 借助 NVIDIA Spectrum 以太网最大限度地提高存储网络性能
借助 NVIDIA Spectrum 以太网最大限度地提高存储网络性能
随着数据生成的不断增加,线性性能扩展已成为横向扩展存储的绝对要求。存储网络就像汽车道路系统:如果道路不是为速度而建造的,那么汽车的潜在速度就无关紧要了。即使是法拉利在充满障碍的非铺装的土路上也会很慢。
连接存储节点的以太网网络架构可能会阻碍横向扩展存储性能。NVIDIA 加速以太网可以消除性能瓶颈,从而为一般应用程序,特别是 AI/ML 实现最高的存储性能。
横向扩展存储需要强大的网络
全球每秒有 54000 张照片被拍摄。当您阅读本文时,这一数字将会更高。无论您的业务是什么,您都有可能拥有大量需要存储和分析的数据,而且数据量每天都在增长。
以前使用越来越大的存储文件服务器的纵向扩展方法已被横向扩展方法所取代,以提供在容量和性能方面线性扩展的存储。
借助横向扩展存储或分布式存储,可以配置和连接多个较小的节点,使其成为一个逻辑单元。单个文件或对象可以分布在多个节点上。
当需要更大的规模时,可以轻松添加额外的存储节点,以提高存储容量和性能。这既适用于传统的企业存储供应商解决方案,也适用于软件和硬件独立采购的软件定义解决方案。
分布式存储实现了灵活的扩展和成本效益,但需要高性能网络来连接存储节点。许多数据中心交换机不适合存储的独特流量特性,实际上可能会削弱横向扩展存储解决方案的性能。
存储流量与传统流量的区别
对于许多用例来说,网络流量是一致且同构的,传统以太网就足够了。但是,存储设备生成的流量可能会导致以下详述问题。
01
网络压力
当前的存储解决方案受益于更快的 SSD 和存储接口,如 NVMe 和 PCIe Gen 4(即将推出 PCIe Gen 5),旨在提供更高的性能。02
拥塞
当存储网络架构饱和时,网络拥塞就不可避免,就像高速公路上交通量过多时造成道路拥堵一样。网络拥塞对于横向扩展存储来说尤其成问题,因为每个存储节点都需要提供快速的数据传输。但当出现拥塞时,许多数据中心交换机都存在公平问题,其中一些节点的速度会比其他节点慢得多。单个文件或对象通常分布在多个节点上,因此任何降低单个节点速度的操作都会有效地降低整个集群的速度。03
突发流量
大多数存储工作负载都是突发的,会产生密集的数据传输,并在短时间内反复需要大量带宽。当这种情况发生时,网络交换机必须使用其缓冲区来吸收突发,直到瞬时突发结束,从而防止数据包丢失。否则,数据包丢失将需要重新传输数据,从而显著降低应用程序性能。04
存储巨型帧
传统的数据中心网络流量使用的最大数据包大小( MTU)为 1.5KB。当横向扩展存储节点可以使用 9KB 的“巨型帧”时,它们的性能会更好,这样可以在提高吞吐量的同时降低 CPU 处理开销。许多使用商用交换机 ASIC 构建的数据中心交换机在处理巨型帧时表现不佳或不可预测。05
低延迟
提高存储 IOP 的方法之一是通过为基于闪存介质中的读/写操作实现几个数量级延迟降低。然而,当网络引入高延迟时,尤其是由于过度缓冲,这些昂贵的性能改进可能会丢失。
训练和推理都需要足够的数据量和高速访问,以确保 GPU 处理器足够快地输入数据,使其保持被充分使用。在训练期间,所有节点都会执行写操作,以提高模型的准确性。这导致了突发,使得交换机必须有效地处理拥塞。最后,较低的存储延迟使 GPU 能够更有效地处理计算任务。
为什么 ASIC 不适合存储流量
大多数数据中心交换机都是使用商用交换机 ASIC 构建的,这些 ASIC 针对传统的数据流量模式和数据包大小进行了成本优化。为了在实现带宽目标的同时保持低成本,以太网交换机芯片供应商通过使用分离缓冲区架构,这牺牲了公平性。
每个交换机都有一个缓冲区,用于吸收流量突发,并在发生拥塞时防止数据包丢失。常见的方法是拥有一个跨多个端口共享的缓冲区。然而,并非所有共享缓冲区都是相同的——存在不同的缓冲区架构。
商用交换机没有完全共享的缓冲区,而是使用入口共享缓冲区或出口共享缓冲区。
对于入口共享缓冲区,在一组传入端口和特定内存切片之间存在静态映射。这些端口只能使用分配切片中的内存,而不能使用整个缓冲区,即使缓冲区的其余部分可用并且没有人在使用它。
对于出口共享缓冲区,在一组输出端口和特定缓冲区内存切片之间进行映射。同样,每组出口只能使用其分配的缓冲区切片,而不能使用整个缓冲区。
对于这两种体系结构,保持在同一内存切片中的流与在内存切片之间传输的流存在行为的不同。如果许多流使用具有相同缓冲区的端口,那么这些端口将面临更高的延迟和更低的吞吐量,而使用缓冲区其他切片的流量将享受更高的性能。
存储性能取决于存储流量(和其他流量)使用的端口以及这些端口缓冲区切片的繁忙程度。这就是为什么使用分离缓冲区的交换机经常遇到公平性、可预测性和微突发吸收相关的问题。
为什么深度缓冲区交换机
在存储方面未得到优化
深度缓冲区交换机通常指的是提供更多缓冲区(GB 而不是 MB)的交换机。深度缓冲区交换机通常被推广用作路由器,因为如果网络速度不匹配或出现多对一通信情况,它们可以吸收并保持大量流量突发。
但在大多数数据中心应用程序(包括横向扩展存储)中,深度缓冲区交换机会对性能产生负面影响,原因如下:
01
作业完成时间
对于并行文件系统,响应速度最慢的存储节点决定了获取文件所需的时间。与具有切片的片上缓冲区的商用交换机 ASIC 不同,深度缓冲区交换机同时具有片上和片外缓冲区,并且它们都是切片的,而非完全共享的缓冲区。
想象一下,在流离开交换机之前,有多少种流进入交换机的方式。它们可以保持在一个片上内存切片内(速度最快),在片上内存切片间传输(速度较慢),或在片上和片外内存切片间传输(速度非常慢)。
所有这些流的行为都会有所不同,因此会导致存储流量的公平性和可预测性问题。由于这些问题会降低一个或多个节点的速度,因此会对作业完成时间产生负面影响,并降低整个分布式存储集群的速度。
02
延迟
交换机缓冲区越大,每个数据包必须经过的队列就越长,延迟也就越大。深度缓冲区交换机的测试平均端口到端口延迟超过 500 微秒。与同代的完全共享缓冲区交换机相比,NVIDIA Spectrum 1 的延迟仅为 0.3 微秒。而交换/路由数据包需要的时间是纳秒而不是微秒。
深度缓冲区延迟高出 1000 倍。您可能想知道,这只是发生在拥塞的时候吗?不会。在拥塞的情况下,深度缓冲区的延迟会高得多;事实上,最高可达 20 毫秒,或高出 50000 倍。对于数据中心之间的路由器来说,500 微秒的延迟可能还可以,但在数据中心内,这意味着闪存存储性能的不可用。
03
功率和成本
深缓冲区交换机即使在空闲时也需要数百瓦的功率才能运行,这使得其持续的运营成本更高。深度缓冲区交换机的初始购买成本也高得多。如果性能更好,这可能是合理的,但实际测试证明恰恰相反。
选择不合适的网络交换机会严重拖慢存储工作负载,使昂贵的快速存储变得像更便宜、更慢的存储一样。
借助 NVIDIA Spectrum 可以降低资本支出和运营支出。节省的电力还可以用于机架内的其他用途。
NVIDIA Spectrum 交换机
针对存储进行了优化
使用商用交换 ASIC,流要么保持在同一个内存切片上,要么在内存切片之间流动。
借助 NVIDIA Spectrum 交换机,由于完全共享的缓冲区,所有流的行为都是相同的。这种架构的价值在于最大的突发吸收能力以及最佳的公平和可预测的性能。通过交换机的所有流都得到相同的处理,并且通常享有相同的良好性能,无论它们使用哪个入口和出口。
深度缓冲区交换机和
NVIDIA Spectrum 的基准测试
第一种情况使用一个通用的存储基准 FIO 工具,在后台流量运行时从两个发起端发送到一个目标端的写操作。这是一种典型的存储场景。
该团队测量了 FIO 工作完成所需的时间(越短越好)。使用深度缓冲区交换机,FIO 作业耗时 87 秒。使用 NVIDIA Spectrum 交换机,作业运行速度提高 40%,仅需 51 秒即可完成。
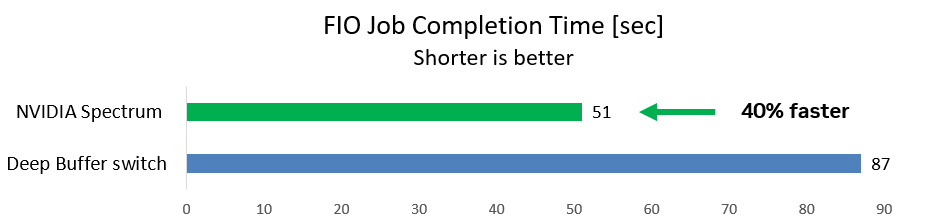
图 1:与深度缓冲区交换机相比,NVIDIA Spectrum 交换机的存储写入操作快 40%
深度缓冲区交换机大大增加了延迟,从而降低了存储速度并降低了应用程序性能。但是延迟能有多高?
对于第二种情况,该团队采用了深度缓冲区交换机,并测试了在不同的拥塞用例下延迟是如何受到影响的。最大缓冲区占用率仅为整个缓冲区大小的 10% 左右。
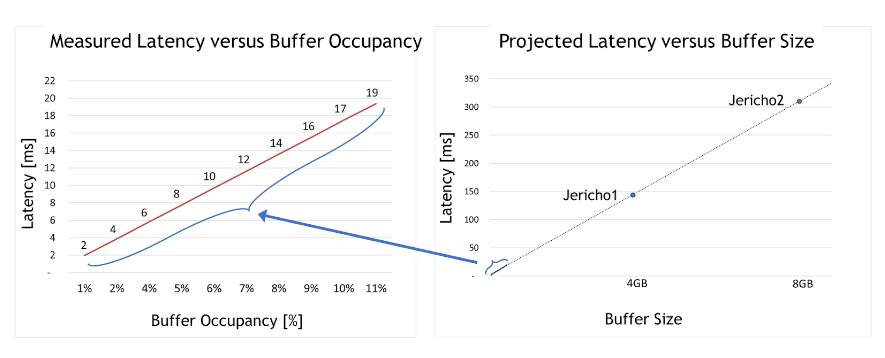
图 2:与缓冲区大小和缓冲区占用率相比的实际和预测延迟
从图 2 左侧的图表中可以得出两个有意义的见解。首先,深度缓冲区交换机延迟比 Spectrum 交换机高 50000 倍(2 – 19 毫秒,而 Spectrum 仅为 300 纳秒)。
其次,缓冲区占用率和延迟之间存在明显的线性相关性。换句话说,测试证明,占用的缓冲区越大,延迟就越大。
有了这一理解,图 2 右侧的图表显示了每个深度缓冲区 ASIC(如 Jericho 1 、Jericho 2 或 Ramon)的最大延迟。这些非常高的延迟数通常与数据中心应用程序不兼容,尤其与快速存储解决方案不兼容。
对于第三种情况,该团队使用了两台 Windows 计算机,并同时将每台计算机中的一个文件复制到同一目标存储中。
使用深度缓冲区交换机时,一台 Windows 计算机的带宽是另一台计算机的三倍( 830MBps 与 290MBps 相比)。使用 Spectrum 交换机时,每台计算机的带宽均为 584 MBps(如预期的 50%)。
实际测试表明,深度缓冲区交换机对数据中心应用程序(如吸收数据包和防止数据丢失)没有积极影响。
长距离或广域网连接可能需要深度缓冲区交换机;然而,它们对于数据中心应用程序来说不是理想选择,并且会产生负面影响,特别是当工作负载扩展到仅两个节点之外时,如本用例中所示。

图 3 :深度缓冲区交换机为每个节点提供了不公平的带宽(左图),而 NVIDIA Spectrum 交换机提供了相等的带宽(右图)
这三个用例证明了为什么深度缓冲区交换机会对 AI/ML 和存储工作负载产生不利影响,而 Spectrum 交换机则提供了最大化的性能。
总结
NVIDIA Spectrum Ethernet switches 是专为 AI/ML 和存储工作负载而构建的,其性能优于具有分离缓冲区或深度缓冲区的交换机。它们可以更好地处理拥塞,防止数据包丢失,并且在处理巨型帧(首选存储)方面表现出色。NVIDIA Spectrum 以太网交换机可以提供良好的应用程序性能,网络延迟也较低。
扫描下方二维码,查看更多有关 NVIDIA Spectrum Ethernet switches 的信息。

更多精彩内容 使用 NVIDIA Spectrum-X 网络平台加速生成式 AI 工作负载
COMPUTEX2023 | NVIDIA 推出面向超大规模生成式 AI 的加速以太网平台
原文标题:借助 NVIDIA Spectrum 以太网最大限度地提高存储网络性能
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
22文章
3727浏览量
90754
原文标题:借助 NVIDIA Spectrum 以太网最大限度地提高存储网络性能
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
以太网速率对网络性能的影响
NVIDIA SuperNIC推进现代AI基础设施发展
NVIDIA 以太网加速 xAI 构建的全球最大 AI 超级计算机

最大限度地提高GSPS ADC中的SFDR性能:杂散源和Mitigat方法

浅析以太网的发展走势
NVIDIA Spectrum-X 以太网网络平台已被业界广泛使用
如何使用以太网交换机最大限度地减少网络延迟
最大程度提高对汽车以太网应用的ESD保护

NVIDIA全新AI以太网络平台大幅提升AI云性能
戴尔科技、慧与和联想即将推出 NVIDIA 全新 AI 以太网络平台
戴尔科技、慧与和联想即将推出 NVIDIA 全新 AI 以太网络平台






 工商网监
工商网监
评论