 基于深度学习模型融合的产品工艺缺陷检测算法简述
基于深度学习模型融合的产品工艺缺陷检测算法简述

基于深度学习模型融合的工业产品(零部件)工艺缺陷检测算法简述
1、序言
随着信息与智能化社会的到来,工业产品生产逐渐走向智能化生产,极大地提高了生产力。但是随着工人大规模解放,产品或零部件的缺陷检测,一直不能实现自动检测。深度学习技术的出现,为这一领域带来了曙光,其高精度、高效率、升级维护简单等特点,使之在这一领域应用越来越广。
说明:由于工作原因,不能开放相关源码。实际情况是,大部分源码都是修改而来,功底好一些的同学,可以自行实现。我讲的很清楚了,希望自己实现,拿来主义永远学不会。最后,文中参考了很多文章和论文,甚至有些大家都知道的话,直接粘贴复制的,因为那些仅仅是介绍单个模型,并不是本文核心内容,谢谢理解。加油,大家。
2、数据集整理
一般情况下,工业产品或零部件所获得的数据不是太多,因为大多数缺陷特征都极其微小,数据采集存在极大问题。在高分辨率相机帮助下盲拍,短时间可以获得大量图片,但是数据筛选存在极大问题。人工筛选,浪费时间和效率,但是有不可避免的进行清洗。况且,工业界高清缺陷数据集,也极其稀少。
几百张的数据对深度卷积网络来说是远远不够的,而且数据分布是极不对称的。而且对特征是否明显来说,缺陷特征是最不明显的,在训练的时候更要进行格外关注。
最后,数据采集的硬件设备,对检测结果也影响巨大。例如,相机的分辨率、补光设备等等。这里,不是咱们讨论的范围,假设已经取得了小部分缺陷图像。
3、图像增强扩充
上述现象不可避免,需要对每类特征图像进行原始增强,使其最低扩充到1000幅左右。比如常用的ImageDataGenerator工具,当然也可以自行编写脚本,请自行百度,资料众多。主要包括图像的旋转、平移、错切、旋转、拉伸、明暗度变化等等。
拍摄图像的过程中,不可避免的出现整个场景图像过于巨大,那么就会导致缺陷特征局部化,也就是所占整幅图像比例较小,不利于特征提取。这种情况下,对图像进行卷积操作后,缺陷特征基本上不会检测提取到或者提取到的特征并不明显。解决办法之一是将场景图像进行有规则的切分,比如一个场景图像被切分成六份,可以横向或纵向或者对角线切分,或者切分成四份均可,依照实际情况进行。然后需要自己去做数据,赋以标签,当然Labelimg这个开源工具可以帮助你。
在预测的时候,只要场景图像的四个或者六个子图像有一个是缺陷图像,就认为其是缺陷图像。这样做的好处是,在一定程度上避免了特征过于局部化。这是我能想到的方法之一,当然业界可能有很多方法,这个比较简单粗暴。但是实际效果还不错。
4、融合模型架构
采用的架构如下:
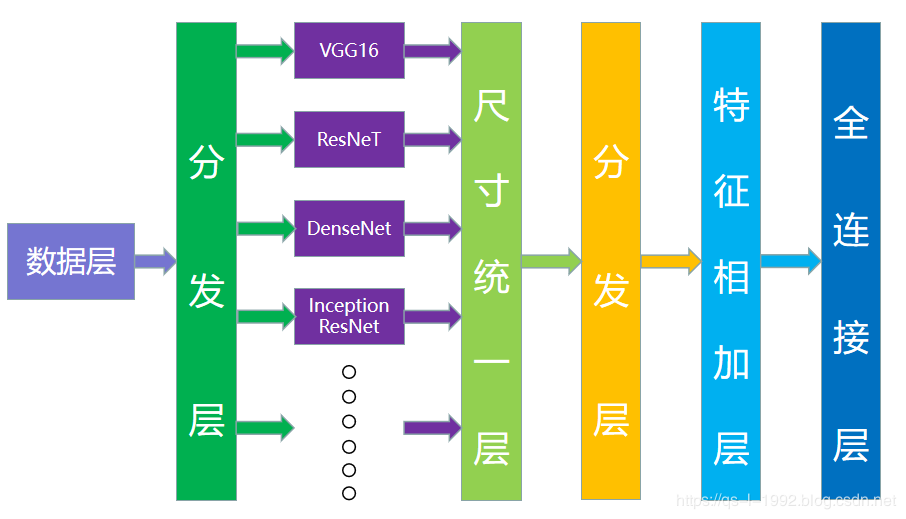
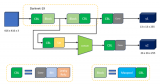
图1 模型融合架构
对上图进行解释。数据层当然就是整理后的数据集,数据集的质量决定了后面的所有事情,所在制作的时候一定要认真,废话不多说。分发层,只是原来单个网络的输入层。这一层的目的,就是为了向各个单个网络输入数据。因为每个网络对数据输入要求是不一样的,这一层就干了这一件事情。接下来就是“隐藏”网络层,这一层就是“并行”连接了网络,分而治之。尺寸统一层,就是将各个网络输出的特征图进行修饰,主要是尺寸上进行修改。空白层,这一层的目的是进一步梳理特征信号,进一步处理,比如添加合适的比例放大特征图等等,当然,这只是初步的想法,还没有实际去做。不可否定的是,工业与学术界肯定有更好的方法,这是以后的工作优化内容。特征相加层,就是将得到的统一的特征“点加”,增强特征的表现形式,处理微小特征的方法。最后是全连接层,用于分类与回归,最后是输出结果。当然,中间的损失层之类的没有说,但是并不代表不存在,钻牛角尖得人退避。
对工业缺陷零件来说,缺陷特征非常细微或者说不明显,通常仅仅一小块区域存在特征,而且高度相似。对于“隐藏层”选择的相关网络,首先,是专注于特征提取,因为特征提取是整个网络的关键所在,其次,要考虑把浅层特征和深度特征进行融合,这样的话结合图像切分,就不会造成主要特征丢失,或者说尽量降低特征的内部损耗。常见的特征提取网络有VGG16、ResNet、DenseNet、Inception-ResNet-V2等等这些,但是笔者复现过得网络只有VGG与ResNet,经过论文以及相关资料,DenseNet效果可能要更好些,留作近期工作内容。
5、融合模型训练
选取不同的缺陷数据,数据尽量不要完全相同,这样可以增加模型的丰富度,更有利于提取相关特征。与“隐藏层”相对应训练几个不同的模型,比如训练出四个模型分别对应于ResNet、DenseNet、Inception-ResNet-V2、VGG四个网络。当然,根据你选择的模型进行对应即可,灵活度极高。
训练完成后,把这四个模型输入层与全连接层去除,仅仅使用这四个模型的相关卷积层进行特征提取,然后利用特征相加层进行特征拼接。拼接的时候注意,在channel方向上保持相同,也就是特征图的w和h必须相同。这是关键中的关键,也是特征统一层存在的意义,否则,特征非但没有增强,反而因为尺寸的问题导致精度下降,得不偿失。
在对应位置上进行特征相加(点加),然后把这些特征进行汇总,重新建立四个网络,每个网络模型分别对应训练好的四个模型,提取训练好模型的参数,赋给新的模型,然后建立全连接层,这个时候只有一个全连接层。在训练的时候,新的网络只用来做特征提取,卷积层的参数不做训练,把这些网络参数冻结,只更新全连接层。
对于上述中的特征融合,还有一种方法就是:用三个训练好的模型进行特征提取,然后建立一个MLP多层感知机类型的网络。训练好的模型去掉全连接层,只保存卷积层,做特征提取,并把产生的特征进行拼接,训练时只对全连接层进行更新。
6、单个网络要点解析
Inception-ResNet-V2的结构如下,细节请看参考文献,这里只是简单说一下。Inception-ResNet-v2,更加昂贵的混合Inception版本,同明显改善了识别性能。
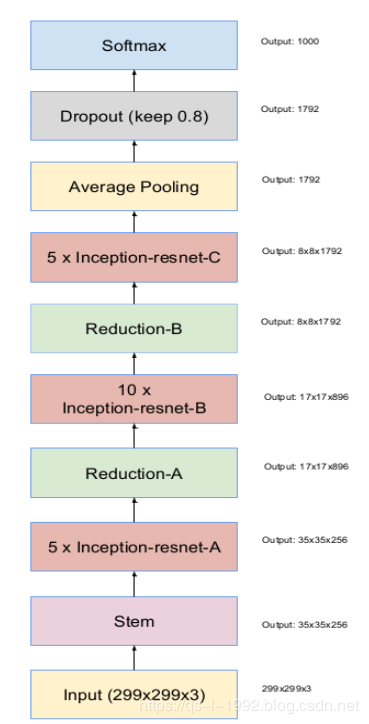
图2 InceptionResNetV2整体架构(图片来源于网络)
其中的stem部分网络结构如下,inception设计,并且conv也使用了7*1+1*7这种优化形式:
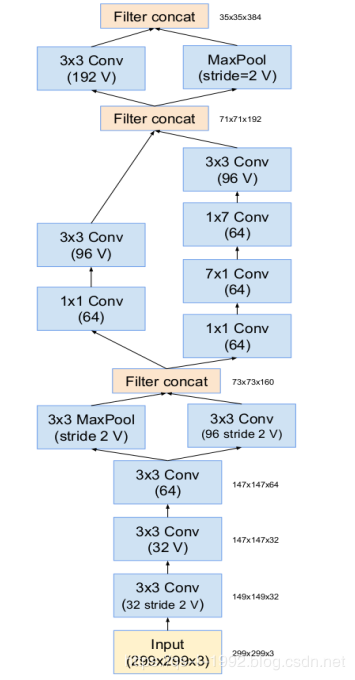
图3 stem部分网络结构(图片来源于网络)
inception-resnet-A部分设计,inception结构相当于加宽网络,也就是并行思想,这是本文灵感来源一。inception+残差设计为:
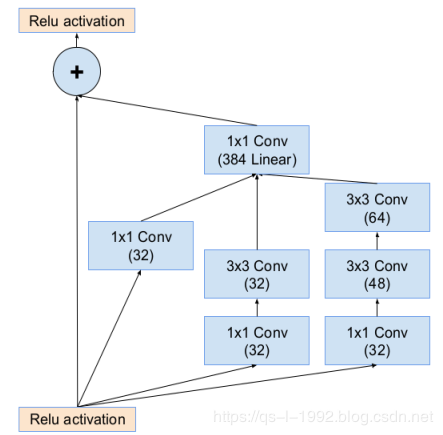
图4 inception-resnet-A设计(图片来源于网络)
通过将不同尺度的feature map进行融合,通过1*n卷积与n*1卷积来替代n*n卷积,从而有效地降低计算量,通过使用多个3x3卷积来代替5x5卷积和7x7卷积来降低计算量。另外在inception resnet v2中将resnet与inception 的网络结构来进行融合,从而进一步提升在 imagenet上的accuracy。咱们文章的灵感来源二也来源于此,特征融合,只是咱们融合了模型以及特征图。说一句没必要的废话,slim库中已经实现的inception-resnet-v2网络,所以以后网络应用更加简单了。
VGG16网络,我接触的比较早了,研究生期间就使用了。读研的时候做了基于Faster R-CNN的高铁定位器识别,当初就是用的VGG网络而不是ZF网络。VGG16相比前辈AlexNet网络做了诸多改进,其中比较主要的是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5),对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小,参数更少,节省算力。
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。话题拉回来,本文灵感来源三就是VGG训练过程,VGG有六种结构或者说有六个阶段的训练过程。分别是A、A-LRN、B、C、D、E六种,训练时,逐层递归训练,由浅入深,思路清晰。训练的方式也对本文产生了影响,冻结卷积层参数,只更新全连接层参数。最后,经过证明D、E两个模型融合,效果最佳。
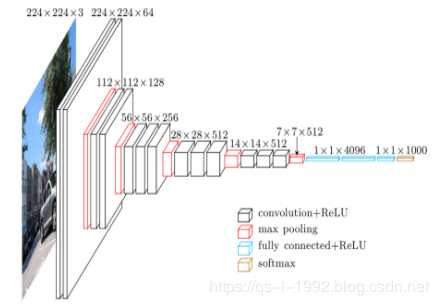
图5 VGG16结构图(图片来源于网络)
ResNet(Residual Neural Network)由微软研究院的Kaiming He等四名华人提出,通过使用ResNet Unit成功训练出了152层的神经网络,并在ILSVRC2015比赛中取得冠军,在top5上的错误率为3.57%,同时参数量比VGGNet低,效果非常突出。ResNet的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升。同时ResNet的推广性非常好,甚至可以直接用到InceptionNet网络中。
ResNet的主要思想是在网络中增加了直连通道,即Highway Network的思想。此前的网络结构是性能输入做一个非线性变换,而Highway Network则允许保留之前网络层的一定比例的输出。ResNet的思想和Highway Network的思想也非常类似,允许原始输入信息直接传到后面的层中,如下图7所示。
CNN能够提取low/mid/high-level的特征,网络的层数越多,意味着能够提取到不同level的特征越丰富。并且,越深的网络提取的特征越抽象,越具有语义信息。既然这样,为什么不能简单地堆叠网络层呢?因为存在梯度弥散或梯度爆炸。有没有解决方法呢?有,正则化初始化和中间的正则化层(Batch Normalization),但是,这样的话也仅仅可以训练几十层的网络。虽然通过上述方法能够训练了,但是又会出现另一个问题,就是退化问题,网络层数增加,但是在训练集上的准确率却饱和甚至下降了。这个不能解释为overfitting,因为overfit应该表现为在训练集上表现更好才对。退化问题说明了深度网络不能很简单地被很好地优化。
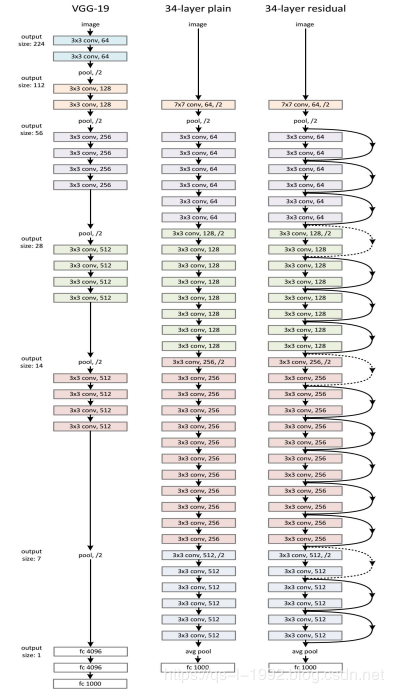
图6 ResNet结构(图片来源于网络)
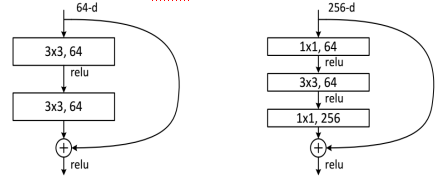
图7 不同的残差单元(图片来源于网络)
DenseNet结构如下:
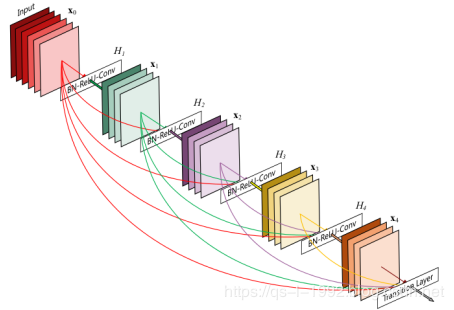
图8 DenseNet结构(图片来源于网络)
DenseNet脱离了加深网络层数(ResNet)和加宽网络结构(Inception)来提升网络性能的定式思维,从特征的角度考虑,通过特征重用和旁路(Bypass)设置,既大幅度减少了网络的参数量,又在一定程度上缓解了gradient vanishing问题的产生.结合信息流和特征复用的假设,是该网络新颖的地方
对于本文四种网络,后续会根据实际测试情况,进行模型的更换与删减,具体情况只有实际测试才能知晓。
7、融合损失函数
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。
首先,二分类交叉上损失公式:
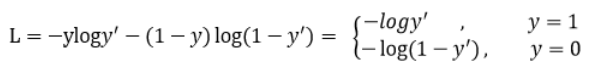
可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。Focal loss的改进高明之处是:
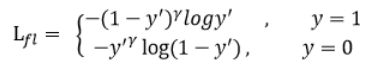
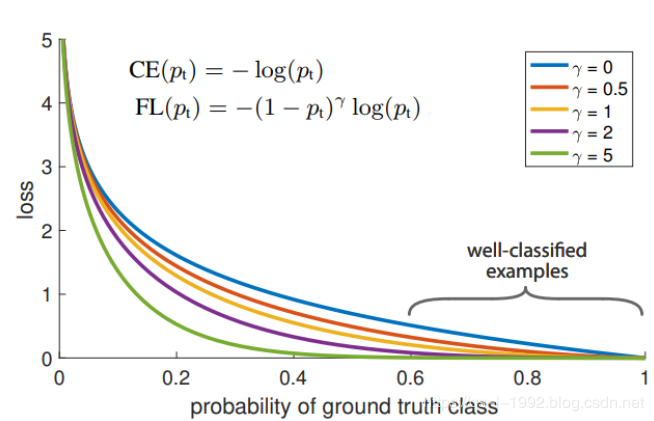
首先在原有的基础上加了一个因子,其中gamma>0使得减少易分类样本的损失。使得更关注于困难的、错分的样本。
此外,平衡因子alpha的加入,用来平衡正负样本本身的比例不均:
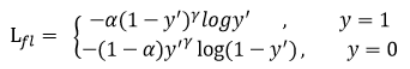
只添加alpha虽然可以平衡正负样本的重要性,但是无法解决简单与困难样本的问题。lambda调节简单样本权重降低的速率,当lambda为0时即为交叉熵损失函数,当lambda增加时,调整因子的影响也在增加。
8、期望与问题
关于融合模型的一些思考,欢迎大家讨论。其中的一些问题已经解决,说实话,每一点都可以形成一篇论文,大家参考。
1)分发层,内部机制是什么?统一分发,还是通道形式?是否需要放大?
2)网络“隐藏”层,模型间进行“某种连接”,是不是会产生特殊火花?
3)网络“隐藏”层,哪几种模型融合效果最好,增加,删减效果怎么样?
4)尺寸统一层,统一的方式,除了简单“比例拉扯”,有没有更好的方式?
5)特征相加层,点加最好?加上比例放大?比例多少?能学习吗?
6)模型融合,目标检测模型融合会更好吗?NLP是否有相关的研究?
7)YOLOv3号称检测小目标(细微特征相对应)能力出色,是否相关思想可以借鉴?
模型的融合并不是简单地堆叠,而是根据特征图尺寸这一核心思想进行重新设计计算。对单个模型的参数进行适当的修改,前提是架构不改变。充分利用每个模型的优点,摒弃缺点。其中最重要的就是砍掉了每个模型的全连接层,极大地降低了参数的数量。
-
源码
+关注
关注
8文章
689浏览量
31549 -
模型
+关注
关注
1文章
3866浏览量
52327 -
深度学习
+关注
关注
73文章
5614浏览量
124728
原文标题:基于深度学习模型融合的工业产品(零部件)工艺缺陷检测算法简述
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
全网唯一一套labview深度学习教程:tensorflow+目标检测:龙哥教你学视觉—LabVIEW深度学习教程
labview缺陷检测算法写不出来?你OUT了!直接上深度学习吧!
labview深度学习检测药品两类缺陷

使用深度卷积神经网络实现深度导向显著性检测算法

如何实现一种深度特征导向显著性检测算法

基于深度学习的疲劳驾驶检测算法及模型

基于深度学习的目标检测算法



评论