 【AI简报20230707】中国团队推出「全球首颗」AI 全自动设计 CPU!重磅,GPT-4 API 全面开放使用!
【AI简报20230707】中国团队推出「全球首颗」AI 全自动设计 CPU!重磅,GPT-4 API 全面开放使用!
1. 仅用 5 小时!中国团队推出「全球首颗」AI 全自动设计 CPU,性能比肩 Intel 486!
原文:https://mp.weixin.qq.com/s/DNBO34Xk2nVwNiEMBjJ-Cg
在这场由 ChatGPT 掀起的 AI 热潮下,越来越多人开始看到如今 AI 的强悍:AI 作图、AI 写论文、AI 编代码、AI 预测完整人类蛋白质组结构、AI 发现速度提升 70% 的新排序算法……
既然 AI 看似“无所不能”,许多人便提出了疑问:“那 AI 真的能像人类一样进行设计工作吗?”在预测蛋白质结构和生成编码等方面,AI 确实表现卓越,但在设计这些物体时,总体而言 AI 的搜索空间还相对较小。
为了探寻 AI 设计能力的极限,近日中国中科院计算所等机构将目标放在了芯片设计上,因为“它是计算机的大脑,也是目前人类所设计的世界上最复杂的设备之一。”
结果,最终数据出人意料:中国中科院计算所等机构利用 AI 技术,设计出了全球首个无人工干预、全自动生成的 CPU 晶片“启蒙 1 号”——整个训练过程不到 5 小时,验证测试准确性却能达到 >99.999999999%!
1. 在无人干预的情况下,让 AI 设计出工业级 CPU
根据相关论文《突破机器设计的极限:利用 AI 进行自动化 CPU 设计(Pushing the Limits of Machine Design: Automated CPU Design with AI)》介绍,这场研究的目的是:赋予机器自主设计 CPU 的能力,以此探索机器设计的边界。
“如果机器能够在无人干预的情况下设计出工业级 CPU,不仅可以显著提高设计效率,还能将机器设计的极限推向接近人类性能的水平,从而推动半导体产业的革命。”论文中还补充道:“自行设计机器的能力,即自我设计,可以作为建立自我进化机器的基础步骤。”
有了基本方向后,即要在没有人工编程的情况下自动化 CPU 设计,团队研究人员决定通过 AI 技术,直接从“输入-输出(IO)”自动生成 CPU 设计,无需人类工程师手动提供任何代码或自然语言描述。
简单来说,传统 CPU 设计需要投入大量人力,包括编写代码、设计电路逻辑、功能验证和优化工作等等。但通过将 CPU 自动设计问题转化为“满足输入-输出规范的电路逻辑生成问题”后,只需要测试用例,便可以直接生成满足需求的电路逻辑——这使得传统 CPU 设计流程中极其耗时的“逻辑设计”和“验证环节”,都被省去了。
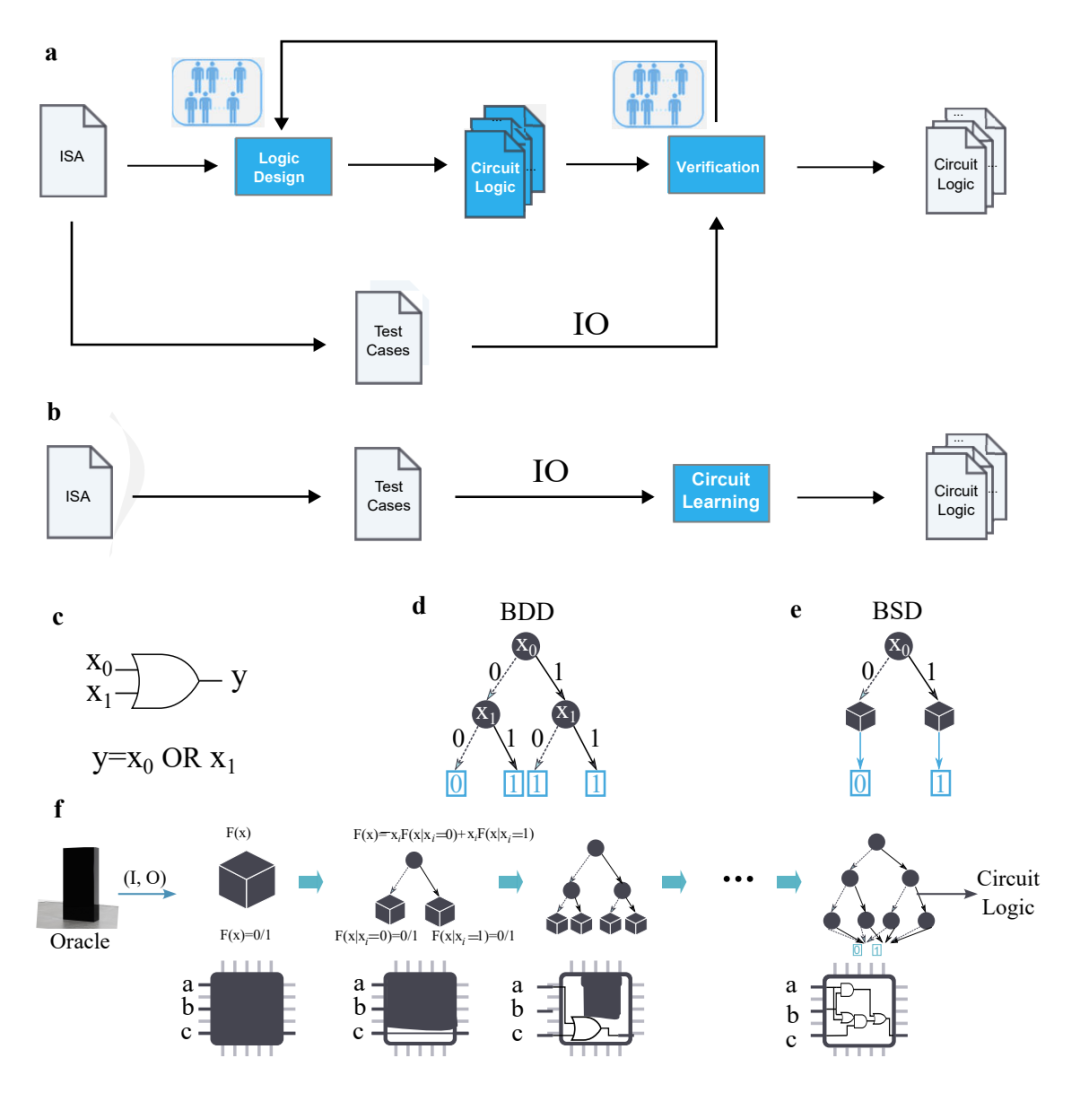
想顺利开启这样的自动化 CPU 设计流程,需要提前对 AI 进行训练,包括观察一系列 CPU 输入和输出,因此论文中才强调该 CPU 的设计是“仅从外部输入-输出观察中形成的,并非正式的程序代码”。
从这些输入和输出中,研究人员生成了一个 BSD 二元猜测图(Binary Speculation Diagram,简称 BSD)算法,并利用基于蒙特卡罗的扩展和布尔函数的原理,大幅提高了基于 AI 进行 CPU 设计的准确性和效率。
2. 可与 Intel 486 系列媲美
通过以上逐步地推敲,一个 CPU 的自动化 AI 设计流程就成型了:仅用 5 小时就生成 400 万逻辑门,全球首款无需人工干预、全自动生成的 CPU 芯片也就此诞生——启蒙 1 号。
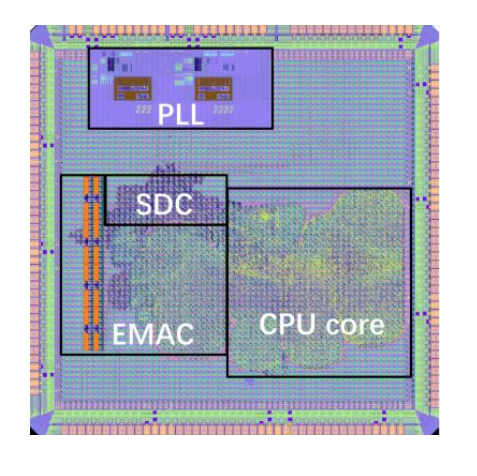
据论文介绍,启蒙 1 号基于 RISC-V的 32 位架构,采用 65nm 工艺,频率可达 300MHz,且可运行 Linux 操作系统。另据媒体报道,相较于现阶段 GPT-4 能设计的电路规模,启蒙 1 号要大 4000 倍。

此外在 Drystone 基准测试中,启蒙 1 号的性能不仅可比肩由人类设计的 Intel 486 系列 CPU,还比 Acorn Archimedes A3010 更快一些。
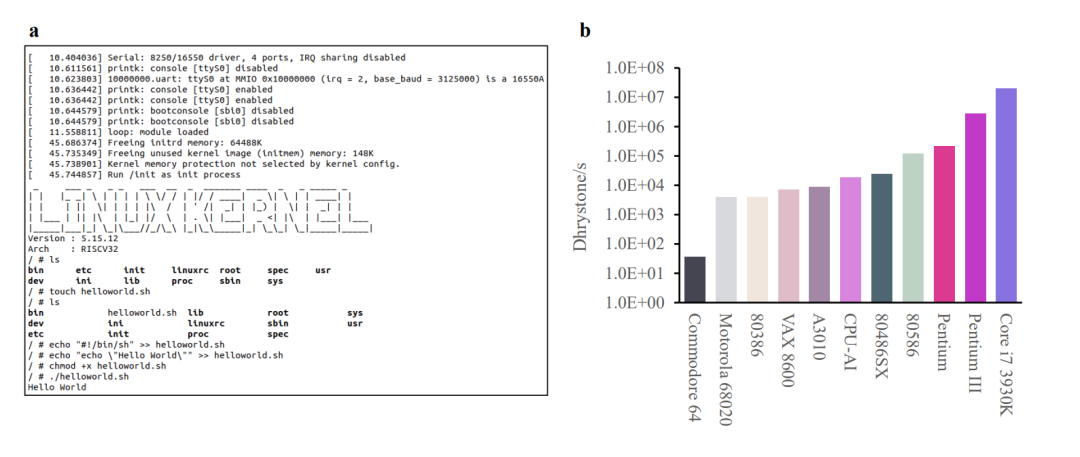 更值得一提的是,这颗完全由 AI 设计的 32 位 RISC-V CPU,其设计周期比人类团队完成类似 CPU 设计的速度,快了近 1000 倍,验证测试准确性也能达到 >99.999999999%。
更值得一提的是,这颗完全由 AI 设计的 32 位 RISC-V CPU,其设计周期比人类团队完成类似 CPU 设计的速度,快了近 1000 倍,验证测试准确性也能达到 >99.999999999%。
不过,有些人可能对于这款由 AI 设计的启蒙 1 号并不在意,毕竟与它性能相近的 Intel 486 系列 CPU(Intel 80486SX),早已是诞生于上世纪 1991 年的“老芯片”了。但研究人员对于启蒙 1 号的开发依旧很自豪:在整个 AI 自动化设计过程中,他们生成的 BSD 算法,甚至还自主发现了冯·诺伊曼架构(一种将程序指令存储器和数据存储器合并在一起的电脑设计概念结构)。
3. 完全由 AI 生成的 CPU 有望超过人类?
平心而论,作为全球首款 AI 自动生成的芯片,启蒙 1 号的性能和规模根本无法与当前顶级的主流 CPU 相比,但正如论文开篇所说,这场实验本身就不是为了开发高性能芯片,而是“探索机器设计的边界”。
让 AI 从头开始构建一个新 RISC-V CPU,其背后的真实意义在于:研究 AI 未来能否用于减少现有半导体行业的设计和优化周期。
如果从这个角度来看,此次中国中科院计算所等机构进行的这项实验,就有了初步的结论:与传统人类设计的 CPU 相比,启蒙 1 号的研发周期缩短了近 1000 倍,因为传统 CPU 设计流程中耗时极长的手动编程和验证过程完全被省略了。
“我们的方法改变了传统的 CPU 设计流程,并有可能改革半导体行业。”在论文的最后,研究人员对于由 AI 完全设计芯片的未来做出展望:“除了提供人性化的设计能力,这种方法还发现了人类知识的冯·诺伊曼架构,未来更有可能产生积极的(甚至未知的)架构优化,这为建立一个自我进化的机器、并最终击败人类设计的最新 CPU 提供了一些启示。”
即研究人员认为,未来通过不断迭代 AI 的芯片设计方式,完全由 AI 生成的 CPU,或许有望达到甚至超越由人类设计的 CPU。那么对于这个说法,你又是否有什么看法吗?
2. 北大法律大模型ChatLaw火了!!
原文:https://mp.weixin.qq.com/s/yFVUh5PqlhNXtJA1NLb5rg
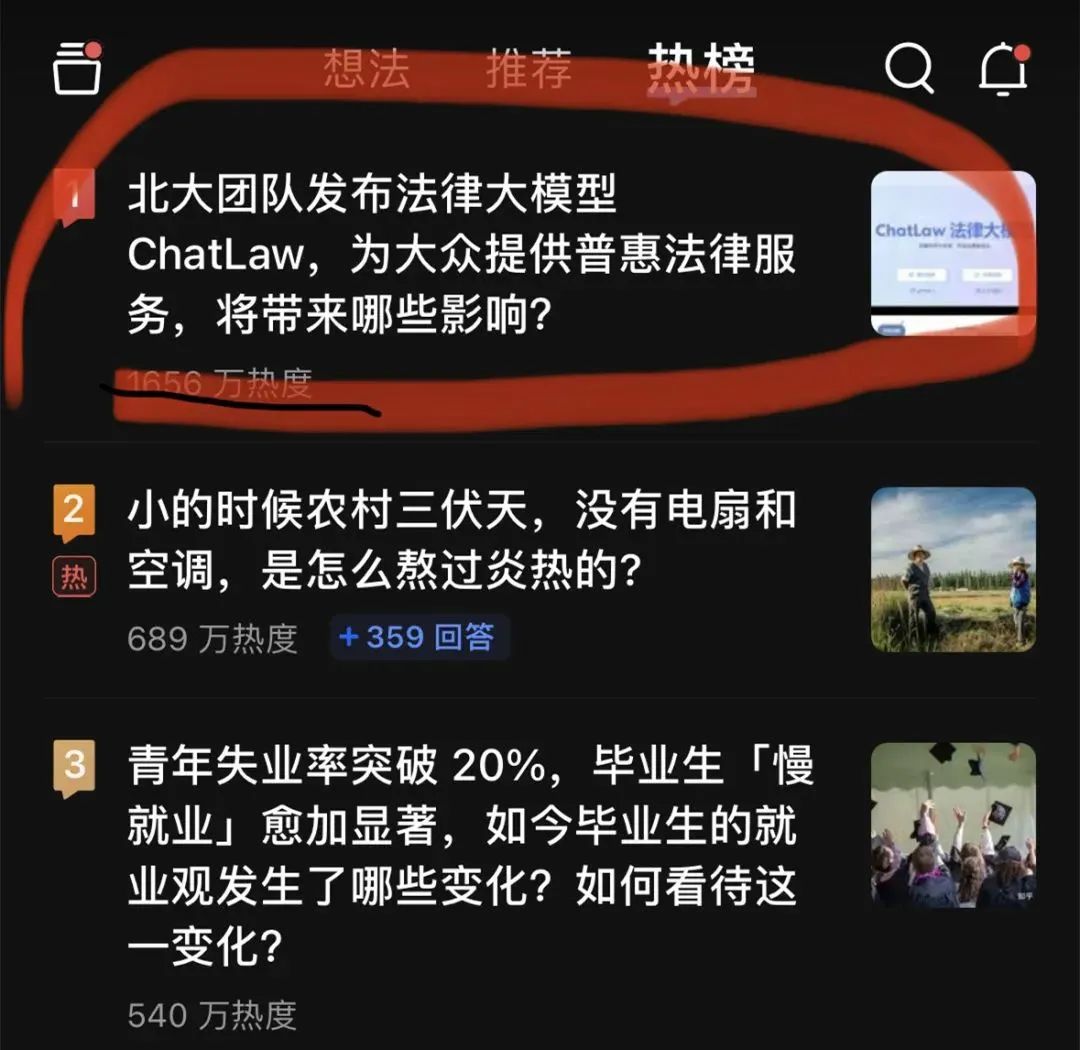
大模型又「爆了」。一个法律大模型 ChatLaw 登上了知乎热搜榜榜首。热度最高时达到了 2000 万左右。
这个 ChatLaw 由北大团队发布,致力于提供普惠的法律服务。一方面当前全国执业律师不足,供给远远小于法律需求;另一方面普通人对法律知识和条文存在天然鸿沟,无法运用法律武器保护自己。
大语言模型最近的崛起正好为普通人以对话方式咨询法律相关问题提供了一个绝佳契机。
目前,ChatLaw 共有三个版本,分别如下:
-
ChatLaw-13B,为学术 demo 版,基于姜子牙 Ziya-LLaMA-13B-v1 训练而来,中文各项表现很好。但是,逻辑复杂的法律问答效果不佳,需要用更大参数的模型来解决;
-
ChatLaw-33B,也为学术 demo 版,基于 Anima-33B 训练而来,逻辑推理能力大幅提升。但是,由于 Anima 的中文语料过少,问答时常会出现英文数据;
-
ChatLaw-Text2Vec,使用 93w 条判决案例做成的数据集,基于 BERT 训练了一个相似度匹配模型,可以将用户提问信息和对应的法条相匹配。根据官方演示,ChatLaw 支持用户上传文件、录音等法律材料,帮助他们归纳和分析,生成可视化导图、图表等。此外,ChatLaw 可以基于事实生成法律建议、法律文书。该项目在 GitHub 上的 Star 量达到了 1.1k。

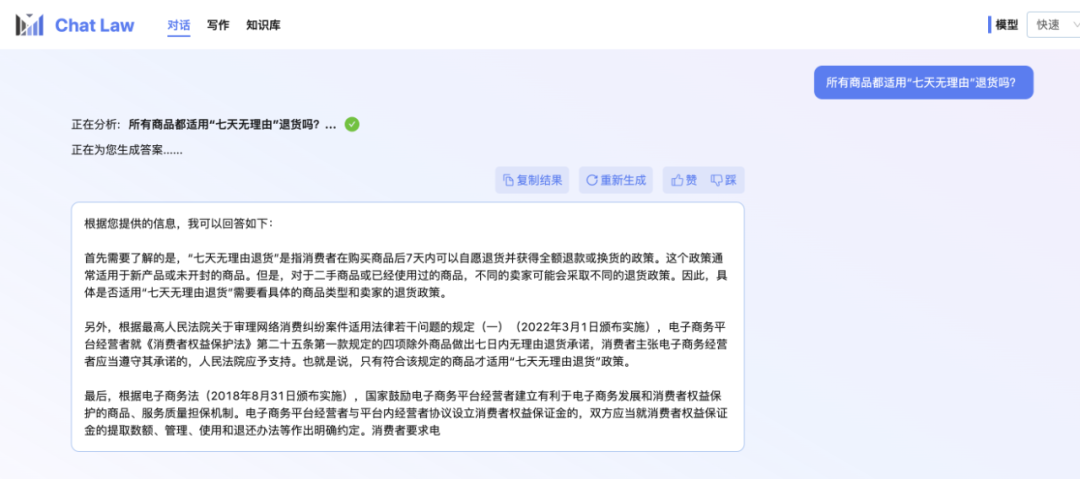
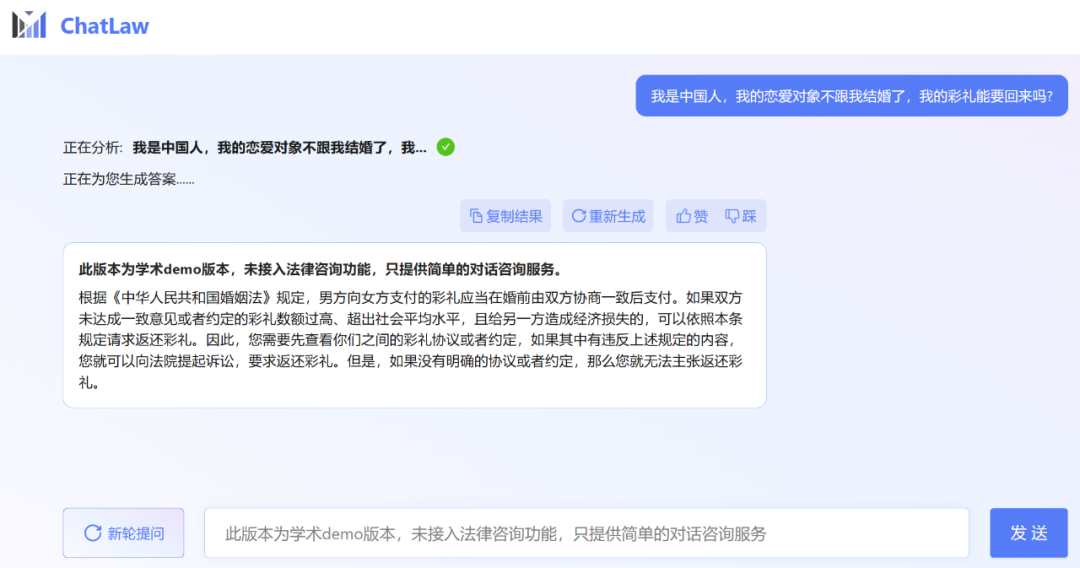
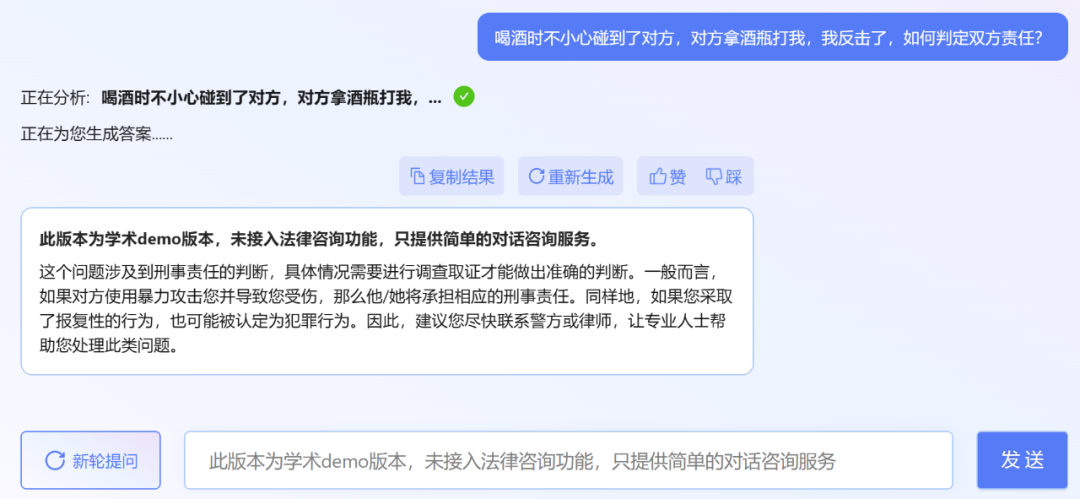
不过,小编发现,ChatLaw 的学术 demo 版本可以试用,遗憾的是没有接入法律咨询功能,只提供了简单的对话咨询服务。这里尝试问了几个问题。
其实最近发布法律大模型的不只有北大一家。上个月底,幂律智能联合智谱 AI 发布了千亿参数级法律垂直大模型 PowerLawGLM。据悉该模型针对中文法律场景的应用效果展现出了独特优势。
ChatLaw 的数据来源、训练框架首先是数据组成。ChatLaw 数据主要由论坛、新闻、法条、司法解释、法律咨询、法考题、判决文书组成,随后经过清洗、数据增强等来构造对话数据。同时,通过与北大国际法学院、行业知名律师事务所进行合作,ChatLaw 团队能够确保知识库能及时更新,同时保证数据的专业性和可靠性。下面我们看看具体示例。
基于法律法规和司法解释的构建示例:

抓取真实法律咨询数据示例:

律师考试多项选择题的建构示例:

然后是模型层面。为了训练 ChatLAW,研究团队在 Ziya-LLaMA-13B 的基础上使用低秩自适应 (Low-Rank Adaptation, LoRA) 对其进行了微调。此外,该研究还引入 self-suggestion 角色,来缓解模型产生幻觉问题。训练过程在多个 A100 GPU 上进行,并借助 deepspeed 进一步降低了训练成本。
如下图为 ChatLAW 架构图,该研究将法律数据注入模型,并对这些知识进行特殊处理和加强;与此同时,他们也在推理时引入多个模块,将通识模型、专业模型和知识库融为一体。
该研究还在推理中对模型进行了约束,这样才能确保模型生成正确的法律法规,尽可能减少模型幻觉。
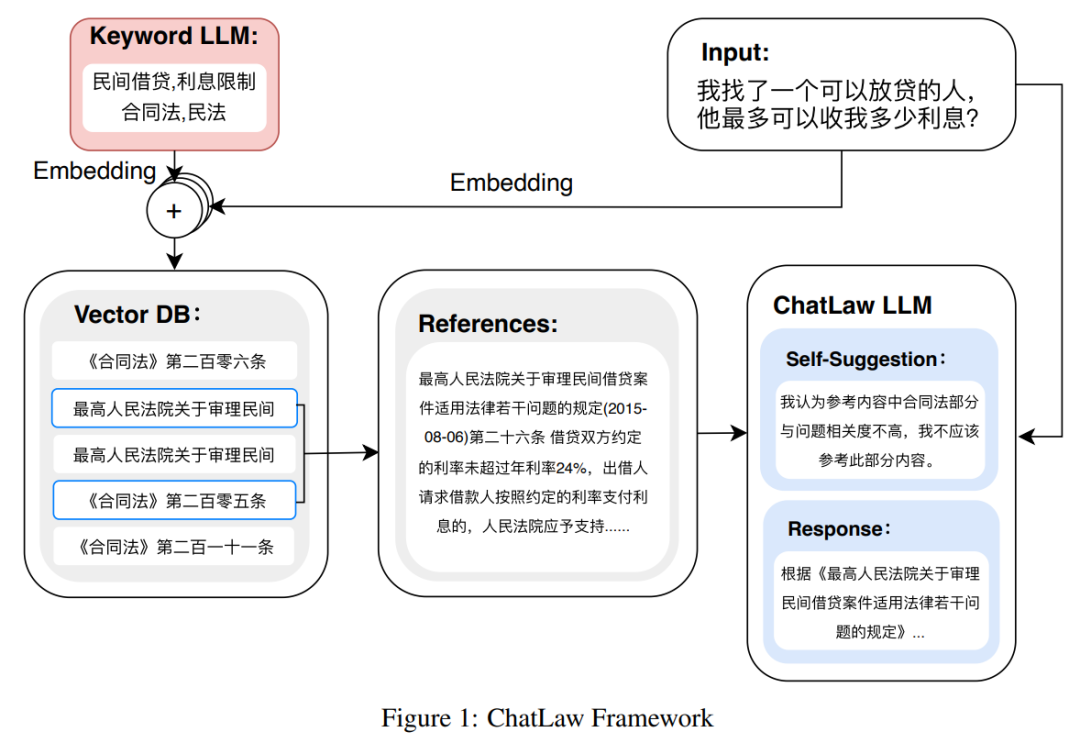
一开始研究团队尝试传统的软件开发方法,如检索时采用 MySQL 和 Elasticsearch,但结果不尽如人意。因而,该研究开始尝试预训练 BERT 模型来进行嵌入,然后使用 Faiss 等方法以计算余弦相似度,提取与用户查询相关的前 k 个法律法规。
当用户的问题模糊不清时,这种方法通常会产生次优的结果。因此,研究者从用户查询中提取关键信息,并利用该信息的向量嵌入设计算法,以提高匹配准确性。
由于大型模型在理解用户查询方面具有显著优势,该研究对 LLM 进行了微调,以便从用户查询中提取关键字。在获得多个关键字后,该研究采用算法 1 检索相关法律规定。

实验结果该研究收集了十余年的国家司法考试题目,整理出了一个包含 2000 个问题及其标准答案的测试数据集,用以衡量模型处理法律选择题的能力。
然而,研究发现各个模型的准确率普遍偏低。在这种情况下,仅对准确率进行比较并无多大意义。因此,该研究借鉴英雄联盟的 ELO 匹配机制,做了一个模型对抗的 ELO 机制,以便更有效地评估各模型处理法律选择题的能力。以下分别是 ELO 分数和胜率图:
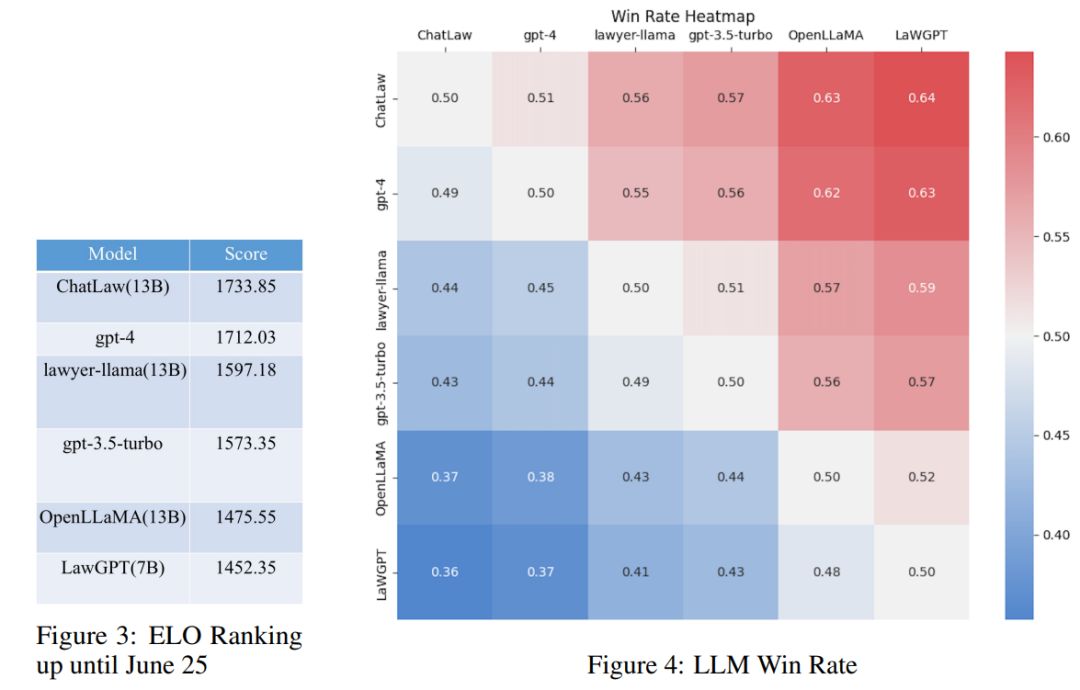
通过对上述实验结果的分析,我们可以得出以下观察结果
(1)引入与法律相关的问答和法规条文的数据,可以在一定程度上提高模型在选择题上的表现;
(2)加入特定类型任务的数据进行训练,模型在该类任务上的表现会明显提升。例如,ChatLaw 模型优于 GPT-4 的原因是文中使用了大量的选择题作为训练数据;
(3)法律选择题需要进行复杂的逻辑推理,因此,参数量更大的模型通常表现更优。参考知乎链接:
https://www.zhihu.com/question/610072848
3. 理解指向,说出坐标!开源模型“Shikra”开启多模态大模型“参考对话”新模式!
原文:https://mp.weixin.qq.com/s/wIkhAcHgqeQ3LA12J6oBnA
在人类的日常交流中,经常会关注场景中不同的区域或物体,人们可以通过说话并指向这些区域来进行高效的信息交换。这种交互模式被称为参考对话(Referential Dialogue)。
如果 MLLM 擅长这项技能,它将带来许多令人兴奋的应用。例如,将其应用到 Apple Vision Pro 等混合现实 (XR) 眼镜中,用户可以使用视线注视指示任何内容与 AI 对话。同时 AI 也可以通过高亮等形式来指向某些区域,实现与用户的高效交流。
本文提出的 Shikra 模型,就赋予了 MLLM 这样的参考对话能力,既可以理解位置输入,也可以产生位置输出。

-
论文地址:http://arxiv.org/abs/2306.15195
-
代码地址:https://github.com/shikras/shikra
Shikra 能够理解用户输入的 point/bounding box,并支持 point/bounding box 的输出,可以和人类无缝地进行参考对话。
Shikra 设计简单直接,采用非拼接式设计,不需要额外的位置编码器、前 / 后目标检测器或外部插件模块,甚至不需要额外的词汇表。

如上图所示,Shikra 能够精确理解用户输入的定位区域,并能在输出中引用与输入时不同的区域进行交流,像人类一样通过对话和定位进行高效交流。

如上图所示,Shikra 不仅具备 LLM 所有的基本常识,还能够基于位置信息做出推理。

如上图所示,Shikra 可以对图片中正在发生的事情产生详细的描述,并为参考的物体生成准确的定位。

尽管 Shikra 没有在 OCR 数据集上专门训练,但也具有基本的 OCR 能力。
更多例子

 其他传统任务
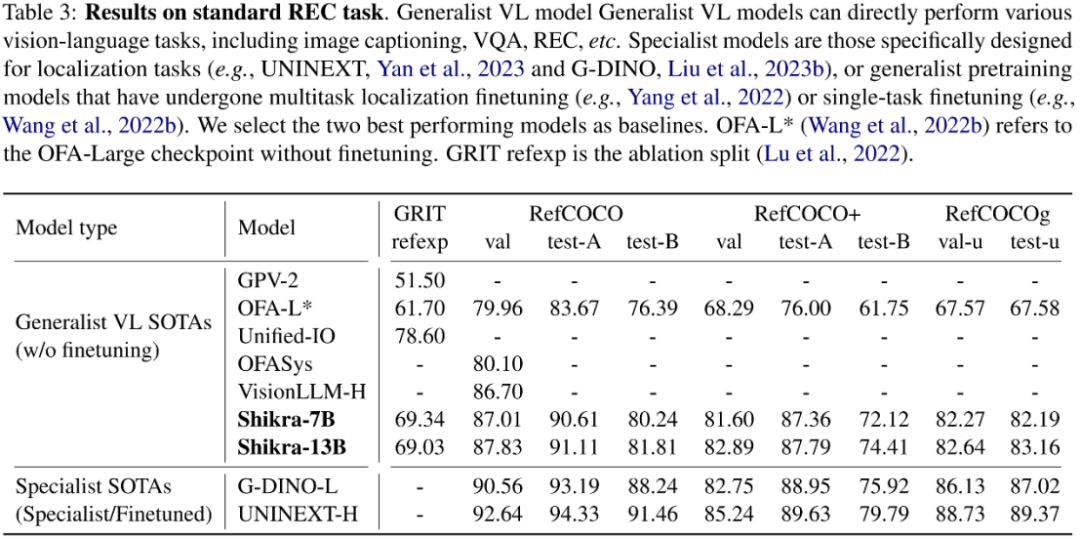
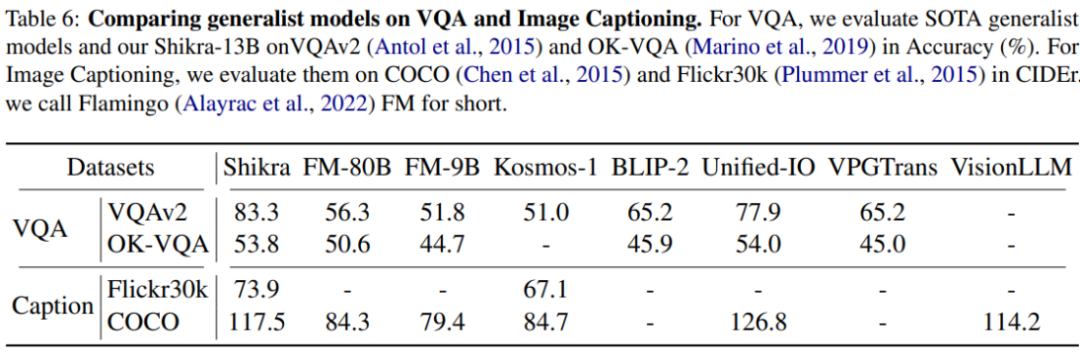
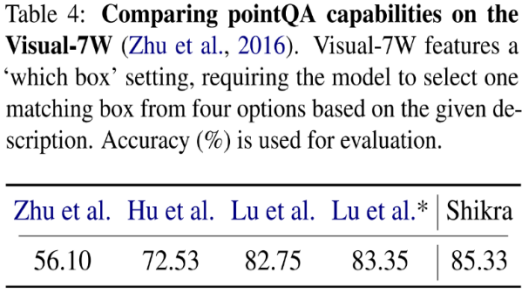
其他传统任务 模型架构采用 CLIP ViT-L/14 作为视觉主干,Vicuna-7/13B 作为基语言模型,使用一层线性映射连接 CLIP 和 Vicuna 的特征空间。Shikra 直接使用自然语言中的数字来表示物体位置,使用 [xmin, ymin, xmax, ymax] 表示边界框,使用 [xcenter, ycenter] 表示区域中心点,区域的 xy 坐标根据图像大小进行归一化。每个数字默认保留 3 位小数。这些坐标可以出现在模型的输入和输出序列中的任何位置。记录坐标的方括号也自然地出现在句子中。Shikra 在传统 REC、VQA、Caption 任务上都能取得优良表现。同时在 PointQA-Twice、Point-V7W 等需要理解位置输入的 VQA 任务上取得了 SOTA 结果。
模型架构采用 CLIP ViT-L/14 作为视觉主干,Vicuna-7/13B 作为基语言模型,使用一层线性映射连接 CLIP 和 Vicuna 的特征空间。Shikra 直接使用自然语言中的数字来表示物体位置,使用 [xmin, ymin, xmax, ymax] 表示边界框,使用 [xcenter, ycenter] 表示区域中心点,区域的 xy 坐标根据图像大小进行归一化。每个数字默认保留 3 位小数。这些坐标可以出现在模型的输入和输出序列中的任何位置。记录坐标的方括号也自然地出现在句子中。Shikra 在传统 REC、VQA、Caption 任务上都能取得优良表现。同时在 PointQA-Twice、Point-V7W 等需要理解位置输入的 VQA 任务上取得了 SOTA 结果。
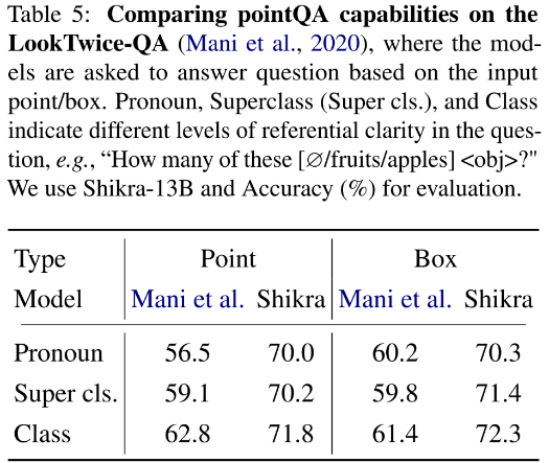
本文使用 POPE benchmark 评估了 Shikra 产生幻觉的程度。Shikra 得到了和 InstrcutBLIP 相当的结果,并远超近期其他 MLLM。
 思想链(CoT),旨在通过在最终答案前添加推理过程以帮助 LLM 回答复杂的 QA 问题。这一技术已被广泛应用到自然语言处理的各种任务中。然而如何在多模态场景下应用 CoT 则尚待研究。尤其因为目前的 MLLM 还存在严重的幻视问题,CoT 经常会产生幻觉,影响最终答案的正确性。通过在合成数据集 CLEVR 上的实验,研究发现,使用带有位置信息的 CoT 时,可以有效减少模型幻觉提高模型性能。
思想链(CoT),旨在通过在最终答案前添加推理过程以帮助 LLM 回答复杂的 QA 问题。这一技术已被广泛应用到自然语言处理的各种任务中。然而如何在多模态场景下应用 CoT 则尚待研究。尤其因为目前的 MLLM 还存在严重的幻视问题,CoT 经常会产生幻觉,影响最终答案的正确性。通过在合成数据集 CLEVR 上的实验,研究发现,使用带有位置信息的 CoT 时,可以有效减少模型幻觉提高模型性能。
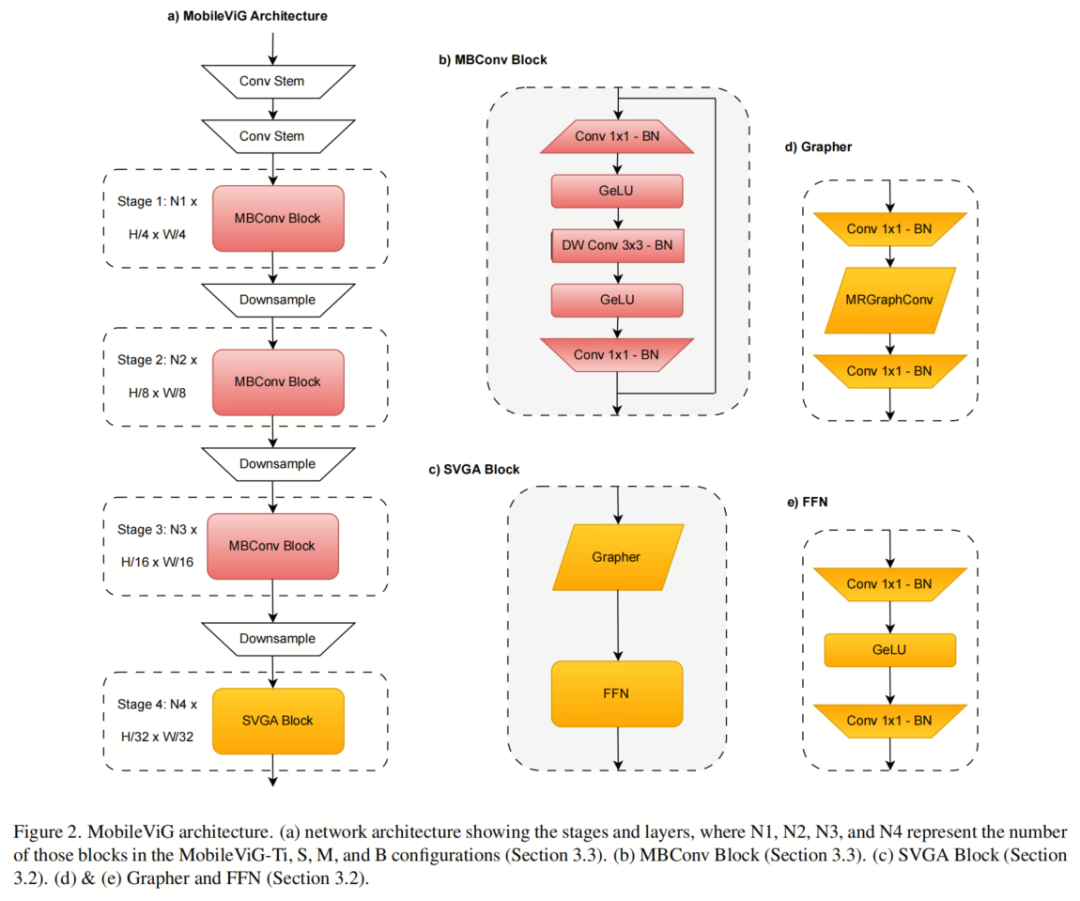
4. 图视觉模型崛起 | MobileViG同等精度比MobileNetv2快4倍,同等速度精度高4%!
原文:https://mp.weixin.qq.com/s/gstvrGg2wHnFyTRXd_cT_A

传统上,卷积神经网络(CNN)和Vision Transformer(ViT)主导了计算机视觉。然而,最近提出的Vision Graph神经网络(ViG)为探索提供了一条新的途径。不幸的是,对于移动端应用程序来说,由于将图像表示为图结构的开销,ViG在计算上是比较耗时的。 在这项工作中,作者提出了一种新的基于图的稀疏注意力机制,即稀疏Vision Graph注意力(SVGA),该机制是为在移动端设备上运行的ViG设计的。此外,作者提出了第一个用于移动端设备上视觉任务的混合CNN-GNN架构MobileViG,该架构使用SVGA。 大量实验表明,MobileViG在图像分类、目标检测和实例分割任务的准确性和/或速度方面优于现有的ViG模型以及现有的移动端CNN和ViT架构。作者最快的模型MobileViG-Ti在ImageNet-1K上实现了75.7%的Top-1准确率,在iPhone 13 Mini NPU(使用CoreML编译)上实现了0.78 ms 的推理延迟,这比MobileNetV2x1.4(1.02 ms ,74.7%Top-1)和MobileNetV2x1.0(0.81 ms ,71.8%Top-1。作者最大的模型MobileViG-B仅用2.30 ms 的延迟就获得了82.6%的Top-1准确率,这比类似规模的EfficientFormer-L3模型(2.77 ms ,82.4%)更快、更准确。 作者的工作证明,设计良好的混合CNN-GNN架构可以成为在移动端设备上设计快速准确模型的新探索途径。 代码:https://github.com/SLDGroup/MobileViG
1. 简介
人工智能(AI)和机器学习(ML)在过去十年中取得了爆炸式的增长。在计算机视觉中,这种增长背后的关键驱动力是神经网络的重新出现,尤其是卷积神经网络(CNNs)和最近的视觉Transformer。尽管通过反向传播训练的神经网络是在20世纪80年代发明的,但它们被用于更小规模的任务,如字符识别。直到AlexNet被引入ImageNet竞赛,神经网络reshape人工智能领域的潜力才得以充分实现。
CNN架构的进一步进步提高了其准确性、效率和速度。与CNN架构一样,多层感知器(MLP)架构和类MLP架构也有望成为通用视觉任务的Backbone。
尽管神经网络和MLP已在计算机视觉中得到广泛应用,但由于视觉和语言任务之间的差异,自然语言处理领域使用了递归神经网络(RNN),特别是长短期记忆(LSTM)网络。尽管LSTM仍在使用,但在NLP任务中,它们在很大程度上已被Transformer架构所取代。随着视觉Transformer(ViT)的引入,引入了一种适用于语言和视觉领域的网络架构。通过将图像分割成patch嵌入序列,可以将图像转换为Transformer模块可用的输入。与神经网络或MLP相比,Transformer架构的主要优势之一是其全局感受野,使其能够从图像中的远距离物体交互中学习。
图神经网络(GNN)已发展为在基于图的结构上运行,如生物网络、社交网络或引文网络。GNN甚至被提议用于节点分类、药物发现、欺诈检测等任务,以及最近提出的视觉GNN(ViG)的计算机视觉任务。简言之,ViG将图像划分为多个patch,然后通过K近邻(KNN)算法连接这些patch,从而提供了处理类似于ViT的全局目标交互的能力。
移动端应用的计算机视觉研究快速增长,导致了使用神经网络学习空间局部表示和使用Vision Transformer(ViT)学习全局表示的混合架构。当前的ViG模型不适合移动端任务,因为它们在移动端设备上运行时效率低且速度慢。可以探索从CNN和ViT模型的设计中学到的概念,以确定CNN-GNN混合模型是否能够提供基于CNN的模型的速度以及基于ViT的模型的准确性。
在这项工作中,作者研究了用于移动端设备上计算机视觉的混合CNN-GNN架构,并开发了一种可以与现有高效架构竞争的基于图形的注意力机制。作者的贡献总结如下:
-
作者提出了一种新的基于图的稀疏注意力方法,用于移动端视觉。作者称作者的注意力方法为稀疏Vision Graph注意力(SVGA)。作者的方法是轻量级的,因为与以前的方法相比,它不需要重新reshape,并且在图构建中几乎没有开销。
-
作者使用作者提出的SVGA、最大相对图卷积以及来自移动端CNN和移动端视觉Transformer架构的概念(作者称之为MobileViG),为视觉任务提出了一种新的移动端CNN-GNN架构。
-
作者提出的模型MobileViG在3个具有代表性的视觉任务(ImageNet图像分类、COCO目标检测和COCO实例分割)上的准确性和/或速度与现有的Vision Graph神经网络(ViG)、移动端卷积神经网络(CNN)和移动端Vision Transformer(ViT)架构类似或者更优的性能。
据作者所知,作者是第一个研究用于移动端视觉应用的混合CNN-GNN架构的算法。作者提出的SVGA注意力方法和MobileViG架构为最先进的移动端架构和ViG架构开辟了一条新的探索之路。
2. 相关工作
ViG被提议作为神经网络和ViT的替代方案,因为它能够以更灵活的格式表示图像数据。ViG通过使用KNN算法来表示图像,其中图像中的每个像素都关注相似的像素。ViG的性能与流行的ViT模型DeiT和SwinTransformer相当,这表明它值得进一步研究。
尽管基于ViT的模型在视觉任务中取得了成功,但与基于CNN的轻量级模型相比,它们仍然较慢,相比之下,基于CNN的模型缺乏基于ViT模型的全局感受域。因此,通过提供比基于ViT的模型更快的速度和比基于CNN的模型更高的精度,基于ViG的模型可能是一种可能的解决方案。据作者所知,目前还没有关于移动端ViG的作品;然而,在移动端CNN和混合模型领域,已有许多工作。作者将移动端架构设计分为两大类:卷积神经网络(CNN)模型和混合CNN-ViT模型,它们融合了CNNs和ViT的元素。
基于CNN架构的MobileNetv2和EfficientNet系列是首批在常见图像任务中取得成功的移动端模型。这些模型轻,推理速度快。然而,纯粹基于CNN的模型已经被混合模型竞争对手稳步取代。
有大量的混合移动端模型,包括MobileViTv2、EdgeViT、LeViT和EfficientFormerv2。这些混合模型在图像分类、目标检测和实例分割任务方面始终优于MobileNetv2,但其中一些模型在延迟方面并不总是表现良好。延迟差异可能与包含ViT块有关,ViT块在移动端硬件上的速度传统上较慢。
为了改善这种状况,作者提出了MobileViG,它提供了与MobileNetv2相当的速度和与EfficientFormer相当的精度。
3. 文本方法
在本节中,作者将描述SVGA算法,并提供有关MobileViG架构设计的详细信息。更确切地说,第3.1节描述了SVGA算法。第3.2节解释了作者如何调整ViG中的Graper模块来创建SVGA块。第3.3节描述了作者如何将SVGA块与反向残差块结合起来进行局部处理,以创建MobileViGTi、MobileViG-S、MobileVeg-M和MobileViG-B。
3.1. Sparse Vision Graph Attention
作者提出稀疏Vision Graph注意力(SVGA)作为Vision GNN中KNN图注意力的一种移动端友好的替代方案。基于KNN的图注意力引入了2个非移动端友好组件,KNN计算和输入reshape,作者用SVGA去除了这两个组件。
更详细地说,每个输入图像都需要KNN计算,因为不能提前知道每个像素的最近邻居。这产生了一个具有看似随机连接的图,如图1a所示。由于KNN的非结构化性质,KNN的作者将输入图像从4D张量reshape为3D张量,使他们能够正确对齐连接像素的特征,用于图卷积。在图形卷积之后,对于随后的卷积层,必须将输入从3D重新reshape为4D。因此,基于KNN的注意力需要KNN计算和2次reshape操作,这两种操作在移动端设备上都是比较耗时的。
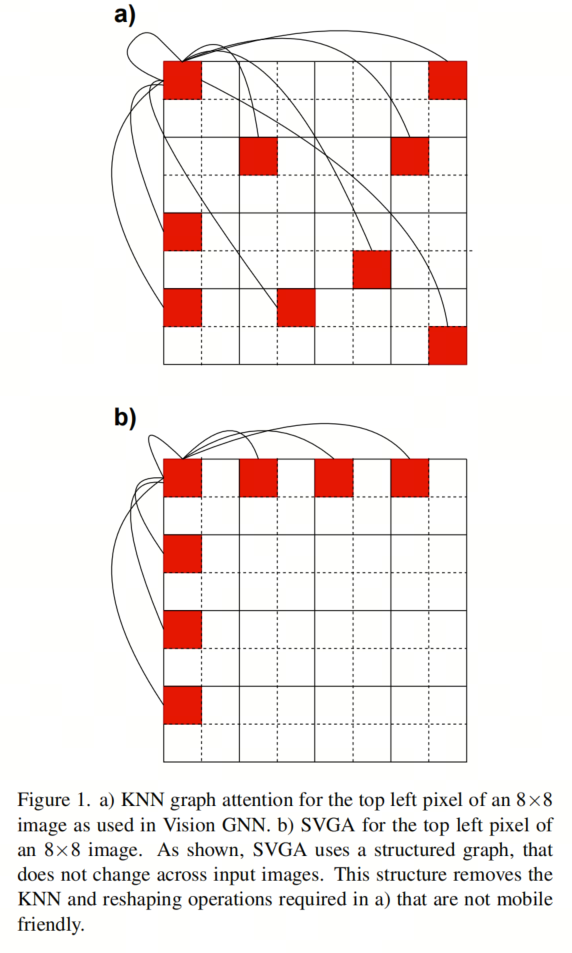
为了消除KNN计算和reshape操作的开销,SVGA假设一个固定图,其中每个像素都连接到其行和列中的第K个像素。例如,给定一个8×8的图像和K=2,左上角的像素将连接到其行上的每一个像素和列下的每一个像素,如图1b所示。对于输入图像中的每个像素重复这种相同的图案。由于图具有固定的结构(即,对于所有8×8个输入图像,每个像素都具有相同的连接),因此不必对输入图像进行reshape来执行图卷积。
相反,它可以使用跨越两个图像维度的滚动操作来实现,在算法1中表示为roll-right和roll-down。滚转操作的第一个参数是滚转的输入,第二个参数是向右或向下滚转的距离。使用图1b中K=2的示例,通过向右滚动图像两次、向右滚动四次和向右滚动六次,可以将左上角像素与其行中的第二个像素对齐。除了向下滚动之外,可以对其列中的每一个像素执行相同的操作。

请注意,由于每个像素都以相同的方式连接,因此用于将左上角像素与其连接对齐的滚动操作同时将图像中的其他每个像素与其连接对准。在MobileViG中,使用最大相对图卷积(MRConv)来执行图卷积。因此,在每次向右滚动和向下滚动操作之后,计算原始输入图像和滚动版本之间的差,在算法1中表示为Xr和Xc,并且按元素进行最大运算并存储在Xj中,也在算法1表示。在完成滚动和最大相对操作之后,执行最终的Conv2d。通过这种方法,SVGA将KNN计算换成了更便宜的滚动操作,因此不需要reshape来执行图卷积。
作者注意到,SVGA避开了KNN的表示灵活性,而倾向于移动端友好。
3.2. SVGA Block
作者将SVGA和更新后的MRConv层插入到Vision GNN中提出的捕获器块中。给定一个输入特征,更新后的图形处理器表示为
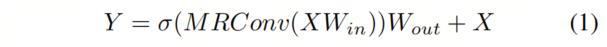
作者还在MRConv步骤中将滤波器组的数量从4(Vision GNN中使用的值)更改为1,以增加MRConv层的表达潜力,而不会显著增加延迟。更新后的Graper模块如图2d所示。
在更新的Graper之后,作者使用了Vision GNN中提出的前馈网络(FFN)模块,如图2e所示。FFN模块是一个两层MLP,表示为
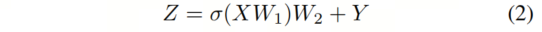
3.3. MobileViG Architecture
图2a中所示的MobileViG架构由卷积Backbone组成,然后是3级反向残差块(MBConv),其扩展比为4,用于MobileNetv2中提出的局部处理。在MBConv块中,作者将ReLU6替换为GeLU,因为它已被证明可以提高计算机视觉任务的性能。MBConv块由1×1卷积加批量归一化(BN)和GeLU、深度3×3卷积加BN和GeLU组成,最后是1×1卷积加BN和残差连接,如图2b所示。
在MBConv块之后,作者使用一个Stage的SVGA块来捕获全局信息,如图2a所示。作者在SVGA块之后还有一个卷积头用于分类。在每个MBConv阶段之后,下采样步骤将输入分辨率减半并扩展通道维度。每个阶段由多个MBConv或SVGA块组成,其中重复次数根据模型大小而变化。
MobileViG-Ti、MobileViG-S、MobileViG-M和MobileViG-B的通道尺寸和每个阶段重复的块的数量可以在表1中看到。
4. 实验
4.1. 图像分类
作者使用PyTorch 1.12和Timm库实现了该模型。作者使用8个NVIDIA A100 GPU来训练每个模型,有效批量大小为1024。这些模型是用AdamW优化器在ImageNet-1K上从头开始训练300个Epoch的。使用余弦退火策略将学习率设置为2e-3。作者使用标准图像分辨率224×224进行训练和测试。
与DeiT类似,作者使用RegNetY-16GF进行知识蒸馏,Top-1准确率为82.9%。对于数据扩充,作者使用RandAugment、Mixup、Cutmix、随机擦除和重复扩充。
作者使用iPhone 13 Mini(iOS 16)在NPU和GPU上测试延迟。这些模型是用CoreML编译的,延迟平均超过1000个预测。
如表2所示,对于类似数量的参数,MobileViG在准确性和GPU延迟方面都优于Pyramid ViG。例如,对于3.5 M以下的参数,MobileViG-S在Top-1的精度上与Pyramid-ViG-Ti匹配,同时速度快2.83倍。此外,在参数减少0.6 M的情况下,MobileViG-B在Top-1的准确率上击败Pyramid-ViG-S 0.5%,同时速度快2.08倍。
与表3中的移动端模型相比,MobileViG至少在NPU延迟、GPU延迟或准确性方面始终优于所有模型。MobileViG-Ti比MobileNetv2更快,Top-1的准确率高3.9%。它还与Top-1的EfficientFormerv2相匹配,同时在NPU和GPU延迟方面略有优势。
MobileViG-S在NPU延迟方面比EfficientNet-B0快近两倍,并比Top-1的准确率高0.5%。与MobileViTv2-1.5相比,MobileViG-M的NPU延迟快3倍以上,GPU延迟快2倍,Top-1精度高0.2%。此外,MobileViG-B比DeiT-S快6倍,能够在Top-1的精度上击败DeiT-S和Swin Tiny。
4.2. 目标检测和实例分割
作者在目标检测和实例分割任务上评估了MobileViG,以进一步证明SVGA的潜力。作者在Mask RCNN中集成了MobileViG作为Backbone,并使用MS COCO 2017数据集进行了实验。作者使用PyTorch 1.12和Timm库实现了Backbone,并使用4个NVIDIA RTX A6000 GPU来训练作者的模型。
作者使用来自300个训练Epoch的预训练ImageNet-1k权重初始化模型,使用初始学习率为2e-4的AdamW优化器,并按照NextViT、EfficientFormer和EfficientFormerV2的过程,以标准分辨率(1333 X 800)训练12个Epoch的模型。
如表4所示,在相似的模型大小下,MobileViG在目标检测和/或实例分割方面的参数或改进的平均精度(AP)方面优于ResNet、PoolFormer、EfficientFormer和PVT。中等规模的模型MobileViG-M模型在目标检测任务上获得41.3 APbox,当50IoU时获得62.8 APbox, 而当IOU75时获得45.1 APbox.
MobileViG的设计部分灵感来自Pyramid-ViG、EfficientFormer和MetaFormer的设计。在MobileViG中获得的结果表明,混合CNN-GNN架构是CNN、ViT和混合CNN-ViT设计的可行替代方案。混合CNN-GNN架构可以提供基于CNN的模型的速度以及ViT模型的准确性,使其成为高精度移动端架构设计的理想候选者。进一步探索用于移动端计算机视觉任务的混合CNN-GNN架构可以改进MobileViG概念,并引入新的最先进的架构。
5. 参考
[1].MobileViG: Graph-Based Sparse Attention for Mobile Vision Applications.
5. 重磅,GPT-4 API 全面开放使用!
原文:https://mp.weixin.qq.com/s/UrRtcvBIVzD_l-SXIjAxPQ
遥想今年 3 月刚推出 GPT-4 的 OpenAI 仅邀请了部分提交申请的开发者参与测试。眼瞅 OpenAI 联合创始人 Greg Brockman 在当时现场演示“史上最为强大”的 GPT-4 模型,轻松通过一张手绘草图生成一个网站、60 秒就能搞定一个小游戏开发等这些功能,一众开发者却不能使用。
而就在今天,GPT-4 的适用性进一步被拓展。OpenAI 正式发布 GPT-4 API,现对所有付费 API 的开发者全面开放!

1. OpenAI 路线图:本月底前向新开发者拓展推出 GPT-4
在上线的这四个月里,相信很多人通过技术解析论文(https://cdn.openai.com/papers/gpt-4.pdf),对于 GPT-4 也不太陌生。

据 OpenAI 透露,自今年 3 月份发布 GPT-4 以来,数以百万计的开发者要求访问 GPT-4 API,且利用 GPT-4 的创新产品的范围每天都在增长。
与其前身 GPT-3.5 相比,GPT-4 的不同之处在于它增强了生成文本(包括代码)的能力,同时还接受图像和文本输入。
该模型在各种专业和学术基准上表现出“人类水平”。此前,OpenAI 研究人员也做过测试,称,如果 GPT-4 是一个仅凭应试能力来判断的人,它可以进入法学院,而且很可能也能进入许多大学。
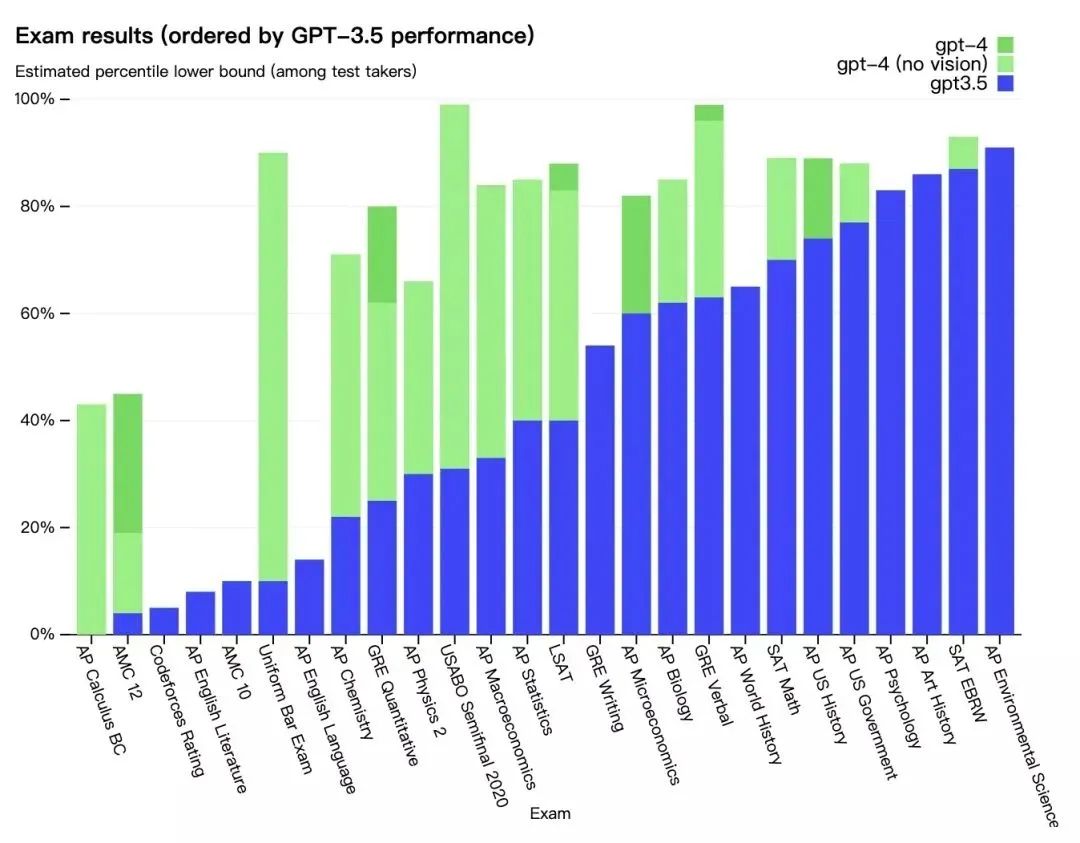
与 OpenAI 以前的 GPT 模型一样,GPT-4 是使用公开的数据进行训练的,包括来自公共网页的数据,以及 OpenAI 授权的数据。从技术维度上来看,GPT-4 是一个基于 Transformer 的模型,经过预训练,可以预测文档中的下一个 token。这个项目的一个核心部分是开发了基础设施和优化方法。这使 OpenAI 能够根据不超过 GPT-4 的 1/1000 的计算量训练的模型,准确地预测 GPT-4 的某些方面的性能。
不过,目前有些遗憾的是,图像理解能力还没有提供给所有 OpenAI 用户。还是像今年 3 月份 OpenAI 宣布的那样,它只是与其合作伙伴 Be My Eyes 进行测试。截至目前,OpenAI 还没有表明何时会向更广泛的用户群开放图像理解能力。
现如今,所有具有成功付费记录的 API 开发者都可以访问具有 8K 上下文的 GPT-4 API,当然,这一次还不能访问 32 K 上下文的。
同时,OpenAI 也有计划在本月底向新的开发者开放访问权限,然后根据计算的可用性,开始提高速率限制。
值得注意的是,虽然 GPT-4 代表了生成式 AI 模型发展的一个重要里程碑,但是这并不意味着它是 100% 完美的。就 GPT-4 而言,它还有可能产生“幻觉”,并理直气壮地犯一些推理性错误。
在未来,OpenAI 表示也正在努力为 GPT-4 和 GPT-3.5 Turbo 安全地启用微调功能,预计这一功能将在今年晚些时候推出。
2. Chat Completions API
在公告中,OpenAI 还宣布将普遍向开发者提供 GPT-3.5 Turbo、DALL-E 和 Whisper APIs。
同时也向开发者分享了目前广泛使用的 Chat Completions API 现状。OpenAI 表示,现在 Chat Completions API 占了其 API GPT 使用量的 97%。
OpenAI 指出,最初的 Completions API 是在 2020 年 6 月推出的,为语言模型进行互动提供了一个自由格式的文本提示。
Chat Completions API 的结构化界面(如系统消息、功能调用)和多轮对话能力能够使开发者能够建立对话体验和广泛的完成任务,同时降低提示注入攻击的风险,因为用户提供的内容可以从结构上与指令分开。

OpenAI 表示,当前也正在弥补 Chat Completions API 的几个不足之处,例如completion token 的日志概率和增加可引导性,以减少回应的 "聊天性"。
3. 旧模型的废弃
另外,OpenAI 也发布了旧模型的弃用计划。即从 2024 年 1 月 4 日开始,某些旧的 OpenAI 模型,特别是 GPT-3 及其衍生模型都将不再可用,并将被新的 "GPT-3 基础"模型所取代,新的模型计算效率会更高。
根据公告显示,具体淘汰的模型包含 Completions API 中的一些旧模型,包含我们熟悉的 davinci:
-
使用基于 GPT-3 模型(ada、babbage、curie、davinci)的稳定模型名称的应用程序将在 2024 年 1 月 4 日自动升级到上述的新模型。在未来几周内,通过在 API 调用中指定以下模型名称,也可以访问新模型进行早期测试:ada-002、babbage-002、curie-002、davinci-002。
-
使用其他旧的完成模型(如 text-davinci-003)的开发者将需要在 2024 年1月4日之前手动升级他们的集成,在他们的 API 请求的 "模型 "参数中指定 gpt-3.5-turbo-instruct。gpt-3.5-turbo-instruct 是一个 InstructGPT 风格的模型,训练方式与 text-davinci-003 类似。这个新的模型是 Completions API 中的一个替代品,并将在未来几周内提供给早期测试。

与此同时,OpenAI 表示,希望在 2024 年 1 月 4 日之后继续使用他们的微调模型的开发者,需要在新的基于 GPT-3 模型(ada-002、babbag-002、curie-002、davinci-002)或更新后的模型(gpt-3.5-turbo、gpt-4)之上进行微调替换。
随着 OpenAI 在今年晚些时候开启微调功能,他们将优先为以前微调过旧型号的用户提供 GPT-3.5 Turbo 和 GPT-4 微调服务。具体原因是,OpenAI 深谙从自己的数据上进行微调的模型上迁移是具有挑战性的,对此他们会为「以前微调过的模型的用户提供支持,使这种过渡尽可能顺利」。
除了淘汰一些 Completions API 旧模型之外,OpenAI 表示,旧的嵌入模型(如 text-search-davinci-doc-001)的用户也需要在 2024 年 1 月 4 日前迁移到 text-embedding-ada-002。

最后,使用 Edits API 及其相关模型(如t ext-davinci-edit-001 或 code-davinci-edit-001)的用户同样需要在 2024 年 1 月 4 日前迁移到 GPT-3.5 Turbo。Edits API 测试版是一个早期的探索性 API,旨在使开发人员能够根据指令返回编辑过的提示版本。

OpenAI 在公告中写道,“我们认识到这对使用这些旧型号的开发者来说是一个重大变化。终止这些模型不是我们轻易做出的决定。我们将承担用户用这些新模式重新嵌入内容的财务成本。”
OpenAI 表示将在未来几周,与受影响的用户联系,一旦新的模型准备好进行早期测试,他们也将提供更多信息。
4. 预告:下周,所有 ChatGPT Plus 用户可用上代码解释器
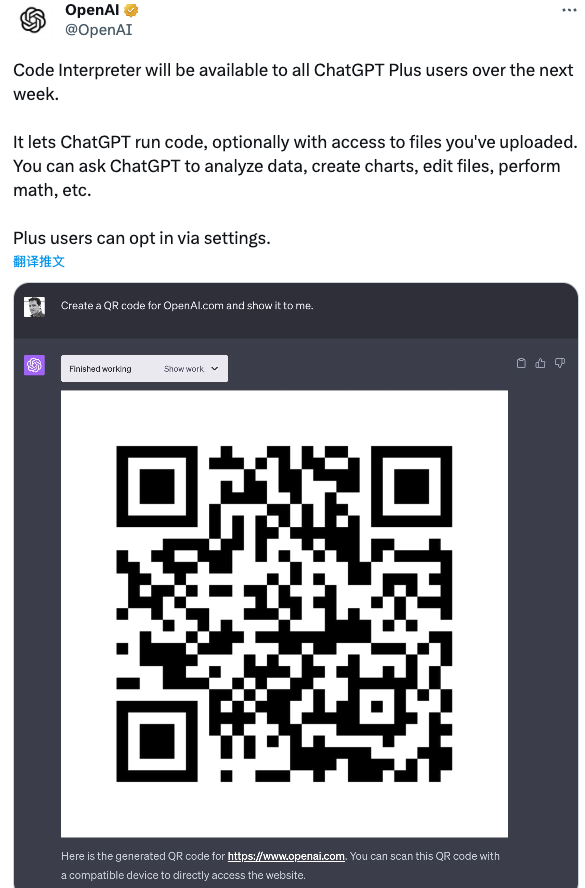
最为值得期待的是,OpenAI 官方还在 Twitter 上预告:代码解释器将在下周向所有 ChatGPT Plus 用户开放。
它允许 ChatGPT 运行代码,并且可以选择访问用户上传的文件。开发者可以直接要求 ChatGPT 分析数据、创建图表、编辑文件、执行数学运算等。
5. 调用 GPT-4 API 可以做的 10 件事
最后,随着此次 GPT-4 API 的放开,开发者再也不用费尽心思地购买 Plus 服务了,调用迄今业界最为强大的 GPT-4 API,无疑也让相关的应用更加智能。
那么,我们到底能用 GPT-4 API 来做什么,对此外媒总结了常见的 10 种用法:
-
基于 GPT-4 API 的叙事能力,可以快速生成复杂情节、人物发展等小说内容,彻底改变文学创作领域。
-
GPT-4 API 为模拟极其真实的对话铺平了道路,反映了人类交互的真实性和精确性。
-
GPT-4 API 展现了即时语言翻译的能力,有效地弥合了各种语言和文化之间的沟通差距。
-
GPT-4 API 在数据分析方面有很强的能力,可以为数据分析市场参与者提供了宝贵的洞察力。
-
GPT-4 API 能够打造与现实世界动态相呼应的高度逼真的虚拟环境,增强了游戏和虚拟现实等领域的沉浸感。
-
GPT-4 API 生成复杂计算机代码的能力,使其成为软件开发人员不可或缺的盟友。
-
GPT-4 API 可以解释和分析医疗数据,帮助准确诊断和预测各种健康状况。
-
利用其先进的语言生成能力,GPT-4 API 可确保快速、准确地生成法律文件。
-
GPT-4 API 展示了解释消费者数据和生成定制营销内容的能力,有效地与目标受众产生共鸣。
-
GPT-4 API 有可能通过分析大量的科学数据来推动科学创新,在化学、物理学和生物学等不同领域发现新的见解。
参考:
https://openai.com/blog/gpt-4-api-general-availability
https://dataconomy.com/2023/07/06/gpt-4-api-is-now-generally-available/
———————End———————
RT-Thread线下入门培训
7月 - 上海,南京
1.免费2.动手实验+理论3.主办方免费提供开发板4.自行携带电脑,及插线板用于笔记本电脑充电5.参与者需要有C语言、单片机(ARM Cortex-M核)基础,请提前安装好RT-Thread Studio 开发环境
报名通道

立即扫码报名
(报名成功即可参加)
点击阅读原文进入官网
原文标题:【AI简报20230707】中国团队推出「全球首颗」AI 全自动设计 CPU!重磅,GPT-4 API 全面开放使用!
-
RT-Thread
+关注
关注
31文章
1289浏览量
40128
原文标题:【AI简报20230707】中国团队推出「全球首颗」AI 全自动设计 CPU!重磅,GPT-4 API 全面开放使用!
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Llama 3 与 GPT-4 比较
科大讯飞发布讯飞星火4.0 Turbo:七大能力超GPT-4 Turbo
OpenAI推出新模型CriticGPT,用GPT-4自我纠错
OpenAI API Key获取:开发人员申请GPT-4 API Key教程
国内直联使用ChatGPT 4.0 API Key使用和多模态GPT4o API调用开发教程!

开发者如何调用OpenAI的GPT-4o API以及价格详情指南
阿里云发布通义千问2.5大模型,多项能力超越GPT-4
商汤科技发布5.0多模态大模型,综合能力全面对标GPT-4 Turbo
微软Copilot全面更新为OpenAI的GPT-4 Turbo模型
新火种AI|秒杀GPT-4,狙杀GPT-5,横空出世的Claude 3振奋人心!






 工商网监
工商网监
评论