 达观曹植大模型正式对外公测!专注于长文本、多语言、垂直化发展
达观曹植大模型正式对外公测!专注于长文本、多语言、垂直化发展

大模型时代到来,国内出现“百模大战”的局面。达观数据自23年3月宣布研发大语言模型以来,一直积极探索大语言模型的专业化、特长化和产品化。通过多年的高质量数据积累,不断精进算法创新,结合多年的文本处理工程实践经验,已开发出具有长文本、多语言、垂直化三大特点的专用国产“曹植”大语言模型。7月伊始,达观正式对外发布“曹植”大语言模型应用公测版,可在达观数据官网申请试用!

申请通道与规则
1申请通道
公司官网申请通道:
http://www.datagrand.com/products/aigc/
2申请规则
申请填写规则:
请按照申请表单页面要求填写,以便于工作人员审核。
申请通过告知:
审核通过后,工作人员将通过电话、短信或邮件方式把体验平台的网址和邀请码发送给您
特点1:长文本
“曹植”大模型三大特点
达观数据在长文本处理领域深耕多年,研发的“曹植”大模型特别擅长做长文档的写作、审核、润色、翻译等。“曹植”通过其卓越的自动化写作能力,可准确完成多类型、复杂结构的长文本写作,自动起草多种类型的文档,轻松应对长篇大论的要求。无论是白皮书、技术报告还是品牌故事,“曹植”大模型都能为客户提供高质量、流畅的文案撰写服务。
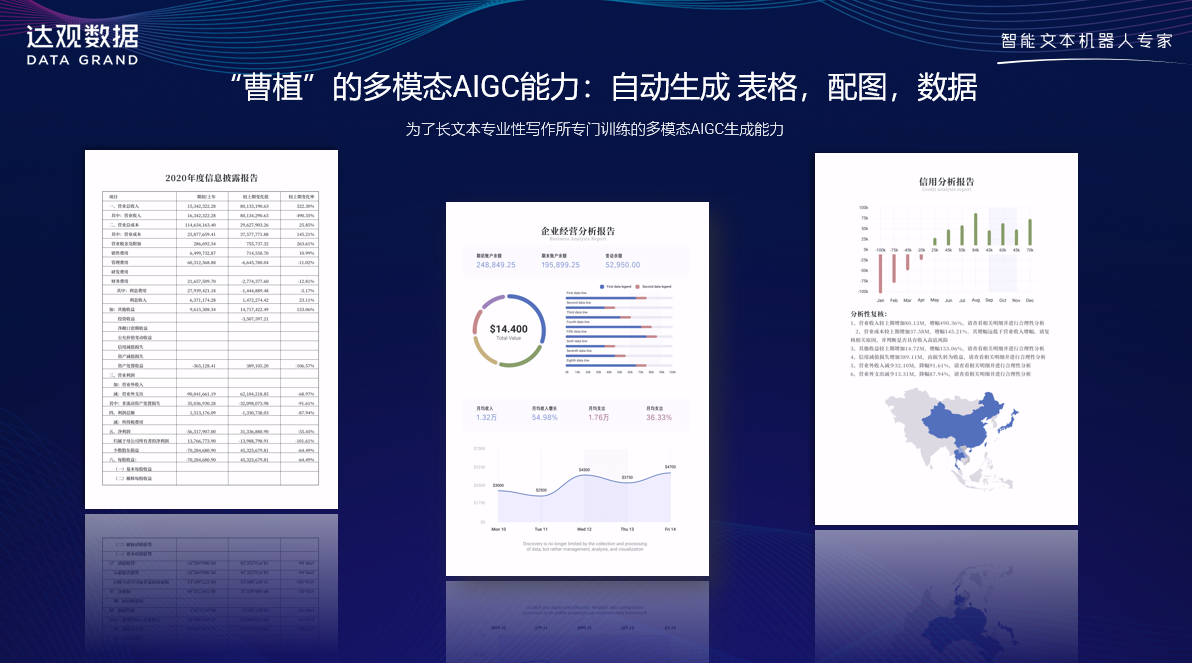
“曹植”大模型独特的专业性报告写作能力
长文本最大的难点在于文档内存在诸多复杂结构元素,如文本、图片、表格、数据图、标题、段落、页眉页脚、摘要等版面元素,以及跨多个文档间存在复杂关系,还需解析各类复杂格式,如PDF、PPT、Excel、Doc,扫描图片等;为提升长文本写作专业性,达观专门训练了多模态AIGC生成能力,可自动生成表格、图表、数据等元素;
特点2:多语言
“曹植”大模型三大特点
“曹植”同时拥有其杰出的多语言写作和翻译能力,使得用户在不同语言环境下都能得到高质量的文案服务。无论需要撰写一篇英文论文、一封法语商业邮件,或者对一篇日文新闻进行翻译,“曹植”都能帮助用户轻松应对各种语言挑战。
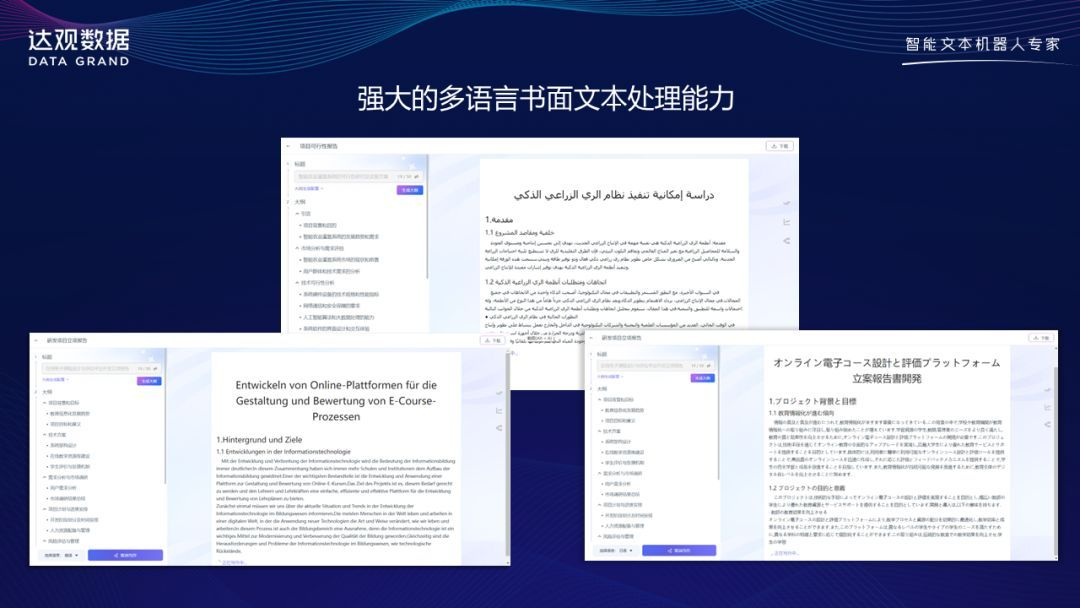
“曹植”大模型多语言写作能力
多语言翻译最大特色是在翻译的同时可以对原文的标题、段落等内容实现 1:1版式还原,无需更改格式,提供实时的翻译体验,广泛应用于多语言文档密集处理场景。

“曹植”大模型多语言1:1版式还原翻译能力
特点3:垂直化
“曹植”大模型三大特点
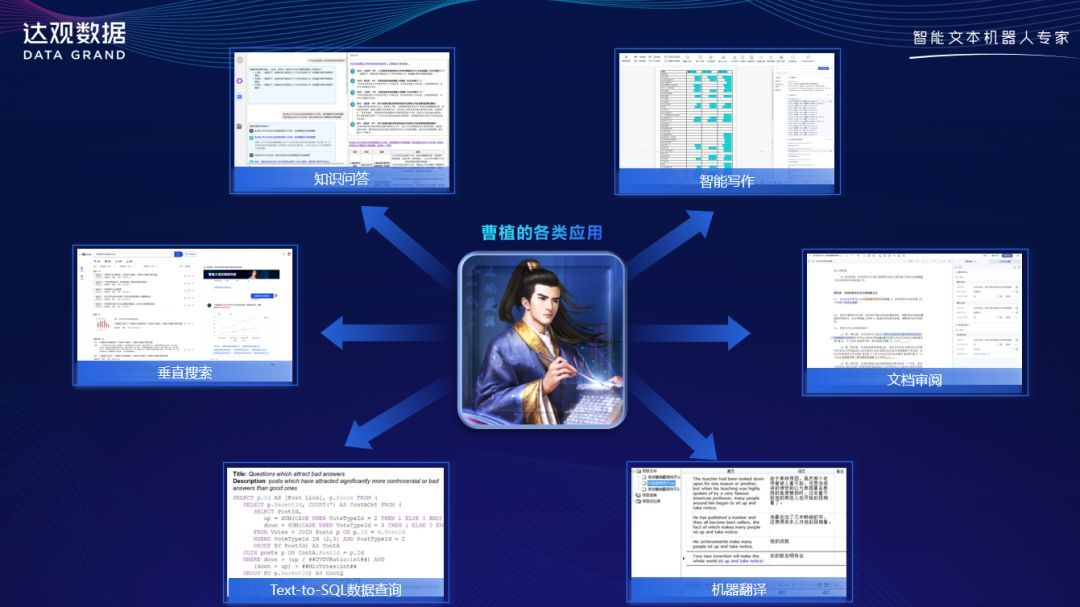
大模型不只有“一问一答”的产品形态,需要和垂直行业应用充分结合,只有和行业应用充分结合,才能解决企业实际的问题。“曹植”可针对不同行业开发特定应用和训练专属数据库,使用海量训练数据进行“曹植”大模型的预训练,生成具备基础语言能力和垂直应用能力的模型;支持个性化定制,本地服务器私有化部署,独家提供监督精调服务,以加强垂直领域专用任务的能力。

“曹植”大模型垂直行业应用能力

加强“曹植”大模型垂直领域专用任务的能力
达观坚持训练数据与算法模型自主可控,实现与国产GPU联调对接,推理功能成功上线运行,与国产GPU合作伙伴开展长期合作,不断优化高质量硬件设备,以适应市场需求和技术发展,为客户提供了“算力+模型”的全套国产化信创方案,让大模型赋能百业。
“曹植”大模型赋能多行业应用
“曹植”垂直领域大语言模型也将进一步夯实达观产业应用智能化基座,全面增强AI全产品矩阵能力。这也是国内大规模语言模型中首批可落地的产业应用级模型,未来将可持续赋能金融、政务、制造等多个垂直领域和通用场景人工智能的落地和发展。
-
大模型
+关注
关注
2文章
3854浏览量
5289
发布评论请先 登录
GT20L24F6Y标准点阵多国语言字库芯片:开启多语言显示新境界
GT32L24F0210标准点阵多国语言字库芯片:多语言显示的理想之选
GT32L24A180标准点阵中外文字库芯片:多语言显示的理想之选
京东多语言质量解决方案
使用 Docker 一键部署 PaddleOCR-VL: 新手保姆级教程

今日看点:象帝先推出首款量产Imagination DXD GPU显卡;小米汽车累计交付突破 50 万台
ElfBoard技术贴|如何在【RK3588】ELF 2开发板上完成PPOC本地化部署

江苏省委书记一行到访思必驰调研
阿里巴巴国际站关键字搜索 API 实战:3 步搞定多语言适配 + 限流破局,询盘量提升 40%
速卖通全球运营利器:商品详情接口多语言 + 合规 + 物流适配技术全解析

广和通发布端侧情感对话大模型FiboEmo-LLM
3万字长文!深度解析大语言模型LLM原理

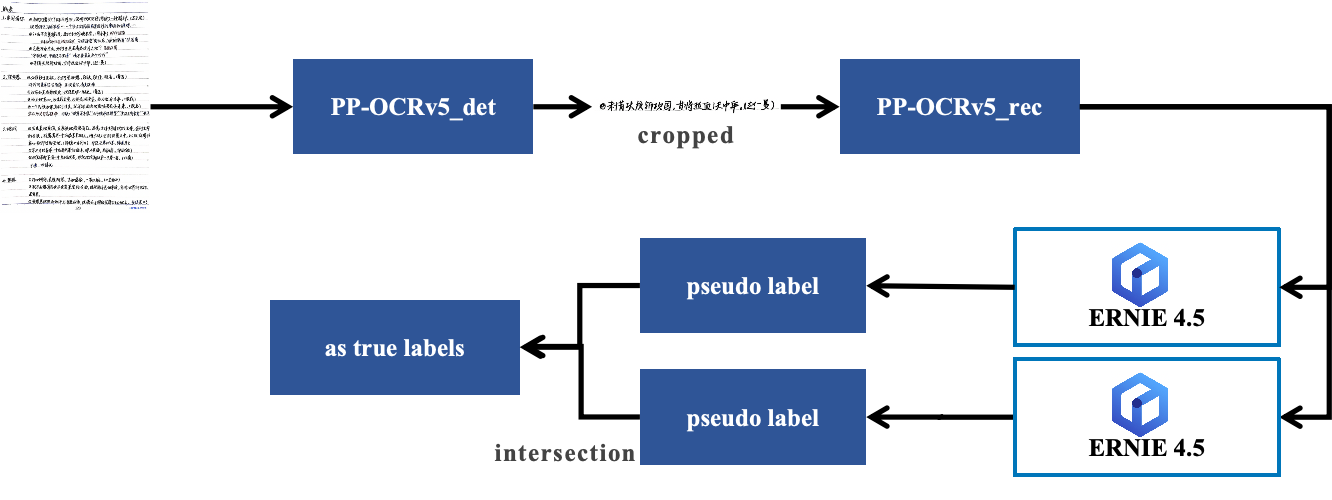
小语种OCR标注效率提升10+倍:PaddleOCR+ERNIE 4.5自动标注实战解析
EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程




评论