 武大+上交提出BatGPT:创新性采用双向自回归架构,可预测前后token
武大+上交提出BatGPT:创新性采用双向自回归架构,可预测前后token
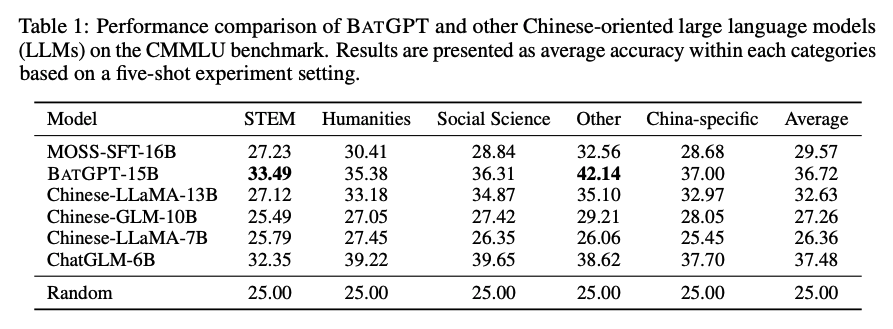
本论文介绍了一种名为BATGPT的大规模语言模型,由武汉大学和上海交通大学联合开发和训练。

该模型采用双向自回归架构,通过创新的参数扩展方法和强化学习方法来提高模型的对齐性能,从而更有效地捕捉自然语言的复杂依赖关系。

BATGPT在语言生成、对话系统和问答等任务中表现出色,是一种高效且多用途的语言模型。
BATGPT 的双向自回归架构如何帮助其捕获自然语言的复杂依赖关系?
BATGPT的双向自回归架构可以同时考虑输入序列的前后文信息,从而更好地捕捉自然语言的复杂依赖关系。
传统的自回归模型只能考虑输入序列的前面部分,而BATGPT的双向自回归架构可以同时考虑前面和后面的信息,从而更好地理解整个输入序列的语义。
这种架构可以有效地解决传统模型中存在的“有限记忆”和“幻觉”问题,提高模型的生成质量和对齐性能。
BATGPT在训练方面提出的参数扩展方法是什么,它是如何提高模型有效性的?
BATGPT在训练方面提出了一种参数扩展方法,即在较小的模型上进行预训练,然后将预训练的参数扩展到更大的模型中。
这种方法可以有效地利用较小模型的预训练参数,从而加速更大模型的训练过程,并提高模型的有效性。
此外,BATGPT还采用了强化学习方法,从AI和人类反馈中学习,以进一步提高模型的对齐性能。这些方法的结合可以显著提高BATGPT的生成质量和对齐性能,使其成为一种高效且多用途的语言模型。
BATGPT 是否可以用于语言生成、对话系统和问答之外的应用程序?
BATGPT表现稳健,能够处理不同类型的提示,因此它具有广泛的能力,并适用于广泛的应用程序。
虽然文中没有明确提到BATGPT是否可以用于语言生成、对话系统和问答之外的应用程序,但是它的广泛能力表明它可以用于其他类型的应用程序。
-
应用程序
+关注
关注
37文章
3277浏览量
57738 -
语言模型
+关注
关注
0文章
527浏览量
10288 -
强化学习
+关注
关注
4文章
267浏览量
11263
原文标题:武大+上交提出 BatGPT:创新性采用双向自回归架构,可预测前后token
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于移动自回归的时序扩散预测模型
基于RK3568国产处理器教学实验箱操作案例分享:一元线性回归实验
基于risc-v架构的芯片与linux系统兼容性讨论
RISC-V架构的目标和特点
如何采用分区架构提升车辆的简易性
MATLAB预测模型哪个好
matlab预测模型有哪些
arimagarch模型怎么预测
更好的预测方法:使用前后控制图
RISC-V架构的特点
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
基于自回归模型的海上风电功率预测方法





 工商网监
工商网监
评论