 SAM-PT:点几下鼠标,视频目标就分割出来了!
SAM-PT:点几下鼠标,视频目标就分割出来了!
只要在视频中点几下鼠标,SAM-PT 就能分割并且追踪物体的轮廓。

视频分割在许多场景下被广泛应用。电影视觉效果的增强、自动驾驶的理解场景,以及视频会议中创建虚拟背景等等都需要应用到视频分割。近期,基于深度学习的视频分割已经有着不错的表现了,但这依旧是计算机视觉中一个具有挑战性的话题。
在半监督视频对象分割(VOS)和视频实例分割(VIS)方面,目前的主流方法处理未知数据时表现一般,是在零样本情况下更是「一言难尽」。零样本情况就是指,这些模型被迁移应用到未经过训练的视频领域,并且这些视频中包含训练之外的物体。而表现一般的原因就是没有特定的视频分割数据进行微调,这些模型就很难在各种场景中保持一致的性能。
克服这个难题,就需要将在图像分割领域取得成功的模型应用到视频分割任务中。这就不得不提到 Segment Anything Model(SAM,分割一切模型)了。
SAM 是一个强大的图像分割基础模型,它在规模庞大的 SA-1B 数据集上进行训练,这其中包含 1100 万张图像和 10 亿多个掩码。大量的训练让 SAM 了具备惊人的零样本泛化能力。SAM 可以在不需要任何标注的情况下,对任何图像中的任何物体进行分割,引起了业界的广泛反响,甚至被称为计算机视觉领域的 GPT。
尽管 SAM 在零样本图像分割上展现了巨大的能力,但它并非「天生」就适用于视频分割任务。
最近研究人员已经开始致力于将 SAM 应用于视频分割。虽然这些方法恢复了大部分分布内数据的性能,但在零样本情况下,它们还是无法保持 SAM 的原始性能。其他不使用 SAM 的方法,如 SegGPT,可以通过视觉 prompt 成功解决一些分割问题,但仍需要对第一帧视频进行掩码注释。这个问题在零样本视频分割中的关键难题。当研究者试图开发能够容易地推广到未见过的场景,并在不同的视频领域持续提供高质量分割的方法时,这个难题就显得更加「绊脚」。
现在,有研究者提出了 SAM-PT(Segment Anything Meets Point Tracking),这或许能够对「绊脚石」的消除提供新的思路。

论文地址:https://arxiv.org/pdf/2307.01197
GitHub 地址:https://github.com/SysCV/sam-pt
如图 1 所示,SAM-PT 第一种将稀疏点追踪与 SAM 相结合用于视频分割的方法。与使用以目标为中心的密集特征匹配或掩码传播不同,这是一种点驱动的方法。它利用嵌入在视频中的丰富局部结构信息来跟踪点。因此,它只需要在第一帧中用稀疏点注释目标对象,并在未知对象上有更好的泛化能力,这一优势在 UVO 基准测试中得到了证明。该方法还有助于保持 SAM 的固有灵活性,同时有效地扩展了它在视频分割方面的能力。
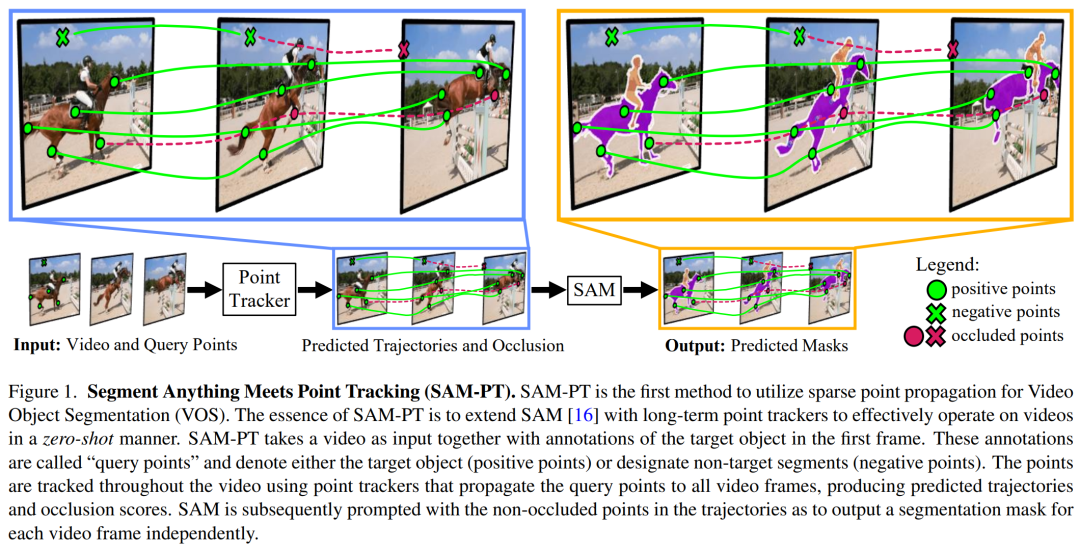
SAM-PT 使用最先进的点追踪器(如 PIPS)预测稀疏点轨迹,以此提示 SAM,利用其多功能性进行视频分割。研究人员发现,使用来自掩码标签的 K-Medoids 聚类中心来初始化跟踪点,是与提示 SAM 最兼容的策略。追踪正反两方面的点可以将目标物体从其背景中清晰地划分出来。
为了进一步优化输出的掩码,研究人员提出了多个掩码解码通道,将两种类型的点进行整合。此外,他们还设计了一种点重新初始化策略,随着时间的推移提高了跟踪的准确性。这种方法包括丢弃变得不可靠或被遮挡的点,并添加在后续帧 (例如当物体旋转时) 中变得可见的物体部分或部分的点。
值得注意的是,本文的实验结果表明,SAM-PT 在几个视频分割基准上与现有的零样本方法不相上下,甚至超过了它们。在训练过程中,SAM-PT 不需要任何视频分割数据,这证明了方法的稳健性和适应性。SAM-PT 具有增强视频分割任务进展的潜力,特别是在零样本场景下。
SAM-PT 方法概览
尽管 SAM 在图像分割方面展示出令人印象深刻的能力,但其在处理视频分割任务方面存在固有的局限性。我们提出的 "Segment Anything Meets Point Tracking"(SAM-PT)方法有效地将 SAM 扩展到视频领域,为视频分割提供了强大的支持,而无需对任何视频分割数据进行训练。
如图 2 所示,SAM-PT 主要由四个步骤组成:
1) 为第一帧选择查询点;
2) 使用点跟踪器,将这些点传播到所有视频帧;
3) 利用 SAM 生成基于传播点的逐帧分割掩码;
4) 通过从预测的掩码中抽取查询点来重新初始化这个过程。
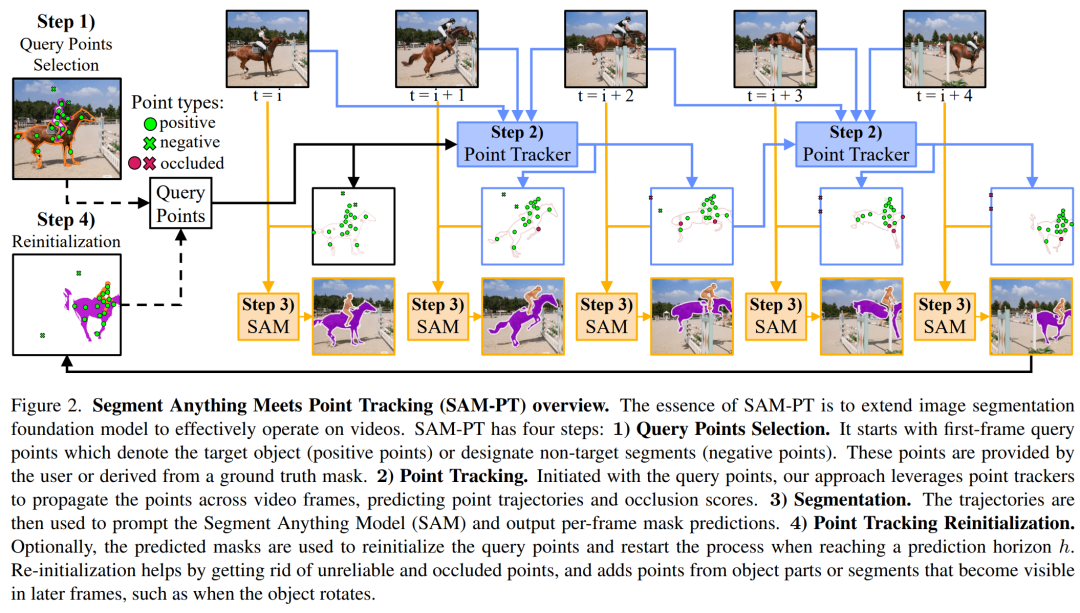
选择查询点。该过程的第一步是定义第一个视频帧中的查询点。这些查询点要么表示目标对象 (正点),要么指定背景和非目标对象 (负点)。用户可以手动、交互式地提供查询点,也可以从真实掩码派生出查询点。
考虑到它们的几何位置或特征差异性,用户可以使用不同的点采样技术从真实掩码中获得查询点,如图 3 所示。这些采样技术包括:随机采样、K-Medoids 采样、Shi-Tomasi 采样和混合采样。

点跟踪。从查询点开始,采用稳健的点跟踪器在视频中的所有帧中传播点,从而得到点的轨迹和遮挡分数。
采用最先进的点跟踪器 PIPS 来传播点,因为 PIPS 对长期跟踪挑战 (如目标遮挡和再现) 显示出适当的稳健性。实验也表明,这比链式光流传播或第一帧对应等方法更有效。
分割。在预测的轨迹中,未遮挡的点作为目标对象在整个视频中的位置的指示器。这时就可以使用非遮挡点来提示 SAM,并利用其固有的泛化能力来输出每帧分割掩码预测(如图 4 所示) 。
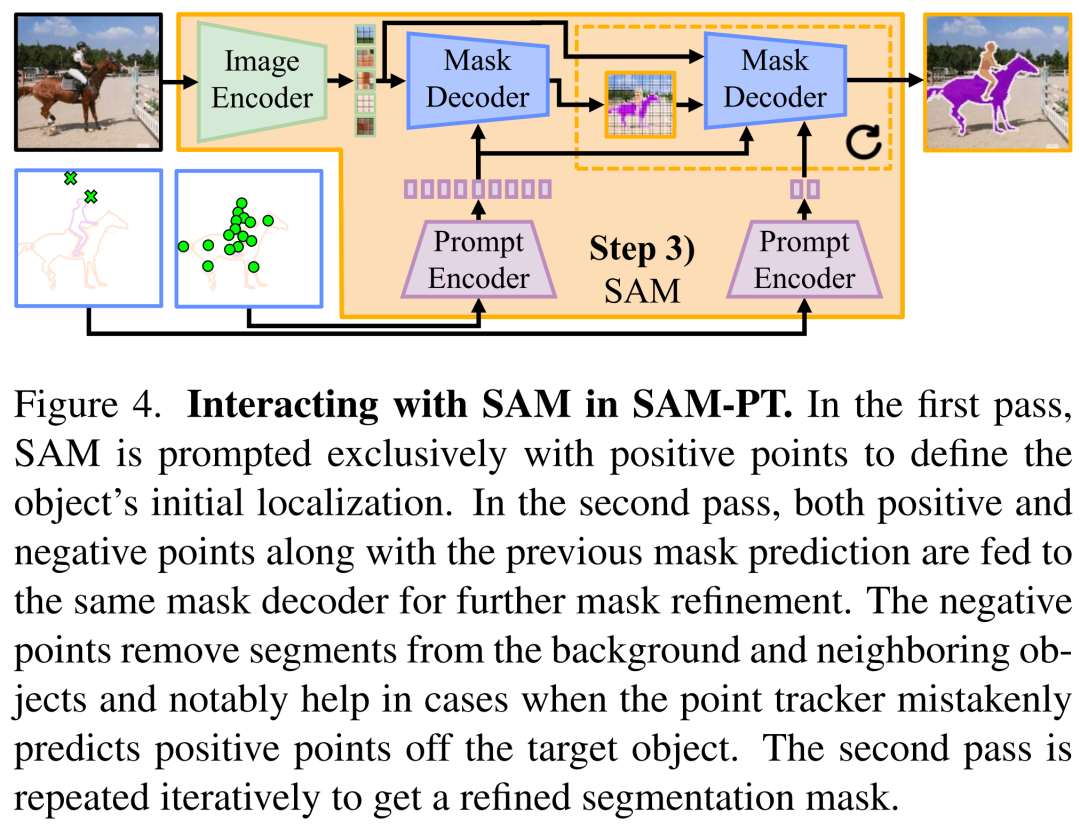
点跟踪重新初始化。一旦达到 h = 8 帧的预测期,用户就可以选择使用预测掩码对查询点进行重新初始化,并将变体表示为 SAM-PT-reinit。在到达这个水平线时,会有 h 个预测的掩码,并将使用最后一个预测的掩模来采样新的点。在这一阶段,之前所有的点都被丢弃,用新采样点来代替。
根据上面的方法,就可以将这个视频进行流畅的分割了,如下图:

看看更多的展示效果:


SAM-PT 与以目标为中心的掩码传播的比较
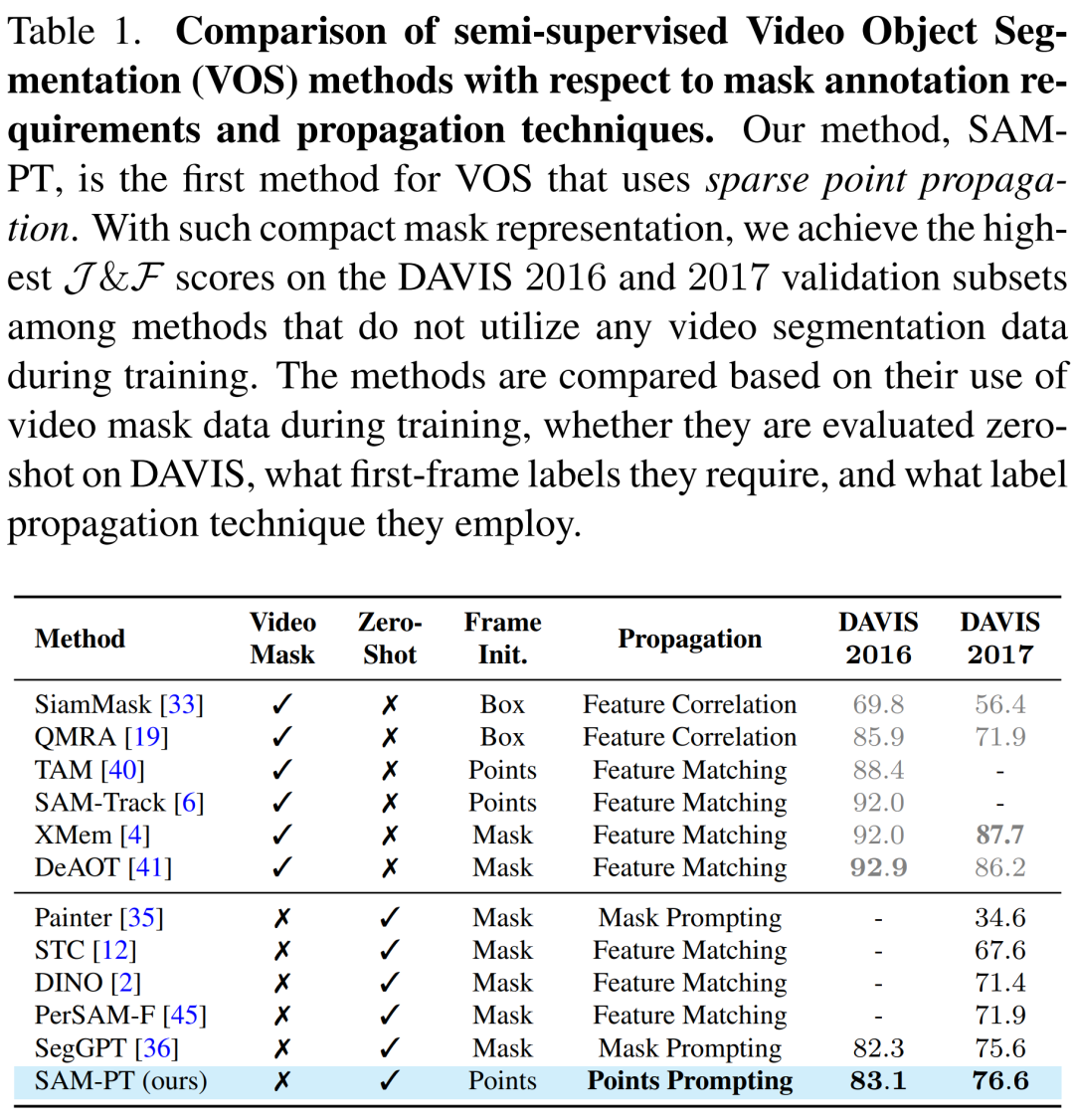
SAM- PT 将稀疏点跟踪与提示 SAM 相结合,并区别于传统依赖于密集目标掩码传播的视频分割方法,如表 1 所示。
与在训练期间不利用视频分割数据的方法相比,SAM-PT 有着与之相当甚至更好的表现。然而,这些方法与那些利用同一域中的视频分割训练数据的方法, 如 XMem 或 DeAOT 之间还是存在着性能差距。
综上所述,SAM-PT 是第一个引入稀疏点传播并结合提示图像分割基础模型,进行零样本视频对象分割的方法。它为关于视频对象分割的研究提供了一个新的视角,并增加了一个新的维度。
实验结果
对于视频物体分割,研究团队在四个 VOS 数据集上评估了他们的方法,分别是 DAVIS 2016, DAVIS 2017, YouTube-VOS 2018, 和 MOSE 2023。
对于视频实例分割,他们在 UVO v1.0 数据集的 densevideo 任务上评估了该方法。
他们还用图像实例分割中的标准评估指标来评估所提出方法,这也适用于视频实例分割。这些指标包括平均准确率(AP)和基于 IoU 的平均召回率(AR)。
视频物体分割的结果
在 DAVIS 2017 数据集上,本文提出的方法优于其他没有经过任何视频物体分割数据训练的方法,如表 3 所示。
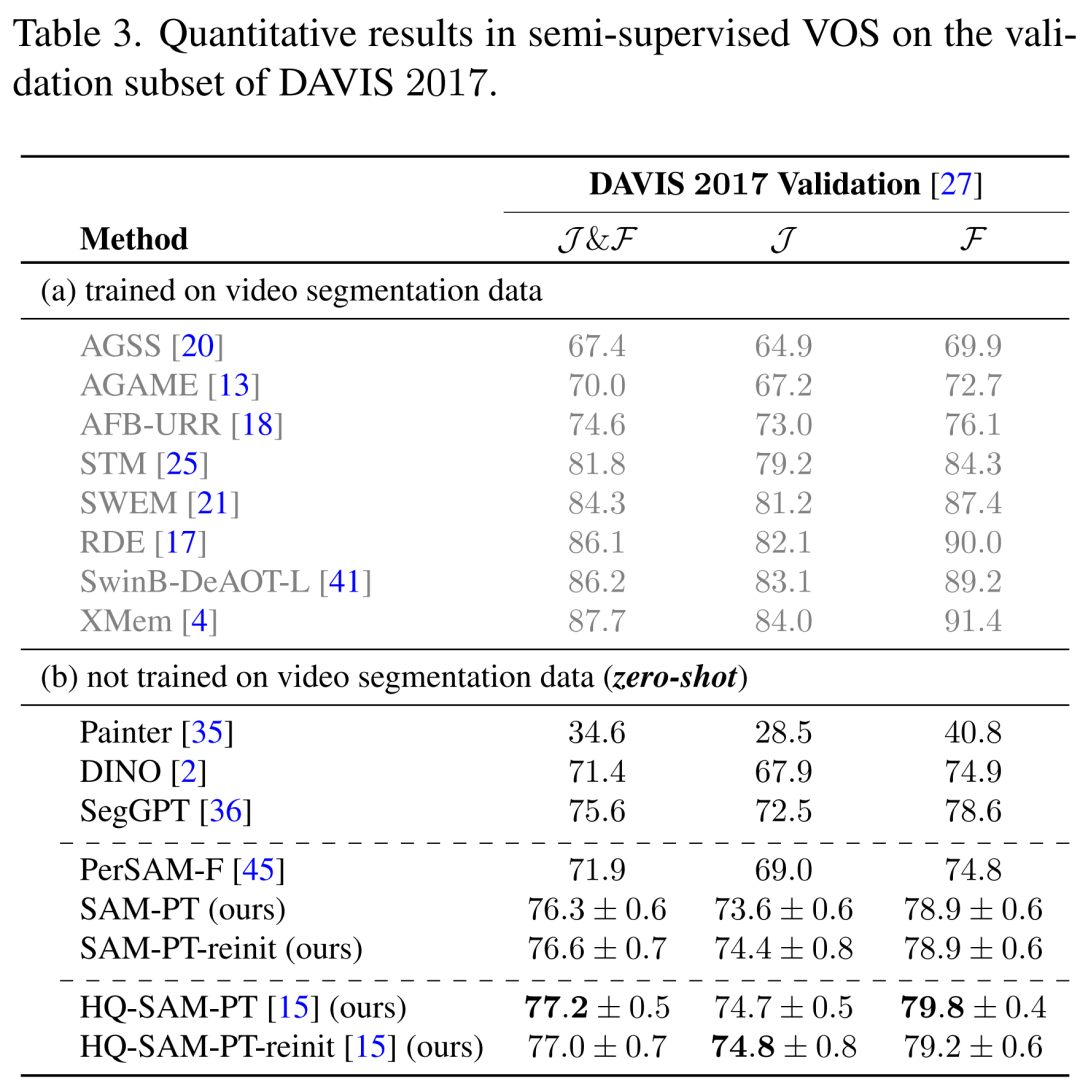
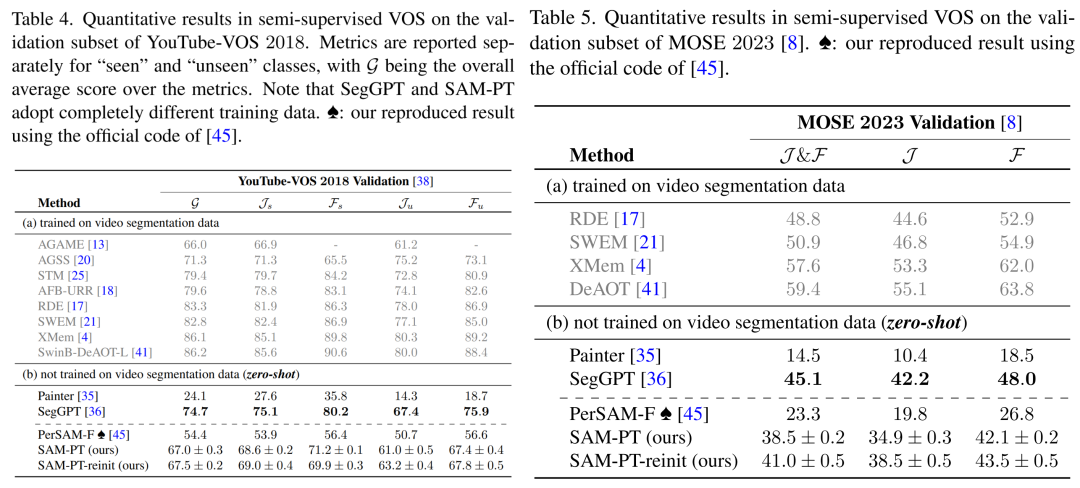
SAM-PT 在 YouTube-VOS 2018 和 MOSE 2023 数据集上的表现也超过了 PerSAM-F,取得了 67.0 和 41.0 的平均分,如表 4、表 5 所示。然而,在不同的掩码训练数据下,与 SegGPT 相比,SAM-PT 在这两个数据集上的表现有所欠缺。
定性分析。在 DAVIS 2017 上对 SAM-PT 和 SAM-PTreinit 成功的视频分割的可视化结果分别见图 7a 和图 7b。值得注意的是,图 8 展示了对未知网络视频的成功视频分割 —— 来自受动画影响的动画电视系列《降世神通:最后的气宗》的片段,这表明了所提出方法的零样本能力。

局限和挑战。SAM-TP 的零样本性能很有竞争力,但仍然存在着一些局限。这些局限主要集中在点跟踪器在处理遮挡、小物体、运动模糊和重新识别方面。在这些方面,点跟踪器的错误会传播到未来的视频帧中。
图 7c 展示了 DAVIS 2017 中的这些问题实例,图 9 展示了《降世神通:最后的气宗》片段中的其他实例。

视频实例分割的结果
在相同的遮罩建议下,SAM-PT 明显优于 TAM,尽管 SAM-PT 没有在任何视频分割数据上训练。TAM 是一个结合了 SAM 和 XMem 的并行方法,其中 XMem 在 BL30K 上进行了预训练,并在 DAVIS 和 YouTube-VOS 上进行了训练,但没有在 UVO 上训练。
另一方面,SAM-PT 结合了 SAM 和 PIPS 点跟踪方法,这两种方法都没有经过视频分割任务的训练。
-
图像分割
+关注
关注
4文章
182浏览量
18079 -
模型
+关注
关注
1文章
3410浏览量
49463 -
SAM
+关注
关注
0文章
113浏览量
33633
原文标题:分割一切视频版来了!SAM-PT:点几下鼠标,视频目标就分割出来了!
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
除了视频分割,这款软件还能进行视频合并、压缩、去水印
基于笔画提取和颜色模型的视频文字分割算法
基于多层采样多阈值的目标分割算法
视觉显著性目标分割提取
使用OpenCv进行运动目标的检测的课程论文免费下载

动态外观模型和高阶能量的双边视频目标分割方法

YOLOv8最新版本支持SAM分割一切

基于SAM设计的自动化遥感图像实例分割方法

复旦开源LVOS:面向真实场景的长时视频目标分割数据集






 工商网监
工商网监
评论