 大语言模型的炒作曲线
大语言模型的炒作曲线
最近几个月,大型语言模型成为了全球的热门词汇,频频登上各大新闻头条。这些复杂的模型,比如 OpenAI 的 GPT-4 和 Meta 的 LLaMA,激发了研究人员、开发人员和公众的想象力。
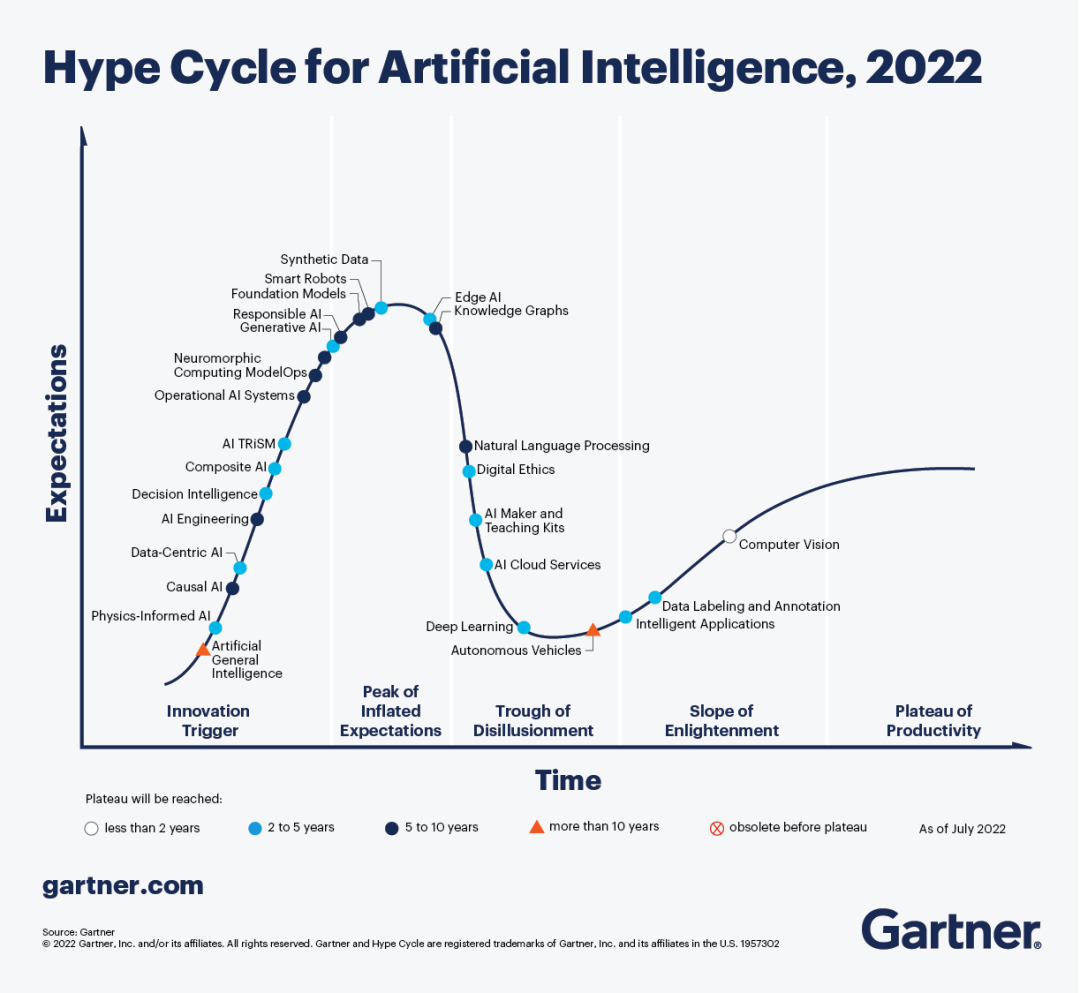
然而,无异于任何一门具有变革性的技术,大型语言模型也经历过炒作,随之而来的预期波动以及恐惧。2022 年底,随着人们对人工智能与生成式 AI 的期望达到高潮,Gartner 发布了一份炒作周期报告。 随着 GPT-4 宣布后,新 AI 产品的开发呈爆炸式增长,时隔不到一年,如今我们处于大型语言模型炒作曲线的什么位置?
大型语言模型究竟是什么? 在讨论炒作曲线之前,我们先来介绍一下大型语言模型究竟是什么。这种模型是生成式 AI 的一个子集,生成文本的能力得以优化,特别是在给定提示和相关上下文的情况下预测句子中的下一个单词。这些模型接受了在非常大的数据集上的训练,使用的参数超过十亿个,而且经过了人类(或其他大型语言模型)的微调。这类模型包括 BERT、GPT 和 T5 等 。 说到底,大型语言模型就是文本计算器,知道如何根据给定的提示,创建人类可以理解的文本。
炒作曲线:从兴奋到现实主义 在某种新技术出现时,经常能够观察到炒作曲线。初期阶段,受到崇高的承诺和有远见的预测的驱使,人们会产生极大的兴奋和期待。 就大型语言模型而言,生成连贯且与上下文紧密相关的文本的能力带动了最初的炒作。媒体报道了这些模型的惊人功能,激发了各行各业无数人的想象力。同时,对于这类工具的误解而产生的恐惧也引发了很多争议。
过高期望的峰值期 随着大型语言模型受到的关注越来越多,对其能力的期望也膨胀至前所未有的高度。人们设想未来人工智能生成的内容将彻底改变新闻业、客户服务、内容创作,乃至个人助理等行业。然而,在这个高峰阶段,我们必须谨记这些模型还远非完美,并且有其局限性。
泡沫化的底谷期 在期望峰值过后,大型语言模型的实际情况逐步浮出水面,并由此而进入一段底谷期。虽然这些模型可以生成令人印象深刻的文本或图像,但它们也有可能生成不准确、带有偏见或无意义的输出。此外,在此阶段,围绕人工智能的伦理问题和对此类技术的潜在滥用被放大。 结果是,热情消退,公众情绪向怀疑和恐惧倾斜。 我认为,如今我们就处于这个阶段,而且我们已经加速通过了过高期望的峰值期! 虽然许多个人和公司利用这项技术创造了巨大的价值,但只是少数个例,而且很多人仍处于泡沫化的底谷期。
稳步爬升的光明期 随着最初的炒作消退,人们对大型语言模型的理解开始更加真实。研究人员和开发人员积极致力于解决与这些模型相关的局限性和挑战。在微调技巧、数据质量和减少偏差等方面进行了改进。 人们的关注从过高的期望过渡到实际应用的改进技术。在稳步爬升的光明期,大型语言模型的真正潜力和价值开始具体化。 大型语言模型并不能解决所有的问题,但可以非常接近。根据帕累托法则(又名80/20法则,约仅有20%的因素影响80%的结果),这些工具只有20%的概率帮助你创造80%的价值,具体取决于用例。这些模型以人与机器之间前所未有的方式释放创造力。不仅可以加快构思的过程,而且还可以消除解决问题的许多障碍。
实质生产的高原期 最终,大型语言模型将找到各自的立足之地,并为多个行业做出有意义的贡献。改进部署战略,更好地理解自己的优势和局限性,再加上适当的道德考量,这些模型都能成为有价值的工具。 大型语言模型不仅能帮助我们完成内容创建、语言翻译、聊天机器人等任务,甚至能够辅助研究人员的研发工作。实质生产的高原期标志着大型语言模型的成熟阶段,它们将无缝融入我们的生活,并成为提供支持的工具。这一切何时会实现还有待观察,但可能比我们想象的要早!
总结 毫无疑问,大型语言模型在人工智能领域引起了轰动。围绕这些模型的炒作曲线是一个自然而然的过程,任何变革性的技术都会经历。虽然最初过高的期望可能会引发低谷期,但必须承认这些模型具有巨大的潜力。 随着技术的不断成熟,难题的攻克,以及应用程序的改进,大型语言模型有望成为加强人类的创造力以及解决问题的宝贵资产。 理解和管理炒作曲线,可以帮助我们负责任地利用这些强大的工具,并利用它们改善社会。
-
人工智能
+关注
关注
1792文章
47425浏览量
238948 -
语言模型
+关注
关注
0文章
530浏览量
10297
原文标题:大语言模型的炒作曲线
文章出处:【微信号:AI科技大本营,微信公众号:AI科技大本营】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
大语言模型开发语言是什么
大语言模型如何开发
【《大语言模型应用指南》阅读体验】+ 俯瞰全书
大语言模型的预训练
大语言模型(LLM)快速理解






 工商网监
工商网监
评论