 浪潮NF5468A5 GPU服务器整体设计及性能深度测评解读
浪潮NF5468A5 GPU服务器整体设计及性能深度测评解读
近日,浪潮信息推出AI服务器 NF5468A5"超值机型 限免试用"活动。浪潮NF5468A5是一款性能强大、应用场景广泛的GPU服务器,硬件设计合理,可最大化发挥核心组件的性能优势,并通过分区散热设计保障服务器稳定运行,同时广泛兼容主流加速卡,计算性能强大,以更灵活的计算架构最大程度地满足用户在图像识别、自然语言处理、语音识别等多场景应用需求,专业测评媒体将其比喻为"算力猛兽"。
本文将围绕NF5468A5整体设计及性能测试进行深度测评解读,展现HPL、内存带宽、AI训练、AI推理、视频编解码、HASH等应用场景的各类测试数据,如对该AI服务器感兴趣可以申请参加试用活动。
浪潮NF5468A5服务器
NF5468A5是浪潮推出的一款面向AI训练和AI推理、视频编解码等多种应用场景的全能型GPU服务器,在4U空间内搭载2颗AMD EPYC处理器,支持多达8张双宽加速卡。浪潮官网显示,这款产品已经支持NVIDIA、AMD、Intel、寒武纪、燧原等多家业界主流AI加速卡。
本次拿到的样机采用如下配置:
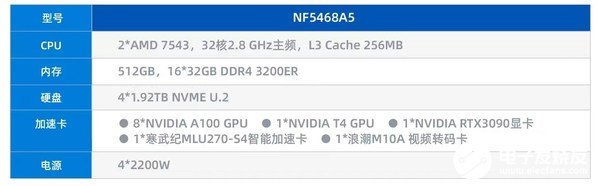
接下来,笔者将从系统解析、性能测试这两个方面对浪潮NF5468A5服务器进行测评。
1.NF5468A5系统解析
1.1整体系统设计
浪潮NF5468A5 AI服务器采用了4U机架式机箱,高x宽x深为175mm x 478mm x 830mm。整体风格简约、硬朗,不论做工、还是用料、细节,均彰显出大厂品质。
前面板沿用浪潮一贯稳重的黑色,六边形的格栅结构由金属制成,可以将风扇高速旋转产生的湍流风切割成平稳的平流风,从而更平稳的吹向服务器内部。前面板右上角,电源键下方是ID、Reset按键和系统状态指示灯,前面板左上角则是VGA、两个USB 3.0接口和管理接口。前面版的丰富接口,充分考虑了运维人员的工作场景,十分便捷。

浪潮NF5468A5前视图
从后窗来看,NF5468A5在4U空间内提供了8个全高全长双宽PCIe x16的物理插槽,支持最新PCIe Gen4,双向通信带宽高达64GB/s,相比PCIe Gen3,功耗不变,但通信性能提升1倍。在此基础上产品还提供了3个全高全长单宽x16物理槽位,可支持25G/100G/200G双口光纤,或者千兆/万兆RJ45网卡以及8/16端口12Gb/s RAID卡,可满足客户对网络及存储的要求。同时可支持1个OCP 3.0网卡专用插槽,支持热插拔,将网卡更换时间从20分钟缩短到1分钟,能够大幅提高运维效率。
NF5468A5支持4个电源模组,可以提供1600W~3000W功率的80 PLUS铂金电源模块,效率高达94%,可选3+1冗余或者2+2冗余,多种组合的冗余电源设计,充分考虑了不同配置AI服务器的负载情况,保障稳定性。

浪潮NF5468A5后视图
整个服务器采用非常紧凑的布局设计,总共分成四个功能区域,从前往后依次是:磁盘存储区、系统散热区、处理器+内存区、GPU+IO扩展区。

浪潮NF5468A5内部俯视图
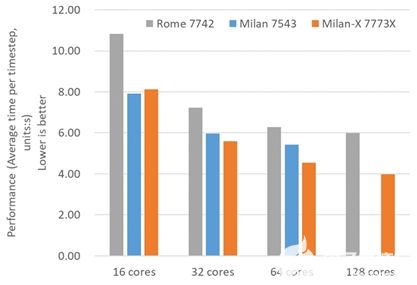
下面我们先看下CPU和内存。这台样机搭配了2颗AMD EPYC 7543处理器,核心数达到了32核心64线程,基准主频2.8GHz,最大加速时钟频率3.7GHz,L3 Cache 256MB,功耗225W。另外,浪潮官网介绍NF5468A5可支持2颗AMD基于"Zen3"微架构内核的EPYC Milan-X处理器,最高128个核心256线程、1536MB L3 Cache 以及18 GT/s XGMI互连链路,CPU TDP最大支持280W。样机配置了16根32G DDR4内存,同时可以看到服务器主板整齐排布了32个DDR4内存插槽,最大容量可达8TB,内存总带宽750GB/s,支持RDIMM/LRDIMM等类型的内存条。NF5468A5强劲的处理器性能、巨大的内存容量和带宽,特别适合AI计算、云计算、HPC以及企业各类业务的工作负载。

浪潮NF5468A5的CPU散热器和内存条
笔者手上的这台NF5468A5,最吸引眼球的是本次测试样机搭配了8颗NVIDIA A100 40G加速卡,从京东网上的报价看,8张A100的价格已经与一款中高端轿车相当,这究竟是一款什么样的AI服务器,笔者将带大家一探究竟。
我们来重点看一下NF5468A5的GPU模组。样机搭配了8张NVIDIA A100 PCIE 40GB GPU加速卡,由于每张卡功耗高达250W,服务器也给GPU板卡配置了单独供电线,保证GPU卡的稳定工作。为了满足PCIE卡的高功率运行,我们看到NF5468A5在GPU板上专门设计了4个用于大电流通流的bus bar,据浪潮的工程师介绍,bus bar的通流能力可以达到2880W,这对于各类PCIE加速卡的支持是非常强劲的。
NF5468A5提供了对丰富外插卡的支持,针对A100这种全高全长的卡配置了专用支架,搭配尾部锁片进行固定,这样能增强产品在运输过程中震动、跌落情况下的可靠性。我们翻开尾部锁片,旋转蓝色旋钮,就能非常顺利的取下GPU进行更换,这种针对PCIE卡免工具的操作非常人性化。

1.2系统散热设计
从浪潮官网产品介绍中看到NF5468A5可以支持2颗280W CPU+8颗300W的GPU,在177mm的空间内浪潮究竟是如何实现的?笔者找浪潮工程师拿到了系统风流图,从中可以看出,系统整体风道采用前进后出的方式,散热风流主要从前面板的硬盘及下方开孔处进入系统。风流经系统风扇后通过导风罩的分配,一部分进入下层前排CPU和内存通道,一部分继续往后吹;经过CPU和内存后的风及未被预热的风大部分流向后方上面3U空间的GPU,小部分流向下面1U空间;最后经后面板流出系统。如此巧妙的风道设计和精准的风流控制,足见浪潮作为全球AI领导厂商深厚的设计功底。
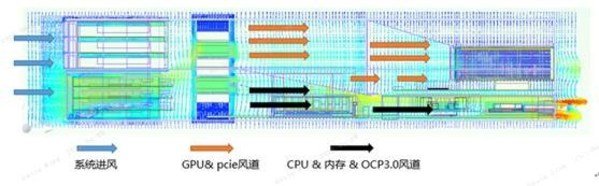
系统分离式风流设计
这款服务器将整机柜产品中"风扇墙"的设计理念搬到了4U机箱中,"风扇墙"一共由6组可以单独维护的子风扇模组组成,风扇后部搭配了流线型设计的导风罩,覆盖了从风扇到GPU中间的区域,但整个导风罩并没有完全挡住风扇的出风区域,结合上面系统风流图也证明是为实现CPU和GPU独立风道的引流设计,避免风流的串扰,无论多"强悍"的CPU和GPU都可以驯服。

NF5468A5中置风扇墙和导流设计
1.3架构设计
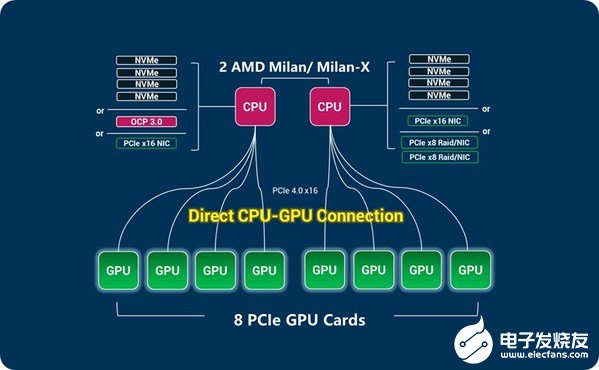
笔者查找了海外网站相关浪潮产品的介绍资料,找到一张产品的拓扑图,发现有别于传统CPU-PCIE Switch-GPU的设计,浪潮产品采用CPU-GPU直连方式。跟浪潮工程师确认,送测的NF5468A5也采用类似设计。工程师介绍,由于省去了PCIE Switch,2颗CPU与GPU的通讯延迟能降低200~300ns,同时GPU到CPU的通信带宽可以达到256GB/s,较GPU通过PCIE Switch只有1条与CPU PCIE通路比,带宽提升4倍,这种极致的互联架构设计,有助于提升GPU与CPU间数据通信的带宽,有效降低数据的处理延迟。
2.NF5468A5性能测评
2.1 HPL测试
样机搭配2颗AMD EPYC 7543处理器,这款处理器是32核64线程,基准主频2.8GHz,L3 Cache 256MB,最大加速时钟频率最高可达3.7GHz,功耗225W。为了能够了解CPU实际性能,下面将采用HPL基准软件进行测试。
在计算机基准测试软件中,HPL是应用最广泛的基准测试程序之一。通过使用高斯消元法对稠密线性方程组进行求解,HPL可以准确测试系统浮点计算指标。在每年全球超级计算机排名TOP500中,HPL测试性能是唯一的评价标准。
由于笔者拿到的设备是一台未预装任何软件的裸金属服务器,为了进行相关测试,首先在上面安装了Ubuntu20.04操作系统。
然后用HPL软件测试了系统的浮点运行能力。通过如下命令,将测试进程和CCD进行绑定。
|
#mpi_options="--mca mpi_leave_pinned 1 --bind-to none --report-bindings --mca btl self,vader" #mpi_options="$mpi_options --map-by ppr:1:l3cache -x OMP_NUM_THREADS=4 -x OMP_PROC_BIND=TRUE -x OMP_PLACES=cores" #mpirun $mpi_options -app ./appfile_ccx |
在运行之前,还需要设置核心运行在最高频率,清除系统缓存,并开启大页内存等设置,保证获得当前平台最高性能。
|
echo 3 > /proc/sys/vm/drop_caches echo 1 > /proc/sys/vm/compact_memory echo 0 > /proc/sys/kernel/numa_balancing echo‘always‘> /sys/kernel/mm/transparent_hugepage/enabled echo‘always‘> /sys/kernel/mm/transparent_hugepage/defrag sudocpupower frequency-set-g performance |
最终测试浮点计算速度为2.69 TFLOPS,根据当前AMD平台理论浮点计算速度,计算效率达到93.74%。
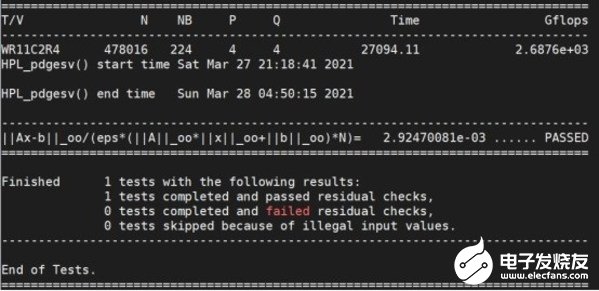
处理器浮点计算测试结果
2.2内存带宽测试
我们用业界主流的测试软件STREAM对NF5468A5的内存带宽进行了测试,测试参数如下:
|
# Thread Binding Options for AMD EPYC 7742/7763 Processor $exportGOMP_CPU_AFFINITY=0-64:8 $exportOMP_NUM_THREADS=8 |
在运行前,清除系统缓存并且开启透明大页内存设置等,设置参数如下:
|
$echomadvise |tee/sys/kernel/mm/transparent_hugepage/enabled $echomadvise |tee/sys/kernel/mm/transparent_hugepage/defrag $ echo 3 > /proc/sys/vm/drop_caches $ echo 1 > /proc/sys/kernel/numa_balancing |
通过以上编译和运行过程中优化,STREAM测试结果为373 GB/s,根据当前平台理论内存带宽409.6 GB/s,实测内存带宽效率达到91.1%。应该说,这个效率非常高了。
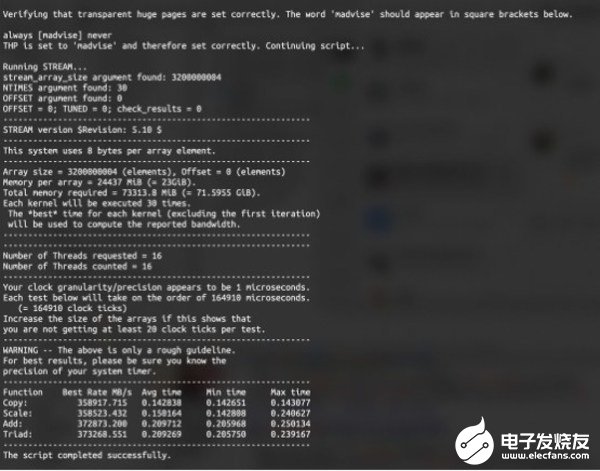
内存带宽测试结果
2.3训练性能测试
下面我们来测试NF5468A5的AI训练性能。样机配置8张NVIDIA A100 PCIE 40GB GPU,这款GPU采用Ampere架构,基于7nm制造工艺,包含了超过540亿个晶体管,拥有6912个CUDA核心,搭载了40GB HBM2内存,具备1.6TB/s的内存带宽,FP64性能9.7 TFLOPS,FP32性能19.5 TFLOPS,FP16性能312 TFLOPS。
笔者从github网站上的公共仓库https://github.com/mlcommons/training_results_v1.0中下载了MLPerf Training V1.0代码,并使用这套代码按照以下测试步骤在NF5468A5上训练ResNet50模型。MLPerf是一套衡量机器学习系统性能的权威标准,将在标准目标下训练或推理机器学习模型的时间,作为一套系统性能的测量标准。MLPerf由图灵奖得主大卫·帕特森(David Patterson)联合谷歌、斯坦福、哈佛大学等单位共同成立,是国际上最有影响力的人工智能基准测试之一。ResNet50是计算机视觉领域中最经典的图像分类模型,广泛应用于图像识别、自动驾驶等场景。
MLPerf代码提供了容器配置文件,我们可以很方便的通过配置文件在自己的服务器设备上创建镜像环境,镜像中包含cuda、cudnn、nccl、mxnet等上层组件。但是在运行容器之前,还需要在Host OS中安装NVIDIA GPU Driver、docker、nvidia-docker这些基础软件。
首先,笔者参考https://docs.nvidia.com/datacenter/tesla/tesla-installation-notes/index.html#runfile教程在Ubuntu20.04操作系统中下载并安装了R470.82.01版本的驱动;然后按照https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker教程安装docker和nvidia-docker。
通过以下命令构建容器镜像:
|
$ cd ~/training_results_v1.0/NVIDIA/benchmarks/resnet/implementations /mxnet $ docker build -t mlperf1.0-nvidia:image_classification . |
在测试之前,通过在nf5468a5_cxx.sh文中添加以下内容绑定核心与进程,最大化的利用系统中的计算资源,达到良好的负载均衡,保证获得最优的性能结果。
|
bind_cpu_cores=([0]="48-63,176-191" [1]="32-47,160-175" [2]="16-31,144-159" [3]="0-15,128-143" [4]="112-127,240-254" [5]="96-111,224-239" [6]="80-95,208-223" [7]="64-79,192-207") bind_mem=([0]="3" [1]="2" [2]="1" [3]="0" [4]="7" [5]="6" [6]="5" [7]="4") |
测试环境准备完成,执行以下指令开始测试:
|
激活环境变量: $ source config_NF5468A5.sh $ export CONT=mlperf1.0-nvidia:image_classification $ export DATADIR=/home/data/mxnet_imagenet/ $ export LOGDIR=/home/resnet50/ 执行测试脚本: $ ./run_with_docker.sh |
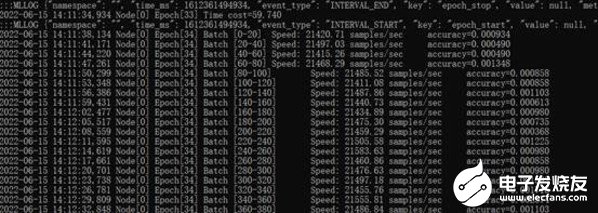
测试结果为21486 images/sec,也就是35分钟即可完成ResNet50模型的训练。参考最近几期MLPerf训练榜单,搭载8张NVIDIA A100 40G GPU卡的服务器的最好成绩是36.2分钟。可以说,在同等GPU配置的服务器中,浪潮NF5468A5的ResNet50训练性能是最好的。
2.4推理性能测试
笔者也测试在目前推理场景中热度最高的NVIDIA Tesla T4,这款精致的GPU卡只有75W,采用Turing架构, 在半高卡的尺寸内集成320个Turing Tensor Core和2560个Turing CUDA Core,配备16GB GDDR6,支持FP32/FP16/INT8/INT4等多种精度的运算,FP16的峰值性能为65T,INT8为130T,INT4为260T。

NVIDIA Tesla T4 GPU
推理性能测试同样使用了MLPerf测试工具,本次测试是基于MLPerf Inference V1.0.复用了训练测试时使用的OS、docker、nvidia-docker等基础软件环境。
我们在NF5468A5搭载1张NVIDIA T4 GPU,使用github网站上的公开代码https://github.com/mlcommons/inference_results_v1.0,按照如下步骤测试了ResNet50模型的推理性能:
同训练时一样,首先要构建容器镜像:
|
# unzip mlperf-inference-release.zip # cd /mlperf-inference-release/closed/Inspur # export MLPERF_SCRATCH_PATH=/home/inspur/data/data_mlperf/ # make prebuild (备注:prebuild后会自动进入容器实例) |
然后执行以下指令开始测试:
| sudo CUDA_VISIBLE_DEVICES=0 make run RUN_ARGS="--benchmark=resnet50 --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly --fast" |
在图像分类应用场景中,使用ImageNet数据集,ResNet50测试结果是每秒处理5671.9张图片。我们了解到NVIDIA T4的ResNet50推理性能为每秒5000张图片左右。应该说,在NF5468A5上测得的T4推理性能非常好了。
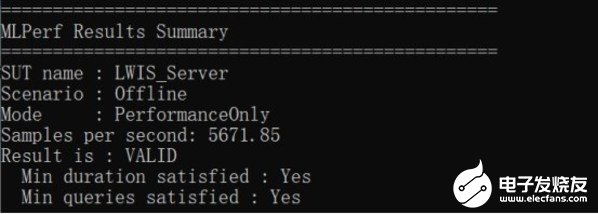
ResNet50推理测试结果
笔者也拿到了寒武纪MLU270-S4推理加速卡。MLU270-S4采用TSMC 16nm工艺制造,集成16GB DDR4内存,支持ECC,同时兼容INT4和INT16运算,理论峰值分别达到256TOPS和64TOPS。
我们发现NF5468A5对寒武纪的板卡也做了很好的兼容性适配,BMC可以显示MLU270-S4的资产信息,风扇转速也根据MLU270-S4的功耗进行了调整,相比A100,能够明显感觉到风扇转速主动降低了。不得不说,浪潮服务器的散热控制做得很精细。

寒武纪MLU270-S4加速卡
我们在NF5468A5上插了1张MLU270-S4,测试了Caffe框架下的ResNet18、PyTorch框架下的GoogleNet以及TensorFlow下的ResNet101v1.5、VGG16和InceptionV3这几个模型的推理性能,在使用int8精度时,计算性能分别为每秒7440、5800、2400、1400和1000张。
笔者分析,浪潮NF5468A5在训练和推理测试中能取得这么好的成绩主要有三个原因:第一,ResNet50模型从算法上还是需要CPU进行一定的图像预取和处理操作,本次送测的AMD 7543具备32核心2.8GHz主频,有助于图像在CPU端的预处理工作;第二,NF5468A5采用CPU和GPU直连设计,有效降低数据的处理延迟,同时单个CPU与GPU通信带宽高达128GB/s;第三,NF5468A5可以支持NVME SSD作为数据盘,通过将多颗NVME SDD数据盘组建RAID,可以极大的提升磁盘IO能力,在AI这种需要频繁读取数据的场景中,能够非常有效的避免因为IO短板带来的性能瓶颈。
2.5视频编解码性能测试
笔者在NF5468A5服务器上也评测了浪潮自研的M10A加速卡。
据浪潮官网介绍,M10A是一款面向AI场景优化设计的VPU(Video Processing Unit), VPU是一种全新的视频处理核心引擎,将视频处理功能做成ASIC芯片,具有硬件编码、硬件解码、硬件转码等视频加速功能,可以减少服务器在视频处理业务上的计算性能消耗和降低视频传输对网络带宽的需求。
M10A在8W功耗下可以提供16路1080P30视频的加速能力,相当于每路1080P视频加速仅需0.5W。M10A针对H.265视频格式压缩算法进行了特殊优化,实测数据表明M10A的H.265编码效果可以使得网络带宽利用率翻倍,同时计算CPU负荷最低可降至2%,适用于直播、短视频、云游戏、视频会议等场景。

浪潮M10加速卡
在FFMPEG视频框架下,我们直接用软件SDK中的demo脚本,测试了M10A在不同视频分辨率下的性能数据,如下是16路1080P全高清视频实时转码的性能测试情况:
在测试的过程中,我们发现M10A VPU芯片内部是"多核"结构,这将进一步降低视频处理延迟,提高多路视频转码时的性能稳定性。
从测试结果看到,M10A进行16路1080P全高清视频转码时,每路视频转码性能都能达到33fps,达到了浪潮官方宣传的性能。
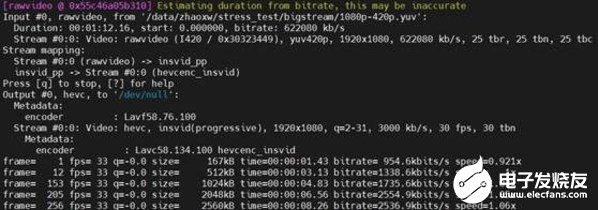
M10A视频转码性能测试结果
另外,我们还测试了4K超高清和720P高清分辨率下的M10A的性能数据,分别可以达到4K 120fps和720P 960fps,解码、编码和转码的性能都是一致的。
在我们跟视频行业技术大咖的交流中了解到,一张M10A的视频处理能力相当于一台双路服务器的性能,M10A具有高性能、低功耗的优点,这对视频行业来说是一个非常高性价比的解决方案。
2.6 HASH性能测试
除了前面讲到的几张加速卡,笔者也尝试了其他板卡,比如主流的消费级显卡RTX3090等,发现NF5468A5都做了很好的适配工作。
RTX3090采用第2代NVIDIA RTX架构-NVIDIA Ampere架构,采用8纳米工艺,拥有10496个CUDA核心,搭载了24 GB GDDR6X内存,384bit位宽。

RTX3090显卡
下面,我们来看看浪潮5468A5搭载RTX3090显卡在区块链场景的性能。基于T-Rex这个知名的应用软件,笔者对业界主流的哈希算法进行了性能测试。T-Rex不仅支持区块链场景中最常用的ETHASH算法,也支持其他诸如BLAKE3、MTP等哈希算法。
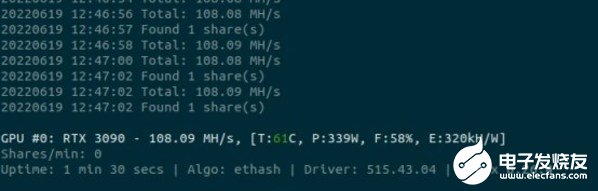
ETHASH算法性能测试过程
针对每种HASH算法,我们使用了t-rex软件的benchmark模型,在单个3090显卡上进行测试,每次测试持续10分钟时间,并记录了最终的性能数据,如下表所示。
浪潮NF5468A5+单卡RTX3090 HASH算法测试结果

其中ETHASH算法的单卡性能达到了108MH/s。
这在很大程度上得益于NF5468A5优秀的散热设计。RTX3090的功耗高达350W,在区块链场景,显卡通常是7*24小时运行,因此对散热的要求非常高。笔者监控了整个测试过程中的GPU功耗和温度情况,发现在长达半天的测试过程中,虽然GPU功耗长期维持在330~340W之间,但是GPU的温度一直维持在60℃左右,甚至在多卡同时运行时,GPU的温度也能保持在60℃左右,可以看出NF5468A5的散热设计做得相当不错。
3. NF5468A5服务器测评总结
通过对产品外观和内部设计的评测,我们看到,浪潮NF5468A5在产品设计上,存储、计算、风扇、GPU扩展等各模块简洁明朗,尤其是巧妙的分区散热设计有效实现CPU与GPU模组的分流,丰富的存储+IO扩展性,同时人性化的设计以扎实的做工,也彰显出浪潮对产品细节的严谨和大厂雄厚的设计实力。
在整体实际性能的综合测试,得益于浪潮高效的产品架构,最大发挥CPU与GPU之间的通讯效能,处理器计算效率达到93.74%,实测内存带宽373 GB/s,搭配8张A100训练ResNet50模型得到每秒处理21486张图片的惊人算力,在ImageNet数据集下进行ResNet50推理测试展现超出T4标称13%的图片处理能力,这台算力猛兽全方位的表现,相信给笔者和大家都留下了深刻的印象。
此外,ETHASH算法单卡性能突破100MH/s;很好地支持寒武纪国产推理卡,轻松实现每秒处理图片超7000张;搭载视频转码卡M10A展示了480fps 1080P视频转码性能。浪潮NF5468A5还有很多意想不到的潜能,笔者期待进一步的发掘,给大家带来更精彩的评测。
责任编辑:彭菁
-
浪潮
+关注
关注
1文章
461浏览量
23871 -
视频编解码
+关注
关注
2文章
54浏览量
11755 -
gpu服务器
+关注
关注
1文章
19浏览量
4387
发布评论请先 登录
相关推荐
双料世界纪录,被浪潮NF8380M5服务器“踩”在脚下
浪潮服务器支持赛灵思Alveo FPGA加速卡将全面上市
浪潮服务器将全面支持赛灵思FPGA加速卡
浪潮推出支持赛灵思 Alveo FPGA加速卡的服务器
浪潮发布的最新AI服务器,将GPU资源利用率提升至前所未有的水平
浪潮推出AI服务器新产品,可满足日趋复杂且多元的AI计算需求
浪潮发布AI服务器NF5488A5,计算性能提升234%
浪潮宣布支持NVIDIA的AI服务器NF5488M5-D和NF5488A5全球量产供货
浪潮宣布支持NVIDIA最新GPU的AI服务器全球量产供货
浪潮AI服务器NF5488A5的实测数据分享,单机最大推理路数提升88%

浪潮服务器NF5488A5展现“AI机王”风采,获权威媒体STH 高度赞誉
浪潮GPU服务器NF5468A5的深度评测





 工商网监
工商网监
评论