 在这个项目中,将在线和离线TSM网络部署到FPGA,通过2D CNN执行视频理解任务。
在这个项目中,将在线和离线TSM网络部署到FPGA,通过2D CNN执行视频理解任务。
在这个项目中,将在线和离线 TSM 网络部署到 FPGA,通过 2D CNN 执行视频理解任务。
介绍
在这个项目中,展示了 Temporal-Shift-Module ( https://hanlab.mit.edu/projects/tsm/)在 FPGA 上解决视频理解问题的实用性和性能。
TSM 是一种网络结构,可以通过 2D CNN 有效学习时间关系。在较高级别上,这是通过一次对单个帧(在线 TSM)或多个帧(离线 TSM)执行推理并在这些张量流经网络时在这些张量之间转移激活来完成的。这是通过将shift操作插入 2D 主干网的bottleneck层(在本例中为 mobilenetv2 和 resnet50)来完成的。然后,该shift操作会打乱时间相邻帧之间的部分输入通道。
详细的解析可以看下面的文章:
❝
https://zhuanlan.zhihu.com/p/64525610
❞
将这样的模型部署到 FPGA 可以带来许多好处。首先,由于 TSM 已经在功效方面带来了巨大优势,部署到 FPGA 可以进一步推动这一点。
TSM网络结构
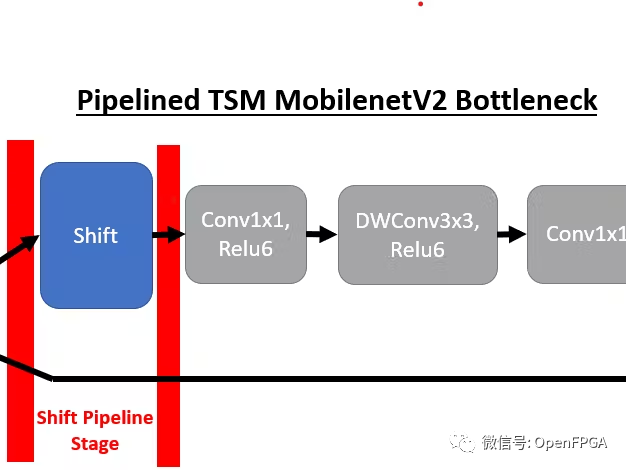
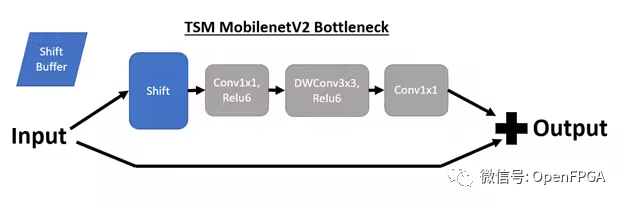
我们将首先回顾这些 TSM 网络的底层结构以及到 DPU 兼容实现的转换。TSM 网络的核心结构是插入骨干模型bottleneck层中的时间shift模块,以实现时间建模。例如,插入shift操作后,TSM MobilenetV2 bottleneck层具有以下结构:
Online Shift
在演示的在线 TSM 网络中,如果我们处于时间步骤 T,我们也处于推理轮 T。shift模块将输入通道的前 1/8 移位到包含来自上一推理轮的相同通道的shift缓冲区( T – 1)。然后,第 (T – 1) 轮的内容被移入 T 轮的当前张量。
Offline Shift
对于离线 TSM,如 resnet50 演示(当前禁用)中所使用的,shift缓冲区被绕过。相反,我们将N 个相邻的时间步骤作为批次中的张量进行处理。通道可以在批次内直接移动,而不是将步骤 (T – 1) 中的通道存储在缓冲区中。此外,这使得能够访问批次内的未来回合(即推理步骤 T 可以与步骤 T + 1 存在于同一批次中)。通过这种访问,离线shift也会将通道从步骤 T + 1 移位到步骤 T 的张量中。
DPU模型优化
为了将TSM部署到 DPU,需要对原始 TSM 模型进行两项重大更改。第一个是将shift模块与网络分离,因为我们无法使用支持的张量流操作来实现shift操作。为了实现这一目标,我们在每次出现shift模块时对模型进行管道化。
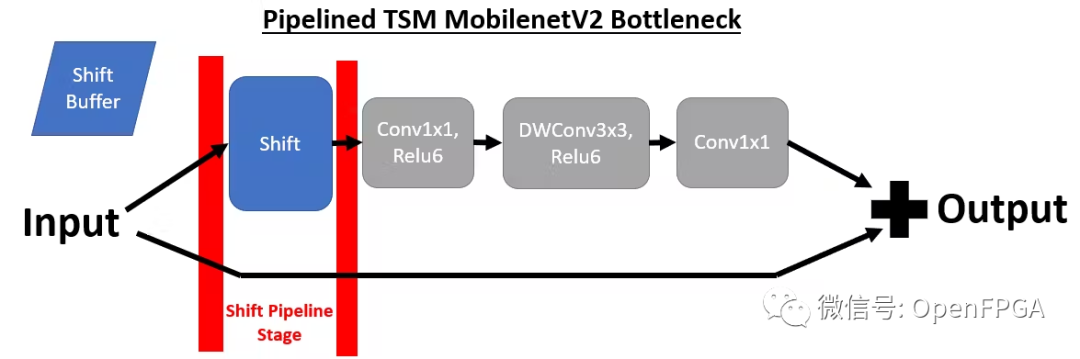
通过将shift模块放置在其自己的管道阶段,我们可以灵活地从 DPU 内核卸载shift操作。下面我们可以看到 MobilenetV2 在线 TSM 的前 4 个管道阶段(从右到左)。如果比较两个bottleneck层实现,并删除shift操作,则这对应于以下转换,其中bottleneck层在移位模块之前包含 1 个输出,在shift模块之后包含 2 个输入。一个输入包含来自顶部分支的移位后张量,另一个输入包含底部分支中未移位的残差张量。
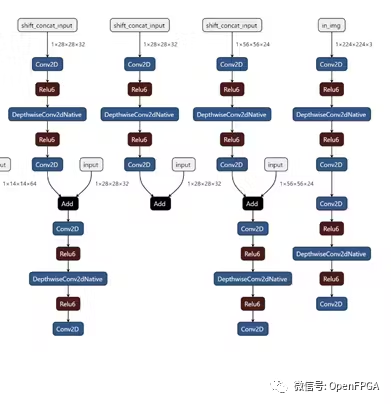
为简单起见,这里我们使用 mobilenetV2 主干网来可视化 TSM,但 resnet-50 主干网也使用相同的方法。
为了实现这种流水线结构, Tensorflow 模型中有一个标志,指示我们是否要生成不包括移位操作的拆分模型(用于 DPU 部署)或在 Tensorflow 中实现移位操作的普通统一模型。如果设置了分割标志,则在每次移位操作之前添加新的输出,并在移位后添加新的占位符,其中输入移位后的输入。
因为移位(shift)模块仅插入到类似于上面所示的 3 级 MobilenetV2 瓶颈的结构中,所以逻辑的实现得到了简化。然而,对于 resnet 模型,我们确保在快捷路径中的归约逻辑之后插入移位管道阶段。由于移位+卷积路径在瓶颈层完成之前独立于快捷路径,因此快捷路径上的操作可以放置在3个阶段中的任何一个中。
DPU量化策略
虽然如上所述对模型进行流水线化简化了转换实现,但由于我们的网络不再是单个内核,因此使 DPU 部署变得复杂。相反,我们为每个管道阶段都有一个内核,无需进行移位操作(MobilenetV2 为 11,resnet50 为 17)。
为了量化这样的网络,我们必须为每个内核提供未量化的输入。为了生成这些信息,我们的模型可以在没有管道阶段的情况下生成。然后,我们直接在 Tensorflow 中对来自真实校准数据集的帧进行推理,但是我们在每个管道边界转储中间网络状态。转储的状态包括需要馈送到 vai_q_tensorflow 的节点名称等元数据以及相应的张量数据。当在校准集中重复推理时,所有这些信息都会被“波及”。
转储此中间推理信息后,我们获得了输入 vai_q_tensorflow 的每个内核的输入张量。该逻辑全部由我们的tensorflow模型脚本和quantize_split.sh脚本中的DUMP_QUANTIZE标志处理(项目结构在“Deployment”部分中描述)。一旦对所有内核运行量化,我们就可以为每个内核生成一个 ELF 文件,就可以集成到我们的主代码中。
演示
下面我们介绍 2 个平台(ZCU104 和 Ultra96V2)和 2 个模型(MobilenetV2 Online TSM 和 Resnet50 Offline TSM)的性能细分。我们将 FPS 计算为 1/(预处理 + 推理延迟)。
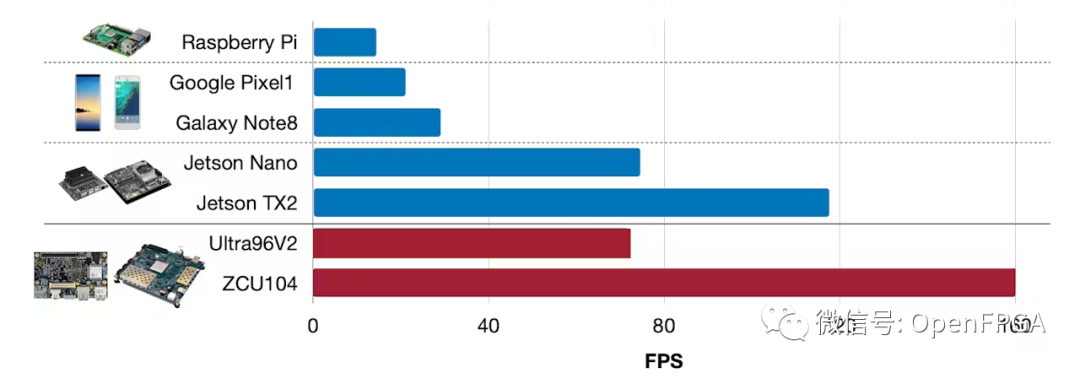
MobilenetV2 在线 TSM 延迟:
ZCU104 (60.1 FPS) - B4096,300MHz,RAM 高,启用所有功能

Ultra96V2 (38.4 FPS) - B2304,300MHz,RAM 低,启用所有功能

现在,我们可以将推理延迟与之前在移动设备和 NVIDIA Jetson 平台上收集的 TSM 数据进行比较。
部署
上面演示的所有代码都位于 TSM github 存储库的 fpga 分支中:
❝
https://github.com/mit-han-lab/temporal-shift-module
❞
环境设置
要为上面这些设置开发环境,按照此处所述进行初始 Vitis-AI 环境设置:
❝
https: //github.com/Xilinx/Vitis-AI
❞
使用的 ZCU104 DPU 映像如下所述:
❝
https: //github.com/Xilinx/Vitis-AI/tree/master/mpsoc
❞
ZCU104 VCU 映像是按照此处所述的 ivas 示例应用程序构建的:
❝
https://github. com/Xilinx/Vitis-In-Depth-Tutorial/tree/master/Runtime_and_System_Optimization/Design_Tutorials/02-ivas-ml
❞
Ultra96V2 映像是根据 2020.1 Avnet BSP 构建的,并在 petalinux 构建时启用 Vitis-AI
❝
https://github.com/Avnet/vitis/tree/2020.1
❞
参考文献
❝
https://www.hackster.io/joshua-noel/tsm-networks-for-efficient-video-understanding-on-fpga-f881ba
❞
❝
https://hanlab.mit.edu/projects/tsm/
❞
❝
https: //github.com/Xilinx/Vitis-AI/tree/master/mpsoc
❞
❝
https://github.com/Avnet/vitis/tree/2020.1
❞
代码
❝
https://github.com/mit-han-lab/temporal-shift-module/tree/master/tsm_fpga
❞
-
FPGA
+关注
关注
1629文章
21742浏览量
603543 -
模块
+关注
关注
7文章
2713浏览量
47494 -
TSM
+关注
关注
0文章
7浏览量
6573
发布评论请先 登录
相关推荐
怎么在xC8中传递和返回2D数组
怎么在xC8中传递和返回2D数组?
理解任务切换和任务状态改变的关键是什么?
如何移植一个CNN神经网络到FPGA中?
可分离卷积神经网络在 Cortex-M 处理器上实现关键词识别
2D到3D视频自动转换系统
一款只通过单个普通的2D摄像头就能实时捕捉视频中的3D动作的系统
通过2D NoC可实现FPGA内部超高带宽逻辑互连






 工商网监
工商网监
评论