 基于Transformer的相机-毫米波雷达融合3D目标检测方法
基于Transformer的相机-毫米波雷达融合3D目标检测方法
编者按
为了发展低成本全场景自动驾驶环境感知技术,针对毫米波雷达与视觉的融合感知技术的研究成为当前热点,然而毫米波雷达和视觉两种模态各有优缺点,如何充分利用两种模态的信息提高3D目标检测的性能,成为业界的一个重要关注点。本文提出了一种利用Transformer实现相机-毫米波雷达融合3D目标检测,并在nuScenes 3D检测基准上实现了最先进的性能,从而启发我们研究基于Transformer的传感器融合感知技术。
摘要
尽管雷达在汽车行业很受欢迎,但对于基于融合的3D目标检测,现有的工作大多集中在激光雷达和相机融合上。在本文中,我们提出了TransCAR,一种基于Tansformer的相机和雷达融合解决方案,用于3D目标检测。我们的TransCAR由两个模块组成。第一个模块从环绕视图相机图像中学习2D特征,然后使用一组稀疏的3D对象查询来索引到这些2D特征。然后,视觉更新的查询通过transformer自我注意层相互交互。第二个模块从多次雷达扫描中学习雷达特征,然后应用transformer解码器学习雷达特征与视觉更新查询之间的交互;transformer解码器内部的交叉注意层可以自适应学习雷达特征与视觉更新查询之间的软关联,而不是只基于传感器标定的硬关联。最后,我们的模型使用集对集的匈牙利损失估计每个查询的边界框,使该方法能够避免非最大抑制。TransCAR利用无时间信息的雷达扫描提高了速度估计。我们的TransCAR再具有挑战性的nuScenes数据集上的卓越实验结果表明,我们的TransCAR由于最先进的基于相机-雷达融合的3D目标检测方法。
1 简介
雷达以用于高级驾驶辅助系统(ADAS)多年。然而,尽管雷达在汽车行业中很流行,考虑到3D目标检测时,大多数工作集中在激光雷达[14,23,25,26,40 - 42,45]、相机[2,7,24,35],和激光雷达-相机融合[6,11,12,15,16,21 - 23,37,38,43]。其中一个原因是,没有那么多带有3D边界框注释的开放数据集,其中包括雷达数据[3,5,9,29]。另一个原因是,与激光雷达点云相比,汽车雷达信号更加稀疏并缺乏高度信息。这些属性使得区分感兴趣的对象和背景的回波变得很困难。然而,雷达与激光雷达相比有其优势:(1)雷达在恶劣天气和光照条件下具有鲁棒性;(2)雷达可以通过多普勒效应精确测量目标的径向速度,而不需要多帧时间信息;(3)雷达的成本比激光雷达低得多。因此,我们认为,通过雷达相机融合研究,有很大的潜力提高表现。 3D目标检测是自动驾驶和ADAS系统的关键。3D物体检测的目标是预测一组感兴趣物体的3D边界框和类别标签。由于汽车雷达数据的稀疏性和高度信息的缺乏,仅从汽车雷达数据中直接估计和分类3D边界框具有一定的挑战性。基于单目相机的3D探测器[2,7,19,24,35]可以对目标进行分类,准确预测目标的航向角和方位角。然而,深度估计中的误差是显著的,因为从单个图像回归深度本质上是一个不适定的逆问题。雷达可以提供精确的深度测量,而基于单目相机的解决方案不能。相机可以产生基于雷达的解决方案不能产生的分类和3D边界框估计。因此,将雷达和相机相融合,以获得更好的3D目标检测表现是一个自然的想法。
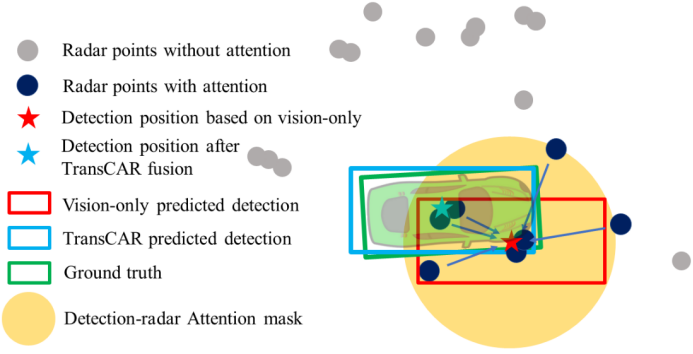
图1:一个来自nuScenes[3]的例子,展示了TransCAR融合的工作原理。仅视觉检测有显著的距离误差。我们的TransCAR融合可以学习基于视觉的查询与相关雷达信号之间的交互,并预测改进的检测。通过查询雷达注意屏蔽,不相关的雷达点不会被注意。 不同传感器模态之间的数据关联是传感器融合技术面临的主要挑战。现有的工作主要依靠多传感器标定来做像素级[31]、特征级[6,12,15,16,39]或检测级[21,22]关联。然而,这对雷达和相机关联来说是一个挑战。首先,雷达缺乏高度测量,使得雷达-相机投影在高度方向上包含了很大的不确定性。其次,雷达波束比典型的图像像素宽得多,并且可以四处反射。这可能导致雷达可以看到一些命中,但摄像头无法感知。第三,雷达测量数据稀疏且分辨率低。许多相机可见的物体并没有被雷达击中。由于这些原因,基于传感器标定的硬编码数据关联算法在雷达和相机融合中的表现较差。 具有深远影响的Transformer框架最初是作为自然语言处理(NLP)的革命性技术提出的[30],随后在计算机视觉应用中显示了其通用性,包括对象分类[8]和检测[4,47]。Transformer内部的自注意和交叉注意机制可以学习多个信息集之间的交互[1,4,30]。我们相信,这使得Transformer框架是一个可行的适合解决相机-雷达融合中的数据关联。在本文中,我们提出了一种新的基于Transformer的雷达和相机融合网络,称为TransCAR,以解决上述问题。 我们的TransCAR首先使用DETR3D[35]生成基于图像的对象查询。然后,TransCAR从多次累积的雷达扫描中学习雷达特征,并应用transformer解码器学习雷达特征与视觉更新查询之间的交互。Transformer解码器内部的交叉注意可以自适应地学习雷达特征与视觉更新查询之间的软关联,而不是只基于传感器标定的硬关联。最后,我们的模型使用集对集匈牙利损失来预测每个查询的边界框。图1说明了TransCAR的主要想法。我们还加入速度差异作为匈牙利二部匹配的指标,因为雷达可以提供精确的径向速度测量。虽然我们的重点是融合多台单目相机和雷达,但提出的TransCAR框架也适用于立体相机系统。我们使用具有挑战性的nuScenes数据集[3]来演示我们的TransCAR。TransCAR的表现大大超过了所有其他先进的(SOTA)基于相机雷达融合的方法。拟议的体系结构提供了以下贡献: •我们研究了雷达数据的特点,提出了一种新型的相机-雷达融合网络,该网络能够自适应地学习软关联,并在基于雷达-相机标定的基础上显示出比硬关联更好的3D检测表现。 •提出了查询-雷达注意屏蔽,以协助交叉注意层,避免远处视觉查询与雷达特征之间的不必要交互,并更好地学习关联。 •在不需要时间信息的情况下,TransCAR改进了雷达的速度估计。 •提交时,在nuScenes 3D检测基准上,TransCAR在已发表的基于相机-雷达融合的方法中排名第一。
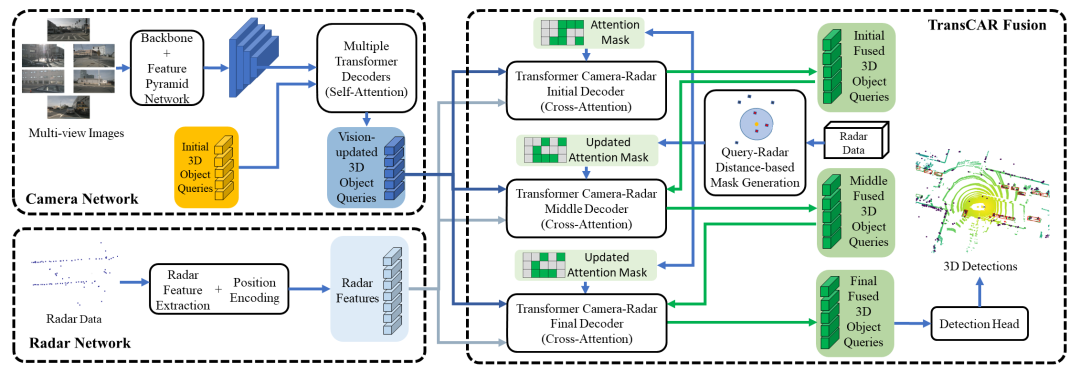
图2:TransCAR系统架构。该系统主要由三个部分组成:(1)基于transformer解码器的相机网络(DETR3D[35])生成基于图像的3D对象查询。初始对象查询是随机生成的;(2)对雷达点位进行编码,提取雷达特征的雷达网络;(3)基于三个transformer交叉注意解码器的TransCAR融合模块。我们提出使用transformer来学习雷达特征与视觉更新对象查询之间的交互,以实现自适应相机-雷达关联。
2TransCAR
所提的TransCAR体系架构图如图2所示。相机网络首先利用环绕视图图像来生成视觉更新的对象查询。雷达网络对雷达点位进行编码并提取雷达特征。然后,TransCAR融合模块将视觉更新的目标查询与有用的雷达特征融合。下面,我们将详细介绍TransCAR中的各个模块。
2.1
相机网络
我们的摄像头网络将6个摄像头采集的环绕主车360度的全景图像和初始3D对象查询作为输入,并输出一组在3D空间的视觉更新的3D对象查询。我们将DETR3D[35]应用于相机网络,并遵循自上而下的迭代设计。它利用初始的3D查询为2D特征建立索引,以细化3D查询。输出的3D视觉更新查询是TransCAR融合模块的输入。2.1.1为什么从相机开始我们使用环绕视图图像生成用于融合的3D物体查询。雷达不适合这项任务,因为许多感兴趣的物体没有雷达回波。这背后有两个主要原因。首先,与相机和激光雷达相比,典型的汽车雷达的垂直视场非常有限,而且它通常安装在较低的位置。因此,任何位于雷达小垂直视场之外的物体都将被忽略。其次,与激光雷达不同,雷达波束更宽,方位角分辨率有限,因此很难探测到小型物体。根据我们在补充资料中的统计,在nuScenes训练集中,雷达有很高的漏检率,特别是对于小目标。对于道路上最常见的两个类别——汽车和行人,雷达漏掉了36.05%的汽车和78.16%的行人。相机有更好的物体可视性。因此,我们首先利用图像预测用于融合的3D物体的查询。2.1.2 研究方法相机网络使用ResNet-101[10]和特征金字塔网络(FPN)[17]学习多尺度特征金字塔。这些多尺度特征图为探测不同大小的目标提供了丰富的信息。效仿[36,47],我们的相机网络(DETR3D[35])是迭代的。它有6个Transformer解码器层来产生视觉更新的3D对象查询;每一层都将前一层的输出查询作为输入。下面解释了每个层中的步骤。 对于第一解码器层,一组N (对于nuScenes N = 900)个可学习3D对象查询Q0= {Q01,Q02,…,q0N}∈RC在3D监视区域内随机初始化。上标0表示到第一层的输入查询,下标是查询的索引。网络从训练数据中学习这些3D查询位置的分布。网络从训练数据中学习这些3D查询位置的分布。对于下面的层,输入查询是来自上一层的输出查询。每个3D对象查询编码一个潜在对象的3D中心位置pi∈R3。通过双线性插值,将这些3D中心点投影到基于相机内外参数的图像特征金字塔中以提取图像特征。假设图像特征金字塔中有k层,对于一个3D点pi,采样后的图像特征fi∈RC是所有k层采样特征的总和,C为特征通道数。一个给定的3D中心点pi可能在任何相机图像中都不可见。我们用零填充这些视点对应的采样图像特征。 Transformer自注意层用于学习N个3D对象查询之间的交互,并生成注意分数。然后将对象查询与通过注意力分数加权的采样的图像特征相结合,形成更新后的对象查询Ql= {ql1,ql2,…,qlN}∈RC,其中l为当前层。Ql是第(l + 1)层查询的输入集。 对于每个更新的对象查询qli,使用两个神经网络预测一个3D边界框和一个类标签。边界框编码和丢失函数的细节在2.4节中描述。训练过程中,每一层后计算一次损失。在推理模式中,仅使用来自最后一层的视觉更新查询输出进行融合。
2.2
雷达网络
该雷达网络的设计目的是学习有用的雷达特征,并对其3D位置进行编码以进行融合。我们首先根据x和y距离对雷达点进行过滤,因为只有在BEV中+/−50米范围内的物体才会在nuScenes[3]中进行评估。由于雷达是稀疏的,我们将前5帧的雷达积累起来,并将其转换为当前帧。nuScenes数据集为每个雷达点提供了18个通道,包括主车帧中的3D位置x, y, z,径向速度vx和vy,主车运动补偿速度vxc和vyc,虚警概率pdh0,动态属性通道dynProp指示群集是移动还是静止,和其他状态通道1。为了使状态通道对网络具有学习的可行性,我们将状态通道转化为独热向量。由于我们使用了5个累积的帧,每个帧相对于当前时间戳的时间偏移对于指示位置偏移是有用的,所以我们还为每个点添加了一个时间偏移通道。通过这些预处理操作,每个输入雷达点有36个通道。 使用多层感知器(MLP)网络学习雷达特征Fr∈RM×C和雷达点位置编码Pr∈RM×C,其中M和C分别为雷达点数和特征通道数。在本文中,我们对nuScenes数据集设置M = 1500, C = 256。注意,即使在nuScenes数据集中累积,每个时间步长的雷达点也少于1500个。因此,为了尺寸兼容性,我们用超出范围的位置和零特征填充空点。图3显示了雷达网络的详细信息。我们将学习到的特征和位置编码结合起来,作为最终的雷达特征Fradar= (Fr+ Pr)∈RM×C。这些最终的雷达特征和相机网络的视觉更新查询将用于下一步的TransCAR融合。
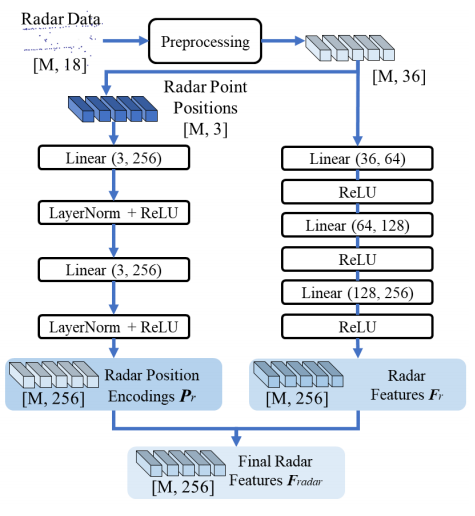
图3:雷达网络细节。位置编码网络(左)以雷达点位置(xyz)作为输入。预处理后的雷达数据(章节2.2)发送到雷达特征提取网络(右侧),学习有用的雷达特征。由于雷达信号非常稀疏,所以每个雷达点都是独立处理的。方括号内的数字表示数据的形状。
2.3
TransCAR融合
TransCAR融合模块将前一步的视觉更新查询和雷达特征作为输入,输出融合查询进行3D边界框预测。在TransCAR融合模块中,三个Transformer解码器以迭代方式工作。提出了查询-雷达注意屏蔽,以帮助交叉注意层更好地学习视觉更新查询与雷达特征之间的交互和关联。2.3.1查询-雷达注意屏蔽如果输入查询、键和值的数量都很大,那么训练一个transformer是很有挑战性和耗时的[4,8]。对于我们的transformer解码器,有N个3D对象查询Q∈RN×C和M个雷达特性Frad∈RM×C作为键和值,其中对于nuScenes N = 900和M = 1500。不需要学习它们之间的每一个成对的交互(900 × 1500)。对于查询qi∈Q,只有附近的雷达特征是有用的。没有必要将qi与其他雷达特征进行交互。因此,我们定义一个二进制N×M 查询-雷达注意屏蔽M∈{0,1}N×M,以防止对某些位置的注意,其中0表示不注意,1表示允许注意。只有当第i个查询qi与第j个雷达特征fj之间的xy欧氏距离小于阈值时,才允许注意M中的位置(i,j)。在TransCAR融合中,三个transformer解码器对应3个查询-雷达注意屏蔽。这三种屏蔽的半径分别为2m、2m和1m。2.3.2 transformer相机与雷达交叉注意在我们的TransCAR融合中,通过级联3个transformer交叉注意解码器来学习视觉更新查询和雷达特征之间的关联。图4显示了一个transformer交叉注意解码器的详细信息。对于初始解码器,相机网络输出的视觉更新查询Qimg∈RN×C为输入查询。Frad∈RM×C的雷达特性是输入键和值。查询-雷达注意屏蔽M1用于防止注意某些不必要的配对。解码器内的交叉注意层将输出注意分数矩阵A1∈[0,1]N×M。对于A1第i行中的M个元素,表示第i个视觉更新查询与所有M个雷达特征之间的注意力得分,总和为1。注意,对于每个查询,只允许注意与之接近的雷达特性,因此对于A1中的每一行,它们中的大多数都是0。这些注意力分数是视觉更新查询和雷达特性之间的关联指示器。然后,用于视觉更新查询的注意力加权雷达特征计算为F∗rad1= (A1·Frad)∈RN×C。这些加权雷达特征与原始的视觉更新查询相结合,然后通过前馈网络(FFN) ΦFFN1进行增强。这形成了初始阶段的融合查询:Qf1= ΦFFN1(Qimg+F∗rad1)∈RN×C。
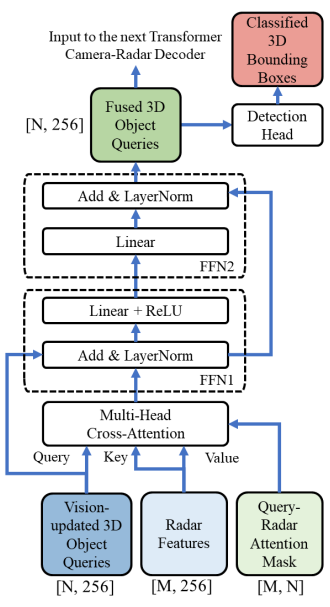
图4:transformer相机-雷达解码器层的细节。视觉更新的3D目标Q是对多头交叉注意模块的Q。雷达的特性是K和V。详见第2.3.2节。括号内的数字表示数据的形状。 中间和最后的transformer解码器的工作原理与最初的解码器相似。但是它们使用之前的融合查询Qf1而不是视觉更新查询作为输入。以中间查询为例,新的查询-雷达注意屏蔽M2是根据Qf1和雷达点位置之间的距离计算的。当查询位置在初始解码器中更新时,我们还使用Qf1中的编码过的查询位置重新采样图像特征ff2。与初始解码器类似,Qf1的注意力加权雷达特征被定义为F∗rad2= (A2·Frad)∈RN×C,其中A2包括初始阶段融合查询Qf1和雷达特征Frad的注意力分数。输出融合查询是通过Qf2= ΦFFN2(Qf1+ F∗rad2+ ff2)∈RN×C学习的。在两个解码器之后,我们使用两组FFN进行边界框预测。我们在训练过程中计算两个解码器的损耗,在推理过程中只使用最后一个解码器的边界框输出。由于能见度的限制,一些查询可能没有附近的雷达信号。我们在训练过程中计算两个解码器的损耗,在推理过程中只使用最后一个解码器的边界框输出。 由于能见度的限制,一些查询可能没有附近的雷达信号。这些查询不会与任何雷达信号交互,它们的注意力分数都是0。来自这些查询的检测将只基于视觉。
2.4
框编码和损失函数
框编码:我们将一个3D边界框b3D编码为一个11位向量:
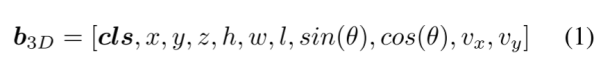
其中cls = {c1,…,cn}为类标号,x、y、z为3D中心位置,h、w、l为3D维度,θ为航向角,vx、vy为沿x、y轴的速度。对于每个输出对象查询q,网络预测它的类分数c∈[0,1]n(n为类数,对于nuScenes n = 10)和3D边界框参数b∈R10:
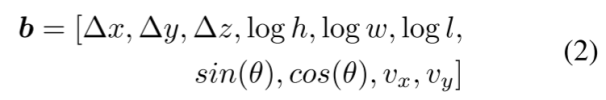
其中∆x,∆y和∆z是预测和上一层查询位置之间的偏移量。与DETR3D估算Sigmoid空间[35]中的位置偏移不同,我们直接回归3D笛卡尔坐标中的位置偏移。DETR3D使用Sigmoid空间,因为他们希望将位置输出保持在[0,1]之间,所以所有的查询位置都在距离边界内。而对于TransCAR,我们从优化的视觉更新查询开始,其位置相对更准确。因此,我们可以避免可能会影响学习的冗余的非线性激活。损失:我们使用集对集匈牙利损失来指导训练,并测量网络预测与以下事实之间的差异[4,28,35]。损失函数中有两个部分,一个用于分类,另一个用于边界框回归。我们将焦点损失[18]用于分类以解决类的不平衡,并将L1损失用于边界框回归。假设N和K表示同一帧中预测和基本事实的个数,由于N明显大于K,我们将φ(无对象)填充基本事实集合。效仿[4,28,35],我们使用匈牙利算法[13]来解决预测和基本事实之间的二部匹配问题:
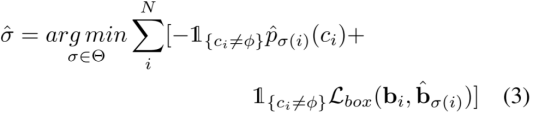
式中,Θ为排列集合,pˆσ(i)(ci)为排列指数为σ(i)的ci类概率,Lbox为边界框的L1差值,bi和bˆσ(i)分别为基本事实框和预测框。这里,请注意,我们还将速度估计vx和vy合并到Lbox中,以便更好地匹配和估计速度。采用最优排列σˆ,最终匈牙利损失可表示为:
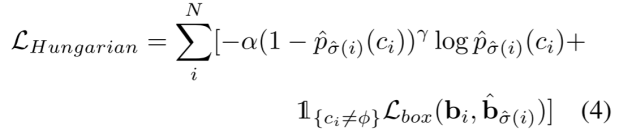
其中α和γ是焦点损失的参数。
3 实验结果
我们在具有挑战性的nuScenes 3D检测基准[3]上评估了我们的TransCAR,因为它是唯一包含雷达的开放大规模标注数据集。
3.1
数据集
在nuScenes数据收集车辆上安装有6台相机、5台雷达和1台激光雷达。nuScenes 3D检测数据集包含1000个20秒的驾驶片段(场景),其中训练片段700个,验证片段150个,测试片段150个。标注率为2Hz,因此分别有28k、6k和6k标注帧用于训练、验证和测试。有10类对象。真阳指标是基于BEV中心距离的。
3.2
评价结果
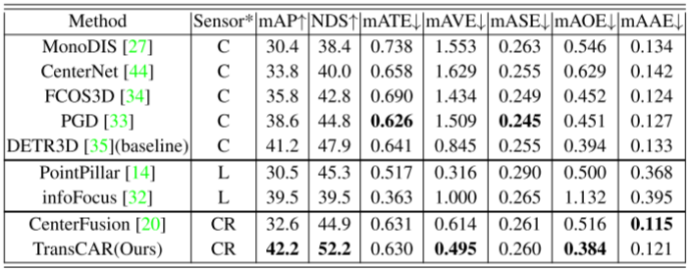
我们在表1中展示了nuScenes测试集的3D检测结果。我们的TransCAR在提交时优于所有其他的相机雷达融合方法。与基线仅相机方法相比,DETR3D[35]、TransCAR具有更高的mAP和NDS (nuScenes Detection Score[3])。注意,DETR3D是用CBGS[46]训练的,而TransCAR不是。从表1中可以看出,在10个等级中,汽车等级提升幅度最大(+2.4%)。汽车和行人是驾驶场景的主要兴趣对象。在nuScenes数据集中,轿车类在训练集中所占比例最高,占总实例的43.74%,其中63.95%的汽车实例被雷达命中。因此,这些汽车实例为我们的TransCAR学习融合提供了足够的训练实例。行人类在训练集中所占比例第二高,占总实例数的19.67%,但雷达返回仅占21.84%。TransCAR仍可将行人mAP提高1.2%。这说明,对于有雷达命中的目标,TransCAR可以利用雷达命中来提高检测表现,对于无雷达命中的目标,TransCAR可以保持基线表现。 表1:nuScenes测试集与SOTA方法的定量比较。在‘Sensor’栏中,‘C’、‘L’和‘CR’分别代表相机、激光雷达和相机-雷达融合。‘C.V.’, ‘Ped’, ‘Motor’和‘T.C’分别是工程车辆、行人、摩托车和交通锥的缩写。TransCAR是目前最好的基于相机雷达融合的方法,拥有最高的NDS和mAP,甚至优于早期发布的基于激光雷达的方法。表现最好的用粗体突出显示,排除了仅使用激光雷达的解决方案。
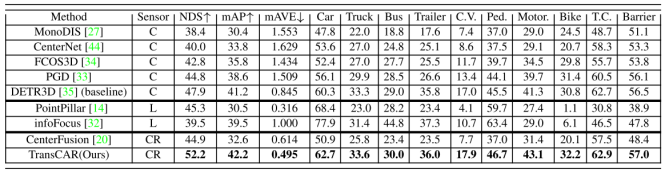
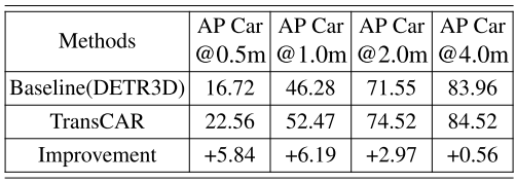
表2为轿车类的基线DETR3D[35] 与不同中心距离评价指标的定量比较。在nuScenes数据集中,真阳指标基于中心距离,即真阳指标与基本真实值之间的中心距离应小于阈值。nuScenes定义了从0.5米到4.0米的四个距离阈值。如表2所示,TransCAR针对所有4个指标改进了AP。特别是对于更加严格和重要的指标0.5和1.0米阈值,改进分别为5.84%和6.19%。 表2:在nuScenes验证集上,不同中心距离评价指标的轿车类与基线DETR3D的平均精度(AP)比较。我们的TransCAR在所有评估指标上都大大提高了AP。
3.3
定性结果
图5显示了在nuScenes数据集[3]上,TransCAR与基线DETR3D[35]之间的定性比较。蓝色和红色的框分别是来自TransCAR和DETR3D的预测,绿色填充的矩形是基本事实。较大的暗点为雷达点,较小的色点为激光雷达参考点(黄色至绿色表示距离的增加)。左列的椭圆区域突出了TransCAR所做的改进,图像上的橙色框突出了自上向下视图中相应的椭圆区域。TransCAR融合了基线DETR3D的检测结果,显著改善了3D边界框估计。
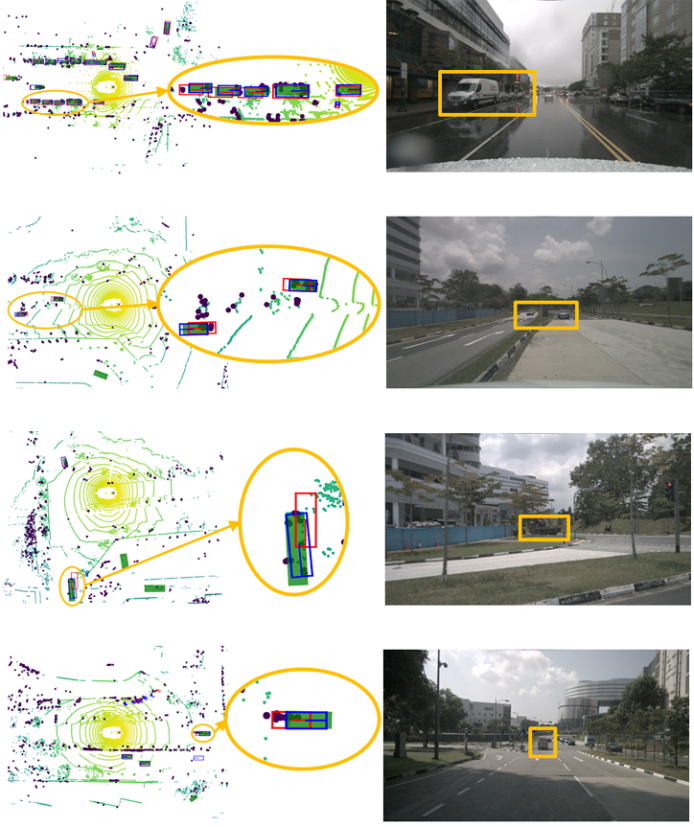
图5:在nuScenes数据集[3]上,TransCAR与基线DETR3D的定性比较。蓝色和红色的框分别是来自TransCAR和DETR3D的预测,绿色填充的矩形是基本事实。较大的暗点为雷达点,较小的色点为激光雷达参考点(黄色至绿色表示距离的增加)。左列的椭圆区域突出了TransCAR所做的改进,图像上的橙色框突出了自上向下视图中相应的椭圆区域。包含放大和彩色的最佳视角。
3.4
消融与分析
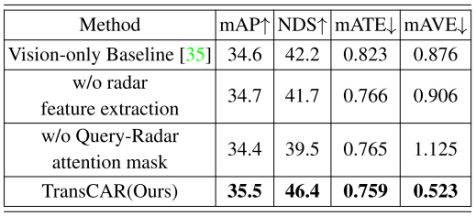
由于篇幅限制,我们在本节展示了部分消融研究,更多的消融研究在补充材料中显示。各组件的贡献:我们评估每个组件在我们的TransCAR网络中的贡献。nuScenes验证集的消融研究结果如表3所示。仅限视觉的基线是DETR3D[35]。径向速度是雷达可以提供的唯一测量结果之一;虽然它不是真实的速度,但它仍然可以引导网络在没有时间信息的情况下预测物体的速度。如表3第二行所示,在没有雷达径向速度时,网络只能利用雷达点的位置进行融合,且mAVE (m/s)显著较高(0.906 vs. 0.523)。查询雷达注意屏蔽可以根据查询和雷达特征之间的距离来防止对它们的注意。如果没有它,每个查询都必须与场景中的所有雷达特征(在我们的工作中是1500)交互。 表3:TransCAR组件在nuScenes 验证集上的消融。
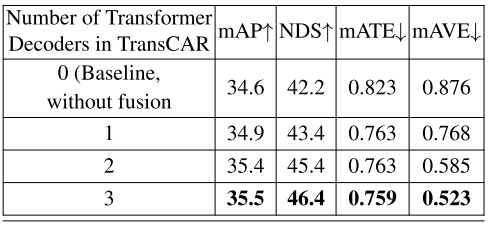
迭代改进:在TransCAR中有三个迭代工作的transformer交叉注意解码器。我们研究了迭代设计在TransCAR融合中的有效性,结果如表4所示。从表4的定量结果可以看出,TransCAR融合中的迭代细化可以提高检测表现,有利于充分利用我们提出的融合架构。 表4:对不同数量transformer解码器在TransCAR中检测结果的评价。
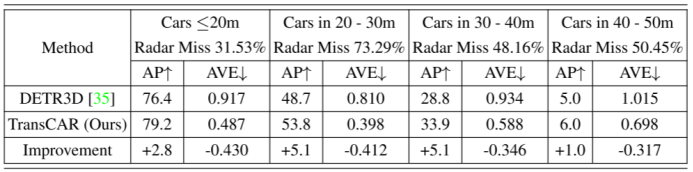
不同距离范围的表现:表5和表6显示了不同距离范围下nuScenes数据集的检测表现,表5显示了10个类的平均结果,表6仅为轿车类。这两个表的结果表明,仅视觉基线法(DETR3D)和我们的TransCAR在较短的距离中表现更好。在20~40米范围内,TransCAR的改进更为显著。这主要是因为对于20米以内的目标,位置误差较小,利用雷达进行改进的空间有限。对于超过40米的物体,该基线的表现很差,因此TransCAR只能提供有限的改进。请注意,表5中所有10个类的平均精度(mAP)和相应的改进比表6中轿车类的要小。这主要有两个原因。首先,mAP是所有类ap的均值,在nuScenes数据集中,雷达传感器对于小型目标类(行人、自行车、交通锥等)有较高的失误率。例如,78.16%的行人和63.74%的骑自行车的人没有雷达信号。因此,与大型对象(汽车、公共汽车等)相比,这些类的表现更差。因此,对于这类目标,TransCAR所带来的改进是有限的,对于有雷达回波的目标类,TransCAR可以利用雷达信号来提高检测表现,对于无雷达回波的目标类,TransCAR只能保持基线表现。其次,nuScenes数据集存在明显的类失衡现象,轿车类占训练实例的43.74%,而其他类如自行车和摩托车仅占1.00%和1.07%。这些稀少的类的训练例子是不够的。对于主要的轿车类,也是驾驶场景中最常见的对象,TransCAR可以大幅度提高检测表现和速度估计(表6)。 表5:nuScenes验证集上所有不同距离范围的平均精度(mAP, %)、nuScenes检测分数(NDS)和平均速度误差(AVE, m/s)。我们的TransCAR在所有距离范围内都优于基线(DETR3D)。

表6:nuScenes验证集上不同距离范围的轿车类的平均精度(AP, %)和平均速度误差(AVE, m/s)。给出了雷达传感器在不同距离下的漏检率。被雷达错过的轿车被定义为没有雷达回波的轿车。我们的TransCAR改进了AP,并在所有距离范围内大大降低了速度估计误差。
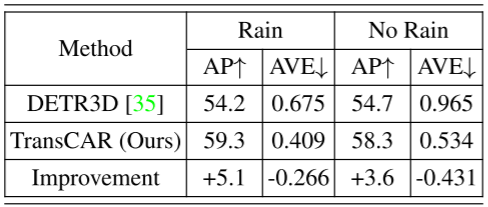
不同的天气和光照条件:与相机相比,雷达在不同的天气和光照条件下鲁棒性更强。我们对雨天和夜间的检测表现进行了评估,结果如表7和表8所示。注意nuScenes不为每个带注释的帧提供天气标签,天气信息在场景描述部分提供(场景是一个20秒的数据段[3])。在人工检查了一些带注解的帧后,我们发现“雨”下的帧并不是在下雨的时候捕获的,有些是在下雨之前或之后采集的。然而,与在晴天采集的图像相比,这些图像的质量较低。因此,它们适合于我们的评价实验。 表7显示了轿车类在下雨和无雨场景下的AP和AVE。与无雨场景相比,在下雨场景中,TransCAR有更高的AP改善(+5.1% vs. +3.6%)。下雨场景的AVE小于无雨场景;这是因为雨帧存在偏差,这些雨场景中的车辆更接近主车,更容易被检测到。 表8为夜间和白天场景的检测表现比较。夜间光照条件差,基线法的表现不如白天(AP为52.2% vs.54.8%,AVE为1.691m/s vs.0.866m/s), TransCAR可以利用雷达数据提高AP 6.9%, 降低AVE 1.012m/s。虽然夜间场景有限(15个场景,602帧),但该结果仍然可以证明TransCAR在夜间场景中的有效性。 表7:在nuScenes验证集上,轿车类在下雨和无雨场景下的平均精度(AP)和平均速度误差(AVE, m/s)的比较。nuScenes验证集中6019帧(150个场景)中有1088帧(27个场景)被标注为下雨。在下雨条件下,TransCAR能够显著提高探测表现,降低速度估计误差。
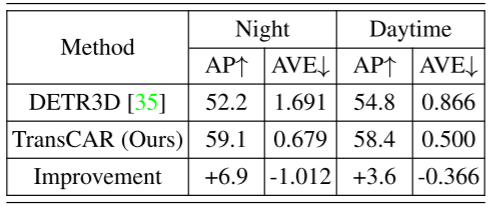
表8:轿车类在nuScenes验证集的夜间和白天场景的平均精度(AP)和平均速度误差(AVE, m/s)的比较。夜间采集nuScenes验证集6019帧中的602帧。TransCAR可以利用雷达数据显著提高表现,降低夜间相机受到影响时的速度估计误差。
4补充材料
4.1
雷达和激光雷达漏检率的比较
与激光雷达相比,雷达具有更高的漏检率。主要有两个原因:第一,与激光雷达相比,汽车雷达的视野非常有限。并且雷达通常安装在较低的位置。因此,任何位于雷达小垂直视场之外的物体都将被忽略。其次,雷达波束较宽,方位角分辨率有限,难以探测到小型目标。nuScenes训练集的LiDAR和radar失误率统计如表9所示。我们计算了不同类别的物体数量,雷达或激光雷达漏检的物体数量以及相应的漏检率。雷达有很高的漏检率,特别是对小目标。对于道路上最常见的两个类别——汽车和行人,雷达漏掉了36.05%的汽车和78.16%的行人。 请注意,我们不是在批评雷达。表9显示了在目标探测任务中使用雷达所面临的挑战。了解雷达测量的性质有助于我们设计合理的融合系统。正如在主论文中讨论的,基于这些统计数据,我们得出结论,雷达,配置在nuScenes车辆上,不适合用于生成3D查询。 表9:nuScenes训练集中,主车50米范围内不同类别对象的统计。* ‘C.V.’, ‘Ped’,‘Motor’ 和‘T.C’分别代表工程车辆、行人、摩托车及交通锥。被雷达或激光雷达错过的目标被定义为该目标没有命中/回波。雷达漏掉了更多的目标。对于自动驾驶应用中最常见的两个类别,汽车和行人,雷达忽略了36.05%的汽车和78.16%的行人。虽然nuScenes没有提供图像中物体的详细可见性,但我们相信它比雷达高得多。因此,我们使用相机而不是雷达来生成3D目标查询进行融合。
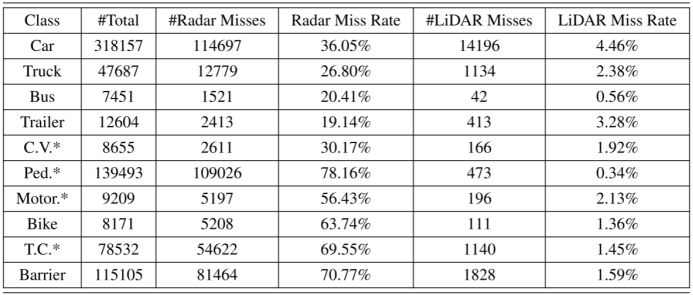
*在“传感器”一栏中,C表示仅摄相机。L代表只使用激光雷达, CR代表基于相机和雷达融合的方法。 我们注意到,尽管雷达传感器有这些物理限制,但我们的结果表明,与雷达融合可以显著改善仅对图像的检测。这开启了以不同方式配置雷达的可能性,例如在车顶上,以减少漏检率,并可能进一步提高融合表现。
4.2
二级评价指标的更多结果
为了完整起见,我们展示了表10,以显示nuScenes测试集上的其他二级评价指标与其他SOTA方法的比较。在与雷达融合后,与其他方法相比,我们的TransCAR在所有二级评价指标上都具有更好或相同水平的表现。特别是在雷达信号融合的情况下,TransCAR在速度估计方面有很大的优势。与基线(DETR3D)相比,TransCAR提高了所有评估指标的表现。 表10:nuScenes测试集上nuScenes数据集定义的其他二级评价指标与其他SOTA方法的比较。排除激光雷达唯一的解决方案,最好的表现突出在粗体。
4.3
更多消融研究
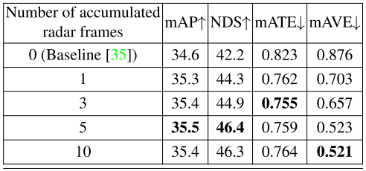
用于融合的雷达帧数:由于雷达点云稀疏,我们累积了多个具有自车运动补偿的雷达帧进行融合。我们评估了累积不同雷达帧数的影响,结果如表11和表12所示。表11显示了nuScenes验证集中所有10个类的评估结果,表12是仅针对轿车类的结果。累积5帧雷达整体效果最好,累积10帧时速度误差mAVE略低。积累更多的雷达帧可以提供更密集的雷达点云进行融合,但同时也会包含更多的噪声点。此外,对于快速移动的物体,积累更多的雷达帧会产生更长的“轨迹”,因为在这个阶段物体的运动无法得到补偿。这可能会潜在地损害边界框位置估计。 表11:累积不同雷达帧数进行融合的各类检测结果评价。
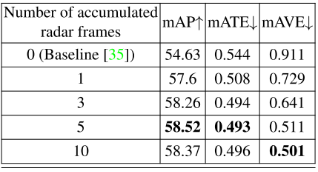
表12:累积不同雷达帧数进行融合的车辆检测结果评价。
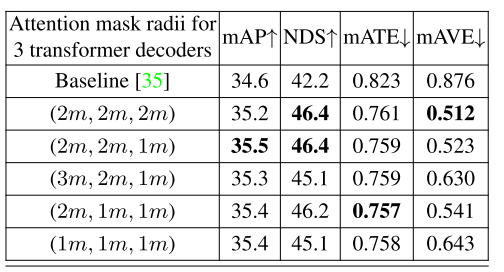
注意屏蔽半径:在我们的TransCAR融合系统中,我们将圆形注意屏蔽应用于transformer解码器。对于每个transformer解码器,圆形注意屏蔽的半径可以不同。我们在nuScenes验证集上测试了不同的圆注意屏蔽半径组合,结果如表13所示。如表13所示,所有半径配置都能显著提高3D检测表现。大的和小的注意屏蔽之间存在一种权衡。大的注意屏蔽可以增加合并正确的雷达特征的概率,特别是对于大的物体,但包含噪声和附近其他物体的雷达特征的可能性也更高。对于小的注意屏蔽,我们更确定所包含的雷达特征是好的,但我们更有可能错过正确的雷达特征。由表13可知,(2m, 2m, 1m)的综合表现最好。开始时较大的半径提供了较高的探测机会,以捕获正确的雷达特征。最后半径越小,估计结果越精确。 表13:在我们的TransCAR中,每个transformer解码器的不同注意屏蔽半径的比较。
5结论
在本文中,我们提出了一种基于transformer的高效、鲁棒的相机与雷达3D检测框架TransCAR,它可以学习雷达特征与视觉查询之间的软关联,而不是基于传感器标定的硬关联。相关的雷达特性提高了距离和速度估计。相关的雷达特性改善了距离和速度估计。我们的TransCAR在具有挑战性的nuScenes探测基准上成为了最先进的相机-雷达探测方法。我们希望我们的工作可以启发雷达相机融合的进一步研究,并激励使用transformer进行传感器融合。
-
3D
+关注
关注
9文章
2875浏览量
107485 -
雷达
+关注
关注
50文章
2930浏览量
117465 -
目标检测
+关注
关注
0文章
209浏览量
15605 -
毫米波雷达
+关注
关注
107文章
1043浏览量
64348
原文标题:TransCAR:基于Transformer的相机-毫米波雷达融合3D目标检测方法
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
毫米波雷达方案对比
毫米波雷达(一)
毫米雷达波概述
求大佬分享一种基于毫米波雷达和机器视觉的前方车辆检测方法
毫米波雷达工作原理,雷达感应模块技术,有什么优势呢?
雷达传感器模块,智能存在感应方案,毫米波雷达工作原理
漫谈车载毫米波雷达历史
加特兰基于AiP毫米波雷达芯片率先实现3D目标跟踪等功能

毫米波雷达(RADAR)

毫米波雷达(RADAR)
毫米波雷达模块的目标检测与跟踪
基于毫米波雷达和多视角相机鸟瞰图融合的3D感知方法





 工商网监
工商网监
评论