 M7S架构设计内幕
M7S架构设计内幕
Go语言本身具备出色的性能,然而在流媒体服务器这种CPU密集+IO密集的双重压力下,GC带来的性能损失是最主要的矛盾。而减少GC的操作最直接的办法就是减少内存申请,多多复用内存。本文将围绕内存复用这个主题,把M7S中相关技术原理讲解一遍,也是M7S性能优化的历程。
读写内存共享
在早期我在研究过许多流媒体服务器的数据转发模式,基本都是在发送给订阅者时将内存复制一份的方式实现读写分离,虽然没有并发问题,但是内存频繁的申请和复制比较消耗资源。
在M7S v1版本中,也沿用了传统的方式。然而Go语言由于采用GC的方式管理内存,导致频繁申请内存会加大GC的压力。
在网友的启发下,从v2版本开始,采用了基于RingBuffer的内存共享读写方式。大大减少了内存复制。
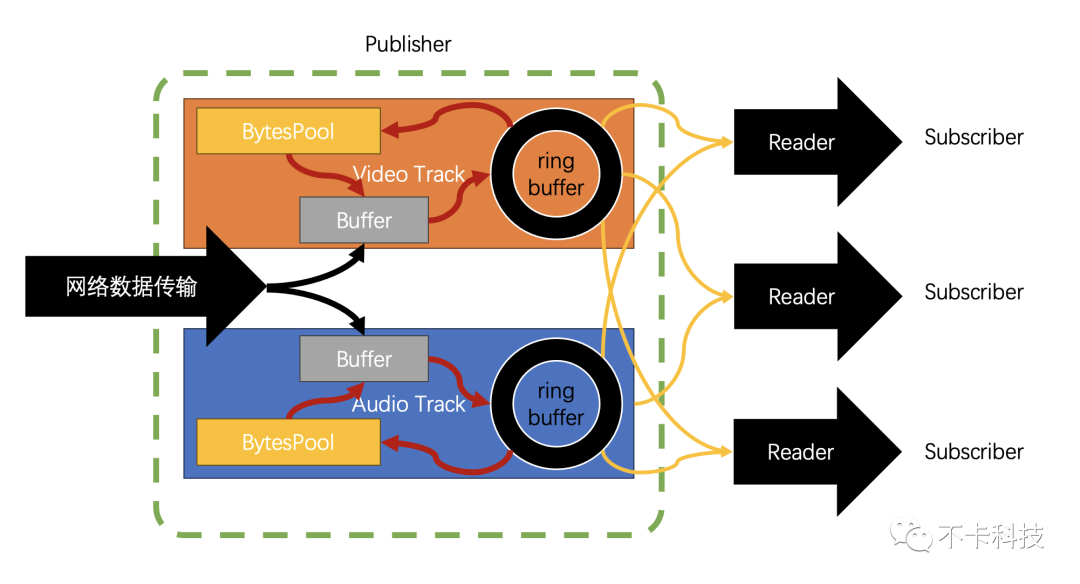
在
Monibuca中每一个流(Stream)对象包含多个Track(分为音视频Track和DataTrack)每个Track包含一个RingBuffer。发布者将数据填入这个RingBuffer中,订阅者则从RingBuffer中读取数据再封装到协议中发送出去,形成转发的核心逻辑。
下面的视频是当时开发的一个UI,实时获取RingBuffer的信息用SVG绘制而成。其中发布者正在不断写入数据,订阅者紧随其后不断读取数据。
由于发布者以及订阅者不在同一个协程中,访问同一个块内存很有可能引起并发读写的问题。如何解决并发读写呢?M7S 经过不断的迭代在这块上面实践了各种方法。既要考虑到性能,还要考虑到代码的可读性和可维护性。
sync.RWMutex
这是最容易想到的,在M7Sv2中就采用了读写锁。操作步骤如下:
- 先锁住Ring中的下一个待写入单元,再将本次写完的单元释放写锁。
- 在本读写单元中等待读取的订阅者在写锁释放的同时获取到读锁,开始读取数据
优点是可读性很强,一眼就能看懂这个原理。缺点是,锁的开销比较大,性能损失很明显。还有一个缺点,就是当订阅者阻塞,会导致发布者追上订阅者,写锁无法获取从而阻塞整个流。(后来Go出了TryLock)
WaitGroup
v3 中采用了这个,但是WaitGroup的Wait操作是一个无限阻塞的操作,必须用Done操作才能结束等待,此时就会有一个问题,engine和发布者有可能会同时去调用Done完成释放(具体原因另开章节介绍)。因此Done就会多调用一次导致panic。后来通过复杂的原子操作解决了(但是大大降低了代码的可读性)。
time.Sleep
v4 中采用了伪自旋锁,所谓的伪自旋锁,就是模仿自旋锁的机制,只是用time.Sleep代替了,runtime.Gosched,减少了自旋次数,从而提高性能。
forr.Frame=&r.Value;r.ctx.Err()==nil&&!r.Frame.CanRead;r.Frame.wait(){
}
CanRead不需要原子操作,有人担心可能会有并发读写问题,其原理同前面说的人走路是一样的,即便出现了并发读写,也不影响逻辑正确运行。最多就是多等待一个周期,稍微增加一点点延迟。
sync.Cond
在v1版本中由于使用的是简单的内存复制,于是有人给了这个方案,但是我却一直绕了一大圈,最后回到这个方案上了,也算是自作聪明。sync.Cond之所以一开始没有选择,是因为里面包含了一个锁(标准库内部强制调用了锁)
func(c*Cond)Wait(){
c.checker.check()
t:=runtime_notifyListAdd(&c.notify)
c.L.Unlock()
runtime_notifyListWait(&c.notify,t)
c.L.Lock()
}
所以就认为性能不高,直到绕了一大圈之后,才找到一个避免锁的方案。当然这些弯路可能必须要走,因为直到自己写了伪自旋锁,才增加了一个是否可读的属性,也就是说有了这个属性后,我们其实只需要一个唤醒的功能即可,于是想到了给sync.Cond提供一个空的锁对象的方式避免了锁:
typeemptyLockerstruct{}
func(emptyLocker)Lock(){}
func(emptyLocker)Unlock(){}
varEmptyLockeremptyLocker
sync.Cond在唤醒协程的时候使用的是Broadcast方法,这个方法可以多次调用而无副作用(不像WaitGroup的Done方法)。也可以减少伪自旋锁带来的轻微延迟。
实际测试中使用Cond比伪自旋锁大概可以节省10%左右的CPU消耗
协议转换中的内存复用
协议转换可以用下面的逻辑来实现:
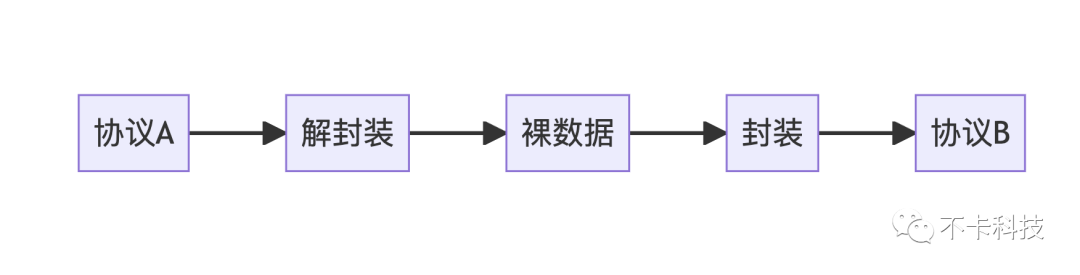
实际情况比这个要复杂一些。所以这里面第一步需要引入go标准库中的net.Buffers来表示“连续的内存”(实际并不一定连续)。当收到一个协议传来的数据时尽量保留,而不去复制它。
同一个协议转发
对于相同的协议,能复用的内存更多一些,举个例子:
RTMP转发到RTMP
RTMP中传输视频帧的格式为AVCC格式,这也是能复用的部分,在实际传输过程中这部分内存并非一个连续内存。RTMP有chunk机制,会把AVCC切割一块块传输,并加上chunk header。
chunkheader|avccpart1|chunkheader|avccpart2······
这个分割的大小默认是128字节,通常RTMP协议会经过协商修改这个大小,因此传入和传出的分块大小不一定相同。那如何复用AVCC的数据呢?此时我们需要用到net.Buffers来表示一帧AVCC数据。
|avccpart1|avccpart2······
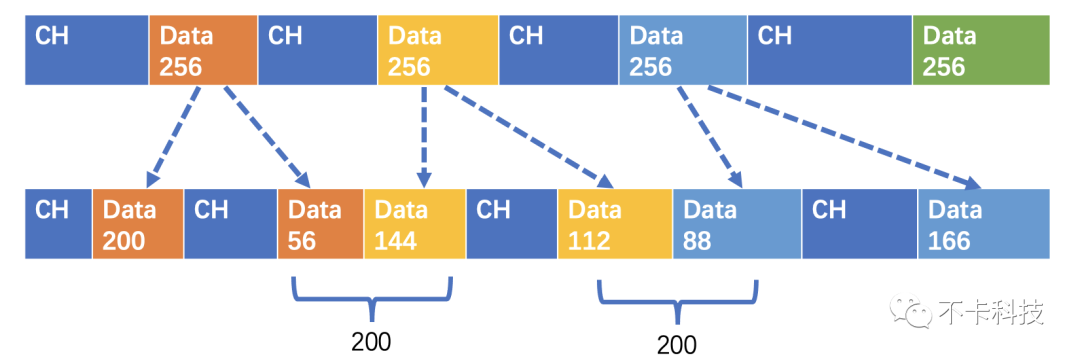
当我们需要另一种分块大小的数据时,可以对原始数据再分割。比如说原始数据是256字节分块的:
|256Bytes|256Bytes······
而新的分块要求是128Bytes的
|128Bytes|128Bytes|128Bytes|128Bytes······
我们并没有申请新的内存,只是多了一些切片。那有人就可能会问了,如果不是正好倍数关系呢?其实无非就是多切几块。比如新的分块要求是200Bytes:
|200Bytes|56Bytes|144Bytes|112Byts|88Bytes······
用下面的图更加直观:
这样发送的时候,并不是一个连续内存,那如何发送呢?这里就用到了writev(windows对应的是WSASend)技术。在Go语言中通过net.Buffers类型写入数据会自动判断使用的技术。
RTSP转发到RTSP
RTSP协议传输的媒体数据是RTP包,RTP包在理想状态下,可以完全复用,就是直接把RTP包缓存起来,等需要发送的时候直接把这个RTP数据原封不动的发出去。在m7s中,由于需要有跳帧追帧的逻辑,所以需要修改时间戳,就无法原封不动的发送RTP包,但是也可以复用其中的Payload部分。
HLS转发到HLS
在纯转发模式下,可以直接将TS切片缓存,完全复用。如果需要将HLS转换成其他协议,则需要将TS格式数据进行解包处理。
FLV转发到FLV
FLV格式由于数据格式也是avcc格式,因此处理逻辑就按照avcc格式统一处理了,FLV的tag头无法复用,涉及到时间戳需要重新生成。
不同协议转发
不同协议之间转发由于两两排列组合很多,因此需要抽象出大类来处理。
协议分类
RTMP、FLV、MP4
该类协议视频是AVCC格式,音频是裸格式(RTMP包含一到两个字节的头)
RTSP、WebRTC
该类的视频是RTP(Header+裸NALU)音频是RTP(Header + AuHeaderLen + AuHeaderxN + AuxN )
HLS、GB28181
这类使用的MPEG2-TS、MPEG2-PS作为传输协议视频采用Header+AnnexB音频采用Header+ADTS+AAC
内存复用
总体而言,视频格式都是前缀+NALU这种方式,AnnexB的前缀是00 00 00 01,而Avcc的前缀是 CTS、 NALU长度等,因此将NALU缓存起来就可以复用NALU数据。在实际实现中,为了方便同类型的协议转换,会同时缓存Avcc格式、RTP格式、以及裸格式,而这三种格式的NALU部分都共用一组内存(内存不连续)
减少发布者的GC
GC的产生
对于一个发布者,即需要不断从网络或是本地文件中读取数据的对象,在不做任何优化的情况下,都会不停的申请内存。例如使用io.ReadAll这种操作,内部会频繁的申请内存。频繁申请内存的结果就是GC压力很大,尤其是高并发的时候,GC带来的消耗可以达到50%的CPU消耗。
sync.Pool
当然我最先想到的一定是使用内存池,也就是sync.Pool来管理需要使用的内存,但是sync.Pool有个缺陷,就是为了协程安全内部有锁。尽管使用了多级缓存等一些列优化手段,最终使用的时候也会消耗一定的性能(经过实测性能开销很大)。而且sync.Pool比较通用,并不是针对特定的对象使用,我们这里是针对[]byte类型进行复用。
自定义Pool
如果Pool不含有锁,性能会大幅提升,那如何解决协程安全呢?答案是协程不安全,即我们只在一个协程里面去操作Pool的取出和放回。通常情况下一个发布者的写入是在同一个协程中的,比如rtmp协议。少数协议如rtsp可能会有多个协程写入数据,因此最后我们是每一个Track一个Pool,保持一个Track一个协程写入。
下图表示的是自定义Pool的结构:
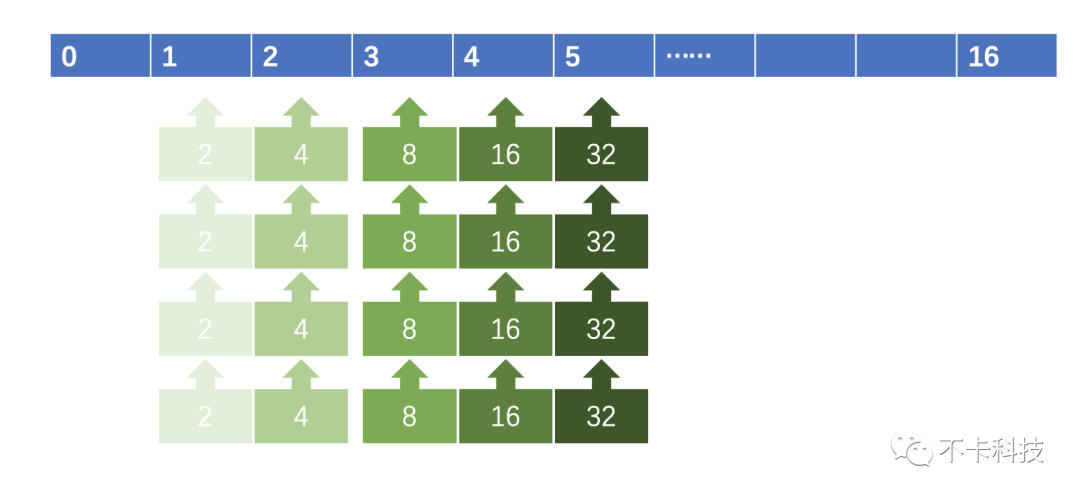
每个Pool是一个数组,数组的每一个元素是一个链表,链表的每一个元素是一个包含[]byte的类型,大小是2的数组下标次幂。
0号元素有特殊用途,由于我们需要记录每一块内存所属的链表来回收,因此需要有一个外壳,而外壳(ListItem)也是需要回收的。而0号元素是存放的只有外壳需要回收而无需回收Value(需要GC的对象)的链表。
typeList[Tany]struct{
ListItem[T]
Lengthint
}
typeListItem[Tany]struct{
ValueT
Next,Pre*ListItem[T]`json:"-"yaml:"-"`
Pool*List[T]`json:"-"yaml:"-"`//回收池
list*List[T]
}
typeBytesPool[]List[Buffer]
回收内存
当RingBuffer中的访问单元被覆盖时,就可以将其中所有的内存对象进行放回Pool。由此实现了从内存使用的闭环,消除了GC。下图中红色箭头代表内存复用机制,可以有效避免申请内存操作。
后记
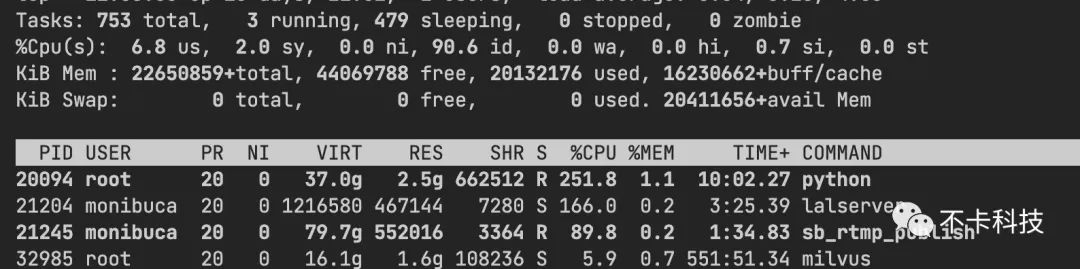
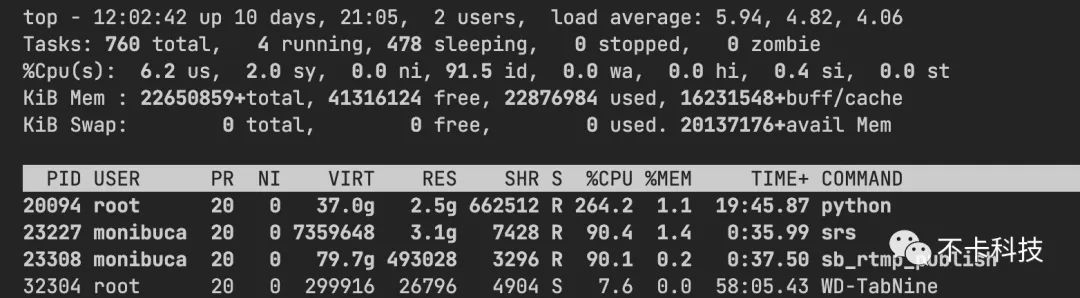
经过上面三板斧的优化后,整体性能提升了50%以上。下图测试10000路rtmp推流的对比:m7s内存占用较高一些,原因就是采用了内存池来减少GC造成的。使用内存来换CPU,在这种场景下还是值得的。


| 流媒体服务器 | 10000路推流CPU消耗 |
| monibuca | 90%~100% |
| zlm | 90%~100% |
| srs | 80%~90% |
| lal | 160%~200% |
由于livego的推流需要先调用一次HTTP获取密钥,所以无法使用压测工具批量推流,本次对比无法参与。
所有流媒体服务器配置均关闭了协议转换的开关,并以Release方式编译。服务器也去除了所有限制,并以完全相同的操作方式进行压测。
-
服务器
+关注
关注
12文章
9410浏览量
86440 -
架构设计
+关注
关注
0文章
32浏览量
6995 -
go语言
+关注
关注
1文章
158浏览量
9143
原文标题:方法)。也可以减少伪自旋锁带来的轻微延迟。
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
kintex产品架构设计文档(成为架构师也是电子人不错的选...
基于ARM架构设计的M1芯片
STM32软件架构设计的意义
对嵌入式系统中的架构设计的理解
富可视发布全面屏新机“M7s”:前后摄像头同时拍摄
ARMv7-M嵌入式架构的特点是什么
系统架构设计的详细讲解
SWE.2的软件架构设计
SYS.3的系统架构设计
架构与微架构设计





 工商网监
工商网监
评论