全延迟案例研究
图 7.IBRC 和 IBGDA 之间 32 PE All to All 传输的延迟比较
图 7 显示了 IBRC 和 IBGDA 的 NVSHMEM 所有对所有集合操作的延迟,突出了 IBGDA 在小消息性能方面的优势。
对于 IBRC ,代理线程是来自设备的所有操作的序列化点。代理线程成批处理请求以减少开销。然而,根据何时向设备提交操作,在设备上几乎同时提交的操作可能会由代理线程的单独循环处理。
代理的操作串行化会产生额外的延迟,并掩盖 NIC 和 GPU 的内部并行性。 IBGDA 结果显示总体延迟更为一致,尤其是对于小于 16KiB 的消息。
Magnum IO NVSHMEM 提高了网络性能
在本博客中,我们展示了 Magnum IO 如何提高小消息网络性能,尤其是对于部署在 HPC 数据中心数百或数千个节点上的大型应用程序。 NVSHMEM 2.6.0 引入了 InfiniBand GPUDirect Async ,它使 GPU 的 SM 能够直接向 NIC 提交通信请求,绕过 CPU 在 NVIDIA InfiniBand 网络上进行网络通信。
与管理通信的代理方法相比, IBGDA 可以在更小的消息大小下保持显著更高的吞吐量。这些性能改进对于需要强大扩展性的应用程序尤其重要,并且随着工作负载扩展到更大数量的 GPU ,消息大小往往会缩小。
IBGDA 还缩小了 NVLink 和网络通信之间的小消息吞吐量差距,使您更容易优化代码,以在当今 GPU 加速的 HPC 系统上进行扩展和扩展。
-
NVIDIA
+关注
关注
14文章
4984浏览量
103016 -
AI
+关注
关注
87文章
30813浏览量
268958
发布评论请先 登录
相关推荐
在模版工程中新建了一个目录components,在这个目录中新建了.c和.h文件文件中有包含idf的库文件,为什么找不到?
在PADS9.3中新建元件封装问题
怎样在STM32cubeIDE中新建一个带hal库的空工程呢
介绍一种多串口通信编程方法
在Keil中新建项目的方法
ORCAD PSPICE 9中新元件的创建方法

ORCAD/PSPICE 9中新元件的创建






 工商网监
工商网监
评论