 Nvidia的H100:有趣的L2缓存和大量带宽
Nvidia的H100:有趣的L2缓存和大量带宽

GPU 最初是纯粹用于图形渲染的设备,但其高度并行的特性也使其对某些计算任务具有吸引力。随着过去几十年 GPU 计算场景的发展,Nvidia 进行了大量投资来占领计算市场。其中一部分涉及认识到计算任务与图形任务有不同的需求,并分散其 GPU 系列以更好地瞄准每个市场。
H100 是 Nvidia 面向计算的 GPU 系列的最新成员。它采用Hopper架构,并建立在一个巨大的814 mm2芯片上,使用台积电的4N工艺和800亿个晶体管。这个巨大的芯片实现了 144 个流式多处理器 (SM)、60 MB 的 L2 缓存和 12 个 512 位 HBM 内存控制器。我们正在 Lambda Cloud 上测试 H100 的 PCIe 版本,该版本支持 114 个 SM、50 MB 的 L2 缓存和 10 个 HBM2 内存控制器。该卡最多可消耗 350 W 的功率。
Nvidia 还提供了 SXM 外形 H100,其功耗高达 700W,并启用了 132 个 SM。SXM H100 还使用 HBM3 内存,提供额外的带宽来满足这些额外的着色器的需要。
关于时钟速度的简要说明
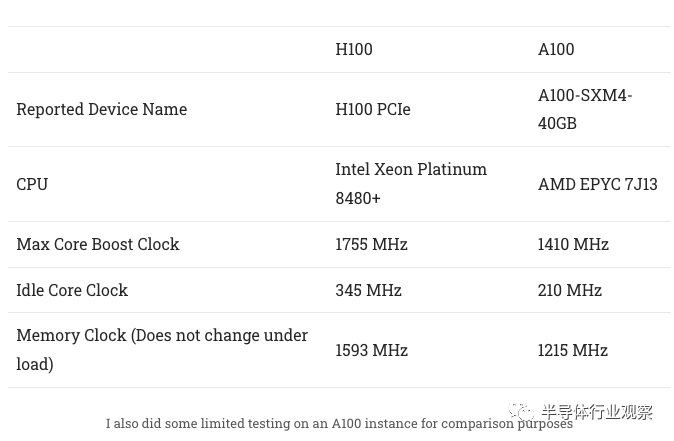
H100 具有比 A100 高得多的升压时钟。在进行微基准测试时,H100 有时会降至 1395 MHz,或者略低于其最大升压时钟的 80%。nvidia-smi 的其他指标表明我们可能会达到功率限制,特别是在从 L2 提取数据时。H100 PCIe 版本的功率限制为 350W,在带宽测试时正好符合这一要求。
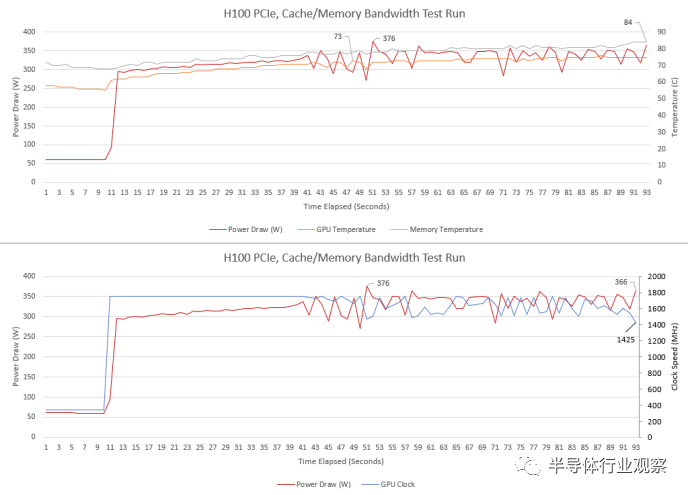
即使 GPU 功耗超过 300W,服务器冷却也能够使 H100 保持在非常低的温度。内存温度稍高一些,但仍在合理范围内。
A100 看到了不同的行为。核心时钟在负载下达到 1410 MHz 并保持不变。功耗也相当高,但 A100 的 SXM4 版本具有更高的 400W 功率限制。可能正因为如此,即使功耗超过 350W,我们也没有看到任何时钟速度下降。
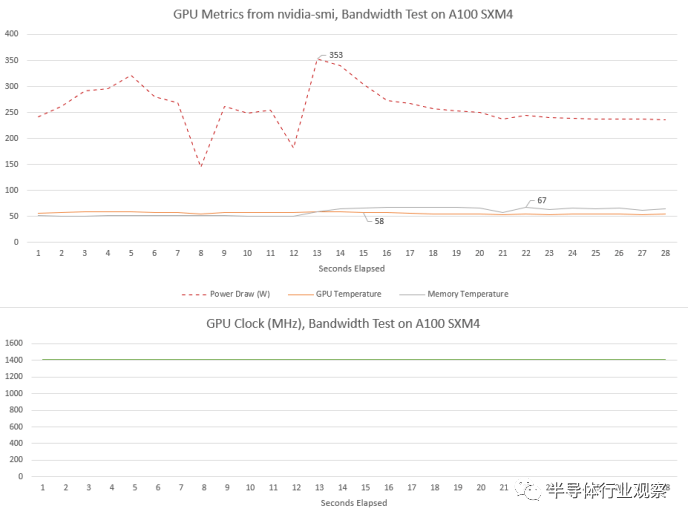
与 H100 一样,A100 的核心温度非常低。被动冷却卡似乎在气流充足的服务器机箱中蓬勃发展。A100的内存温度也比H100低。
缓存和内存设置
计算机几乎一直受到内存速度的限制。我们已经看到消费类 GPU 通过日益复杂的缓存设置来应对这一问题。AMD 的 RX 6900 XT 使用四级缓存层次结构,末级缓存容量为 128 MB,而 Nvidia 的 RTX 4090 将二级容量扩展至 72 MB。Nvidia 的计算 GPU 的缓存容量也有所增加,但策略略有不同。
流式多处理器 (SM) 是 Nvidia 的基本 GPU 构建块。Nvidia 在之前面向数据中心的 GPU 中一直强调 SM 私有缓存。对于大多数 Nvidia 架构,SM 具有私有内存块,可以在 L1 缓存和共享内存(软件管理暂存器)使用之间灵活分区。GK210 Kepler SM 具有 128 KB 的内存,而客户端实现的内存为 64 KB。A100 为 192 KB,而客户端 Ampere 为 128 KB。现在,H100 将 L1/共享内存容量提高到 256 KB。
我们可以使用 Nvidia 的专有 API 对 L1 缓存分配进行有限的测试。我们通常使用 OpenCL 或 Vulkan 进行测试,因为许多供应商支持这些 API,让测试无需修改即可在各种 GPU 上运行。但 CUDA 对 L1 和共享内存分割的控制有限。具体来说,我们可以要求 GPU 偏好 L1 缓存容量、偏好均等分割或偏好共享内存容量。请求更大的 L1 缓存分配不会带来任何延迟损失。
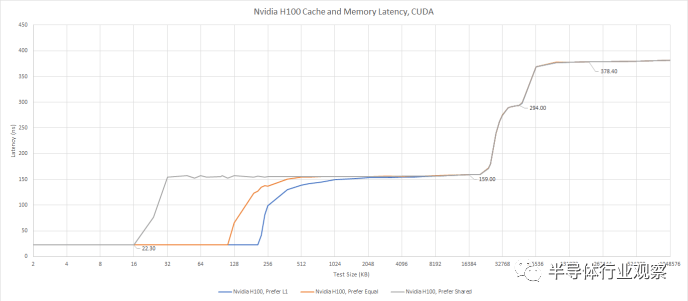
使用 CUDA 测试内存访问延迟,这让我们可以指定首选的 L1/共享内存分割。
当我们要求 CUDA 优先选择 L1 缓存容量时,我们看到 208 KB 的 L1 缓存。通过这种设置,H100 比任何其他 GPU 拥有更多的一级数据缓存能力。即使我们考虑到 AMD 使用单独内存进行缓存和暂存器的策略,H100 仍然领先。将 RDNA 3 的 L0 矢量缓存、标量缓存和 LDS(暂存器)容量加起来仅提供 208 KB 的存储空间,而 Hopper 上的存储空间为 256 KB。
相对于A100,H100的L1容量更高,延迟更低。这是一个值得欢迎的改进,并且在缓存层次结构中继续保持比 A100 稍好的趋势。
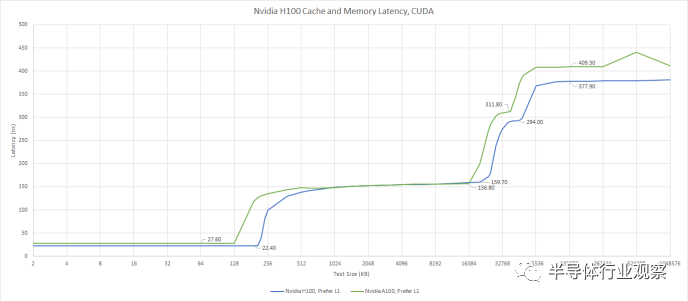
对于 L1 无法容纳的数据,H100 有 50 MB L2。当 A100 于 2020 年推出时,其 40 MB L2 为其提供了比当时任何 Nvidia GPU 更高的末级缓存容量。H100稍微增加了缓存容量,但今天没什么特别的。Nvidia 的 RTX 4090 具有 72 MB 的二级缓存,而 AMD 的高端 RDNA 2 和 RDNA 3 GPU 分别具有 128 MB 和 96 MB 的末级缓存。

Nvidia 白皮书中的 H100 框图,显示了两个 L2 分区以及它们之间的链接
H100还继承了A100的分离式L2配置。GPU 上运行的任何线程都可以访问全部 50 MB 缓存,但速度不同。访问“远”分区所需的时间几乎是原来的两倍。它的延迟大约与 RX 6900 XT 上的 VRAM 一样长,这使得它对带宽更有用,而不是让单个扭曲或波前更快完成。
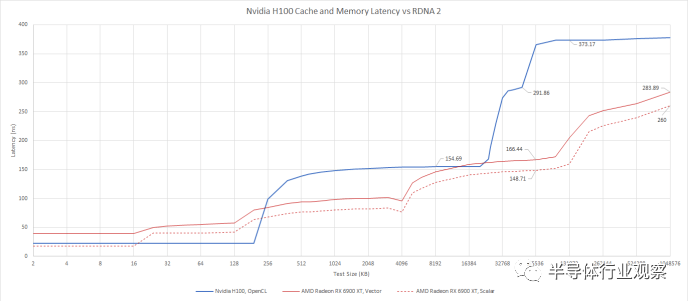
使用 OpenCL 与 AMD 的客户端 RDNA 2 架构进行比较
H100 的二级缓存感觉像是两级设置,而不是单级缓存。在 H100 上运行的线程可以比在 A100 上更快地访问“远”L2 缓存,因此 Nvidia 与上一代相比有所改进。在实现大型缓存方面,A100 是 Nvidia 的先驱,而 H100 的设置是 A100 的自然演变。但这并不是现代客户端 GPU 上使用的低延迟、高效的缓存设置。
在 VRAM 中,H100 的延迟比 A100 略低,与一些较旧的客户端 GPU 相当。例如,GTX 980 Ti 的 VRAM 延迟约为 354 ns。
不再有常量缓存?
Nvidia 长期以来一直使用单独的常量缓存层次结构,通常具有 2 KB 常量缓存,并由 32 至 64 KB 中级常量缓存支持。常量缓存提供非常低的延迟访问,但它是只读的并且由有限的内存空间支持。H100 以不同的方式处理常量内存。Nvidia 可以分配最多 64 KB 的恒定内存(这一限制可以追溯到 Tesla 架构),并且延迟在整个范围内是恒定的。
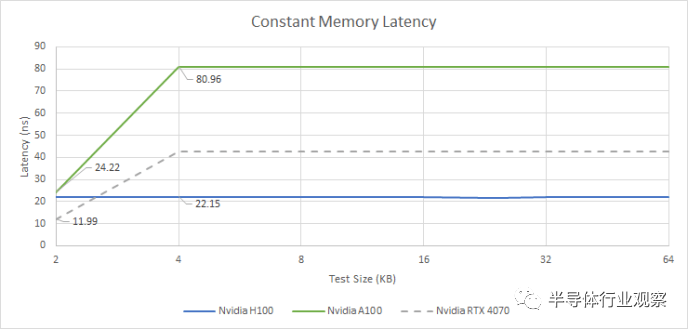
此外,延迟看起来与 L1 缓存延迟几乎相同。H100 可能使用 L1 数据缓存来保存常量数据。验证这个假设需要额外的测试,由于现实生活和日常工作的需求,我目前无法投入时间。但无论 Nvidia 做了什么,它都比 A100 的持续缓存有了明显的改进,并且全面降低了延迟。如果 Ada Lovelace 可以处理来自小型且快速的 2 KB 常量缓存的请求,那么它可以享受较低的延迟,但如果有大量常量数据,它也会落后。
本地内存延迟
如前所述,H100 的 SM 具有大块私有存储,可以在 L1 缓存和共享内存使用之间分配。共享内存是 Nvidia 的术语,指的是软件管理的暂存器,可提供始终如一的高性能。AMD 的等效项称为本地数据共享 (LDS)。在 Intel GPU 上,它称为共享本地内存 (SLM)。OpenCL 将此内存类型称为本地内存。
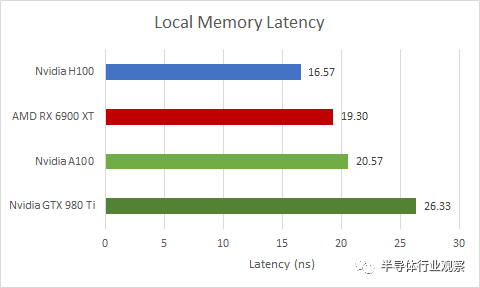
尽管 H100 从同一存储块中分配共享内存,但共享内存比 L1 缓存访问更快,因为它不需要标记比较和状态检查来确保命中。与各种 GPU 相比,H100 表现出色,尽管它可以比任何其他当前 GPU 分配更多的共享内存容量。
Atomics
共享内存(或本地内存)对于同步同一工作组内的线程也很有用。在这里,我们正在测试 OpenCL 的atomic_cmpxchg 函数,该函数会进行比较和交换操作,并保证在这些操作之间没有其他东西会触及其所使用的内存。
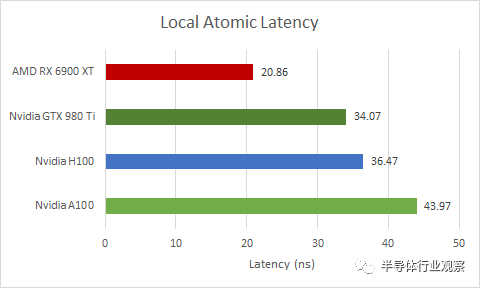
H100 在这种原子(Atomics)操作方面做得相当好,尽管它有点落后于消费级 GPU 的能力。令人惊讶的是,这也适用于以较低时钟运行的旧 GPU,例如 GTX 980 Ti。不过,H100 确实比 A100 做得更好。
如果我们在全局内存(即由 VRAM 支持的内存)上执行相同的操作,延迟会严重得多。它略高于 L2 延迟,因此 H100 可能正在 L2 缓存处处理跨 SM 同步。
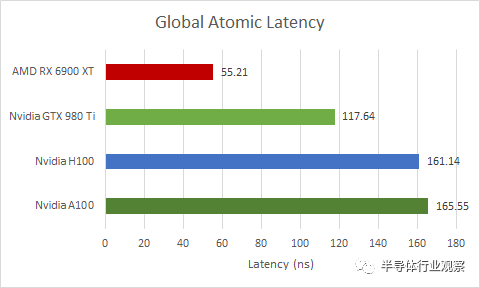
同样,H100 比 A100 略有改进,但与消费级 GPU 相比有所不足。但这一次,差距要大得多。RX 6900 XT 将 H100 和 A100 远远抛在了后面。旧版 GTX 980 Ti 的性能也好很多。我认为在巨大的 814 mm2或 826 mm2芯片上同步事物是相当具有挑战性的。
分布式共享内存
为了降低跨巨大芯片传输数据的成本,H100 具有一项称为分布式共享内存 (DSMEM) 的功能。使用此功能,应用程序可以将数据保存在 GPC 或 SM 集群中。与上述全局原子相比,这应该允许更低的延迟数据共享,同时能够在比工作组中容纳的更多线程之间共享数据。
测试此功能需要每小时支付 2 美元购买 H100 实例,同时学习新的 API,然后在没有其他 GPU 的情况下进行测试,以对结果进行健全性检查。即使在有利的条件下,编写、调试和验证测试通常也需要许多小时。Nvidia 声称 DSMEM通常比通过全局内存交换数据快 7 倍。
带宽
延迟只是问题的一部分。H100 等 GPU 专为极其并行的计算工作负载而设计,并且可能不必处理可用并行性较低的情况。这与消费类 GPU 形成鲜明对比,消费类 GPU 偶尔会面临较少的并行任务,例如几何处理或小型绘制调用。所以,H100强调的是海量带宽。从 L2 缓存开始,我们看到超过 5.5 TB/s 的读取带宽。我们测量了 RX 7900 XTX L2 的读取带宽约为 5.7 TB/s,因此 H100 获得了几乎相同的带宽量和更高的缓存容量。
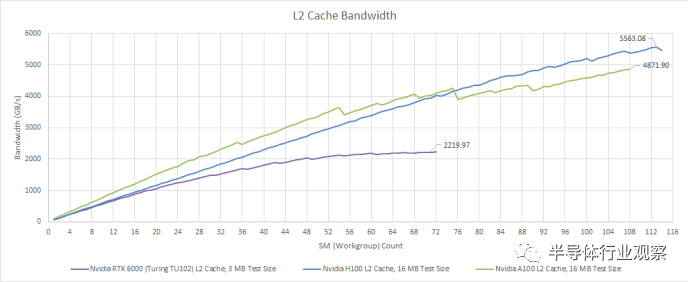
使用 OpenCL 进行测试
与 A100 相比,H100 的带宽提升虽小但很明显。但这仅适用于“近”L2 分区。如前所述,A100 和 H100 的 L2 并不是真正的单级缓存。如果我们超过“接近”L2 容量,带宽会明显变差。在访问整个 50 MB L2 时,H100 与 A100 相比也有所退步,为 3.8 TB/s,而 A100 为 4.5 TB/s。Nvidia 可能已经确定很少有工作负载在 A100 上受 L2 带宽限制,因此放弃一点跨分区 L2 带宽并不是什么大问题。
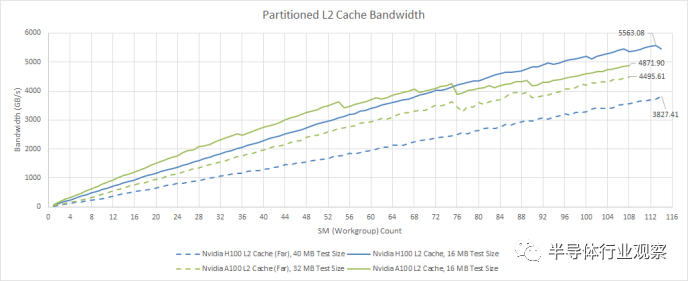
从绝对意义上讲,即使请求必须穿过缓存分区,H100 的 50 MB L2 仍然可以提供大量带宽。相比之下,RDNA 2 的无限缓存可提供约 2 TB/s 的带宽,而 RDNA 3 的无限缓存仅略低于 3 TB/s。因此,H100 提供的缓存容量比 AMD 高端客户端 GPU 上的无限缓存要少一些,但通过更高的带宽来弥补。
然而,我觉得 Nvidia 可以将一些客户端工程引入到面向计算的 GPU 中。他们的 RTX 4090 提供约 5 TB/s 的 L2 带宽,并具有更多的 L2 缓存容量。从好的方面来说,H100 的 L2 提供比 VRAM 高得多的带宽,即使请求必须跨分区也是如此。这是一种恭维,因为 H100 拥有大量的 VRAM 带宽。
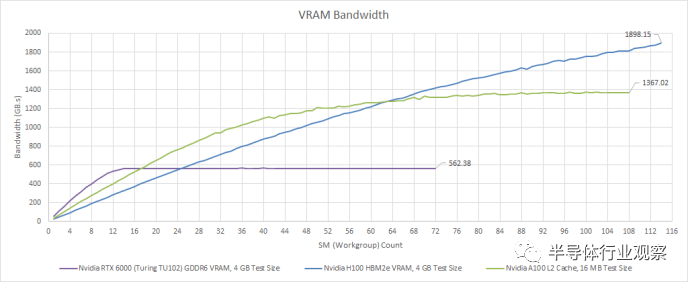
凭借五个 HBM2e 堆栈,H100 可以从 VRAM 中提取略低于 2 TB/s 的速度。因此,H100 的 VRAM 带宽实际上非常接近 RDNA 2 的 Infinity Cache 带宽。它还代表了相对于 A100 的显着改进。A100 使用 HBM2,并且仍然比任何消费类 GPU 拥有更多的 VRAM 带宽,但其较低的内存时钟让 H100 领先。
H100 的 VRAM 带宽对于没有缓存友好访问模式的大量工作集非常有用。消费级 GPU 已趋向于良好的缓存,而不是大量的 VRAM 设置。与具有适度 GDDR 设置但具有出色缓存的 GPU 相比,少数使用 HBM 的消费级 GPU 的性能表现平平。这是因为缓存延迟较低,即使工作负载较小,也可以更轻松地保持执行单元的运行。从 Nvidia 和 AMD 构建计算 GPU 的方式来看,计算工作负载似乎恰恰相反。A100 已经针对大型工作负载进行了调整。H100 更进一步,如果您可以填充一半以上的 GPU,则 H100 领先于 A100,但如果您不能填充一半以上,则 H100 会落后一些。
计算吞吐量
A100 的 SM 提供比客户端 Ampere 更高的理论占用率和 FP64 性能,但只有 FP32 吞吐量的一半。H100 通过为每个 SM 子分区 (SMSP) 提供 32 个 FP32 单元来解决这个问题,让它每个时钟执行一个扭曲指令。
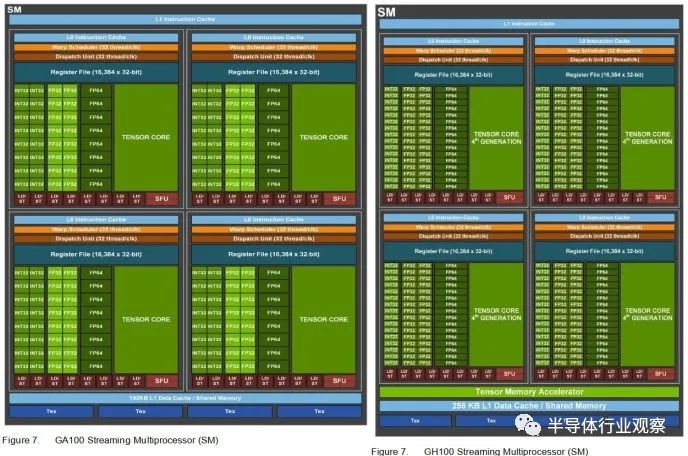
数据来自A100和H100各自的白皮书
除了 FP32 性能之外,FP64 性能也翻倍。每个 H100 SMSP 可以每两个周期执行一条 FP64 warp 指令,而 A100 每四个周期执行一次。这使得 H100 在需要提高精度的科学应用中比 A100 表现更好。
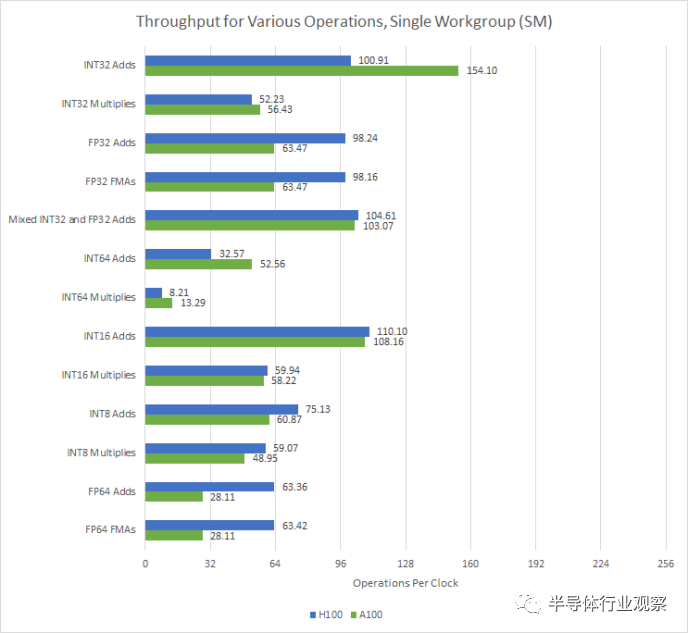
A100 上的 INT32 加法吞吐量绝对是一个测量误差。遗憾的是,Nvidia 不支持 OpenCL 的 FP16 扩展,因此无法测试 FP16 吞吐量
同时,H100继承了Nvidia在整数乘法方面的优势。具体来说,与 AMD GPU 上的四分之一速率相比,INT32 乘法以一半速率执行。另一方面,AMD GPU 可以以双倍速率执行 16 位整数运算,而 Nvidia GPU 则不能。
在GPU层面,H100的特点是SM数量小幅增加,时钟速度大幅提高。其结果是计算吞吐量全面显着增加。由于 SM 级别的变化,H100 的 FP32 和 FP64 吞吐量将 A100 击败。
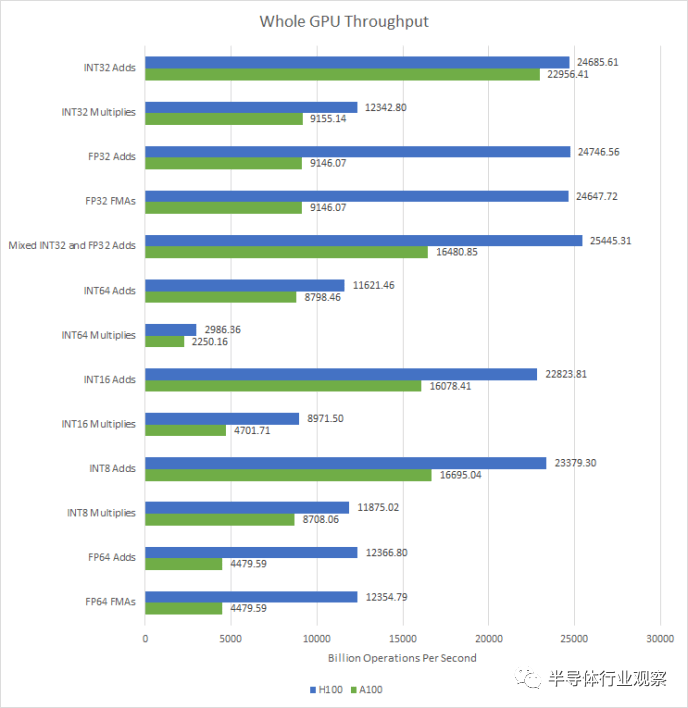
H100 的改进将为各种应用程序带来性能优势,因为很难想象有任何 GPGPU 程序不使用 FP32 或 FP64。将这些操作的吞吐量加倍以及 SM 数量和时钟速度的增加将使工作负载更快地完成。
除了矢量计算性能之外,H100 还使张量核心吞吐量翻倍。张量核心专门通过打破 SIMT 模型来进行矩阵乘法,并在 warp 的寄存器中存储矩阵。我没有为张量核心编写测试,并且在不久的将来编写一个测试超出了我空闲时间爱好项目的时间范围。但是,我相信 Nvidia 关于这个主题的白皮书。
最后的话
近年来,消费类 GPU 已朝着在面对较小工作负载时保持良好性能的方向发展。当然,它们仍然很宽,但 AMD 和 Nvidia 在吞吐量和延迟之间取得了平衡。RDNA 2/3 和 Ada Lovelace 的运行频率均超过 2 GHz,这意味着它们的时钟速度接近服务器 CPU 的时钟速度。除了高时钟速度之外,复杂的缓存层次结构还提供延迟优势和高带宽,前提是访问模式对缓存友好。与此同时,昂贵的内存解决方案已经失宠。少数配备 HBM 的客户端 GPU 从未在配备 GDDR 的竞争对手中表现出色,尽管拥有更多的内存带宽和更多的计算吞吐量来支持这一点。
但这显然不适用于计算 GPU,因为它们已经朝着相反的方向发展。H100 是一款以相对较低的时钟运行的超宽 GPU,它强调每瓦性能而不是绝对性能。1755 MHz 是 Pascal 的典型频率,该架构是七年前推出的。与最新的客户端 GPU 相比,缓存容量和延迟表现一般。与此同时,英伟达并没有牺牲带宽。在带宽方面,H100 的 L2 并不落后于客户端 GPU。L2 之后,由于巨大的 HBM 配置,VRAM 带宽变得巨大。H100 与 A100 和 AMD 的 CDNA GPU 一样,旨在运行大型、长时间运行的作业。基于对 VRAM 带宽而非缓存容量的重视,这些作业可能属于这样的类别:如果您无法使用几十兆字节的缓存捕获访问模式,
H100 在 SM 级别上也有别于客户端设计。用于 L1 或共享内存的更多内存意味着精心设计的程序可以将大量数据保留在非常靠近执行单元的位置。在 H100 的 144 个物理 SM 中,有 36.8 MB 的 L1 和共享内存容量,这使得芯片面积投资显着。Nvidia 还使用 SM 区域来跟踪飞行中的更多扭曲,以应对更高的 L1 未命中延迟。H100 可以跟踪每个 SM 64 个扭曲,而客户端 Ampere 和 Ada Lovelace 则为 48 个。额外的 SM 区域用于使 FP32、FP64 和张量吞吐量加倍。
客户端 GPU 继续提供合理的计算能力,如果您足够讨厌自己,数据中心 GPU可能会被迫渲染图形。但在可预见的未来,面向计算和图形的架构可能会继续分化。Ada Lovelace 和 H100 有很多差异,即使它们基于相似的基础。在 AMD 方面,RDNA 和 CDNA 也继续存在分歧,尽管两者的 ISA 根源都可以追溯到古老的 GCN 架构。这种分歧是很自然的,因为工艺节点进展减慢,每个人都试图专业化以充分利用每个晶体管。
审核编辑:汤梓红
-
控制器
+关注
关注
114文章
17909浏览量
195723 -
NVIDIA
+关注
关注
14文章
5721浏览量
110230 -
gpu
+关注
关注
28文章
5317浏览量
136178 -
带宽
+关注
关注
3文章
1054浏览量
43649 -
内存
+关注
关注
9文章
3252浏览量
76569
原文标题:Nvidia 的 H100:有趣的 L2 和大量带宽
文章出处:【微信号:IC大家谈,微信公众号:IC大家谈】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
英伟达a100和h100哪个强?英伟达A100和H100的区别
请教关于c6424 L2缓存设置问题
NVIDIA发布新一代产品—NVIDIA H100

GTC2022大会亮点:NVIDIA发布全新AI计算系统—DGX H100

NVIDIA发布最新Hopper架构的H100系列GPU和Grace CPU超级芯片
蓝海大脑服务器全力支持NVIDIA H100 GPU
利用NVIDIA HGX H100加速计算数据中心平台应用
关于NVIDIA H100 GPU的问题解答
详解NVIDIA H100 TransformerEngine
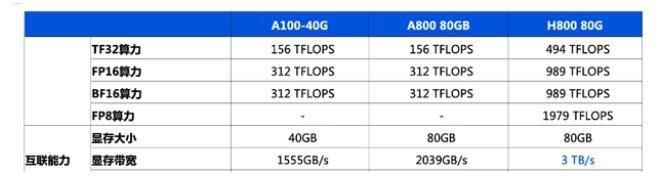
传英伟达新AI芯片H20综合算力比H100降80%
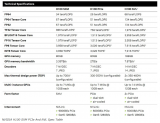
英伟达A100和H100比较




评论