 如何计算transformer模型的参数量
如何计算transformer模型的参数量
1. 前言
最近,OpenAI推出的ChatGPT展现出了卓越的性能,引发了大规模语言模型(Large Language Model,LLM)的研究热潮。大规模语言模型的“大”体现在两个方面:模型参数规模大,训练数据规模大。以GPT3为例,GPT3的参数量为1750亿,训练数据量达到了570GB。进而,训练大规模语言模型面临两个主要挑战:显存效率和计算效率。
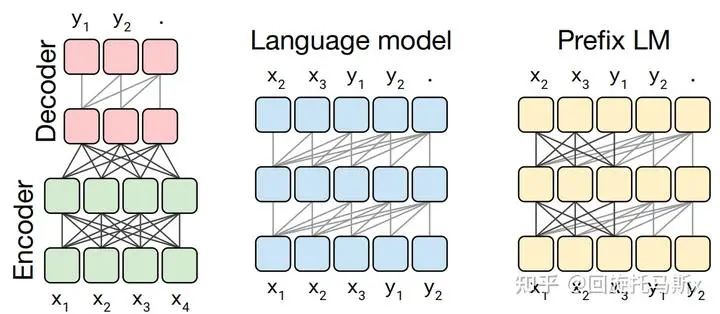
现在业界的大语言模型都是基于transformer模型的,模型结构主要有两大类:encoder-decoder(代表模型是T5)和decoder-only,具体的,decoder-only结构又可以分为Causal LM(代表模型是GPT系列)和PrefixLM(代表模型是GLM)。归因于GPT系列取得的巨大成功,大多数的主流大语言模型都采用Causal LM结构。因此,针对decoder-only框架,为了更好地理解训练训练大语言模型的显存效率和计算效率,本文分析采用decoder-only框架transformer模型的模型参数量、计算量、中间激活值、KV cache。
为了方便分析,先定义好一些数学符号。记transformer模型的层数为 ,隐藏层维度为
,隐藏层维度为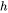 ,注意力头数为
,注意力头数为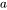 。词表大小为
。词表大小为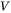 ,训练数据的批次大小为
,训练数据的批次大小为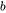 ,序列长度为
,序列长度为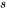 。
。
2. 模型参数量
transformer模型由个相同的层组成,每个层分为两部分:self-attention块和MLP块。
self-attention块的模型参数有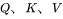 的权重矩阵
的权重矩阵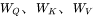 和偏置,输出权重矩阵
和偏置,输出权重矩阵 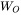 和偏置,4个权重矩阵的形状为
和偏置,4个权重矩阵的形状为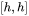 ,4个偏置的形状为
,4个偏置的形状为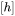 。self- attention块的参数量为
。self- attention块的参数量为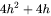 。
。
MLP块由2个线性层组成,一般地,第一个线性层是先将维度从 映射到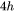 ,第二个线性层再将维度从映射到。第一个线性层的权重矩阵
,第二个线性层再将维度从映射到。第一个线性层的权重矩阵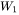 的形状为
的形状为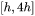 ,偏置的形状为
,偏置的形状为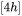 。第二个线性层权重矩阵
。第二个线性层权重矩阵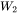 的形状为
的形状为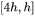 ,偏置形状为 。MLP块的参数量为
,偏置形状为 。MLP块的参数量为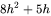 。
。
self-attention块和MLP块各有一个layer normalization,包含了2个可训练模型参数:缩放参数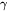 和平移参数
和平移参数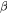 ,形状都是 。2个layernormalization的参数量为 。
,形状都是 。2个layernormalization的参数量为 。
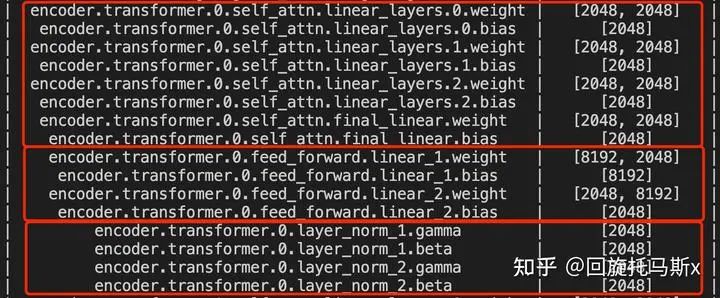
总的,每个transformer层的参数量为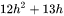 。
。
除此之外,词嵌入矩阵的参数量也较多,词向量维度通常等于隐藏层维度,词嵌入矩阵的参数量为 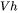 。最后的输出层的权重矩阵通常与词嵌入矩阵是参数共享的。
。最后的输出层的权重矩阵通常与词嵌入矩阵是参数共享的。
关于位置编码,如果采用可训练式的位置编码,会有一些可训练模型参数,数量比较少。如果采用相对位置编码,例如RoPE和ALiBi,则不包含可训练的模型参数。我们忽略这部分参数。
综上,层transformer模型的可训练模型参数量为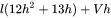 。当隐藏维度 较大时,可以忽略一次项, 模型参数量近似为
。当隐藏维度 较大时,可以忽略一次项, 模型参数量近似为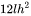 。
。
接下来,我们估计不同版本LLaMA模型的参数量。
| 实际参数量 | 隐藏维度h | 层数l | 12lh^2 |
|---|---|---|---|
| 6.7B | 4096 | 32 | 6,442,450,944 |
| 13.0B | 5120 | 40 | 12,582,912,000 |
| 32.5B | 6656 | 60 | 31,897,681,920 |
| 65.2B | 8192 | 80 | 64,424,509,440 |
2.1 训练过程中的显存占用分析
在训练神经网络的过程中,占用显存的大头主要分为四部分:模型参数、前向计算过程中产生的中间激活、后向传递计算得到的梯度、优化器状态。这里着重分析参数、梯度和优化器状态的显存占用,中间激活的显存占用后面会详细介绍。训练大模型时通常会采用AdamW优化器,并用混合精度训练来加速训练,基于这个前提分析显存占用。
在一次训练迭代中,每个可训练模型参数都会对应1个梯度,并对应2个优化器状态(Adam优化器梯度的一阶动量和二阶动量)。设模型参数量为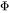 ,那么梯度的元素数量为 ,AdamW优化器的元素数量为
,那么梯度的元素数量为 ,AdamW优化器的元素数量为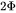 。float16数据类型的元素占2个bytes,float32数据类型的元素占4个bytes。在混合精度训练中,会使用float16的模型参数进行前向传递和后向传递,计算得到float16的梯度;在优化器更新模型参数时,会使用float32的优化器状态、float32的梯度、float32的模型参数来更新模型参数。因此,对于每个可训练模型参数,占用了
。float16数据类型的元素占2个bytes,float32数据类型的元素占4个bytes。在混合精度训练中,会使用float16的模型参数进行前向传递和后向传递,计算得到float16的梯度;在优化器更新模型参数时,会使用float32的优化器状态、float32的梯度、float32的模型参数来更新模型参数。因此,对于每个可训练模型参数,占用了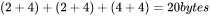 。使用AdamW优化器和混合精度训练来训练参数量为 的大模型, 模型参数、梯度和优化器状态占用的显存大小为
。使用AdamW优化器和混合精度训练来训练参数量为 的大模型, 模型参数、梯度和优化器状态占用的显存大小为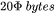 。
。
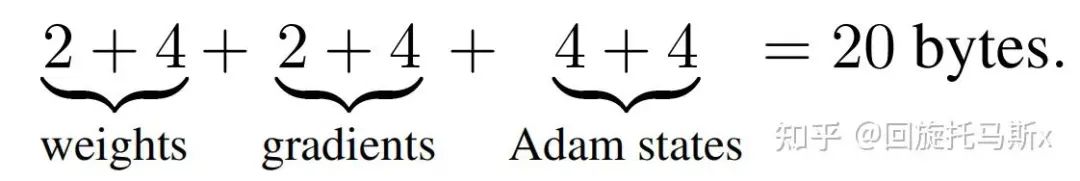
2.2 推理过程中的显存占用分析
在神经网络的推理阶段,没有优化器状态和梯度,也不需要保存中间激活。少了梯度、优化器状态、中间激活,模型推理阶段占用的显存要远小于训练阶段。模型推理阶段,占用显存的大头主要是模型参数,如果使用float16来进行推理,推理阶段模型参数占用的显存大概是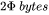 。如果使用KVcache来加速推理过程, KV cache也需要占用显存,KVcache占用的显存下文会详细介绍。此外,输入数据也需要放到GPU上,还有一些中间结果(推理过程中的中间结果用完会尽快释放掉),不过这部分占用的显存是很小的,可以忽略。
。如果使用KVcache来加速推理过程, KV cache也需要占用显存,KVcache占用的显存下文会详细介绍。此外,输入数据也需要放到GPU上,还有一些中间结果(推理过程中的中间结果用完会尽快释放掉),不过这部分占用的显存是很小的,可以忽略。
3. 计算量FLOPs估计
FLOPs,floating point operations,表示浮点数运算次数,衡量了计算量的大小。
如何计算矩阵乘法的FLOPs呢?
对于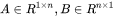 ,计算
,计算 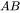 需要进行
需要进行 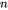 次乘法运算和 次加法运算,共计
次乘法运算和 次加法运算,共计 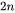 次浮点数运算,需要 的FLOPs。对于
次浮点数运算,需要 的FLOPs。对于 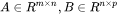 ,计算 需要的浮点数运算次数为
,计算 需要的浮点数运算次数为 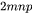 。
。
在一次训练迭代中,假设输入数据的形状为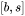 。我们 先分析self-attention块的计算,计算公式如下:
。我们 先分析self-attention块的计算,计算公式如下:
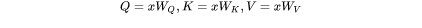
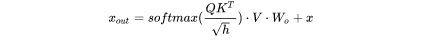
1. 计算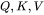 :矩阵乘法的输入和输出形状为
:矩阵乘法的输入和输出形状为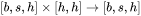 。计算量为
。计算量为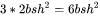 。
。
2.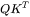 矩阵乘法的输入和输出形状为
矩阵乘法的输入和输出形状为
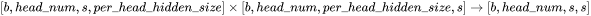 。计算量为
。计算量为 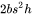 。
。
3. 计算在 上的加权 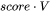 ,矩阵乘法的输入和输出形状为
,矩阵乘法的输入和输出形状为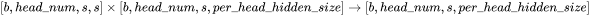 。计算量为 。
。计算量为 。
4. attention后的线性映射,矩阵乘法的输入和输出形状为。计算量为 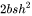 。
。
接下来分析MLP块的计算,计算公式如下:
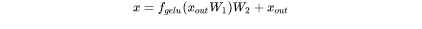
1. 第一个线性层,矩阵乘法的输入和输出形状为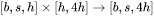 。计算量为
。计算量为 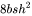 。
。
2. 第二个线性层,矩阵乘法的输入和输出形状为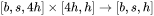 。计算量为 。
。计算量为 。
将上述计算量相加,得到每个transformer层的计算量大约为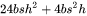 。
。
此外,另一个计算量的大头是logits的计算,将隐藏向量映射为词表大小。矩阵乘法的输入和输出形状为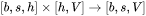 ,计算量为
,计算量为 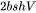 。
。
因此,对于一个 层的transformer模型,输入数据形状为 的情况下,一次训练迭代的计算量为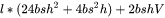 。
。
3.1 计算量与参数量的关联
当隐藏维度 比较大,且远大于序列长度 时,我们可以忽略一次项,计算量可以近似为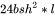 。前面提到当模型参数量为 ,输入的tokens数为
。前面提到当模型参数量为 ,输入的tokens数为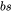 ,存在等式
,存在等式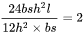 。我们可以近似认为: 在一次前向传递中,对于每个token,每个模型参数,需要进行2次浮点数运算,即一次乘法法运算和一次加法运算。
。我们可以近似认为: 在一次前向传递中,对于每个token,每个模型参数,需要进行2次浮点数运算,即一次乘法法运算和一次加法运算。
一次训练迭代包含了前向传递和后向传递,后向传递的计算量是前向传递的2倍。因此,前向传递 + 后向传递的系数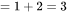 。一次训练迭代中,对于每个token,每个模型参数,需要进行
。一次训练迭代中,对于每个token,每个模型参数,需要进行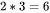 次浮点数运算。
次浮点数运算。
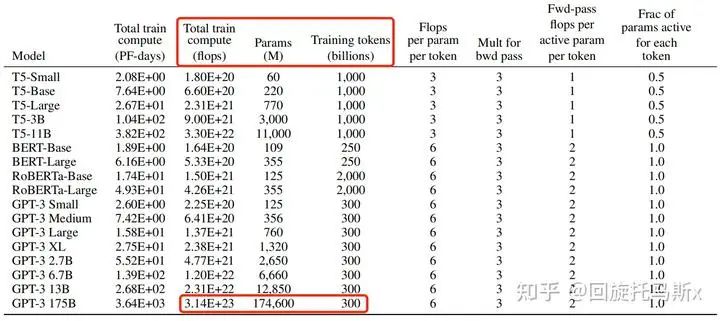
接下来,我们可以估计训练GPT3-175B所需要的计算量。对于GPT3,每个token,每个参数进行了6次浮点数运算,再乘以参数量和总tokens数就得到了总的计算量。GPT3的模型参数量为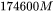 ,训练数据量为
,训练数据量为 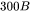 tokens。
tokens。
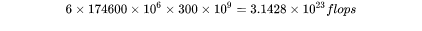
3.2 训练时间估计
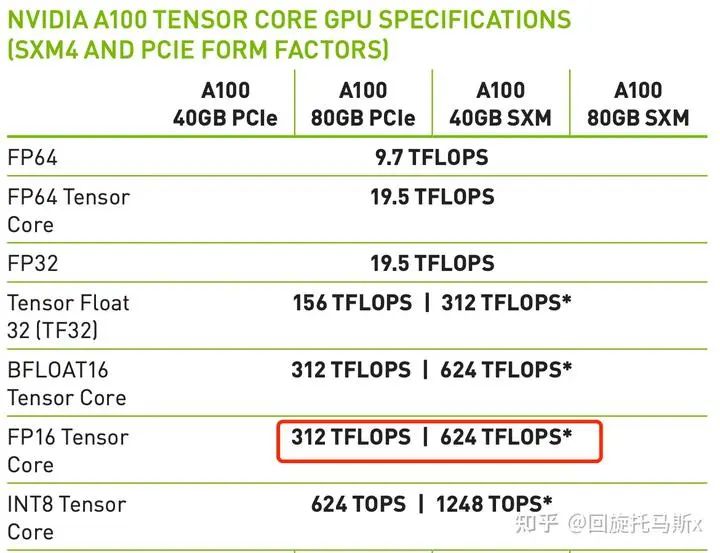
模型参数量和训练总tokens数决定了训练transformer模型需要的计算量。给定硬件GPU类型的情况下,可以估计所需要的训练时间。给定计算量,训练时间(也就是GPU算完这么多flops的计算时间)不仅跟GPU类型有关,还与GPU利用率有关。计算端到端训练的GPU利用率时,不仅要考虑前向传递和后向传递的计算时间,还要**考虑CPU加载数据、优化器更新、多卡通信和记录日志的时间。一般来讲,GPU利用率一般在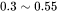 之间。
之间。
上文讲到一次前向传递中,对于每个token,每个模型参数,进行2次浮点数计算。使用激活重计算技术来减少中间激活显存(下文会详细介绍)需要进行一次额外的前向传递,因此前向传递+ 后向传递 + 激活重计算的系数=1+2+1=4。使用激活重计算的一次训练迭代中,对于每个token,每个模型参数,需要进行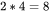 次浮点数运算。在给定训练tokens数、硬件环境配置的情况下,训练transformer模型的计算时间为:
次浮点数运算。在给定训练tokens数、硬件环境配置的情况下,训练transformer模型的计算时间为:

以GPT3-175B为例,在1024张40GB显存的A100上,在300Btokens的数据上训练175B参数量的GPT3。40GB显存A100的峰值性能为312TFLOPS,设GPU利用率为0.45,则所需要的训练时间为34天,这与[7]中的训练时间是对得上的。
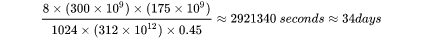
以LLaMA-65B为例,在2048张80GB显存的A100上,在1.4TBtokens的数据上训练了65B参数量的模型。80GB显存A100的峰值性能为624TFLOPS,设GPU利用率为0.3,则所需要的训练时间为21天,这与[4]中的实际训练时间是对得上的。
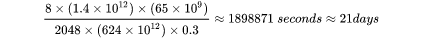
4. 中间激活值分析
除了模型参数、梯度、优化器状态外,占用显存的大头就是前向传递过程中计算得到的中间激活值了,需要保存中间激活以便在后向传递计算梯度时使用。这里的激活(activations)指的是:前向传递过程中计算得到的,并在后向传递过程中需要用到的所有张量。这里的激活不包含模型参数和优化器状态,但包含了dropout操作需要用到的mask矩阵。
在分析中间激活的显存占用时,只考虑激活占用显存的大头,忽略掉一些小的buffers。比如,对于layernormalization,计算梯度时需要用到层的输入、输入的均值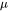 和方差
和方差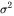 。输入包含了
。输入包含了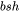 个元素,而输入的均值和方差分别包含了 个元素。由于 通常是比较大的(千数量级),有
个元素,而输入的均值和方差分别包含了 个元素。由于 通常是比较大的(千数量级),有 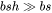 。因此,对于layernormalization,中间激活近似估计为 ,而不是
。因此,对于layernormalization,中间激活近似估计为 ,而不是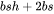 。
。
大模型在训练过程中通常采用混合精度训练,中间激活值一般是float16或者bfloat16数据类型的。在分析中间激活的显存占用时,假设中间激活值是以float16或bfloat16数据格式来保存的,每个元素占了2个bytes。唯一例外的是,dropout操作的mask矩阵,每个元素只占1个bytes。在下面的分析中,单位是bytes,而不是元素个数。
每个transformer层包含了一个self-attention块和MLP块,并分别对应了一个layer normalization连接。
先分析self-attention块的中间激活。self-attention块的计算公式如下:
1. 对于 ,需要保存它们共同的输入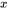 ,这就是中间激活。输入 的形状为
,这就是中间激活。输入 的形状为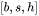 ,元素个数为 ,占用显存大小为
,元素个数为 ,占用显存大小为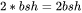 。
。
2. 对于 矩阵乘法,需要保存中间激活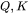 ,两个张量的形状都是 ,占用显存大小合计为
,两个张量的形状都是 ,占用显存大小合计为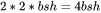 。
。
3. 对于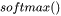 函数,需要保存函数的输入 ,占用显存大小为
函数,需要保存函数的输入 ,占用显存大小为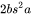 ,这里的 表示注意力头数。
,这里的 表示注意力头数。
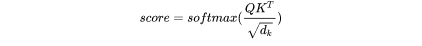
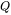 的形状为:
的形状为: 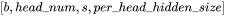
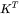 的形状为:
的形状为: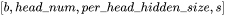
的形状为: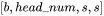 ,元素个数为
,元素个数为 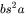 ,占用显存大小为 。
,占用显存大小为 。
4. 计算完函数后,会进行dropout操作。需要保存一个mask矩阵,mask矩阵的形状与 相同,占用显存大小为 。
5. 计算在 上的attention,即 ,需要保存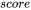 ,大小为 ;以及 ,大小为
,大小为 ;以及 ,大小为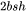 。二者占用显存大小合计为
。二者占用显存大小合计为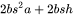 。
。
6. 计算输出映射以及一个dropout操作。输入映射需要保存其输入,大小为 ;dropout需要保存mask矩阵,大小为 。二者占用显存大小合计为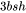 。
。
因此,将上述中间激活相加得到,self-attention块的中间激活占用显存大小为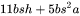 。
。
接下来看MLP块的中间激活。MLP块的计算公式如下:
1. 第一个线性层需要保存其输入,占用显存大小为 。
2. 激活函数需要保存其输入,占用显存大小为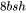 。
。
3. 第二个线性层需要保存其输入,占用显存大小为 。
4. 最后有一个dropout操作,需要保存mask矩阵,占用显存大小为 。
对于MLP块,需要保存的中间激活值为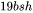 。
。
另外,self-attention块和MLP块分别对应了一个layer normalization。每个layer norm需要保存其输入,大小为 。2个layer norm需要保存的中间激活为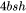 。
。
综上,每个transformer层需要保存的中间激活占用显存大小为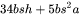 。对于层transformer模型,还有embedding层、最后的输出层。embedding层不需要中间激活。总的而言,当隐藏维度 比较大,层数 较深时,这部分的中间激活是很少的,可以忽略。因此,对于 层transformer模型,中间激活占用的显存大小可以近似为
。对于层transformer模型,还有embedding层、最后的输出层。embedding层不需要中间激活。总的而言,当隐藏维度 比较大,层数 较深时,这部分的中间激活是很少的,可以忽略。因此,对于 层transformer模型,中间激活占用的显存大小可以近似为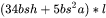 。
。
4.1 对比中间激活与模型参数的显存大小
在一次训练迭代中,模型参数(或梯度)占用的显存大小只与模型参数量和参数数据类型有关,与输入数据的大小是没有关系的。优化器状态占用的显存大小也是一样,与优化器类型有关,与模型参数量有关,但与输入数据的大小无关。而中间激活值与输入数据的大小(批次大小 和序列长度 )是成正相关的,随着批次大小 和序列长度的增大,中间激活占用的显存会同步增大。当我们训练神经网络遇到显存不足OOM(Out OfMemory)问题时,通常会尝试减小批次大小来避免显存不足的问题,这种方式减少的其实是中间激活占用的显存,而不是模型参数、梯度和优化器的显存。
以GPT3-175B为例,我们来直观地对比下模型参数与中间激活的显存大小。GPT3的模型配置如下。我们假设采用混合精度训练,模型参数和中间激活都采用float16数据类型,每个元素占2个bytes。
| 模型名 | 参数量 | 层数 | 隐藏维度 | 注意力头数 |
|---|---|---|---|---|
| GPT3 | 175B | 96 | 12288 | 96 |
GPT3的模型参数量为175B,占用的显存大小为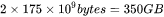 。GPT3模型需要占用350GB的显存。
。GPT3模型需要占用350GB的显存。
GPT3的序列长度 为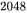 。对比不同的批次大小 占用的中间激活:
。对比不同的批次大小 占用的中间激活:
当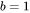 时,中间激活占用显存为
时,中间激活占用显存为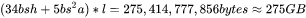 ,大约是模型参数显存的0.79倍。
,大约是模型参数显存的0.79倍。
当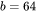 时,中间激活占用显存为
时,中间激活占用显存为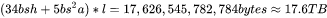 ,大约是模型参数显存的50倍。
,大约是模型参数显存的50倍。
当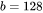 时,中间激活占用显存为
时,中间激活占用显存为
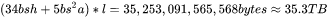 ,大约是模型参数显存的101倍。
,大约是模型参数显存的101倍。
可以看到随着批次大小的增大,中间激活占用的显存远远超过了模型参数显存。通常会采用 激活重计算技术来减少中间激活,理论上可以将中间激活显存从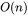 减少到
减少到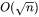 ,代价是增加了一次额外前向计算的时间,本质上是“时间换空间”。
,代价是增加了一次额外前向计算的时间,本质上是“时间换空间”。
5. KV cache
在推断阶段,transformer模型加速推断的一个常用策略就是使用 KV cache。一个典型的大模型生成式推断包含了两个阶段:
1.预填充阶段:输入一个prompt序列,为每个transformer层生成 key cache和value cache(KV cache)。
2.解码阶段:使用并更新KV cache,一个接一个地生成词,当前生成的词依赖于之前已经生成的词。
第 个transformer层的权重矩阵为
个transformer层的权重矩阵为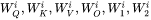 。其中,self-attention块的4个权重矩阵
。其中,self-attention块的4个权重矩阵 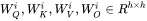 ,并且MLP块的2个权重矩阵
,并且MLP块的2个权重矩阵 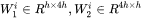 。
。
预填充阶段
假设第 个transformer层的输入为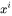 ,self-attention块的key、value、query和output表示为
,self-attention块的key、value、query和output表示为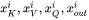 ,其中,
,其中, 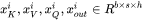 。
。
key cache和value cache的计算过程为:
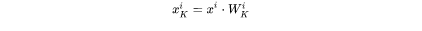
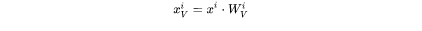
第 个transformer层剩余的计算过程为:
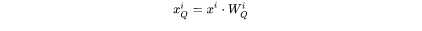
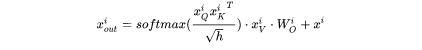
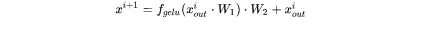
解码阶段
给定当前生成词在第 个transformer层的向量表示为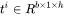 。推断计算分两部分:更新KV cache和计算第 个transformer层的输出。
。推断计算分两部分:更新KV cache和计算第 个transformer层的输出。
更新key cache和value cache的计算过程如下:
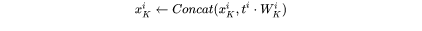
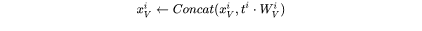
第 个transformer层剩余的计算过程为:
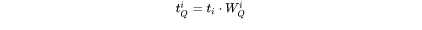
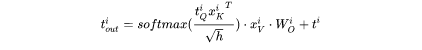
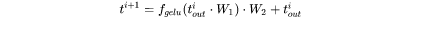
5.1 KV cache的显存占用分析
假设输入序列的长度为 ,输出序列的长度为 ,以float16来保存KV cache,那么 KVcache的峰值显存占用大小为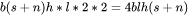 。这里第一个2表示K/V cache,第二个2表示float16占2个bytes。
。这里第一个2表示K/V cache,第二个2表示float16占2个bytes。
以GPT3为例,对比KV cache与模型参数占用显存的大小。GPT3模型占用显存大小为350GB。假设批次大小 ,输入序列长度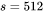 ,输出序列长度
,输出序列长度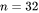 ,则KV cache占用显存为
,则KV cache占用显存为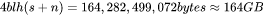 ,大约是模型参数显存的0.5倍。
,大约是模型参数显存的0.5倍。
6. 总结
本文首先介绍了如何计算transformer模型的参数量,基于参数量可以进一步估计模型参数、梯度和优化器状态占用的显存大小。接着,本文估计了训练迭代中,在给定训练tokens数的情况下transformer模型的计算量,给予计算量和显卡性能可以进一步估计训练迭代的计算耗时。然后,本文分析了transformer模型前向计算过程中产生的中间激活值的显存大小,中间激活的显存大小与输入数据大小正相关,甚至会远超过模型参数占用的显存。最后,本文介绍了transformer模型推理过程常用的加速策略:使用KVcache。总的来说,分析transformer模型的参数量、计算量、中间激活和KV cache,有助于理解大模型训练和推断过程中的显存效率和计算效率。
-
模型
+关注
关注
1文章
3415浏览量
49475 -
Transformer
+关注
关注
0文章
147浏览量
6155 -
ChatGPT
+关注
关注
29文章
1578浏览量
8285
原文标题:分析transformer模型的参数量、计算量、中间激活、KV cache
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于卷积的基础模型InternImage网络技术分析
基于Transformer做大模型预训练基本的并行范式
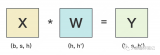
如何使用MATLAB构建Transformer模型

你了解在单GPU上就可以运行的Transformer模型吗
Google科学家设计简化稀疏架构Switch Transformer,语言模型的参数量可扩展至 1.6 万亿
一个GPU训练一个130亿参数的模型
超大Transformer语言模型的分布式训练框架

Microsoft使用NVIDIA Triton加速AI Transformer模型应用
在X3派上玩转一亿参数量超大Transformer,DIY专属你的离线语音识别

基于Transformer的大型语言模型(LLM)的内部机制

transformer模型详解:Transformer 模型的压缩方法
基于Transformer模型的压缩方法






 工商网监
工商网监
评论