 疯抢!HBM成为AI新瓶颈!
疯抢!HBM成为AI新瓶颈!
继英伟达之后,全球科技巨头实际上正在通过向 SK 海力士索取第五代高带宽内存 (HBM) HBM3E 样品来进行预订。
半导体业内人士7月3日报道称,全球各大科技巨头已陆续向SK海力士索取HBM3E样品。该名单包括 AMD、微软和亚马逊。
样品请求是下订单之前的强制性流程,旨在证明其 GPU、其他半导体芯片或云系统以及内存半导体之间的兼容性。这表明产品的良率足够稳定,可以进行量产,标志着交付前的最后阶段。HBM3E是当前顶级第四代HBM3的下一代产品。SK海力士是目前全球唯一一家量产HBM3芯片的公司。
SK海力士正忙于处理来自客户的大量HBM3E样品请求。英伟达首先要求提供样品,这次的出货量几乎是千钧一发。这些索取样品的客户公司可能会在今年年底收到样品。全球领先的GPU公司Nvidia此前曾向SK海力士供应HBM3,并已索取HBM3E样品。各大科技公司都在热切地等待 SK 海力士的样品。
随着HBM3E需求的爆炸性增长,产量显着增加。SK 海力士决定使用最新的尖端 10 纳米级第五代 (1b) 技术大幅提高明年的产量。大部分增量将由 HBM3E 填充。这表明SK海力士正在以HBM为首要业务战略,全力克服半导体低迷。据悉,SK海力士约40%的营业利润来自HBM。
所有向 SK 海力士索取 HBM3E 样品的公司都是人工智能行业的主要参与者。AMD 与 Nvidia 一起引领 GPU 市场。GPU 对于处理大量数据至关重要,是 ChatGPT 等生成型人工智能的大脑。为此,诸如 HBM 之类的高性能、大容量存储器至关重要。瓜分GPU市场的Nvidia和AMD都已向SK海力士伸出了援手。
AMD最近发布了其下一代GPU MI300X,并表示将从SK海力士和三星电子获得HBM3供应。此次,似乎是向SK海力士索取了HBM3E样品,以确定第五代HBM的供应商。MI300X配备的HBM是Nvidia去年底推出的最新旗舰GPU H100的2.4倍。
亚马逊和微软是云服务领域的两大巨头。他们的市场份额加起来超过了50%。作为生存策略,云服务公司优先引入生成式AI技术,并大幅增加投资。亚马逊旗下运营的全球第一云服务提供商(CSP)亚马逊网络服务近期投资1亿美元建立人工智能创新中心。与此同时,微软的Azure云服务正在扩大与ChatGPT开发商OpenAI的合作关系。
市场研究公司TrendForce表示:“亚马逊网络服务和谷歌等主要云服务公司正在开发自己的专用集成电路(ASIC)和配备Nvidia GPU的AI服务器,是当前HBM激增的推动力要求。”
以DRAM 4月的指标性产品DDR4 8Gb为例,批发价为每个1.48美元左右,环比下跌1%;4Gb产品价格为每个1.1美元左右,环比下跌8%。
在DRAM的整体颓势之中,HBM(高带宽内存,High Bandwidth Memory)却在逆势增长。身为DRAM的一种,与大部队背道而驰,价格一路水涨船高。据媒体报道,2023年开年后三星、SK海力士两家存储大厂HBM订单快速增加,HBM3规格DRAM价格上涨5倍。HBM3原本价格大约30美元每GB,现在的价格怕是更加惊人。
一边是总体DRAM跌到成本价,一边是“尖子生”HBM价格涨5倍。
6 月 18 日据 businesskorea 以及 etnews 报道,SK 海力士将扩展其 HBM3 后道工艺生产线,并已收到英伟达要求其送测 HBM3E 样品的请求
据称,考虑到对人工智能 (AI) 半导体的需求增加,S 海力士正在考虑将 HBM 的产能翻倍的计划。
业内消息称 SK 海力士于 6 月 14 日收到了 NVIDIA 对 HBM3E 样品的请求,并正在准备发货。HBM3E 是当前可用的最高规格 DRAM HBM3 的下一代,被誉为是第五代半导体产品。
SK 海力士目前正致力于开发该产品,目标是在明年上半年实现量产。SK 海力士副总裁朴明秀在今年 4 月的第一季度收益公告电话会议上透露:“我们正在为今年下半年准备 8Gbps HBM3E 产品样品,并计划在明年上半年实现量产。”
半导体产业联盟查询发现,目前 SK 海力士在 HBM 市场已经领先于三星电子。据市场研究公司 TrendForce 称,截至去年,SK 海力士在全球 HBM 市场上占据 50% 的市场份额,而三星电子则保持在 40% 左右。
去年 6 月,SK 海力士成为世界上第一个大规模生产高性能 HBM3 的公司,从而一举奠定其市场领导地位。在通过 HBM3 样品的严格性能评估后,成功满足了高端客户的需求,目前已经在为 NVIDIA H100 供应。
如果他们成功交付第五代 HBM 产品,将进一步巩固他们在超快速 AI 半导体市场上的领先地位。
HBM的优势
直接地说,HBM将会让服务器的计算能力得到提升。由于短时间内处理大量数据,AI服务器对带宽提出了更高的要求。HBM的作用类似于数据的“中转站”,就是将使用的每一帧、每一幅图像等图像数据保存到帧缓存区中,等待GPU调用。与传统内存技术相比,HBM具有更高带宽、更多I/O数量、更低功耗、更小尺寸,能够让AI服务器在数据处理量和传输速率有大幅提升。
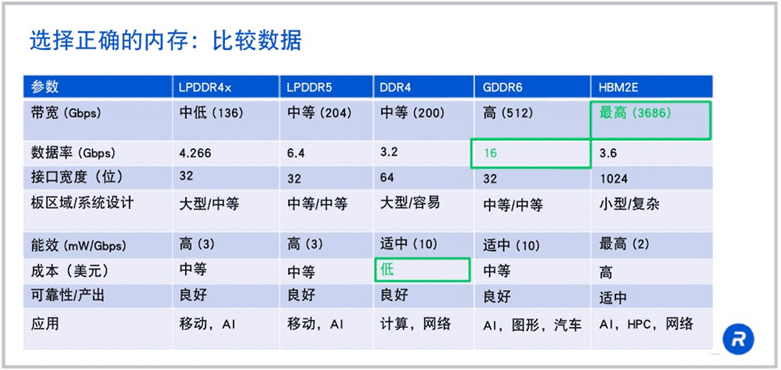
来源:rambus
可以看到HBM在带宽方面有着“碾压”级的优势。如果 HBM2E 在 1024 位宽接口上以 3.6Gbps 的速度运行,那么就可以得到每秒 3.7Tb 的带宽,这是 LPDDR5 或 DDR4 带宽的 18 倍以上。
除了带宽优势,HBM可以节省面积,进而在系统中安装更多GPU。HBM 内存由与 GPU 位于同一物理封装上的内存堆栈组成。
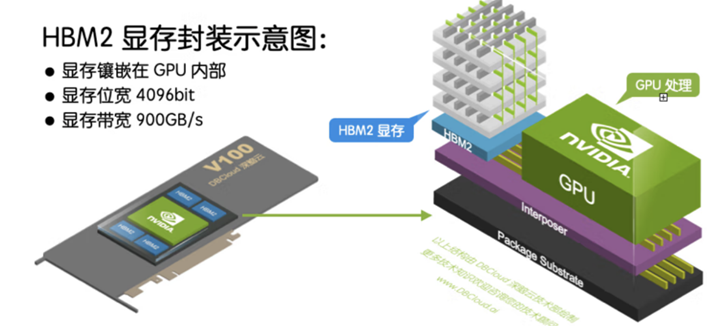
这样的架构意味着与传统的 GDDR5/6 内存设计相比,可节省大量功耗和面积,从而允许系统中安装更多 GPU。随着 HPC、AI 和数据分析数据集的规模不断增长,计算问题变得越来越复杂,GPU 内存容量和带宽也越来越大是一种必需品。H100 SXM5 GPU 通过支持 80 GB(五个堆栈)快速 HBM3 内存,提供超过 3 TB/秒的内存带宽,是 A100 内存带宽的 2 倍。
过去对于HBM来说,价格是一个限制因素。但现在大模型市场上正处于百家争鸣时期,对于布局大模型的巨头们来说时间就是金钱,因此“贵有贵的道理”的HBM成为了大模型巨头的新宠。随着高端GPU需求的逐步提升,HBM开始成为AI服务器的标配。
目前英伟达的A100及H100,各搭载达80GB的HBM2e及HBM3,在其最新整合CPU及GPU的Grace Hopper芯片中,单颗芯片HBM搭载容量再提升20%,达96GB。
AMD的MI300也搭配HBM3,其中,MI300A容量与前一代相同为128GB,更高端MI300X则达192GB,提升了50%。
预期Google将于2023年下半年积极扩大与Broadcom合作开发AISC AI加速芯片TPU也计划搭载HBM存储器,以扩建AI基础设施。
-
芯片
+关注
关注
459文章
51568浏览量
429763 -
DRAM
+关注
关注
40文章
2337浏览量
184266 -
SK海力士
+关注
关注
0文章
980浏览量
38907
原文标题:疯抢!HBM成为AI新瓶颈!
文章出处:【微信号:WW_CGQJS,微信公众号:传感器技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
HBM4到来前夕,HBM热出现两极分化
HBM3E量产后,第六代HBM4要来了!

AI兴起推动HBM需求激增,DRAM市场面临重塑
AI时代核心存力HBM(上)
HBM上车?HBM2E被用于自动驾驶汽车
被称为“小号HBM”,华邦电子CUBE进阶边缘AI存储
中国AI芯片和HBM市场的未来
剑指HBM及AI芯片,普莱信重磅发布Loong系列TCB先进封装设备
美光调整2024年资本支出预测,加强AI产业HBM投资力度
三星联席CEO在AI合作交流中力推HBM内存
高盛谈HBM四年十倍市场 受益于AI服务器持续增长
SK海力士HBM3E正式量产,巩固AI存储领域的领先地位
HBM:突破AI算力内存瓶颈,技术迭代引领高性能存储新纪元

从两会看AI产业飞跃,HBM需求预示存储芯片新机遇






 工商网监
工商网监
评论